
















 Heim
HeimAI-Anmerkungsherausforderungen: Der Mythos der automatisierten Kennzeichnung
Die Forschung im Bereich maschinelles Lernen geht oft davon aus, dass AI die Annotation von Datensätzen verbessern kann, insbesondere Bildunterschriften für Vision-Sprach-Modelle (VLMs), um Kosten zu senken und die Belastung durch menschliche Überwachung zu reduzieren.
Dies erinnert an den „Download mehr RAM“-Meme aus den frühen 2000er Jahren, der die Vorstellung verspottet, dass Software Hardware-Beschränkungen beheben kann.
Dennoch wird die Qualität der Annotation oft übersehen, überschattet von der Aufregung um neue AI-Modelle, obwohl sie eine entscheidende Rolle in maschinellen Lernpipelines spielt.
Die Fähigkeit von AI, Muster zu erkennen und zu replizieren, hängt von hochwertigen, konsistenten menschlichen Annotationen ab – Labels und Beschreibungen, die von Menschen in unvollkommenen Umgebungen subjektiv erstellt werden.
Systeme, die darauf abzielen, das Verhalten von Annotatoren nachzuahmen, um Menschen zu ersetzen und genaue Kennzeichnung zu skalieren, scheitern, wenn sie mit Daten konfrontiert werden, die nicht in menschlich gelieferten Beispielen enthalten sind. Ähnlichkeit ist nicht gleichbedeutend mit Gleichwertigkeit, und domänenübergreifende Konsistenz bleibt in der Computer Vision schwer erreichbar.
Letztendlich definiert menschliches Urteilsvermögen die Daten, die AI-Systeme formen.
RAG-Lösungen
Bis vor kurzem wurden Fehler in Datensatz-Annotationen als geringfügige Kompromisse toleriert, angesichts der unvollkommenen, aber marktfähigen Ergebnisse generativer AI.
Eine Studie aus Singapur 2025 stellte fest, dass Halluzinationen – AI, die falsche Ausgaben generiert – inhärent im Design dieser Systeme sind.
RAG-basierte Agenten, die Fakten über Internetsuchen verifizieren, gewinnen in Forschung und kommerziellen Anwendungen an Bedeutung, erhöhen jedoch die Ressourcenkosten und verursachen Verzögerungen bei Anfragen. Neue Informationen, die auf trainierte Modelle angewendet werden, fehlt die Tiefe nativer Modellverbindungen.
Fehlerhafte Annotationen untergraben die Modellleistung, und die Verbesserung ihrer Qualität, obwohl aufgrund menschlicher Subjektivität unvollkommen, ist entscheidend.
RePOPE-Einblicke
Eine deutsche Studie deckt Mängel in älteren Datensätzen auf, mit Fokus auf die Genauigkeit von Bildunterschriften in Benchmarks wie MSCOCO. Sie zeigt, wie Fehler in Labels die Bewertung von Halluzinationen in Vision-Sprach-Modellen verzerren.

Beispiele aus einer aktuellen Studie, die falsche Objektidentifikationen in Bildunterschriften des MSCOCO-Datensatzes zeigen. Manuelle Überarbeitungen des POPE-Benchmarks verdeutlichen die Fallstricke der Kostensenkung bei der Annotationspflege. Quelle: https://arxiv.org/pdf/2504.15707
Stellen Sie sich ein AI vor, das ein Straßenbild auf ein Fahrrad hin bewertet. Wenn das Modell Ja sagt, der Datensatz aber Nein, wird es als falsch markiert. Wenn jedoch ein Fahrrad sichtbar ist, aber in der Annotation übersehen wurde, ist das Modell korrekt, und der Datensatz ist fehlerhaft. Solche Fehler verzerren die Modellgenauigkeit und Halluzinationsmetriken.
Falsche oder vage Annotationen können genaue Modelle fehleranfällig erscheinen lassen oder fehlerhafte Modelle zuverlässig wirken, was die Diagnose von Halluzinationen und die Modellbewertung erschwert.
