
















 Lar
LarDesafios de Anotação de IA: O Mito da Rotulagem Automatizada
A pesquisa em aprendizado de máquina frequentemente presume que a IA pode melhorar as anotações de conjuntos de dados, especialmente legendas de imagens para modelos de visão-linguagem (VLMs), para reduzir custos e aliviar a carga de supervisão humana.
Isso ecoa o meme do início dos anos 2000 'baixar mais RAM', zombando da ideia de que o software pode corrigir limitações de hardware.
No entanto, a qualidade da anotação é muitas vezes negligenciada, ofuscada pelo entusiasmo em torno de novos modelos de IA, apesar de seu papel crítico nos pipelines de aprendizado de máquina.
A capacidade da IA de identificar e replicar padrões depende de anotações humanas de alta qualidade e consistentes—rótulos e descrições criados por pessoas tomando decisões subjetivas em cenários imperfeitos.
Sistemas que tentam imitar o comportamento de anotadores para substituir humanos e escalar a rotulagem precisa enfrentam dificuldades quando confrontados com dados não incluídos nos exemplos fornecidos por humanos. Similaridade não equivale a equivalência, e a consistência entre domínios permanece elusiva na visão computacional.
Em última análise, o julgamento humano define os dados que moldam os sistemas de IA.
Soluções RAG
Até recentemente, erros nas anotações de conjuntos de dados eram tolerados como compensações menores, dado os resultados imperfeitos, mas comercializáveis, da IA generativa.
Um estudo de Cingapura de 2025 descobriu que alucinações—a IA gerando saídas falsas—são inerentes ao design desses sistemas.
Agentes baseados em RAG, que verificam fatos por meio de pesquisas na internet, estão ganhando tração em aplicações de pesquisa e comerciais, mas aumentam os custos de recursos e os atrasos nas consultas. Novas informações aplicadas a modelos treinados carecem da profundidade das conexões nativas do modelo.
Anotações falhas comprometem o desempenho do modelo, e melhorar sua qualidade, embora imperfeita devido à subjetividade humana, é crucial.
Insights do RePOPE
Um estudo alemão expõe falhas em conjuntos de dados mais antigos, focando na precisão das legendas de imagens em benchmarks como MSCOCO. Ele revela como erros de rótulos distorcem avaliações de alucinações em modelos de visão-linguagem.

Exemplos de um estudo recente mostrando identificação incorreta de objetos nas legendas do conjunto de dados MSCOCO. Revisões manuais do benchmark POPE destacam as armadilhas de cortar custos na curadoria de anotações. Fonte: https://arxiv.org/pdf/2504.15707
Considere uma IA avaliando uma imagem de cena de rua em busca de uma bicicleta. Se o modelo diz sim, mas o conjunto de dados afirma não, ele é marcado como errado. No entanto, se uma bicicleta está visivelmente presente, mas foi omitida na anotação, o modelo está correto, e o conjunto de dados está falho. Esses erros distorcem a precisão do modelo e as métricas de alucinação.
Anotações incorretas ou vagas podem fazer modelos precisos parecerem propensos a erros ou modelos defeituosos parecerem confiáveis, complicando o diagnóstico de alucinações e a classificação de modelos.
O estudo revisita o benchmark de Avaliação de Sondagem de Objetos Baseada em Votação (POPE), que testa a capacidade dos modelos de visão-linguagem de identificar objetos em imagens usando rótulos MSCOCO.
O POPE reformula a alucinação como uma tarefa de classificação sim/não, perguntando aos modelos se objetos específicos aparecem nas imagens, usando prompts como “Há um na imagem?”

Exemplos de alucinação de objetos em modelos de visão-linguagem. Rótulos em negrito marcam objetos nas anotações originais; rótulos vermelhos destacam objetos alucinados pelo modelo. O exemplo à esquerda usa avaliação tradicional, enquanto os três à direita vêm de variantes do POPE. Fonte: https://aclanthology.org/2023.emnlp-main.20.pdf
Objetos de referência (resposta: Sim) são pareados com objetos inexistentes (resposta: Não), selecionados aleatoriamente, frequentemente ou com base em coocorrência. Isso permite uma avaliação de alucinação estável, independente de prompts, sem análise complexa de legendas.
O estudo, RePOPE: Impacto de Erros de Anotação no Benchmark POPE, verifica novamente os rótulos MSCOCO e encontra muitos erros ou ambiguidades.

