
















 首頁
首頁AI標註挑戰:自動化標籤的神話
機器學習研究通常假設AI能增強資料集標註,特別是視覺語言模型(VLMs)的圖像描述,以降低成本並減輕人工監督負擔。
這與2000年代初的「下載更多RAM」迷因相呼應,嘲笑軟體能解決硬體限制的想法。
然而,標註品質常被忽視,儘管它在機器學習流程中扮演關鍵角色,卻被新AI模型的熱潮所掩蓋。
AI辨識與複製模式的能力依賴於高品質、一致的人工標註——由人類在不完美環境中主觀判斷所製定的標籤與描述。
試圖模仿標註者行為以取代人工並擴展精確標籤的系統,在面對未包含在人工提供範例中的數據時,表現不佳。相似性並不等同於等價性,跨領域的一致性在電腦視覺中仍難以實現。
最終,人類判斷定義了塑造AI系統的數據。
RAG解決方案
直到最近,資料集標註中的錯誤被視為次要妥協,因為生成AI的產出雖不完美但具市場價值。
2025年新加坡研究發現,幻覺(AI生成錯誤輸出)是這些系統設計的固有問題。
基於RAG的代理通過網路搜尋驗證事實,在研究與商業應用中逐漸受到重視,但增加了資源成本與查詢延遲。應用於已訓練模型的新資訊缺乏原生模型連繫的深度。
錯誤的標註會削弱模型表現,提升標註品質雖因人類主觀性而不完美,但至關重要。
RePOPE洞察
德國研究揭露舊資料集的缺陷,聚焦於MSCOCO等基準中的圖像描述準確性,顯示標籤錯誤如何扭曲視覺語言模型的幻覺評估。

近期研究範例顯示MSCOCO資料集描述中物體辨識錯誤。對POPE基準的手動修訂凸顯了節省標註整理成本的陷阱。 來源:https://arxiv.org/pdf/2504.15707
假設AI評估街景圖像中的自行車,若模型回答是,但資料集標示否,則被判定錯誤。然而,若圖像中明顯有自行車但標註遺漏,模型正確,資料集錯誤。此類錯誤會扭曲模型準確性與幻覺指標。
不正確或模糊的標註可能使準確的模型看似錯誤,或使有缺陷的模型看似可靠,複雜化幻覺診斷與模型排名。
該研究重新審視基於投票的物體探測評估(POPE)基準,測試視覺語言模型使用MSCOCO標籤辨識圖像中物體的能力。
POPE將幻覺重新定義為是/否分類任務,詢問模型圖像中是否包含特定物體,使用提示如“圖像中有嗎?”

視覺語言模型中的物體幻覺範例。粗體標籤標示原始標註中的物體;紅色標籤突出模型幻覺的物體。左側範例使用傳統評估,右側三例來自POPE變體。 來源:https://aclanthology.org/2023.emnlp-main.20.pdf
真實物體(答案:是)與不存在物體(答案:否)配對,隨機、頻繁或基於共現選擇。這實現了穩定、不依賴提示的幻覺評估,無需複雜的描述分析。
研究《RePOPE:標註錯誤對POPE基準的影響》重新檢查MSCOCO標籤,發現許多錯誤或模糊之處。

2014年MSCOCO資料集的圖像。 來源:https://arxiv.org/pdf/1405.0312
這些錯誤改變了模型排名,部分頂尖模型在對比修正標籤後表現下降。
使用原始POPE與重新標註的RePOPE測試開源視覺語言模型,顯示排名顯著變動,特別是F1分數,部分模型表現下降。
該研究認為標註錯誤掩蓋了模型的真實幻覺,提出RePOPE作為更準確的評估工具。

研究範例顯示POPE描述遺漏細微物體,如電車車廂旁的人或被網球選手遮擋的椅子。
方法論與測試
研究人員對MSCOCO標註進行重新標註,每例由兩名人工審查者處理。模糊案例,如下所述,被排除在測試之外。