Die Studie überprüft den Polling-based Object Probing Evaluation (POPE)-Benchmark, der die Fähigkeit von Vision-Sprach-Modellen testet, Objekte in Bildern mit MSCOCO-Labels zu identifizieren.
POPE formuliert Halluzination als Ja/Nein-Klassifikationsaufgabe und fragt Modelle, ob bestimmte Objekte in Bildern vorkommen, mit Prompts wie „Gibt es ein im Bild?“

Beispiele für Objekthalluzinationen in Vision-Sprach-Modellen. Fettgedruckte Labels markieren Objekte in ursprünglichen Annotationen; rote Labels heben von Modellen halluzinierte Objekte hervor. Das linke Beispiel verwendet traditionelle Bewertung, während die drei rechten aus POPE-Varianten stammen. Quelle: https://aclanthology.org/2023.emnlp-main.20.pdf
Grundwahrheits-Objekte (Antwort: Ja) werden mit nicht existierenden Objekten (Antwort: Nein) gepaart, die zufällig, häufig oder basierend auf Co-Occurrence ausgewählt werden. Dies ermöglicht eine stabile, von Prompts unabhängige Halluzinationsbewertung ohne komplexe Bildunterschriftenanalyse.
Die Studie, RePOPE: Einfluss von Annotationsfehlern auf den POPE-Benchmark, überprüft MSCOCO-Labels und findet viele Fehler oder Mehrdeutigkeiten.

Bilder aus dem MSCOCO-Datensatz von 2014. Quelle: https://arxiv.org/pdf/1405.0312
Diese Fehler verändern die Modellrankings, wobei einige Spitzenperformer bei Bewertung mit korrigierten Labels zurückfallen.
Tests an Open-Weight-Vision-Sprach-Modellen mit dem ursprünglichen POPE und dem neu gelabelten RePOPE zeigen erhebliche Verschiebungen im Ranking, insbesondere bei F1-Scores, wobei mehrere Modelle an Leistung einbüßen.
Die Studie argumentiert, dass Annotationsfehler echte Modellhalluzinationen verbergen und präsentiert RePOPE als genaueres Bewertungstool.

Beispiele aus der Studie zeigen, dass POPE-Bildunterschriften subtile Objekte übersehen, wie eine Person nahe einer Straßenbahnkabine oder ein vom Tennisspieler verdeckter Stuhl.
Methodik und Tests
Forscher haben MSCOCO-Annotationen mit zwei menschlichen Prüfern pro Instanz neu gelabelt. Mehrdeutige Fälle, wie die folgenden, wurden aus den Tests ausgeschlossen.

Mehrdeutige Fälle in POPE mit unklaren Labels, wie Teddybären als Bären oder Motorräder als Fahrräder, ausgeschlossen aus RePOPE aufgrund subjektiver Klassifikationen und MSCOCO-Inkonsistenzen.
Das Paper stellt fest:
„Ursprüngliche Annotatoren übersehen Menschen im Hintergrund oder hinter Glas, Stühle, die von einem Tennisspieler verdeckt werden, oder eine schwache Karotte in Krautsalat.“
„Inkonsistente MSCOCO-Labels, wie die Klassifizierung eines Teddybären als Bär oder eines Motorrads als Fahrrad, resultieren aus unterschiedlichen Objektdefinitionen, was solche Fälle als mehrdeutig kennzeichnet.“
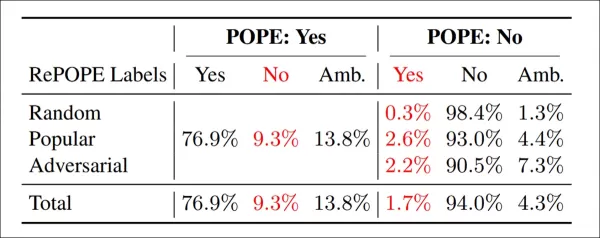
Ergebnisse der Neu-Annotation: In allen POPE-Varianten waren 9,3 % der ‚Ja‘-Labels falsch, 13,8 % mehrdeutig; 1,7 % der ‚Nein‘-Labels waren falsch gelabelt, 4,3 % mehrdeutig.
