
















 Hogar
Hogar
Meta -se ve a la Llama 4 con un largo contexto Scout y Maverick Models, 2t Parameter Behemoth próximamente!
En enero de 2025, el mundo de la IA se vio sacudido cuando una startup china de IA relativamente desconocida, DeepSeek, lanzó un desafío con su modelo de razonamiento de lenguaje de código abierto innovador, DeepSeek R1. Este modelo no solo superó a gigantes como Meta, sino que lo hizo con una fracción del costo, se rumorea que con solo unos pocos millones de dólares. ¡Ese es el tipo de presupuesto que Meta podría gastar en solo un par de sus líderes de equipo de IA! Esta noticia puso a Meta en un frenesí, especialmente porque su último modelo Llama, versión 3.3, lanzado solo un mes antes, ya parecía algo obsoleto.
Avanzando hasta hoy, el fundador y CEO de Meta, Mark Zuckerberg, ha acudido a Instagram para anunciar el lanzamiento de la nueva serie Llama 4. Esta serie incluye el Llama 4 Maverick de 400 mil millones de parámetros y el Llama 4 Scout de 109 mil millones de parámetros, ambos disponibles para que los desarrolladores los descarguen y comiencen a experimentar de inmediato en llama.com y Hugging Face. También hay un adelanto de un modelo colosal de 2 billones de parámetros, Llama 4 Behemoth, aún en entrenamiento, sin fecha de lanzamiento a la vista.
Capacidades Multimodales y de Contexto Largo
Una de las características destacadas de estos nuevos modelos es su naturaleza multimodal. No se limitan al texto; también pueden manejar video e imágenes. Y vienen con ventanas de contexto increíblemente largas: 1 millón de tokens para Maverick y un asombroso 10 millones para Scout. Para ponerlo en perspectiva, ¡eso es como manejar hasta 1,500 y 15,000 páginas de texto de una vez! Imagina las posibilidades para campos como la medicina, la ciencia o la literatura, donde necesitas procesar y generar grandes cantidades de información.
Arquitectura de Mezcla de Expertos
Los tres modelos Llama 4 emplean la arquitectura de "mezcla de expertos (MoE)", una técnica que ha estado causando sensación, popularizada por empresas como OpenAI y Mistral. Este enfoque combina varios modelos más pequeños y especializados en un modelo más grande y eficiente. Cada modelo Llama 4 es una mezcla de 128 expertos diferentes, lo que significa que solo el experto necesario y uno compartido manejan cada token, haciendo que los modelos sean más rentables y rápidos de ejecutar. Meta presume que Llama 4 Maverick puede ejecutarse en un solo host Nvidia H100 DGX, lo que facilita su implementación.
Rentable y Accesible
Meta se enfoca en hacer estos modelos accesibles. Tanto Scout como Maverick están disponibles para autoalojamiento, e incluso han compartido algunas estimaciones de costos atractivas. Por ejemplo, el costo de inferencia para Llama 4 Maverick está entre $0.19 y $0.49 por millón de tokens, lo cual es una ganga en comparación con otros modelos propietarios como GPT-4o. Y si estás interesado en usar estos modelos a través de un proveedor de nube, Groq ya ha ofrecido precios competitivos.
Razonamiento Mejorado y MetaP
Estos modelos están diseñados con el razonamiento, la codificación y la resolución de problemas en mente. Meta ha utilizado algunas técnicas ingeniosas durante el entrenamiento para potenciar estas capacidades, como eliminar prompts fáciles y usar aprendizaje por refuerzo continuo con prompts cada vez más difíciles. También han presentado MetaP, una nueva técnica que permite establecer hiperparámetros en un modelo y aplicarlos a otros, ahorrando tiempo y dinero. Es un cambio radical, especialmente para entrenar monstruos como Behemoth, que utiliza 32K GPUs y procesa más de 30 billones de tokens.