Imagens do conjunto de dados MSCOCO de 2014. Fonte: https://arxiv.org/pdf/1405.0312
Esses erros alteram as classificações de modelos, com alguns dos melhores desempenhos caindo quando avaliados contra rótulos corrigidos.
Testes em modelos de visão-linguagem de peso aberto usando o POPE original e o RePOPE re-rotulado mostram mudanças significativas nas classificações, especialmente nos escores F1, com vários modelos caindo em desempenho.
O estudo argumenta que erros de anotação escondem a verdadeira alucinação do modelo, apresentando o RePOPE como uma ferramenta de avaliação mais precisa.

Exemplos do estudo mostrando legendas do POPE que perderam objetos sutis, como uma pessoa perto da cabine de um bonde ou uma cadeira obscurecida por um jogador de tênis.
Metodologia e Testes
Os pesquisadores re-rotularam as anotações MSCOCO com dois revisores humanos por instância. Casos ambíguos, como os abaixo, foram excluídos dos testes.

Casos ambíguos no POPE com rótulos pouco claros, como ursos de pelúcia como ursos ou motocicletas como bicicletas, excluídos do RePOPE devido a classificações subjetivas e inconsistências do MSCOCO.
O artigo observa:
“Os anotadores originais ignoraram pessoas ao fundo ou atrás de vidros, cadeiras obscurecidas por um jogador de tênis, ou uma cenoura fraca em salada de repolho.”
“Rótulos inconsistentes do MSCOCO, como classificar um urso de pelúcia como urso ou uma motocicleta como bicicleta, derivam de definições de objetos variadas, marcando esses casos como ambíguos.”
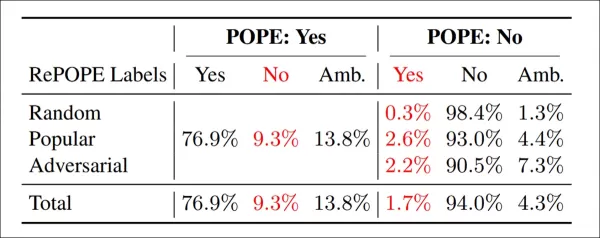
Resultados da re-anotação: Entre as variantes do POPE, 9,3% dos rótulos 'Sim' estavam incorretos, 13,8% ambíguos; 1,7% dos rótulos 'Não' estavam errados, 4,3% ambíguos.
A equipe testou modelos de peso aberto, incluindo InternVL2.5, LLaVA-NeXT, Vicuna,Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B e PaliGemma2, em POPE e RePOPE.
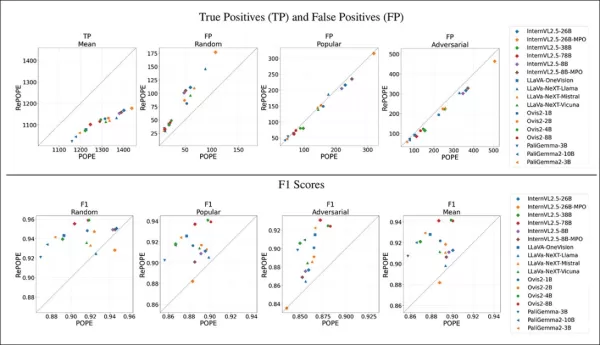
Resultados mostram que erros de rótulos originais causaram uma queda nos verdadeiros positivos. Falsos positivos dobraram no subconjunto aleatório, permaneceram estáveis no subconjunto popular e diminuíram ligeiramente no subconjunto adversário. A re-rotulagem mudou as classificações F1, com modelos como Ovis2-4B e -8B subindo ao topo.
Gráficos mostram que os verdadeiros positivos caíram entre os modelos, já que respostas corretas muitas vezes se baseavam em rótulos defeituosos, enquanto os falsos positivos variaram.
No subconjunto aleatório do POPE, os falsos positivos quase dobraram, revelando objetos presentes, mas perdidos nas anotações originais. No subconjunto adversário, os falsos positivos caíram, pois objetos ausentes muitas vezes não foram rotulados, mas estavam presentes.
Precisão e revocação foram afetadas, mas as classificações de modelos permaneceram estáveis. Os escores F1, métrica chave do POPE, mudaram significativamente, com modelos de ponta como InternVL2.5-8B caindo e Ovis2-4B e -8B subindo.
Os escores de precisão foram menos confiáveis devido a exemplos positivos e negativos desiguais no conjunto de dados corrigido.
O estudo enfatiza a necessidade de anotações de alta qualidade e compartilha rótulos corrigidos no GitHub, observando que o RePOPE sozinho não aborda completamente a saturação do benchmark, pois os modelos ainda pontuam acima de 90% em verdadeiros positivos e negativos. Benchmarks adicionais como DASH-B são recomendados.
Conclusão
Este estudo, viável devido ao pequeno conjunto de dados, destaca os desafios de escalar para conjuntos de dados em hiperescala, onde isolar dados representativos é difícil e pode distorcer resultados.
Mesmo que viável, os métodos atuais apontam para a necessidade de uma anotação humana melhor e mais extensa.
‘Melhor’ e ‘mais’ apresentam desafios distintos. Plataformas de baixo custo como Amazon Mechanical Turk arriscam anotações de baixa qualidade, enquanto a terceirização para diferentes regiões pode não se alinhar com o caso de uso pretendido do modelo.
Isso permanece um problema central e não resolvido na economia do aprendizado de máquina.
Artigo relacionado
 A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Recomendações de tópicos especiais relacionados
Negócios
A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Recomendações de tópicos especiais relacionados
Negócios
 Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
 10 ferramentas
10 ferramentas
 xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai
chatbot
Os melhores treinadores de paquera e conversação com IA: melhore seu carisma social e sua autoconfiança em tempo real
Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

