
















 Maison
MaisonDéfis de l'annotation par IA : Le mythe de l'étiquetage automatisé
La recherche en apprentissage automatique suppose souvent que l'IA peut améliorer les annotations des ensembles de données, en particulier les légendes d'images pour les modèles vision-langage (VLM), pour réduire les coûts et les besoins de supervision humaine.
Cela rappelle le mème des années 2000 « télécharger plus de RAM », qui se moquait de l'idée que le logiciel peut résoudre les limites matérielles.
Pourtant, la qualité de l'annotation est souvent négligée, éclipsée par l'engouement pour les nouveaux modèles d'IA, malgré son rôle crucial dans les pipelines d'apprentissage automatique.
La capacité de l'IA à identifier et reproduire des motifs dépend d'annotations humaines de haute qualité et cohérentes — étiquettes et descriptions créées par des personnes prenant des décisions subjectives dans des contextes imparfaits.
Les systèmes visant à imiter le comportement des annotateurs pour remplacer les humains et scaler l'étiquetage précis peinent face à des données non incluses dans les exemples fournis par les humains. La similarité n'équivaut pas à l'équivalence, et la cohérence inter-domaine reste insaisissable en vision par ordinateur.
En fin de compte, le jugement humain définit les données qui façonnent les systèmes d'IA.
Solutions RAG
Jusqu'à récemment, les erreurs dans les annotations des ensembles de données étaient tolérées comme des compromis mineurs étant donné les résultats imparfaits mais commercialisables de l'IA générative.
Une étude de Singapour de 2025 a révélé que les hallucinations — l'IA générant des sorties fausses — sont inhérentes à la conception de ces systèmes.
Les agents basés sur RAG, qui vérifient les faits via des recherches sur Internet, gagnent en popularité dans la recherche et les applications commerciales, mais augmentent les coûts de ressources et les délais de requête. Les nouvelles informations appliquées aux modèles entraînés manquent de la profondeur des connexions natives des modèles.
Les annotations défectueuses compromettent les performances des modèles, et améliorer leur qualité, bien qu'imparfaite en raison de la subjectivité humaine, est crucial.
Perspectives RePOPE
Une étude allemande expose les défauts des anciens ensembles de données, en se concentrant sur la précision des légendes d'images dans des benchmarks comme MSCOCO. Elle révèle comment les erreurs d'étiquetage faussent les évaluations des hallucinations dans les modèles vision-langage.

Exemples d'une étude récente montrant une identification incorrecte des objets dans les légendes de l'ensemble de données MSCOCO. Les révisions manuelles du benchmark POPE soulignent les écueils de la réduction des coûts dans la curation d'annotations. Source : https://arxiv.org/pdf/2504.15707
Considérez une IA évaluant une image de scène de rue pour un vélo. Si le modèle dit oui mais que l'ensemble de données dit non, il est marqué comme erroné. Pourtant, si un vélo est visiblement présent mais manqué dans l'annotation, le modèle est correct, et l'ensemble de données est défectueux. Ces erreurs faussent la précision du modèle et les métriques d'hallucination.
Des annotations incorrectes ou vagues peuvent faire paraître des modèles précis comme erronés ou des modèles défectueux comme fiables, compliquant le diagnostic des hallucinations et le classement des modèles.
L'étude revisite le benchmark d'évaluation par sondage d'objets (POPE), qui teste la capacité des modèles vision-langage à identifier des objets dans les images en utilisant les étiquettes MSCOCO.
POPE reformule l'hallucination comme une tâche de classification oui/non, demandant aux modèles si des objets spécifiques apparaissent dans les images, en utilisant des invites comme « Y a-t-il un dans l'image ? »

Exemples d'hallucination d'objets dans les modèles vision-langage. Les étiquettes en gras marquent les objets des annotations originales ; les étiquettes rouges soulignent les objets hallucinés par les modèles. L'exemple de gauche utilise une évaluation traditionnelle, tandis que les trois de droite proviennent de variantes POPE. Source : https://aclanthology.org/2023.emnlp-main.20.pdf
Les objets de vérité terrain (réponse : Oui) sont jumelés avec des objets inexistants (réponse : Non), sélectionnés aléatoirement, fréquemment, ou en fonction de la co-occurrence. Cela permet une évaluation stable des hallucinations, indépendante des invites, sans analyse complexe des légendes.
L'étude, RePOPE : Impact des erreurs d'annotation sur le benchmark POPE, revérifie les étiquettes MSCOCO et trouve de nombreuses erreurs ou ambiguïtés.

