




AI Annotation Challenges: The Myth of Automated Labeling
Machine learning research often assumes AI can enhance dataset annotations, especially image captions for vision-language models (VLMs), to cut costs and reduce human supervision burdens.
This echoes the early 2000s 'download more RAM' meme, mocking the idea that software can fix hardware limits.
Yet, annotation quality is often overlooked, dwarfed by the buzz around new AI models, despite its critical role in machine learning pipelines.
The ability of AI to identify and replicate patterns hinges on high-quality, consistent human annotations—labels and descriptions crafted by people making subjective calls in imperfect settings.
Systems aiming to mimic annotator behavior to replace humans and scale accurate labeling struggle when faced with data not included in human-provided examples. Similarity doesn’t equate to equivalence, and cross-domain consistency remains elusive in computer vision.
Ultimately, human judgment defines the data that shapes AI systems.
RAG Solutions
Until recently, errors in dataset annotations were tolerated as minor trade-offs given the imperfect but marketable outputs of generative AI.
A 2025 Singapore study found hallucinations—AI generating false outputs—are inherent to these systems’ designs.
RAG-based agents, which verify facts via internet searches, are gaining traction in research and commercial applications but increase resource costs and query delays. New information applied to trained models lacks the depth of native model connections.
Flawed annotations undermine model performance, and improving their quality, though imperfect due to human subjectivity, is critical.
RePOPE Insights
A German study exposes flaws in older datasets, focusing on image caption accuracy in benchmarks like MSCOCO. It reveals how label errors distort hallucination assessments in vision-language models.

Examples from a recent study showing incorrect object identification in MSCOCO dataset captions. Manual revisions to the POPE benchmark highlight the pitfalls of cost-cutting in annotation curation. Source: https://arxiv.org/pdf/2504.15707
Consider an AI evaluating a street scene image for a bicycle. If the model says yes but the dataset claims no, it’s marked wrong. Yet, if a bicycle is visibly present but missed in annotation, the model is correct, and the dataset is flawed. Such errors skew model accuracy and hallucination metrics.
Incorrect or vague annotations can make accurate models seem error-prone or faulty ones appear reliable, complicating hallucination diagnosis and model ranking.
The study revisits the Polling-based Object Probing Evaluation (POPE) benchmark, which tests vision-language models’ ability to identify objects in images using MSCOCO labels.
POPE reframes hallucination as a yes/no classification task, asking models if specific objects appear in images, using prompts like “Is there a

Examples of object hallucination in vision-language models. Bold labels mark objects in original annotations; red labels highlight model-hallucinated objects. The left example uses traditional evaluation, while the right three come from POPE variants. Source: https://aclanthology.org/2023.emnlp-main.20.pdf
Ground-truth objects (answer: Yes) are paired with non-existent objects (answer: No), selected randomly, frequently, or based on co-occurrence. This enables stable, prompt-independent hallucination evaluation without complex caption analysis.
The study, RePOPE: Impact of Annotation Errors on the POPE Benchmark, rechecks MSCOCO labels and finds many errors or ambiguities.

Images from the 2014 MSCOCO dataset. Source: https://arxiv.org/pdf/1405.0312
These errors alter model rankings, with some top performers dropping when evaluated against corrected labels.
Tests on open-weight vision-language models using the original POPE and the re-labeled RePOPE show significant ranking shifts, especially in F1 scores, with several models falling in performance.
The study argues that annotation errors hide true model hallucination, presenting RePOPE as a more accurate evaluation tool.

Examples from the study showing POPE captions missing subtle objects, like a person near a tram cabin or a chair obscured by a tennis player.
Methodology and Testing
Researchers re-labeled MSCOCO annotations with two human reviewers per instance. Ambiguous cases, like those below, were excluded from testing.