Das Team testete Open-Weight-Modelle, einschließlich InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B und PaliGemma2, anhand von POPE und RePOPE.
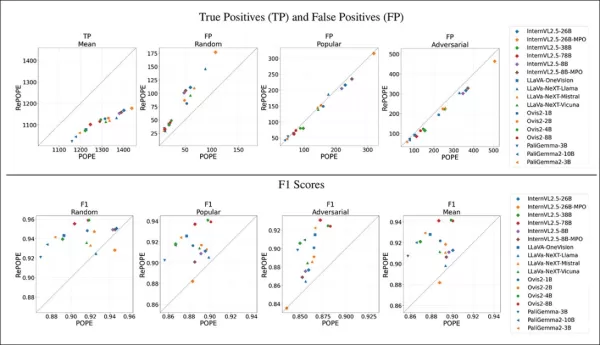
Ergebnisse zeigen, dass Fehler in den ursprünglichen Labels einen Rückgang der wahren Positiven verursachten. Falsche Positiven verdoppelten sich im zufälligen Subset, blieben im populären Subset stabil und nahmen im adversariellen Subset leicht ab. Neu-Labelung verschob F1-Rankings, wobei Modelle wie Ovis2-4B und -8B an die Spitze stiegen.
Grafiken zeigen, dass wahre Positiven bei allen Modellen zurückgingen, da korrekte Antworten oft auf fehlerhaften Labels basierten, während falsche Positiven variierten.
Im zufälligen Subset von POPE verdoppelten sich die falschen Positiven fast, da vorhandene, aber in den ursprünglichen Annotationen übersehene Objekte aufgedeckt wurden. Im adversariellen Subset sanken die falschen Positiven, da abwesende Objekte oft ungelabelt, aber vorhanden waren.
Präzision und Recall waren betroffen, aber die Modellrankings blieben stabil. F1-Scores, die zentrale Metrik von POPE, verschoben sich signifikant, wobei Top-Modelle wie InternVL2.5-8B zurückfielen und Ovis2-4B und -8B aufstiegen.
Genauigkeitsscores waren aufgrund ungleichmäßiger positiver und negativer Beispiele im korrigierten Datensatz weniger zuverlässig.
Die Studie betont die Notwendigkeit hochwertiger Annotationen und teilt korrigierte Labels auf GitHub, wobei sie anmerkt, dass RePOPE allein die Benchmarksättigung nicht vollständig löst, da Modelle immer noch über 90 % bei wahren Positiven und Negativen erreichen. Zusätzliche Benchmarks wie DASH-B werden empfohlen.
Fazit
Diese Studie, durchführbar aufgrund des kleinen Datensatzes, beleuchtet Herausforderungen bei der Skalierung auf Hyperscale-Datensätze, wo die Isolierung repräsentativer Daten schwierig ist und Ergebnisse verzerren kann.
Selbst wenn machbar, deuten aktuelle Methoden auf die Notwendigkeit besserer, umfassenderer menschlicher Annotation hin.
„Besser“ und „mehr“ stellen unterschiedliche Herausforderungen dar. Kostengünstige Plattformen wie Amazon Mechanical Turk riskieren schlechte Annotationsqualität, während Outsourcing in verschiedene Regionen nicht mit dem beabsichtigten Anwendungsfall des Modells übereinstimmen könnte.
Dies bleibt ein zentrales, ungelöstes Problem in der Ökonomie des maschinellen Lernens.
Erstmals veröffentlicht am Mittwoch, 23. April 2025
Verwandter Artikel
 Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Empfehlungen zu verwandten Spezialthemen
Geschäft
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
 10 Tools
10 Tools
 xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai
Code
Die besten KI-Tools für automatisierte Einheitstests: Generieren Sie mit nur einem Klick Jest-, PyTest- und JUnit-Testfälle.
Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

 Kommentare (2)
Kommentare (2)
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
Die Forschung im Bereich maschinelles Lernen geht oft davon aus, dass AI die Annotation von Datensätzen verbessern kann, insbesondere Bildunterschriften für Vision-Sprach-Modelle (VLMs), um Kosten zu senken und die Belastung durch menschliche Überwachung zu reduzieren.
Dies erinnert an den „Download mehr RAM“-Meme aus den frühen 2000er Jahren, der die Vorstellung verspottet, dass Software Hardware-Beschränkungen beheben kann.
Dennoch wird die Qualität der Annotation oft übersehen, überschattet von der Aufregung um neue AI-Modelle, obwohl sie eine entscheidende Rolle in maschinellen Lernpipelines spielt.
Die Fähigkeit von AI, Muster zu erkennen und zu replizieren, hängt von hochwertigen, konsistenten menschlichen Annotationen ab – Labels und Beschreibungen, die von Menschen in unvollkommenen Umgebungen subjektiv erstellt werden.
Systeme, die darauf abzielen, das Verhalten von Annotatoren nachzuahmen, um Menschen zu ersetzen und genaue Kennzeichnung zu skalieren, scheitern, wenn sie mit Daten konfrontiert werden, die nicht in menschlich gelieferten Beispielen enthalten sind. Ähnlichkeit ist nicht gleichbedeutend mit Gleichwertigkeit, und domänenübergreifende Konsistenz bleibt in der Computer Vision schwer erreichbar.
Letztendlich definiert menschliches Urteilsvermögen die Daten, die AI-Systeme formen.
RAG-Lösungen
Bis vor kurzem wurden Fehler in Datensatz-Annotationen als geringfügige Kompromisse toleriert, angesichts der unvollkommenen, aber marktfähigen Ergebnisse generativer AI.
Eine Studie aus Singapur 2025 stellte fest, dass Halluzinationen – AI, die falsche Ausgaben generiert – inhärent im Design dieser Systeme sind.
RAG-basierte Agenten, die Fakten über Internetsuchen verifizieren, gewinnen in Forschung und kommerziellen Anwendungen an Bedeutung, erhöhen jedoch die Ressourcenkosten und verursachen Verzögerungen bei Anfragen. Neue Informationen, die auf trainierte Modelle angewendet werden, fehlt die Tiefe nativer Modellverbindungen.
Fehlerhafte Annotationen untergraben die Modellleistung, und die Verbesserung ihrer Qualität, obwohl aufgrund menschlicher Subjektivität unvollkommen, ist entscheidend.
RePOPE-Einblicke
Eine deutsche Studie deckt Mängel in älteren Datensätzen auf, mit Fokus auf die Genauigkeit von Bildunterschriften in Benchmarks wie MSCOCO. Sie zeigt, wie Fehler in Labels die Bewertung von Halluzinationen in Vision-Sprach-Modellen verzerren.
Beispiele aus einer aktuellen Studie, die falsche Objektidentifikationen in Bildunterschriften des MSCOCO-Datensatzes zeigen. Manuelle Überarbeitungen des POPE-Benchmarks verdeutlichen die Fallstricke der Kostensenkung bei der Annotationspflege. Quelle: https://arxiv.org/pdf/2504.15707
Stellen Sie sich ein AI vor, das ein Straßenbild auf ein Fahrrad hin bewertet. Wenn das Modell Ja sagt, der Datensatz aber Nein, wird es als falsch markiert. Wenn jedoch ein Fahrrad sichtbar ist, aber in der Annotation übersehen wurde, ist das Modell korrekt, und der Datensatz ist fehlerhaft. Solche Fehler verzerren die Modellgenauigkeit und Halluzinationsmetriken.
Falsche oder vage Annotationen können genaue Modelle fehleranfällig erscheinen lassen oder fehlerhafte Modelle zuverlässig wirken, was die Diagnose von Halluzinationen und die Modellbewertung erschwert.