POPE中模糊案例的標籤不清晰,如泰迪熊被標為熊或摩托車被標為自行車,因主觀分類及MSCOCO不一致被RePOPE排除。
論文指出:
“原始標註者忽略了背景中的人或玻璃後的人、被網球選手遮擋的椅子,或涼拌沙拉中模糊的胡蘿蔔。”
“MSCOCO標籤不一致,如將泰迪熊分類為熊或摩托車為自行車,源於物體定義的差異,這些案例被標為模糊。”
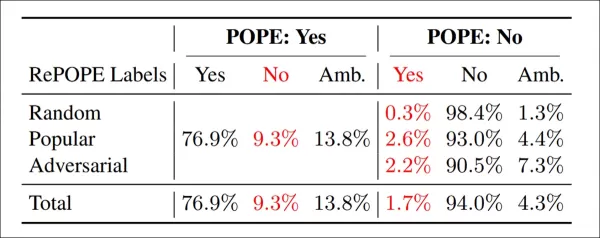
重新標註結果:POPE變體中,9.3%的‘是’標籤錯誤,13.8%模糊;1.7%的‘否’標籤錯誤,4.3%模糊。
研究團隊測試了開源模型,包括InternVL2.5、LLaVA-NeXT、Vicuna、Mistral 7b、Llama、LLaVA-OneVision、Ovis2、PaliGemma-3B及PaliGemma2,涵蓋POPE與RePOPE。
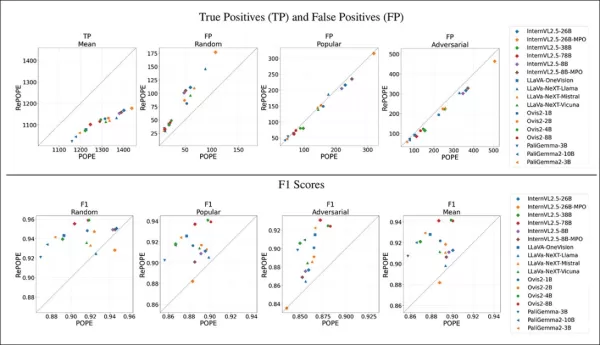
結果顯示原始標籤錯誤導致真陽性下降。假陽性在隨機子集近乎翻倍,流行子集穩定,對抗子集略減。重新標註改變F1排名,Ovis2-4B與-8B等模型名列前茅。
圖表顯示真陽性在各模型中下降,因正確答案常基於錯誤標籤,而假陽性則因子集不同而變化。
在POPE的隨機子集中,假陽性幾乎翻倍,揭示原始標註遺漏但實際存在的物體。在對抗子集中,假陽性下降,因不存在的物體常未標註但實際存在。
精確度與召回率受到影響,但模型排名保持穩定。F1分數(POPE的關鍵指標)顯著變動,頂尖模型如InternVL2.5-8B下降,Ovis2-4B與-8B上升。
由於修正資料集中正負樣本不均,準確度分數可靠性較低。
該研究強調高品質標註的必要性,並在GitHub分享修正標籤,指出RePOPE單獨無法完全解決基準飽和問題,因模型在真陽性與真陰性上仍超過90%。建議使用如DASH-B等額外基準。
結論
這項研究因資料集規模小而可行,突顯了擴展至超大規模資料集的挑戰,難以隔離代表性數據,可能導致結果偏差。
即使可行,當前方法顯示需要更好、更廣泛的人工標註。
「更好」與「更多」帶來不同挑戰。低成本平台如Amazon Mechanical Turk可能導致標註品質不佳,而外包至不同地區可能與模型預期用例不符。
這仍是機器學習經濟學中未解的核心問題。
首次發表於2025年4月23日,星期三
相關文章
 全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優
如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進
相關專題推薦
商業
全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優
如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進
相關專題推薦
商業
 頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
 10 個工具
10 個工具
 xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai
漫畫創作
少年漫畫頂尖 AI 生成器:打造高張力動作場面與能量特效
立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai
商業
最佳 AI 支出追蹤工具:掃描收據並自動分類公司開支
2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai
商業
最佳 AI 招聘工具:篩選履歷與自動化安排候選人面試
在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

