
















 Дом
ДомВызовы аннотации AI: Миф об автоматической разметке
Исследования машинного обучения часто предполагают, что ИИ может улучшить аннотации наборов данных, особенно подписи к изображениям для моделей визуально-языкового взаимодействия (VLMs), чтобы снизить затраты и уменьшить необходимость человеческого контроля.
Это напоминает мем начала 2000-х годов «скачай больше оперативной памяти», высмеивающий идею, что программное обеспечение может устранить аппаратные ограничения.
Однако качество аннотаций часто игнорируется, затмеваемое ажиотажем вокруг новых моделей ИИ, несмотря на их критическую роль в процессах машинного обучения.
Способность ИИ определять и воспроизводить шаблоны зависит от высококачественных, последовательных человеческих аннотаций — меток и описаний, созданных людьми, принимающими субъективные решения в неидеальных условиях.
Системы, стремящиеся имитировать поведение аннотаторов для замены людей и масштабирования точной разметки, сталкиваются с трудностями при работе с данными, не включенными в примеры, предоставленные людьми. Сходство не равно эквивалентности, а согласованность между доменами остается недостижимой в компьютерном зрении.
В конечном итоге человеческие суждения определяют данные, которые формируют системы ИИ.
Решения RAG
До недавнего времени ошибки в аннотациях наборов данных считались незначительными компромиссами, учитывая несовершенные, но коммерчески успешные результаты генеративного ИИ.
Исследование 2025 года в Сингапуре показало, что галлюцинации — ИИ, генерирующий ложные результаты, — присущи конструкции этих систем.
Агенты на основе RAG, проверяющие факты через поиск в интернете, набирают популярность в исследованиях и коммерческих приложениях, но увеличивают затраты на ресурсы и задержки запросов. Новая информация, применяемая к обученным моделям, не имеет глубины связей, присущих нативным моделям.
Ошибочные аннотации подрывают производительность моделей, и улучшение их качества, хотя и несовершенное из-за человеческой субъективности, имеет решающее значение.
Инсайты RePOPE
Немецкое исследование выявляет недостатки старых наборов данных, акцентируя внимание на точности подписей к изображениям в бенчмарках, таких как MSCOCO. Оно показывает, как ошибки в метках искажают оценки галлюцинаций в моделях визуально-языкового взаимодействия.

Примеры из недавнего исследования, показывающие неверную идентификацию объектов в подписях набора данных MSCOCO. Ручная доработка бенчмарка POPE подчеркивает недостатки экономии на курировании аннотаций. Источник: https://arxiv.org/pdf/2504.15707
Рассмотрим ИИ, оценивающий изображение уличной сцены на наличие велосипеда. Если модель говорит да, а набор данных утверждает нет, это считается ошибкой. Но если велосипед явно присутствует, но пропущен в аннотации, модель права, а набор данных ошибочен. Такие ошибки искажают точность модели и метрики галлюцинаций.
Неверные или расплывчатые аннотации могут сделать точные модели кажущимися ошибочными, а ошибочные — надежными, усложняя диагностику галлюцинаций и ранжирование моделей.
Исследование пересматривает бенчмарк Polling-based Object Probing Evaluation (POPE), который тестирует способность моделей визуально-языкового взаимодействия идентифицировать объекты на изображениях с использованием меток MSCOCO.
POPE переформулирует галлюцинацию как задачу классификации да/нет, спрашивая модели, присутствует ли конкретный объект на изображении, используя подсказки вроде «Есть ли на изображении?»

Примеры галлюцинаций объектов в моделях визуально-языкового взаимодействия. Жирные метки обозначают объекты в исходных аннотациях; красные метки выделяют объекты, галлюцинированные моделями. Левый пример использует традиционную оценку, а три справа — из вариантов POPE. Источник: https://aclanthology.org/2023.emnlp-main.20.pdf
Объекты, присутствующие в действительности (ответ: Да), сопоставляются с несуществующими объектами (ответ: Нет), выбранными случайно, часто или на основе совместного появления. Это обеспечивает стабильную оценку галлюцинаций, независимую от подсказок, без сложного анализа подписей.
Исследование, RePOPE: Влияние ошибок аннотации на бенчмарк POPE, перепроверяет метки MSCOCO и выявляет множество ошибок или двусмысленностей.