Ambiguous cases in POPE with unclear labels, like teddy bears as bears or motorcycles as bicycles, excluded from RePOPE due to subjective classifications and MSCOCO inconsistencies.
The paper notes:
“Original annotators overlooked people in backgrounds or behind glass, chairs obscured by a tennis player, or a faint carrot in coleslaw.”
“Inconsistent MSCOCO labels, like classifying a teddy bear as a bear or a motorcycle as a bicycle, stem from varying object definitions, marking such cases as ambiguous.”
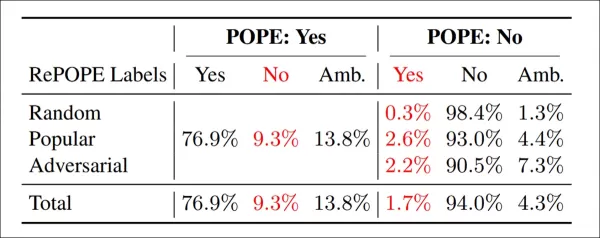
Re-annotation results: Across POPE variants, 9.3% of ‘Yes’ labels were incorrect, 13.8% ambiguous; 1.7% of ‘No’ labels were mislabeled, 4.3% ambiguous.
The team tested open-weight models, including InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B, and PaliGemma2, across POPE and RePOPE.
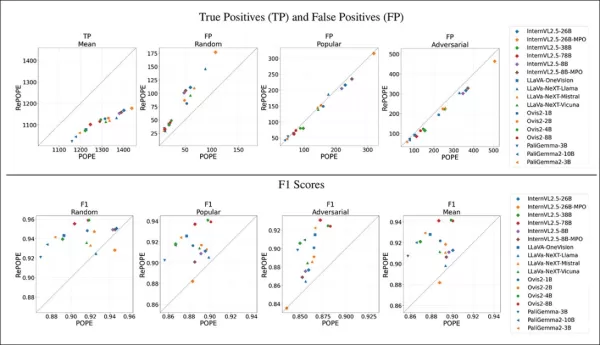
Results show original label errors caused a drop in true positives. False positives doubled on the random subset, stayed steady on the popular subset, and slightly decreased on the adversarial subset. Re-labeling shifted F1 rankings, with models like Ovis2-4B and -8B rising to the top.
Graphs show true positives dropped across models, as correct answers were often based on faulty labels, while false positives varied.
In POPE’s random subset, false positives nearly doubled, revealing objects present but missed in original annotations. In the adversarial subset, false positives dropped, as absent objects were often unlabeled but present.
Precision and recall were affected, but model rankings remained stable. F1 scores, POPE’s key metric, shifted significantly, with top models like InternVL2.5-8B dropping and Ovis2-4B and -8B climbing.
Accuracy scores were less reliable due to uneven positive and negative examples in the corrected dataset.
The study emphasizes the need for high-quality annotations and shares corrected labels on GitHub, noting that RePOPE alone doesn’t fully address benchmark saturation, as models still score above 90% in true positives and negatives. Additional benchmarks like DASH-B are recommended.
Conclusion
This study, feasible due to the small dataset, highlights challenges in scaling to hyperscale datasets, where isolating representative data is tough and may skew results.
Even if feasible, current methods point to the need for better, more extensive human annotation.
‘Better’ and ‘more’ pose distinct challenges. Low-cost platforms like Amazon Mechanical Turk risk poor-quality annotations, while outsourcing to different regions may misalign with the model’s intended use case.
This remains a core, unresolved issue in machine learning economics.
First published Wednesday, April 23, 2025
Related article
 Heeseung's AI-Powered 'Wildflower' Cover: A New Era of Music Creation
The digital world is rapidly transforming, introducing groundbreaking ways to express creativity. AI-generated covers have emerged as a unique medium, enabling artists and fans to reimagine beloved tr
AI-Powered Tools Boost Voice Clarity for Content Creators
In the digital era, pristine audio is essential for engaging content, whether for podcasts, videos, or professional communication. Conventional methods often fail to deliver, but Artificial Intelligen
Tech Giants Empower Educators with AI Training Programs
Technology is revolutionizing education, and leading tech companies are equipping teachers with vital skills. Giants like Microsoft, OpenAI, and Anthropic have partnered with teachers’ unions to estab
Comments (0)
0/200
Heeseung's AI-Powered 'Wildflower' Cover: A New Era of Music Creation
The digital world is rapidly transforming, introducing groundbreaking ways to express creativity. AI-generated covers have emerged as a unique medium, enabling artists and fans to reimagine beloved tr
AI-Powered Tools Boost Voice Clarity for Content Creators
In the digital era, pristine audio is essential for engaging content, whether for podcasts, videos, or professional communication. Conventional methods often fail to deliver, but Artificial Intelligen
Tech Giants Empower Educators with AI Training Programs
Technology is revolutionizing education, and leading tech companies are equipping teachers with vital skills. Giants like Microsoft, OpenAI, and Anthropic have partnered with teachers’ unions to estab
Comments (0)
0/200
Machine learning research often assumes AI can enhance dataset annotations, especially image captions for vision-language models (VLMs), to cut costs and reduce human supervision burdens.
This echoes the early 2000s 'download more RAM' meme, mocking the idea that software can fix hardware limits.
Yet, annotation quality is often overlooked, dwarfed by the buzz around new AI models, despite its critical role in machine learning pipelines.
The ability of AI to identify and replicate patterns hinges on high-quality, consistent human annotations—labels and descriptions crafted by people making subjective calls in imperfect settings.
Systems aiming to mimic annotator behavior to replace humans and scale accurate labeling struggle when faced with data not included in human-provided examples. Similarity doesn’t equate to equivalence, and cross-domain consistency remains elusive in computer vision.
Ultimately, human judgment defines the data that shapes AI systems.
RAG Solutions
Until recently, errors in dataset annotations were tolerated as minor trade-offs given the imperfect but marketable outputs of generative AI.
A 2025 Singapore study found hallucinations—AI generating false outputs—are inherent to these systems’ designs.