Rendimiento y Comparaciones
Entonces, ¿cómo se comparan estos modelos? Zuckerberg ha sido claro sobre su visión de que la IA de código abierto lidere el camino, y Llama 4 es un gran paso en esa dirección. Aunque no establecen nuevos récords de rendimiento en todos los ámbitos, ciertamente están cerca de la cima de su clase. Por ejemplo, Llama 4 Behemoth supera a algunos pesos pesados en ciertos puntos de referencia, aunque aún está intentando alcanzar a DeepSeek R1 y la serie o1 de OpenAI en otros.
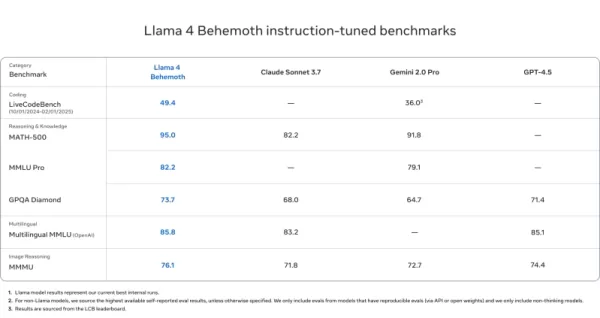
Llama 4 Behemoth
- Supera a GPT-4.5, Gemini 2.0 Pro y Claude Sonnet 3.7 en MATH-500 (95.0), GPQA Diamond (73.7) y MMLU Pro (82.2)
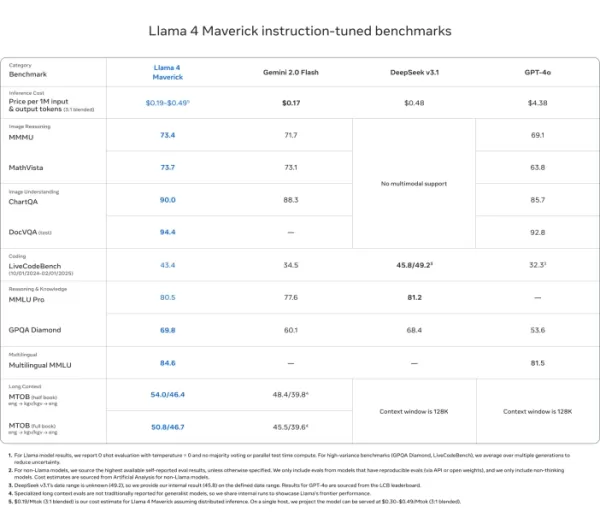
Llama 4 Maverick
- Supera a GPT-4o y Gemini 2.0 Flash en la mayoría de los puntos de referencia de razonamiento multimodal como ChartQA, DocVQA, MathVista y MMMU
- Competitivo con DeepSeek v3.1 mientras usa menos de la mitad de los parámetros activos
- Puntuaciones de referencia: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
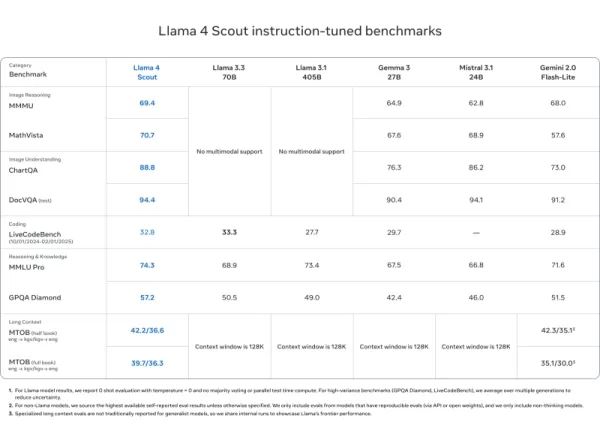
Llama 4 Scout
- Iguala o supera a modelos como Mistral 3.1, Gemini 2.0 Flash-Lite y Gemma 3 en DocVQA (94.4), MMLU Pro (74.3) y MathVista (70.7)
- Longitud de contexto de 10M de tokens sin igual, ideal para documentos largos y bases de código
Comparación con DeepSeek R1
Cuando se trata de las grandes ligas, Llama 4 Behemoth se mantiene firme pero no llega a destronar a DeepSeek R1 ni a la serie o1 de OpenAI. Está ligeramente por detrás en MATH-500 y MMLU, pero adelante en GPQA Diamond. Aun así, está claro que Llama 4 es un contendiente fuerte en el espacio del razonamiento.