 Comentários (2)
Comentários (2)
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
A pesquisa em aprendizado de máquina frequentemente presume que a IA pode melhorar as anotações de conjuntos de dados, especialmente legendas de imagens para modelos de visão-linguagem (VLMs), para reduzir custos e aliviar a carga de supervisão humana.
Isso ecoa o meme do início dos anos 2000 'baixar mais RAM', zombando da ideia de que o software pode corrigir limitações de hardware.
No entanto, a qualidade da anotação é muitas vezes negligenciada, ofuscada pelo entusiasmo em torno de novos modelos de IA, apesar de seu papel crítico nos pipelines de aprendizado de máquina.
A capacidade da IA de identificar e replicar padrões depende de anotações humanas de alta qualidade e consistentes—rótulos e descrições criados por pessoas tomando decisões subjetivas em cenários imperfeitos.
Sistemas que tentam imitar o comportamento de anotadores para substituir humanos e escalar a rotulagem precisa enfrentam dificuldades quando confrontados com dados não incluídos nos exemplos fornecidos por humanos. Similaridade não equivale a equivalência, e a consistência entre domínios permanece elusiva na visão computacional.
Em última análise, o julgamento humano define os dados que moldam os sistemas de IA.
Soluções RAG
Até recentemente, erros nas anotações de conjuntos de dados eram tolerados como compensações menores, dado os resultados imperfeitos, mas comercializáveis, da IA generativa.
Um estudo de Cingapura de 2025 descobriu que alucinações—a IA gerando saídas falsas—são inerentes ao design desses sistemas.
Agentes baseados em RAG, que verificam fatos por meio de pesquisas na internet, estão ganhando tração em aplicações de pesquisa e comerciais, mas aumentam os custos de recursos e os atrasos nas consultas. Novas informações aplicadas a modelos treinados carecem da profundidade das conexões nativas do modelo.
Anotações falhas comprometem o desempenho do modelo, e melhorar sua qualidade, embora imperfeita devido à subjetividade humana, é crucial.
Insights do RePOPE
Um estudo alemão expõe falhas em conjuntos de dados mais antigos, focando na precisão das legendas de imagens em benchmarks como MSCOCO. Ele revela como erros de rótulos distorcem avaliações de alucinações em modelos de visão-linguagem.
Exemplos de um estudo recente mostrando identificação incorreta de objetos nas legendas do conjunto de dados MSCOCO. Revisões manuais do benchmark POPE destacam as armadilhas de cortar custos na curadoria de anotações. Fonte: https://arxiv.org/pdf/2504.15707
Considere uma IA avaliando uma imagem de cena de rua em busca de uma bicicleta. Se o modelo diz sim, mas o conjunto de dados afirma não, ele é marcado como errado. No entanto, se uma bicicleta está visivelmente presente, mas foi omitida na anotação, o modelo está correto, e o conjunto de dados está falho. Esses erros distorcem a precisão do modelo e as métricas de alucinação.
Anotações incorretas ou vagas podem fazer modelos precisos parecerem propensos a erros ou modelos defeituosos parecerem confiáveis, complicando o diagnóstico de alucinações e a classificação de modelos.
O estudo revisita o benchmark de Avaliação de Sondagem de Objetos Baseada em Votação (POPE), que testa a capacidade dos modelos de visão-linguagem de identificar objetos em imagens usando rótulos MSCOCO.
O POPE reformula a alucinação como uma tarefa de classificação sim/não, perguntando aos modelos se objetos específicos aparecem nas imagens, usando prompts como “Há um
Exemplos de alucinação de objetos em modelos de visão-linguagem. Rótulos em negrito marcam objetos nas anotações originais; rótulos vermelhos destacam objetos alucinados pelo modelo. O exemplo à esquerda usa avaliação tradicional, enquanto os três à direita vêm de variantes do POPE. Fonte: https://aclanthology.org/2023.emnlp-main.20.pdf
Objetos de referência (resposta: Sim) são pareados com objetos inexistentes (resposta: Não), selecionados aleatoriamente, frequentemente ou com base em coocorrência. Isso permite uma avaliação de alucinação estável, independente de prompts, sem análise complexa de legendas.