 評論 (2)
0/500
評論 (2)
0/500
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
機器學習研究通常假設AI能增強資料集標註,特別是視覺語言模型(VLMs)的圖像描述,以降低成本並減輕人工監督負擔。
這與2000年代初的「下載更多RAM」迷因相呼應,嘲笑軟體能解決硬體限制的想法。
然而,標註品質常被忽視,儘管它在機器學習流程中扮演關鍵角色,卻被新AI模型的熱潮所掩蓋。
AI辨識與複製模式的能力依賴於高品質、一致的人工標註——由人類在不完美環境中主觀判斷所製定的標籤與描述。
試圖模仿標註者行為以取代人工並擴展精確標籤的系統,在面對未包含在人工提供範例中的數據時,表現不佳。相似性並不等同於等價性,跨領域的一致性在電腦視覺中仍難以實現。
最終,人類判斷定義了塑造AI系統的數據。
RAG解決方案
直到最近,資料集標註中的錯誤被視為次要妥協,因為生成AI的產出雖不完美但具市場價值。
2025年新加坡研究發現,幻覺(AI生成錯誤輸出)是這些系統設計的固有問題。
基於RAG的代理通過網路搜尋驗證事實,在研究與商業應用中逐漸受到重視,但增加了資源成本與查詢延遲。應用於已訓練模型的新資訊缺乏原生模型連繫的深度。
錯誤的標註會削弱模型表現,提升標註品質雖因人類主觀性而不完美,但至關重要。
RePOPE洞察
德國研究揭露舊資料集的缺陷,聚焦於MSCOCO等基準中的圖像描述準確性,顯示標籤錯誤如何扭曲視覺語言模型的幻覺評估。
近期研究範例顯示MSCOCO資料集描述中物體辨識錯誤。對POPE基準的手動修訂凸顯了節省標註整理成本的陷阱。 來源:https://arxiv.org/pdf/2504.15707
假設AI評估街景圖像中的自行車,若模型回答是,但資料集標示否,則被判定錯誤。然而,若圖像中明顯有自行車但標註遺漏,模型正確,資料集錯誤。此類錯誤會扭曲模型準確性與幻覺指標。
不正確或模糊的標註可能使準確的模型看似錯誤,或使有缺陷的模型看似可靠,複雜化幻覺診斷與模型排名。
該研究重新審視基於投票的物體探測評估(POPE)基準,測試視覺語言模型使用MSCOCO標籤辨識圖像中物體的能力。
POPE將幻覺重新定義為是/否分類任務,詢問模型圖像中是否包含特定物體,使用提示如“圖像中有嗎?”
視覺語言模型中的物體幻覺範例。粗體標籤標示原始標註中的物體;紅色標籤突出模型幻覺的物體。左側範例使用傳統評估,右側三例來自POPE變體。 來源:https://aclanthology.org/2023.emnlp-main.20.pdf
真實物體(答案:是)與不存在物體(答案:否)配對,隨機、頻繁或基於共現選擇。這實現了穩定、不依賴提示的幻覺評估,無需複雜的描述分析。
研究《RePOPE:標註錯誤對POPE基準的影響》重新檢查MSCOCO標籤,發現許多錯誤或模糊之處。
2014年MSCOCO資料集的圖像。 來源:https://arxiv.org/pdf/1405.0312
這些錯誤改變了模型排名,部分頂尖模型在對比修正標籤後表現下降。
使用原始POPE與重新標註的RePOPE測試開源視覺語言模型,顯示排名顯著變動,特別是F1分數,部分模型表現下降。
該研究認為標註錯誤掩蓋了模型的真實幻覺,提出RePOPE作為更準確的評估工具。
研究範例顯示POPE描述遺漏細微物體,如電車車廂旁的人或被網球選手遮擋的椅子。
方法論與測試
研究人員對MSCOCO標註進行重新標註,每例由兩名人工審查者處理。模糊案例,如下所述,被排除在測試之外。
POPE中模糊案例的標籤不清晰,如泰迪熊被標為熊或摩托車被標為自行車,因主觀分類及MSCOCO不一致被RePOPE排除。
論文指出:
“原始標註者忽略了背景中的人或玻璃後的人、被網球選手遮擋的椅子,或涼拌沙拉中模糊的胡蘿蔔。”
“MSCOCO標籤不一致,如將泰迪熊分類為熊或摩托車為自行車,源於物體定義的差異,這些案例被標為模糊。”
重新標註結果:POPE變體中,9.3%的‘是’標籤錯誤,13.8%模糊;1.7%的‘否’標籤錯誤,4.3%模糊。
研究團隊測試了開源模型,包括InternVL2.5、LLaVA-NeXT、Vicuna、Mistral 7b、Llama、LLaVA-OneVision、Ovis2、PaliGemma-3B及PaliGemma2,涵蓋POPE與RePOPE。
結果顯示原始標籤錯誤導致真陽性下降。假陽性在隨機子集近乎翻倍,流行子集穩定,對抗子集略減。重新標註改變F1排名,Ovis2-4B與-8B等模型名列前茅。
圖表顯示真陽性在各模型中下降,因正確答案常基於錯誤標籤,而假陽性則因子集不同而變化。
在POPE的隨機子集中,假陽性幾乎翻倍,揭示原始標註遺漏但實際存在的物體。在對抗子集中,假陽性下降,因不存在的物體常未標註但實際存在。
精確度與召回率受到影響,但模型排名保持穩定。F1分數(POPE的關鍵指標)顯著變動,頂尖模型如InternVL2.5-8B下降,Ovis2-4B與-8B上升。
由於修正資料集中正負樣本不均,準確度分數可靠性較低。
該研究強調高品質標註的必要性,並在GitHub分享修正標籤,指出RePOPE單獨無法完全解決基準飽和問題,因模型在真陽性與真陰性上仍超過90%。建議使用如DASH-B等額外基準。
結論
這項研究因資料集規模小而可行,突顯了擴展至超大規模資料集的挑戰,難以隔離代表性數據,可能導致結果偏差。
即使可行,當前方法顯示需要更好、更廣泛的人工標註。
「更好」與「更多」帶來不同挑戰。低成本平台如Amazon Mechanical Turk可能導致標註品質不佳,而外包至不同地區可能與模型預期用例不符。
這仍是機器學習經濟學中未解的核心問題。
首次發表於2025年4月23日,星期三