Die Studie überprüft den Polling-based Object Probing Evaluation (POPE)-Benchmark, der die Fähigkeit von Vision-Sprach-Modellen testet, Objekte in Bildern mit MSCOCO-Labels zu identifizieren.
POPE formuliert Halluzination als Ja/Nein-Klassifikationsaufgabe und fragt Modelle, ob bestimmte Objekte in Bildern vorkommen, mit Prompts wie „Gibt es ein
Beispiele für Objekthalluzinationen in Vision-Sprach-Modellen. Fettgedruckte Labels markieren Objekte in ursprünglichen Annotationen; rote Labels heben von Modellen halluzinierte Objekte hervor. Das linke Beispiel verwendet traditionelle Bewertung, während die drei rechten aus POPE-Varianten stammen. Quelle: https://aclanthology.org/2023.emnlp-main.20.pdf
Grundwahrheits-Objekte (Antwort: Ja) werden mit nicht existierenden Objekten (Antwort: Nein) gepaart, die zufällig, häufig oder basierend auf Co-Occurrence ausgewählt werden. Dies ermöglicht eine stabile, von Prompts unabhängige Halluzinationsbewertung ohne komplexe Bildunterschriftenanalyse.
Die Studie, RePOPE: Einfluss von Annotationsfehlern auf den POPE-Benchmark, überprüft MSCOCO-Labels und findet viele Fehler oder Mehrdeutigkeiten.
Bilder aus dem MSCOCO-Datensatz von 2014. Quelle: https://arxiv.org/pdf/1405.0312
Diese Fehler verändern die Modellrankings, wobei einige Spitzenperformer bei Bewertung mit korrigierten Labels zurückfallen.
Tests an Open-Weight-Vision-Sprach-Modellen mit dem ursprünglichen POPE und dem neu gelabelten RePOPE zeigen erhebliche Verschiebungen im Ranking, insbesondere bei F1-Scores, wobei mehrere Modelle an Leistung einbüßen.
Die Studie argumentiert, dass Annotationsfehler echte Modellhalluzinationen verbergen und präsentiert RePOPE als genaueres Bewertungstool.
Beispiele aus der Studie zeigen, dass POPE-Bildunterschriften subtile Objekte übersehen, wie eine Person nahe einer Straßenbahnkabine oder ein vom Tennisspieler verdeckter Stuhl.
Methodik und Tests
Forscher haben MSCOCO-Annotationen mit zwei menschlichen Prüfern pro Instanz neu gelabelt. Mehrdeutige Fälle, wie die folgenden, wurden aus den Tests ausgeschlossen.
Mehrdeutige Fälle in POPE mit unklaren Labels, wie Teddybären als Bären oder Motorräder als Fahrräder, ausgeschlossen aus RePOPE aufgrund subjektiver Klassifikationen und MSCOCO-Inkonsistenzen.
Das Paper stellt fest:
„Ursprüngliche Annotatoren übersehen Menschen im Hintergrund oder hinter Glas, Stühle, die von einem Tennisspieler verdeckt werden, oder eine schwache Karotte in Krautsalat.“
„Inkonsistente MSCOCO-Labels, wie die Klassifizierung eines Teddybären als Bär oder eines Motorrads als Fahrrad, resultieren aus unterschiedlichen Objektdefinitionen, was solche Fälle als mehrdeutig kennzeichnet.“
Ergebnisse der Neu-Annotation: In allen POPE-Varianten waren 9,3 % der ‚Ja‘-Labels falsch, 13,8 % mehrdeutig; 1,7 % der ‚Nein‘-Labels waren falsch gelabelt, 4,3 % mehrdeutig.
Das Team testete Open-Weight-Modelle, einschließlich InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B und PaliGemma2, anhand von POPE und RePOPE.
Ergebnisse zeigen, dass Fehler in den ursprünglichen Labels einen Rückgang der wahren Positiven verursachten. Falsche Positiven verdoppelten sich im zufälligen Subset, blieben im populären Subset stabil und nahmen im adversariellen Subset leicht ab. Neu-Labelung verschob F1-Rankings, wobei Modelle wie Ovis2-4B und -8B an die Spitze stiegen.