Punto de Referencia Llama 4 Behemoth DeepSeek R1 OpenAI o1-1217 MATH-500 95.0 97.3 96.4 GPQA Diamond 73.7 71.5 75.7 MMLU 82.2 90.8 91.8
Seguridad y Neutralidad Política
Meta tampoco ha olvidado la seguridad. Han introducido herramientas como Llama Guard, Prompt Guard y CyberSecEval para mantener todo en orden. Y están haciendo un esfuerzo por reducir el sesgo político, buscando un enfoque más equilibrado, especialmente después del apoyo señalado de Zuckerberg a la política republicana tras las elecciones de 2024.
El Futuro con Llama 4
Con Llama 4, Meta está ampliando los límites de la eficiencia, la apertura y el rendimiento en la IA. Ya sea que busques construir asistentes de IA de nivel empresarial o sumergirte profundamente en la investigación de IA, Llama 4 ofrece opciones poderosas y flexibles que priorizan el razonamiento. Está claro que Meta está comprometido a hacer que la IA sea más accesible e impactante para todos.
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Recomendaciones de temas especiales relacionados
Negocio
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Recomendaciones de temas especiales relacionados
Negocio
 El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
El mejor software de optimización de precios con IA: realiza un seguimiento de la competencia y ajusta automáticamente los precios de la tienda
Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
 10 herramientas
10 herramientas
 xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
xix.ai
código
Los mejores revisores de código basados en IA: automatiza el cumplimiento de las normas de código limpio y refactoriza los archivos de repositorios heredados
Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai
Texto a voz
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

 comentario (30)
0/500
comentario (30)
0/500
![MichaelThomas]()
A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
![LarryWilliams]()
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
![CarlGonzalez]()
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
![BruceRoberts]()
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
![OwenLewis]()
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
![RogerSanchez]()
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀
En enero de 2025, el mundo de la IA se vio sacudido cuando una startup china de IA relativamente desconocida, DeepSeek, lanzó un desafío con su modelo de razonamiento de lenguaje de código abierto innovador, DeepSeek R1. Este modelo no solo superó a gigantes como Meta, sino que lo hizo con una fracción del costo, se rumorea que con solo unos pocos millones de dólares. ¡Ese es el tipo de presupuesto que Meta podría gastar en solo un par de sus líderes de equipo de IA! Esta noticia puso a Meta en un frenesí, especialmente porque su último modelo Llama, versión 3.3, lanzado solo un mes antes, ya parecía algo obsoleto.
Avanzando hasta hoy, el fundador y CEO de Meta, Mark Zuckerberg, ha acudido a Instagram para anunciar el lanzamiento de la nueva serie Llama 4. Esta serie incluye el Llama 4 Maverick de 400 mil millones de parámetros y el Llama 4 Scout de 109 mil millones de parámetros, ambos disponibles para que los desarrolladores los descarguen y comiencen a experimentar de inmediato en llama.com y Hugging Face. También hay un adelanto de un modelo colosal de 2 billones de parámetros, Llama 4 Behemoth, aún en entrenamiento, sin fecha de lanzamiento a la vista.
Capacidades Multimodales y de Contexto Largo
Una de las características destacadas de estos nuevos modelos es su naturaleza multimodal. No se limitan al texto; también pueden manejar video e imágenes. Y vienen con ventanas de contexto increíblemente largas: 1 millón de tokens para Maverick y un asombroso 10 millones para Scout. Para ponerlo en perspectiva, ¡eso es como manejar hasta 1,500 y 15,000 páginas de texto de una vez! Imagina las posibilidades para campos como la medicina, la ciencia o la literatura, donde necesitas procesar y generar grandes cantidades de información.