O estudo, RePOPE: Impacto de Erros de Anotação no Benchmark POPE, verifica novamente os rótulos MSCOCO e encontra muitos erros ou ambiguidades.
Imagens do conjunto de dados MSCOCO de 2014. Fonte: https://arxiv.org/pdf/1405.0312
Esses erros alteram as classificações de modelos, com alguns dos melhores desempenhos caindo quando avaliados contra rótulos corrigidos.
Testes em modelos de visão-linguagem de peso aberto usando o POPE original e o RePOPE re-rotulado mostram mudanças significativas nas classificações, especialmente nos escores F1, com vários modelos caindo em desempenho.
O estudo argumenta que erros de anotação escondem a verdadeira alucinação do modelo, apresentando o RePOPE como uma ferramenta de avaliação mais precisa.
Exemplos do estudo mostrando legendas do POPE que perderam objetos sutis, como uma pessoa perto da cabine de um bonde ou uma cadeira obscurecida por um jogador de tênis.
Metodologia e Testes
Os pesquisadores re-rotularam as anotações MSCOCO com dois revisores humanos por instância. Casos ambíguos, como os abaixo, foram excluídos dos testes.
Casos ambíguos no POPE com rótulos pouco claros, como ursos de pelúcia como ursos ou motocicletas como bicicletas, excluídos do RePOPE devido a classificações subjetivas e inconsistências do MSCOCO.
O artigo observa:
“Os anotadores originais ignoraram pessoas ao fundo ou atrás de vidros, cadeiras obscurecidas por um jogador de tênis, ou uma cenoura fraca em salada de repolho.”
“Rótulos inconsistentes do MSCOCO, como classificar um urso de pelúcia como urso ou uma motocicleta como bicicleta, derivam de definições de objetos variadas, marcando esses casos como ambíguos.”
Resultados da re-anotação: Entre as variantes do POPE, 9,3% dos rótulos 'Sim' estavam incorretos, 13,8% ambíguos; 1,7% dos rótulos 'Não' estavam errados, 4,3% ambíguos.
A equipe testou modelos de peso aberto, incluindo InternVL2.5, LLaVA-NeXT, Vicuna,Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B e PaliGemma2, em POPE e RePOPE.
Resultados mostram que erros de rótulos originais causaram uma queda nos verdadeiros positivos. Falsos positivos dobraram no subconjunto aleatório, permaneceram estáveis no subconjunto popular e diminuíram ligeiramente no subconjunto adversário. A re-rotulagem mudou as classificações F1, com modelos como Ovis2-4B e -8B subindo ao topo.
Gráficos mostram que os verdadeiros positivos caíram entre os modelos, já que respostas corretas muitas vezes se baseavam em rótulos defeituosos, enquanto os falsos positivos variaram.
No subconjunto aleatório do POPE, os falsos positivos quase dobraram, revelando objetos presentes, mas perdidos nas anotações originais. No subconjunto adversário, os falsos positivos caíram, pois objetos ausentes muitas vezes não foram rotulados, mas estavam presentes.
Precisão e revocação foram afetadas, mas as classificações de modelos permaneceram estáveis. Os escores F1, métrica chave do POPE, mudaram significativamente, com modelos de ponta como InternVL2.5-8B caindo e Ovis2-4B e -8B subindo.
Os escores de precisão foram menos confiáveis devido a exemplos positivos e negativos desiguais no conjunto de dados corrigido.
O estudo enfatiza a necessidade de anotações de alta qualidade e compartilha rótulos corrigidos no GitHub, observando que o RePOPE sozinho não aborda completamente a saturação do benchmark, pois os modelos ainda pontuam acima de 90% em verdadeiros positivos e negativos. Benchmarks adicionais como DASH-B são recomendados.
Conclusão
Este estudo, viável devido ao pequeno conjunto de dados, destaca os desafios de escalar para conjuntos de dados em hiperescala, onde isolar dados representativos é difícil e pode distorcer resultados.
Mesmo que viável, os métodos atuais apontam para a necessidade de uma anotação humana melhor e mais extensa.
‘Melhor’ e ‘mais’ apresentam desafios distintos. Plataformas de baixo custo como Amazon Mechanical Turk arriscam anotações de baixa qualidade, enquanto a terceirização para diferentes regiões pode não se alinhar com o caso de uso pretendido do modelo.
Isso permanece um problema central e não resolvido na economia do aprendizado de máquina.