Изображения из набора данных MSCOCO 2014 года. Источник: https://arxiv.org/pdf/1405.0312
Эти ошибки изменяют рейтинги моделей, причем некоторые лидеры падают при оценке с исправленными метками.
Тесты на моделях с открытым весом с использованием исходного POPE и перемаркированного RePOPE показывают значительные сдвиги в рейтингах, особенно в F1-показателях, с падением производительности нескольких моделей.
Исследование утверждает, что ошибки аннотации скрывают истинные галлюцинации моделей, представляя RePOPE как более точный инструмент оценки.

Примеры из исследования, показывающие, что подписи POPE упускают тонкие объекты, такие как человек рядом с кабиной трамвая или стул, скрытый теннисистом.
Методология и тестирование
Исследователи перемаркировали аннотации MSCOCO с двумя человеческими рецензентами на каждый случай. Двусмысленные случаи, как указано ниже, были исключены из тестирования.

Двусмысленные случаи в POPE с нечеткими метками, например, плюшевый мишка как медведь или мотоцикл как велосипед, исключены из RePOPE из-за субъективных классификаций и несоответствий MSCOCO.
В статье отмечается:
«Исходные аннотаторы упустили людей на заднем плане или за стеклом, стулья, скрытые теннисистом, или едва заметную морковь в салате.»
«Непоследовательные метки MSCOCO, такие как классификация плюшевого мишки как медведя или мотоцикла как велосипеда, связаны с различиями в определениях объектов, что делает такие случаи двусмысленными.»
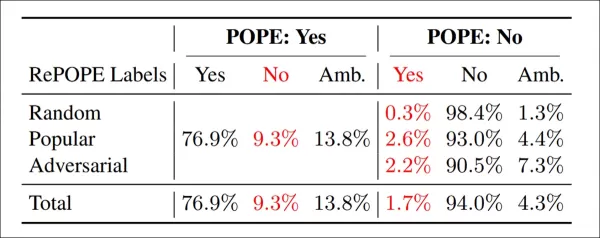
Результаты перемаркировки: в вариантах POPE 9,3% меток «Да» были неверными, 13,8% — двусмысленными; 1,7% меток «Нет» были ошибочными, 4,3% — двусмысленными.
Команда протестировала модели с открытым весом, включая InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B и PaliGemma2, на POPE и RePOPE.
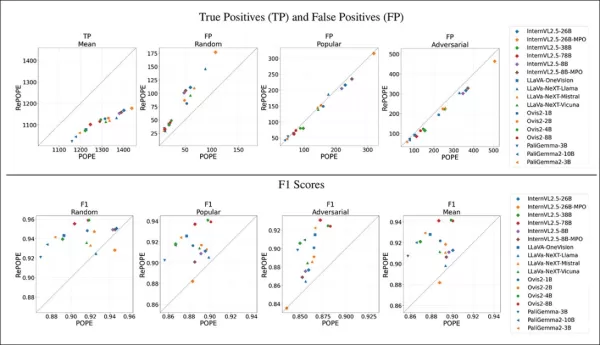
Результаты показывают, что ошибки исходных меток вызвали снижение истинных позитивов. Ложные позитивы удвоились в случайном подмножестве, остались стабильными в популярном и слегка снизились в антагонистическом. Перемаркировка изменила рейтинги F1, с моделями, такими как Ovis2-4B и -8B, поднявшимися на вершину.
Графики показывают снижение истинных позитивов у моделей, так как правильные ответы часто основывались на ошибочных метках, в то время как ложные позитивы варьировались.
В случайном подмножестве POPE ложные позитивы почти удвоились, выявляя объекты, присутствующие, но пропущенные в исходных аннотациях. В антагонистическом подмножестве ложные позитивы снизились, так как отсутствующие объекты часто не были помечены, но присутствовали.
Точность и полнота пострадали, но рейтинги моделей остались стабильными. Показатели F1, ключевые для POPE, значительно изменились, с падением топ-моделей, таких как InternVL2.5-8B, и ростом Ovis2-4B и -8B.
Показатели точности были менее надежными из-за неравномерного количества позитивных и негативных примеров в исправленном наборе данных.
Исследование подчеркивает необходимость высококачественных аннотаций и публикует исправленные метки на GitHub, отмечая, что RePOPE сам по себе не решает проблему насыщения бенчмарков, так как модели по-прежнему набирают более 90% по истинным позитивным и негативным результатам. Рекомендуются дополнительные бенчмарки, такие как DASH-B.
Заключение
Это исследование, возможное благодаря небольшому набору данных, подчеркивает трудности масштабирования на гипермасштабные наборы данных, где выделение репрезентативных данных сложно и может искажать результаты.
Даже если это возможно, текущие методы указывают на необходимость более качественной и обширной человеческой аннотации.
«Лучше» и «больше» создают разные проблемы. Недорогие платформы, такие как Amazon Mechanical Turk, рискуют дать низкокачественные аннотации, а аутсорсинг в разные регионы может не соответствовать предполагаемому использованию модели.
Это остается ключевой, нерешенной проблемой в экономике машинного обучения.
Впервые опубликовано в среду, 23 апреля 2025 года
Связанная статья
 Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц
Рекомендации по связанным специальным темам
Создание комиксов
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц
Рекомендации по связанным специальным темам
Создание комиксов
 Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Лучшие генераторы на базе ИИ для сёнэн-манги: создавайте динамичные сцены боевых действий и эффекты энергии
Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
 15 инструментов
15 инструментов
 xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
xix.ai
Бизнес
Лучшие приложения для учета расходов на базе ИИ: сканируйте чеки и автоматически классифицируйте корпоративные расходы
Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai
Бизнес
Лучшие инструменты для подбора персонала с помощью ИИ: отбор резюме и автоматизация планирования собеседований с кандидатами
Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai
Производительность
Персональные тренеры по благополучию и концентрации на базе ИИ: борьба с выгоранием и повышение уровня умственной энергии
Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai
чат-бот
Лучшие романтические чат-боты на базе ИИ: постройте долгосрочные отношения с помощью чат-ботов с устойчивой индивидуальностью
Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai
Образование и обучение
Лучшие наставники в области искусственного интеллекта и науки о данных: мастерство работы с SQL, библиотекой Pandas и рабочими процессами машинного обучения
Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