Arquitectura de Mezcla de Expertos
Los tres modelos Llama 4 emplean la arquitectura de "mezcla de expertos (MoE)", una técnica que ha estado causando sensación, popularizada por empresas como OpenAI y Mistral. Este enfoque combina varios modelos más pequeños y especializados en un modelo más grande y eficiente. Cada modelo Llama 4 es una mezcla de 128 expertos diferentes, lo que significa que solo el experto necesario y uno compartido manejan cada token, haciendo que los modelos sean más rentables y rápidos de ejecutar. Meta presume que Llama 4 Maverick puede ejecutarse en un solo host Nvidia H100 DGX, lo que facilita su implementación.
Rentable y Accesible
Meta se enfoca en hacer estos modelos accesibles. Tanto Scout como Maverick están disponibles para autoalojamiento, e incluso han compartido algunas estimaciones de costos atractivas. Por ejemplo, el costo de inferencia para Llama 4 Maverick está entre $0.19 y $0.49 por millón de tokens, lo cual es una ganga en comparación con otros modelos propietarios como GPT-4o. Y si estás interesado en usar estos modelos a través de un proveedor de nube, Groq ya ha ofrecido precios competitivos.
Razonamiento Mejorado y MetaP
Estos modelos están diseñados con el razonamiento, la codificación y la resolución de problemas en mente. Meta ha utilizado algunas técnicas ingeniosas durante el entrenamiento para potenciar estas capacidades, como eliminar prompts fáciles y usar aprendizaje por refuerzo continuo con prompts cada vez más difíciles. También han presentado MetaP, una nueva técnica que permite establecer hiperparámetros en un modelo y aplicarlos a otros, ahorrando tiempo y dinero. Es un cambio radical, especialmente para entrenar monstruos como Behemoth, que utiliza 32K GPUs y procesa más de 30 billones de tokens.
Rendimiento y Comparaciones
Entonces, ¿cómo se comparan estos modelos? Zuckerberg ha sido claro sobre su visión de que la IA de código abierto lidere el camino, y Llama 4 es un gran paso en esa dirección. Aunque no establecen nuevos récords de rendimiento en todos los ámbitos, ciertamente están cerca de la cima de su clase. Por ejemplo, Llama 4 Behemoth supera a algunos pesos pesados en ciertos puntos de referencia, aunque aún está intentando alcanzar a DeepSeek R1 y la serie o1 de OpenAI en otros.
Llama 4 Behemoth
- Supera a GPT-4.5, Gemini 2.0 Pro y Claude Sonnet 3.7 en MATH-500 (95.0), GPQA Diamond (73.7) y MMLU Pro (82.2)
Llama 4 Maverick
- Supera a GPT-4o y Gemini 2.0 Flash en la mayoría de los puntos de referencia de razonamiento multimodal como ChartQA, DocVQA, MathVista y MMMU
- Competitivo con DeepSeek v3.1 mientras usa menos de la mitad de los parámetros activos
- Puntuaciones de referencia: ChartQA (90.0), DocVQA (94.4), MMLU Pro (80.5)
Llama 4 Scout
- Iguala o supera a modelos como Mistral 3.1, Gemini 2.0 Flash-Lite y Gemma 3 en DocVQA (94.4), MMLU Pro (74.3) y MathVista (70.7)
- Longitud de contexto de 10M de tokens sin igual, ideal para documentos largos y bases de código
Comparación con DeepSeek R1
Cuando se trata de las grandes ligas, Llama 4 Behemoth se mantiene firme pero no llega a destronar a DeepSeek R1 ni a la serie o1 de OpenAI. Está ligeramente por detrás en MATH-500 y MMLU, pero adelante en GPQA Diamond. Aun así, está claro que Llama 4 es un contendiente fuerte en el espacio del razonamiento.