Images de l'ensemble de données MSCOCO de 2014. Source : https://arxiv.org/pdf/1405.0312
Ces erreurs modifient les classements des modèles, certains des meilleurs performeurs chutant lorsqu'évalués avec des étiquettes corrigées.
Les tests sur des modèles vision-langage à poids ouvert utilisant le POPE original et le RePOPE relabellisé montrent des changements significatifs de classement, en particulier dans les scores F1, avec plusieurs modèles en baisse de performance.
L'étude soutient que les erreurs d'annotation masquent les véritables hallucinations des modèles, présentant RePOPE comme un outil d'évaluation plus précis.

Exemples de l'étude montrant que les légendes POPE manquent des objets subtils, comme une personne près d'une cabine de tram ou une chaise obscurcie par un joueur de tennis.
Méthodologie et tests
Les chercheurs ont relabellisé les annotations MSCOCO avec deux réviseurs humains par instance. Les cas ambigus, comme ceux ci-dessous, ont été exclus des tests.

Cas ambigus dans POPE avec des étiquettes floues, comme des ours en peluche comme ours ou des motos comme vélos, exclus de RePOPE en raison de classifications subjectives et d'incohérences MSCOCO.
L'article note :
« Les annotateurs originaux ont négligé les personnes en arrière-plan ou derrière une vitre, les chaises obscurcies par un joueur de tennis, ou une carotte floue dans une salade de chou. »
« Les étiquettes MSCOCO incohérentes, comme classer un ours en peluche comme ours ou une moto comme vélo, proviennent de définitions variables des objets, marquant ces cas comme ambigus. »
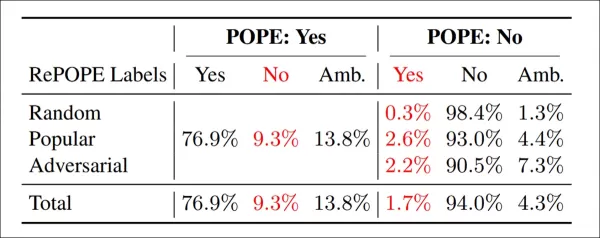
Résultats de la ré-annotation : Sur toutes les variantes POPE, 9,3 % des étiquettes « Oui » étaient incorrectes, 13,8 % ambiguës ; 1,7 % des étiquettes « Non » étaient mal étiquetées, 4,3 % ambiguës.
L'équipe a testé des modèles à poids ouvert, y compris InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B et PaliGemma2, sur POPE et RePOPE.
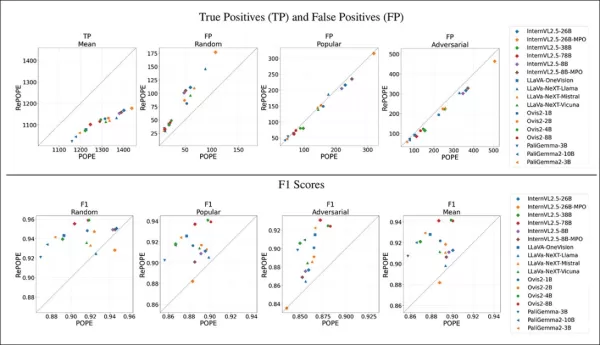
Les résultats montrent que les erreurs d'étiquettes originales ont causé une baisse des vrais positifs. Les faux positifs ont doublé sur le sous-ensemble aléatoire, sont restés stables sur le sous-ensemble populaire, et ont légèrement diminué sur le sous-ensemble adversarial. La relabellisation a modifié les classements F1, avec des modèles comme Ovis2-4B et -8B en hausse.
Les graphiques montrent que les vrais positifs ont chuté pour tous les modèles, car les réponses correctes étaient souvent basées sur des étiquettes erronées, tandis que les faux positifs variaient.
Dans le sous-ensemble aléatoire de POPE, les faux positifs ont presque doublé, révélant des objets présents mais manqués dans les annotations originales. Dans le sous-ensemble adversarial, les faux positifs ont diminué, car les objets absents étaient souvent non étiquetés mais présents.
La précision et le rappel ont été affectés, mais les classements des modèles sont restés stables. Les scores F1, métrique clé de POPE, ont changé de manière significative, avec des modèles de tête comme InternVL2.5-8B en baisse et Ovis2-4B et -8B en hausse.
Les scores de précision étaient moins fiables en raison d'exemples positifs et négatifs inégaux dans l'ensemble de données corrigé.
L'étude souligne la nécessité d'annotations de haute qualité et partage les étiquettes corrigées sur GitHub, notant que RePOPE seul ne résout pas complètement la saturation des benchmarks, car les modèles obtiennent encore plus de 90 % en vrais positifs et négatifs. Des benchmarks supplémentaires comme DASH-B sont recommandés.
Conclusion
Cette étude, réalisable grâce à la petite taille de l'ensemble de données, met en lumière les défis de la mise à l'échelle vers des ensembles de données hyperscale, où isoler des données représentatives est difficile et peut fausser les résultats.
Même si cela est réalisable, les méthodes actuelles soulignent le besoin d'annotations humaines meilleures et plus nombreuses.
« Meilleur » et « plus » posent des défis distincts. Les plateformes à faible coût comme Amazon Mechanical Turk risquent des annotations de mauvaise qualité, tandis que l'externalisation dans différentes régions peut ne pas correspondre à l'usage prévu du modèle.
Cela reste un problème central et non résolu dans l'économie de l'apprentissage automatique.
Publié pour la première fois le mercredi 23 avril 2025
Article connexe
 Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté
Recommandations de sujets spéciaux liés
Création de bande dessinée
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
 15 outils
15 outils
 xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai
Éducation et apprentissage
Meilleurs mentors en science des données et intelligence artificielle : maîtrise de SQL, Pandas et des workflows d'apprentissage automatique
Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