Grafiken zeigen, dass wahre Positiven bei allen Modellen zurückgingen, da korrekte Antworten oft auf fehlerhaften Labels basierten, während falsche Positiven variierten.
Im zufälligen Subset von POPE verdoppelten sich die falschen Positiven fast, da vorhandene, aber in den ursprünglichen Annotationen übersehene Objekte aufgedeckt wurden. Im adversariellen Subset sanken die falschen Positiven, da abwesende Objekte oft ungelabelt, aber vorhanden waren.
Präzision und Recall waren betroffen, aber die Modellrankings blieben stabil. F1-Scores, die zentrale Metrik von POPE, verschoben sich signifikant, wobei Top-Modelle wie InternVL2.5-8B zurückfielen und Ovis2-4B und -8B aufstiegen.
Genauigkeitsscores waren aufgrund ungleichmäßiger positiver und negativer Beispiele im korrigierten Datensatz weniger zuverlässig.
Die Studie betont die Notwendigkeit hochwertiger Annotationen und teilt korrigierte Labels auf GitHub, wobei sie anmerkt, dass RePOPE allein die Benchmarksättigung nicht vollständig löst, da Modelle immer noch über 90 % bei wahren Positiven und Negativen erreichen. Zusätzliche Benchmarks wie DASH-B werden empfohlen.
Fazit
Diese Studie, durchführbar aufgrund des kleinen Datensatzes, beleuchtet Herausforderungen bei der Skalierung auf Hyperscale-Datensätze, wo die Isolierung repräsentativer Daten schwierig ist und Ergebnisse verzerren kann.
Selbst wenn machbar, deuten aktuelle Methoden auf die Notwendigkeit besserer, umfassenderer menschlicher Annotation hin.
„Besser“ und „mehr“ stellen unterschiedliche Herausforderungen dar. Kostengünstige Plattformen wie Amazon Mechanical Turk riskieren schlechte Annotationsqualität, während Outsourcing in verschiedene Regionen nicht mit dem beabsichtigten Anwendungsfall des Modells übereinstimmen könnte.
Dies bleibt ein zentrales, ungelöstes Problem in der Ökonomie des maschinellen Lernens.
Erstmals veröffentlicht am Mittwoch, 23. April 2025










 Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
Die experimentelle KI „Claude“ von Anthropic wickelt in einem E-Commerce-Test Verhandlungen und Transaktionen ab
Angesichts der rasanten Fortschritte im Bereich der künstlichen Intelligenz hat Anthropic am vergangenen Freitag still und leise ein internes Experiment namens „Project Deal“ gestartet, um das Potenzi
 DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
DeepSeek Code steht kurz vor der Markteinführung
Angesichts der rasanten Entwicklung der KI-Technologie befindet sich DeepSeek an einem spannenden Wendepunkt. Das KI-Unternehmen gab kürzlich bekannt, dass es sich Finanzmittel in Höhe von über 70 Mil
 Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko
Musks Grok: 1,5 Billionen Parameter und die Übernahme von Cursor-Code – bahnbrechende Neuerung oder nur ein Bluff?
Elon Musk macht endlich einen Schritt.Im Wettlauf um die KI-Programmierung legen OpenAI und Anthropic einen Gang zu, während xAI hinterherzuhinken scheint. Musk hat oft sein Ziel bekräftigt, Claude Ko

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

Entdecken Sie die neuesten, hochbewerteten KI-Tools von 2026 für den automatisierten Unit-Testing-Prozess. Unsere sorgfältig ausgewählten Lösungen bieten leistungsstarke und bahnbrechende Funktionen, um sofort Jest-, PyTest- und JUnit-Testfälle zu generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings auf XIX.AI. Entfalten Sie Ihr KI-Potenzial und steigern Sie noch heute die Produktivität Ihrer Entwicklungstätigkeit.
10 Tools
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