 全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優
全新榮威i6以65.9萬人民幣上市,搭載高通驍龍8155處理器與「斗寶」大模型
上汽榮威今日推出全新榮威i6,這款緊湊型轎車全面採用了榮威D7的設計語言。其獨特的大型直立式水箱護罩與橫向環形燈帶貫穿車頭,營造出強烈的科技感與視覺寬度。 車尾部分,上翹的鴨尾式尾翼與全寬尾燈相得益彰,賦予整車更顯活力的年輕氣息。全新榮威i6車身長4767毫米、寬1828毫米、高1498毫米,軸距為2755毫米。 得益於寬敞的車內空間,它躋身A+級轎車之列,在後排頭部空間與膝部空間方面具備顯著優
 如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
如何保護資產、建築物及個人健康?
在這個充滿變數的世界裡,保障已不再僅是選項,而是戰略上的必要之舉。無論是守護財務、強化建築結構,還是關注個人健康,長期的穩定都仰賴於主動規劃。真正的安全是多層次的,取決於財務管理、結構韌性與明智的健康意識三者相輔相成。守護最重要的事物,意味著必須未雨綢繆,而非僅在損害發生後才做出反應。財務保障:第一道防線每個人與每家企業都運作於財務架構之中。收入、支出、負債與投資構成了穩定的基石。若缺乏有條不紊的
 AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進
AI 瀏覽器 Comet 正式上線,在 iPad 上全面支援多工處理
Perplexity 的 AI 瀏覽器 Comet 已正式推出 iPad 版本,現已全面相容於 iPadOS。此次更新導入多視窗瀏覽功能、多工處理支援,並與 OpenAI 和 Anthropic 等頂尖 AI 模型深度整合,帶來更智能的網路體驗。Comet 瀏覽器拓展了使用者探索網路及與 AI 聊天機器人互動的方式,提供直觀的管道存取 OpenAI 和 Anthropic 等頂尖 AI 模型,以進

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的少年漫畫 AI 生成工具。我們精心挑選的頂級清單,匯集了能打造高張力動作場面與動態能量特效的強大工具。透過實際測試,比較免費與付費選項的差異。釋放您的創作潛能,今天就開始打造史詩級漫畫吧!
15 個工具
xix.ai

2026 年最新最佳 AI 報銷管理工具:備受好評的解決方案,可自動掃描收據並分類企業支出。探索強大且顛覆傳統的解決方案,助您輕鬆管理報銷、精準追蹤財務,並簡化合規流程。我們精心整理並每週更新的免費與付費方案比較指南,將協助您找到最合適的選擇。透過 XIX.AI 的專家精選,釋放您的 AI 優勢。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最新且評價最高的 AI 招聘工具。我們精心挑選的清單收錄了強大且具顛覆性的解決方案,可協助篩選履歷並自動化安排候選人面試。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即找到最適合您的招聘助手,並優化您的招聘流程!
10 個工具
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