| Punto de Referencia | Llama 4 Behemoth | DeepSeek R1 | OpenAI o1-1217 |
|---|---|---|---|
| MATH-500 | 95.0 | 97.3 | 96.4 |
| GPQA Diamond | 73.7 | 71.5 | 75.7 |
| MMLU | 82.2 | 90.8 | 91.8 |
Seguridad y Neutralidad Política
Meta tampoco ha olvidado la seguridad. Han introducido herramientas como Llama Guard, Prompt Guard y CyberSecEval para mantener todo en orden. Y están haciendo un esfuerzo por reducir el sesgo político, buscando un enfoque más equilibrado, especialmente después del apoyo señalado de Zuckerberg a la política republicana tras las elecciones de 2024.
El Futuro con Llama 4
Con Llama 4, Meta está ampliando los límites de la eficiencia, la apertura y el rendimiento en la IA. Ya sea que busques construir asistentes de IA de nivel empresarial o sumergirte profundamente en la investigación de IA, Llama 4 ofrece opciones poderosas y flexibles que priorizan el razonamiento. Está claro que Meta está comprometido a hacer que la IA sea más accesible e impactante para todos.










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
Meta AI ya responde a los mensajes de los compradores en Facebook Marketplace
Facebook Marketplace presenta nuevas funciones de Meta AI, entre las que se incluyen respuestas automáticas a las consultas de los compradores, según anunció la empresa el jueves. La plataforma tambié
 OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf

Descubre el mejor software de optimización de precios con IA de 2026 en XIX.AI. Nuestra selección incluye herramientas de primera categoría y revolucionarias que analizan a la competencia y ajustan automáticamente los precios de tu tienda para maximizar los beneficios. Compara las opciones gratuitas con las de pago mediante pruebas reales. Aprovecha ahora tu ventaja competitiva en materia de precios.
10 herramientas
xix.ai

Descubre los mejores revisores de código con IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría y revolucionarias para automatizar el cumplimiento de las normas de código limpio y refactorizar archivos de repositorios heredados. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo tu ventaja con la IA.
10 herramientas
xix.ai

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

A 2 trillion parameter model? The environmental footprint of training these behemoths is starting to overshadow the hype for me. Meta's scale race is impressive, but I hope the next headline is about efficiency breakthroughs, not just size. 🌍💔
Honnêtement, l'IA est en train de devenir une course aux armements écologique... Meta sort un modèle de 2T paramètres, mais on ne parle jamais de l'énergie nécessaire pour l'entraîner. DeepSeek R1 montre qu'on peut être efficace sans monstre énergivore. Un peu de sobriété, peut-être ? 🌱
Ладно, Meta выпускает Llama 4 с 2 триллионами параметров... Но я до сих пор не могу заставить свою предыдущую модель правильно переводить рецепт борща! 😅 Интересно, эти «революционные» модели когда-нибудь действительно поймут культурные нюансы или просто станут мастерами генерации клише?
Meta qui continue la course aux armements avec ces modèles à 2T paramètres... mais franchement, c'est pas un peu excessif ? En janvier on avait déjà DeepSeek R1 qui montrait qu'on pouvait faire mieux avec moins. J'ai l'impression qu'ils cherchent juste à impressionner avec des chiffres gigantesques 🤔
Llama 4 sounds like a beast! That 10M token context window is wild—imagine analyzing entire books in one go. But can Meta keep up with DeepSeek’s efficiency? Excited for Behemoth, though! 🚀
Llama 4 정말 대단해요! 긴 문맥 스카우트와 마버릭 모델은 놀랍네요. 2T 파라미터의 괴물이 나올 걸 기대하고 있어요. 다만, 설정하는 게 좀 복잡해요. 그래도, AI의 미래가 밝아 보이네요! 🚀