 commentaires (2)
commentaires (2)
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
La recherche en apprentissage automatique suppose souvent que l'IA peut améliorer les annotations des ensembles de données, en particulier les légendes d'images pour les modèles vision-langage (VLM), pour réduire les coûts et les besoins de supervision humaine.
Cela rappelle le mème des années 2000 « télécharger plus de RAM », qui se moquait de l'idée que le logiciel peut résoudre les limites matérielles.
Pourtant, la qualité de l'annotation est souvent négligée, éclipsée par l'engouement pour les nouveaux modèles d'IA, malgré son rôle crucial dans les pipelines d'apprentissage automatique.
La capacité de l'IA à identifier et reproduire des motifs dépend d'annotations humaines de haute qualité et cohérentes — étiquettes et descriptions créées par des personnes prenant des décisions subjectives dans des contextes imparfaits.
Les systèmes visant à imiter le comportement des annotateurs pour remplacer les humains et scaler l'étiquetage précis peinent face à des données non incluses dans les exemples fournis par les humains. La similarité n'équivaut pas à l'équivalence, et la cohérence inter-domaine reste insaisissable en vision par ordinateur.
En fin de compte, le jugement humain définit les données qui façonnent les systèmes d'IA.
Solutions RAG
Jusqu'à récemment, les erreurs dans les annotations des ensembles de données étaient tolérées comme des compromis mineurs étant donné les résultats imparfaits mais commercialisables de l'IA générative.
Une étude de Singapour de 2025 a révélé que les hallucinations — l'IA générant des sorties fausses — sont inhérentes à la conception de ces systèmes.
Les agents basés sur RAG, qui vérifient les faits via des recherches sur Internet, gagnent en popularité dans la recherche et les applications commerciales, mais augmentent les coûts de ressources et les délais de requête. Les nouvelles informations appliquées aux modèles entraînés manquent de la profondeur des connexions natives des modèles.
Les annotations défectueuses compromettent les performances des modèles, et améliorer leur qualité, bien qu'imparfaite en raison de la subjectivité humaine, est crucial.
Perspectives RePOPE
Une étude allemande expose les défauts des anciens ensembles de données, en se concentrant sur la précision des légendes d'images dans des benchmarks comme MSCOCO. Elle révèle comment les erreurs d'étiquetage faussent les évaluations des hallucinations dans les modèles vision-langage.
Exemples d'une étude récente montrant une identification incorrecte des objets dans les légendes de l'ensemble de données MSCOCO. Les révisions manuelles du benchmark POPE soulignent les écueils de la réduction des coûts dans la curation d'annotations. Source : https://arxiv.org/pdf/2504.15707
Considérez une IA évaluant une image de scène de rue pour un vélo. Si le modèle dit oui mais que l'ensemble de données dit non, il est marqué comme erroné. Pourtant, si un vélo est visiblement présent mais manqué dans l'annotation, le modèle est correct, et l'ensemble de données est défectueux. Ces erreurs faussent la précision du modèle et les métriques d'hallucination.
Des annotations incorrectes ou vagues peuvent faire paraître des modèles précis comme erronés ou des modèles défectueux comme fiables, compliquant le diagnostic des hallucinations et le classement des modèles.
L'étude revisite le benchmark d'évaluation par sondage d'objets (POPE), qui teste la capacité des modèles vision-langage à identifier des objets dans les images en utilisant les étiquettes MSCOCO.
POPE reformule l'hallucination comme une tâche de classification oui/non, demandant aux modèles si des objets spécifiques apparaissent dans les images, en utilisant des invites comme « Y a-t-il un
Exemples d'hallucination d'objets dans les modèles vision-langage. Les étiquettes en gras marquent les objets des annotations originales ; les étiquettes rouges soulignent les objets hallucinés par les modèles. L'exemple de gauche utilise une évaluation traditionnelle, tandis que les trois de droite proviennent de variantes POPE. Source : https://aclanthology.org/2023.emnlp-main.20.pdf
Les objets de vérité terrain (réponse : Oui) sont jumelés avec des objets inexistants (réponse : Non), sélectionnés aléatoirement, fréquemment, ou en fonction de la co-occurrence. Cela permet une évaluation stable des hallucinations, indépendante des invites, sans analyse complexe des légendes.