 A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
A Haier lança o robô exoesqueleto esportivo com IA mais leve do mundo, pesando apenas 1,75 kg
O Grupo Haier apresentou o robô exoesqueleto com inteligência artificial mais leve do mundo para esportes — o Haier Exoskeleton Robot W3. Este lançamento estabelece um novo recorde do setor em termos
 A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr
A primeira série dramática com AIGC da Yaoke Media, “O Mistério do Bronze em Qinling”, estreia hoje com protagonistas criados por IA
Hoje marca o lançamento oficial da minissérie de mistério e fantasia com IA da Yaoke Media, “A História Secreta do Bronze de Qinling”. Estrelada pelos dois primeiros atores de IA contratados pela empr
 Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam
Satya Nadella está pronto para aproveitar o novo acordo com a OpenAI
Na quarta-feira, um analista da Wall Street perguntou diretamente ao CEO da Microsoft, Satya Nadella, como a nova parceria com a OpenAI afetaria os resultados financeiros da empresa.Nadella descreveu o novo acordo como uma vitória para todos. “Estam

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

Descubra os melhores treinadores de conversação e paquera com IA de 2026 no XIX.AI. Nossa seleção cuidadosamente escolhida e com as melhores avaliações ajuda você a desenvolver carisma social e confiança em tempo real. Explore ferramentas imperdíveis e revolucionárias, com comparações entre versões gratuitas e pagas e rankings atualizados semanalmente. Descubra hoje mesmo o seu diferencial social.
10 ferramentas
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