RAG-based agents, which verify facts via internet searches, are gaining traction in research and commercial applications but increase resource costs and query delays. New information applied to trained models lacks the depth of native model connections.
Flawed annotations undermine model performance, and improving their quality, though imperfect due to human subjectivity, is critical.
RePOPE Insights
A German study exposes flaws in older datasets, focusing on image caption accuracy in benchmarks like MSCOCO. It reveals how label errors distort hallucination assessments in vision-language models.
Examples from a recent study showing incorrect object identification in MSCOCO dataset captions. Manual revisions to the POPE benchmark highlight the pitfalls of cost-cutting in annotation curation. Source: https://arxiv.org/pdf/2504.15707
Consider an AI evaluating a street scene image for a bicycle. If the model says yes but the dataset claims no, it’s marked wrong. Yet, if a bicycle is visibly present but missed in annotation, the model is correct, and the dataset is flawed. Such errors skew model accuracy and hallucination metrics.
Incorrect or vague annotations can make accurate models seem error-prone or faulty ones appear reliable, complicating hallucination diagnosis and model ranking.
The study revisits the Polling-based Object Probing Evaluation (POPE) benchmark, which tests vision-language models’ ability to identify objects in images using MSCOCO labels.
POPE reframes hallucination as a yes/no classification task, asking models if specific objects appear in images, using prompts like “Is there a
Examples of object hallucination in vision-language models. Bold labels mark objects in original annotations; red labels highlight model-hallucinated objects. The left example uses traditional evaluation, while the right three come from POPE variants. Source: https://aclanthology.org/2023.emnlp-main.20.pdf
Ground-truth objects (answer: Yes) are paired with non-existent objects (answer: No), selected randomly, frequently, or based on co-occurrence. This enables stable, prompt-independent hallucination evaluation without complex caption analysis.
The study, RePOPE: Impact of Annotation Errors on the POPE Benchmark, rechecks MSCOCO labels and finds many errors or ambiguities.
Images from the 2014 MSCOCO dataset. Source: https://arxiv.org/pdf/1405.0312
These errors alter model rankings, with some top performers dropping when evaluated against corrected labels.
Tests on open-weight vision-language models using the original POPE and the re-labeled RePOPE show significant ranking shifts, especially in F1 scores, with several models falling in performance.
The study argues that annotation errors hide true model hallucination, presenting RePOPE as a more accurate evaluation tool.
Examples from the study showing POPE captions missing subtle objects, like a person near a tram cabin or a chair obscured by a tennis player.
Methodology and Testing
Researchers re-labeled MSCOCO annotations with two human reviewers per instance. Ambiguous cases, like those below, were excluded from testing.
Ambiguous cases in POPE with unclear labels, like teddy bears as bears or motorcycles as bicycles, excluded from RePOPE due to subjective classifications and MSCOCO inconsistencies.
The paper notes:
“Original annotators overlooked people in backgrounds or behind glass, chairs obscured by a tennis player, or a faint carrot in coleslaw.”
“Inconsistent MSCOCO labels, like classifying a teddy bear as a bear or a motorcycle as a bicycle, stem from varying object definitions, marking such cases as ambiguous.”
Re-annotation results: Across POPE variants, 9.3% of ‘Yes’ labels were incorrect, 13.8% ambiguous; 1.7% of ‘No’ labels were mislabeled, 4.3% ambiguous.
The team tested open-weight models, including InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B, and PaliGemma2, across POPE and RePOPE.
Results show original label errors caused a drop in true positives. False positives doubled on the random subset, stayed steady on the popular subset, and slightly decreased on the adversarial subset. Re-labeling shifted F1 rankings, with models like Ovis2-4B and -8B rising to the top.
Graphs show true positives dropped across models, as correct answers were often based on faulty labels, while false positives varied.
In POPE’s random subset, false positives nearly doubled, revealing objects present but missed in original annotations. In the adversarial subset, false positives dropped, as absent objects were often unlabeled but present.
Precision and recall were affected, but model rankings remained stable. F1 scores, POPE’s key metric, shifted significantly, with top models like InternVL2.5-8B dropping and Ovis2-4B and -8B climbing.
Accuracy scores were less reliable due to uneven positive and negative examples in the corrected dataset.
The study emphasizes the need for high-quality annotations and shares corrected labels on GitHub, noting that RePOPE alone doesn’t fully address benchmark saturation, as models still score above 90% in true positives and negatives. Additional benchmarks like DASH-B are recommended.
Conclusion
This study, feasible due to the small dataset, highlights challenges in scaling to hyperscale datasets, where isolating representative data is tough and may skew results.
Even if feasible, current methods point to the need for better, more extensive human annotation.
‘Better’ and ‘more’ pose distinct challenges. Low-cost platforms like Amazon Mechanical Turk risk poor-quality annotations, while outsourcing to different regions may misalign with the model’s intended use case.
This remains a core, unresolved issue in machine learning economics.
First published Wednesday, April 23, 2025