 Комментарии (2)
Комментарии (2)
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
Исследования машинного обучения часто предполагают, что ИИ может улучшить аннотации наборов данных, особенно подписи к изображениям для моделей визуально-языкового взаимодействия (VLMs), чтобы снизить затраты и уменьшить необходимость человеческого контроля.
Это напоминает мем начала 2000-х годов «скачай больше оперативной памяти», высмеивающий идею, что программное обеспечение может устранить аппаратные ограничения.
Однако качество аннотаций часто игнорируется, затмеваемое ажиотажем вокруг новых моделей ИИ, несмотря на их критическую роль в процессах машинного обучения.
Способность ИИ определять и воспроизводить шаблоны зависит от высококачественных, последовательных человеческих аннотаций — меток и описаний, созданных людьми, принимающими субъективные решения в неидеальных условиях.
Системы, стремящиеся имитировать поведение аннотаторов для замены людей и масштабирования точной разметки, сталкиваются с трудностями при работе с данными, не включенными в примеры, предоставленные людьми. Сходство не равно эквивалентности, а согласованность между доменами остается недостижимой в компьютерном зрении.
В конечном итоге человеческие суждения определяют данные, которые формируют системы ИИ.
Решения RAG
До недавнего времени ошибки в аннотациях наборов данных считались незначительными компромиссами, учитывая несовершенные, но коммерчески успешные результаты генеративного ИИ.
Исследование 2025 года в Сингапуре показало, что галлюцинации — ИИ, генерирующий ложные результаты, — присущи конструкции этих систем.
Агенты на основе RAG, проверяющие факты через поиск в интернете, набирают популярность в исследованиях и коммерческих приложениях, но увеличивают затраты на ресурсы и задержки запросов. Новая информация, применяемая к обученным моделям, не имеет глубины связей, присущих нативным моделям.
Ошибочные аннотации подрывают производительность моделей, и улучшение их качества, хотя и несовершенное из-за человеческой субъективности, имеет решающее значение.
Инсайты RePOPE
Немецкое исследование выявляет недостатки старых наборов данных, акцентируя внимание на точности подписей к изображениям в бенчмарках, таких как MSCOCO. Оно показывает, как ошибки в метках искажают оценки галлюцинаций в моделях визуально-языкового взаимодействия.
Примеры из недавнего исследования, показывающие неверную идентификацию объектов в подписях набора данных MSCOCO. Ручная доработка бенчмарка POPE подчеркивает недостатки экономии на курировании аннотаций. Источник: https://arxiv.org/pdf/2504.15707
Рассмотрим ИИ, оценивающий изображение уличной сцены на наличие велосипеда. Если модель говорит да, а набор данных утверждает нет, это считается ошибкой. Но если велосипед явно присутствует, но пропущен в аннотации, модель права, а набор данных ошибочен. Такие ошибки искажают точность модели и метрики галлюцинаций.
Неверные или расплывчатые аннотации могут сделать точные модели кажущимися ошибочными, а ошибочные — надежными, усложняя диагностику галлюцинаций и ранжирование моделей.
Исследование пересматривает бенчмарк Polling-based Object Probing Evaluation (POPE), который тестирует способность моделей визуально-языкового взаимодействия идентифицировать объекты на изображениях с использованием меток MSCOCO.
POPE переформулирует галлюцинацию как задачу классификации да/нет, спрашивая модели, присутствует ли конкретный объект на изображении, используя подсказки вроде «Есть ли на изображении?»
Примеры галлюцинаций объектов в моделях визуально-языкового взаимодействия. Жирные метки обозначают объекты в исходных аннотациях; красные метки выделяют объекты, галлюцинированные моделями. Левый пример использует традиционную оценку, а три справа — из вариантов POPE. Источник: https://aclanthology.org/2023.emnlp-main.20.pdf
Объекты, присутствующие в действительности (ответ: Да), сопоставляются с несуществующими объектами (ответ: Нет), выбранными случайно, часто или на основе совместного появления. Это обеспечивает стабильную оценку галлюцинаций, независимую от подсказок, без сложного анализа подписей.