L'étude, RePOPE : Impact des erreurs d'annotation sur le benchmark POPE, revérifie les étiquettes MSCOCO et trouve de nombreuses erreurs ou ambiguïtés.
Images de l'ensemble de données MSCOCO de 2014. Source : https://arxiv.org/pdf/1405.0312
Ces erreurs modifient les classements des modèles, certains des meilleurs performeurs chutant lorsqu'évalués avec des étiquettes corrigées.
Les tests sur des modèles vision-langage à poids ouvert utilisant le POPE original et le RePOPE relabellisé montrent des changements significatifs de classement, en particulier dans les scores F1, avec plusieurs modèles en baisse de performance.
L'étude soutient que les erreurs d'annotation masquent les véritables hallucinations des modèles, présentant RePOPE comme un outil d'évaluation plus précis.
Exemples de l'étude montrant que les légendes POPE manquent des objets subtils, comme une personne près d'une cabine de tram ou une chaise obscurcie par un joueur de tennis.
Méthodologie et tests
Les chercheurs ont relabellisé les annotations MSCOCO avec deux réviseurs humains par instance. Les cas ambigus, comme ceux ci-dessous, ont été exclus des tests.
Cas ambigus dans POPE avec des étiquettes floues, comme des ours en peluche comme ours ou des motos comme vélos, exclus de RePOPE en raison de classifications subjectives et d'incohérences MSCOCO.
L'article note :
« Les annotateurs originaux ont négligé les personnes en arrière-plan ou derrière une vitre, les chaises obscurcies par un joueur de tennis, ou une carotte floue dans une salade de chou. »
« Les étiquettes MSCOCO incohérentes, comme classer un ours en peluche comme ours ou une moto comme vélo, proviennent de définitions variables des objets, marquant ces cas comme ambigus. »
Résultats de la ré-annotation : Sur toutes les variantes POPE, 9,3 % des étiquettes « Oui » étaient incorrectes, 13,8 % ambiguës ; 1,7 % des étiquettes « Non » étaient mal étiquetées, 4,3 % ambiguës.
L'équipe a testé des modèles à poids ouvert, y compris InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B et PaliGemma2, sur POPE et RePOPE.
Les résultats montrent que les erreurs d'étiquettes originales ont causé une baisse des vrais positifs. Les faux positifs ont doublé sur le sous-ensemble aléatoire, sont restés stables sur le sous-ensemble populaire, et ont légèrement diminué sur le sous-ensemble adversarial. La relabellisation a modifié les classements F1, avec des modèles comme Ovis2-4B et -8B en hausse.
Les graphiques montrent que les vrais positifs ont chuté pour tous les modèles, car les réponses correctes étaient souvent basées sur des étiquettes erronées, tandis que les faux positifs variaient.
Dans le sous-ensemble aléatoire de POPE, les faux positifs ont presque doublé, révélant des objets présents mais manqués dans les annotations originales. Dans le sous-ensemble adversarial, les faux positifs ont diminué, car les objets absents étaient souvent non étiquetés mais présents.
La précision et le rappel ont été affectés, mais les classements des modèles sont restés stables. Les scores F1, métrique clé de POPE, ont changé de manière significative, avec des modèles de tête comme InternVL2.5-8B en baisse et Ovis2-4B et -8B en hausse.
Les scores de précision étaient moins fiables en raison d'exemples positifs et négatifs inégaux dans l'ensemble de données corrigé.
L'étude souligne la nécessité d'annotations de haute qualité et partage les étiquettes corrigées sur GitHub, notant que RePOPE seul ne résout pas complètement la saturation des benchmarks, car les modèles obtiennent encore plus de 90 % en vrais positifs et négatifs. Des benchmarks supplémentaires comme DASH-B sont recommandés.
Conclusion
Cette étude, réalisable grâce à la petite taille de l'ensemble de données, met en lumière les défis de la mise à l'échelle vers des ensembles de données hyperscale, où isoler des données représentatives est difficile et peut fausser les résultats.
Même si cela est réalisable, les méthodes actuelles soulignent le besoin d'annotations humaines meilleures et plus nombreuses.
« Meilleur » et « plus » posent des défis distincts. Les plateformes à faible coût comme Amazon Mechanical Turk risquent des annotations de mauvaise qualité, tandis que l'externalisation dans différentes régions peut ne pas correspondre à l'usage prévu du modèle.
Cela reste un problème central et non résolu dans l'économie de l'apprentissage automatique.
Publié pour la première fois le mercredi 23 avril 2025










 Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
Principal investisseur de Suno : la suppression des publications ne comblera pas les lacunes en matière de poursuites pour violation du droit d'auteur
La plateforme de génération musicale par IA très attendue, Suno, est confrontée à une rude bataille en matière de droits d'auteur, et une remarque sans détours de son principal investisseur pourrait b
 Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
Claude Opus 4.7 fait son entrée sur le marché en misant davantage sur la fiabilité que sur l'intelligence
Anthropic a maintenu un rythme soutenu cette année, en déployant de nouvelles fonctionnalités presque tous les deux jours. Le très attendu Claude Opus 4.7 vient d'être officiellement lancé, et il est
 Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté
Haier lance le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde, pesant seulement 1,75 kg
Le groupe Haier a présenté le robot exosquelette sportif doté d'une intelligence artificielle le plus léger au monde : le Haier Exoskeleton Robot W3. Ce lancement établit un nouveau record de légèreté

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs mentors en sciences des données et en intelligence artificielle pour 2026 afin de maîtriser SQL, Pandas et les workflows d'apprentissage automatique. Explorez notre sélection soigneusement élaborée sur XIX.AI pour bénéficier d'une guidance puissante et révolutionnaire. Comparez les options gratuites et payantes en tenant compte de perspectives pratiques. Développez rapidement vos compétences en sciences des données.
10 outils
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