 Heeseung's AI-Powered 'Wildflower' Cover: A New Era of Music Creation
The digital world is rapidly transforming, introducing groundbreaking ways to express creativity. AI-generated covers have emerged as a unique medium, enabling artists and fans to reimagine beloved tr
Heeseung's AI-Powered 'Wildflower' Cover: A New Era of Music Creation
The digital world is rapidly transforming, introducing groundbreaking ways to express creativity. AI-generated covers have emerged as a unique medium, enabling artists and fans to reimagine beloved tr
 AI-Powered Tools Boost Voice Clarity for Content Creators
In the digital era, pristine audio is essential for engaging content, whether for podcasts, videos, or professional communication. Conventional methods often fail to deliver, but Artificial Intelligen
Tech Giants Empower Educators with AI Training Programs
Technology is revolutionizing education, and leading tech companies are equipping teachers with vital skills. Giants like Microsoft, OpenAI, and Anthropic have partnered with teachers’ unions to estab
AI-Powered Tools Boost Voice Clarity for Content Creators
In the digital era, pristine audio is essential for engaging content, whether for podcasts, videos, or professional communication. Conventional methods often fail to deliver, but Artificial Intelligen
Tech Giants Empower Educators with AI Training Programs
Technology is revolutionizing education, and leading tech companies are equipping teachers with vital skills. Giants like Microsoft, OpenAI, and Anthropic have partnered with teachers’ unions to estab