Исследование, RePOPE: Влияние ошибок аннотации на бенчмарк POPE, перепроверяет метки MSCOCO и выявляет множество ошибок или двусмысленностей.
Изображения из набора данных MSCOCO 2014 года. Источник: https://arxiv.org/pdf/1405.0312
Эти ошибки изменяют рейтинги моделей, причем некоторые лидеры падают при оценке с исправленными метками.
Тесты на моделях с открытым весом с использованием исходного POPE и перемаркированного RePOPE показывают значительные сдвиги в рейтингах, особенно в F1-показателях, с падением производительности нескольких моделей.
Исследование утверждает, что ошибки аннотации скрывают истинные галлюцинации моделей, представляя RePOPE как более точный инструмент оценки.
Примеры из исследования, показывающие, что подписи POPE упускают тонкие объекты, такие как человек рядом с кабиной трамвая или стул, скрытый теннисистом.
Методология и тестирование
Исследователи перемаркировали аннотации MSCOCO с двумя человеческими рецензентами на каждый случай. Двусмысленные случаи, как указано ниже, были исключены из тестирования.
Двусмысленные случаи в POPE с нечеткими метками, например, плюшевый мишка как медведь или мотоцикл как велосипед, исключены из RePOPE из-за субъективных классификаций и несоответствий MSCOCO.
В статье отмечается:
«Исходные аннотаторы упустили людей на заднем плане или за стеклом, стулья, скрытые теннисистом, или едва заметную морковь в салате.»
«Непоследовательные метки MSCOCO, такие как классификация плюшевого мишки как медведя или мотоцикла как велосипеда, связаны с различиями в определениях объектов, что делает такие случаи двусмысленными.»
Результаты перемаркировки: в вариантах POPE 9,3% меток «Да» были неверными, 13,8% — двусмысленными; 1,7% меток «Нет» были ошибочными, 4,3% — двусмысленными.
Команда протестировала модели с открытым весом, включая InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B и PaliGemma2, на POPE и RePOPE.
Результаты показывают, что ошибки исходных меток вызвали снижение истинных позитивов. Ложные позитивы удвоились в случайном подмножестве, остались стабильными в популярном и слегка снизились в антагонистическом. Перемаркировка изменила рейтинги F1, с моделями, такими как Ovis2-4B и -8B, поднявшимися на вершину.
Графики показывают снижение истинных позитивов у моделей, так как правильные ответы часто основывались на ошибочных метках, в то время как ложные позитивы варьировались.
В случайном подмножестве POPE ложные позитивы почти удвоились, выявляя объекты, присутствующие, но пропущенные в исходных аннотациях. В антагонистическом подмножестве ложные позитивы снизились, так как отсутствующие объекты часто не были помечены, но присутствовали.
Точность и полнота пострадали, но рейтинги моделей остались стабильными. Показатели F1, ключевые для POPE, значительно изменились, с падением топ-моделей, таких как InternVL2.5-8B, и ростом Ovis2-4B и -8B.
Показатели точности были менее надежными из-за неравномерного количества позитивных и негативных примеров в исправленном наборе данных.
Исследование подчеркивает необходимость высококачественных аннотаций и публикует исправленные метки на GitHub, отмечая, что RePOPE сам по себе не решает проблему насыщения бенчмарков, так как модели по-прежнему набирают более 90% по истинным позитивным и негативным результатам. Рекомендуются дополнительные бенчмарки, такие как DASH-B.
Заключение
Это исследование, возможное благодаря небольшому набору данных, подчеркивает трудности масштабирования на гипермасштабные наборы данных, где выделение репрезентативных данных сложно и может искажать результаты.
Даже если это возможно, текущие методы указывают на необходимость более качественной и обширной человеческой аннотации.
«Лучше» и «больше» создают разные проблемы. Недорогие платформы, такие как Amazon Mechanical Turk, рискуют дать низкокачественные аннотации, а аутсорсинг в разные регионы может не соответствовать предполагаемому использованию модели.
Это остается ключевой, нерешенной проблемой в экономике машинного обучения.
Впервые опубликовано в среду, 23 апреля 2025 года










 Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
Выпущена версия Claude Opus 4.7, в которой надежность ценится выше интеллекта
В этом году компания Anthropic сохраняет высокие темпы развития, выпуская новые функции почти каждый день. Долгожданная версия Claude Opus 4.7 только что была официально выпущена, и что интересно, в с
 Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
Компания Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом, вес которого составляет всего 1,75 кг
Группа Haier представила самый легкий в мире спортивный робот-экзоскелет с искусственным интеллектом — Haier Exoskeleton Robot W3. Этот запуск устанавливает новый отраслевой рекорд по легкости и знаме
 Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц
Сегодня стартует первый сериал Yaoke Media, созданный с помощью технологий AIGC, — «Тайна бронзы в Циньлине» с главными героями, нарисованными искусственным интеллектом
Сегодня состоялся официальный запуск короткометражного фэнтезийного детективного сериала «Тайная история бронзы Циньлин» от Yaoke Media. В главных ролях — первые два подписанных компанией ИИ-актера, Ц

Откройте для себя лучшие генераторы искусственного интеллекта для манги в стиле «сёнен» 2026 года на сайте XIX.AI. В нашем тщательно отобранном списке представлены мощные инструменты для создания динамичных сцен боевых действий и эффектных энергетических эффектов. Сравните бесплатные и платные варианты на основе реальных тестов. Раскройте свой творческий потенциал и начните создавать эпическую мангу уже сегодня!
15 инструментов
xix.ai

Лучшие программы для учета расходов с ИИ 2026 года: самые популярные инструменты для сканирования чеков и автоматической классификации корпоративных расходов. Откройте для себя мощные, революционные решения для удобного управления расходами, точного финансового мониторинга и оптимизации соблюдения нормативных требований. Наш тщательно составленный и еженедельно обновляемый обзор бесплатных и платных вариантов поможет вам найти идеальный вариант. Воспользуйтесь преимуществами ИИ с помощью рекомендаций экспертов XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших инструментов для рекрутинга на базе ИИ 2026 года на сайте XIX.AI. В нашем тщательно составленном списке представлены мощные, революционные решения для отбора резюме и автоматизации планирования собеседований с кандидатами. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Найдите своего идеального помощника по подбору персонала и оптимизируйте процесс рекрутинга уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучших в 2026 году ИИ-тренеров по личному благополучию и концентрации внимания на сайте XIX.AI. В нашем тщательно составленном рейтинге представлены высокооцененные, революционные инструменты для борьбы с выгоранием и повышения умственной энергии. Сравните бесплатные и платные варианты с помощью реальных отзывов. Откройте для себя путь к максимальной продуктивности и благополучию уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие романтические чат-боты с искусственным интеллектом 2026 года, которые помогут вам построить искренние и долгосрочные отношения. В нашем тщательно составленном списке вы найдете чат-ботов с яркими и последовательными личностями, сравнение бесплатных и платных версий, а также результаты реальных тестов. Найдите своего идеального спутника и начните строить отношения уже сегодня на XIX.AI.
10 инструментов
xix.ai

Откройте для себя 20 лучших наставников в области искусственного интеллекта и науки о данных на 2026 год, которые помогут вам овладеть SQL, Pandas и рабочими процессами машинного обучения. Изучите наш тщательно отобранный список на сайте XIX.AI – здесь вы найдете эффективные рекомендации, способные изменить ход ваших работ. Сравните бесплатные и платные варианты с примерами из реальной практики. Освоите науку о данных уже сегодня.
10 инструментов
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













