
















 Hogar
HogarDesafíos de la Anotación con IA: El Mito del Etiquetado Automatizado
La investigación en aprendizaje automático a menudo asume que la IA puede mejorar las anotaciones de conjuntos de datos, especialmente las descripciones de imágenes para modelos de visión-lenguaje (VLMs), para reducir costos y la carga de supervisión humana.
Esto recuerda al meme de principios de los 2000 "descarga más RAM", que se burlaba de la idea de que el software podía solucionar los límites del hardware.
Sin embargo, la calidad de la anotación a menudo se pasa por alto, opacada por el entusiasmo por los nuevos modelos de IA, a pesar de su papel crítico en los procesos de aprendizaje automático.
La capacidad de la IA para identificar y replicar patrones depende de anotaciones humanas de alta calidad y consistentes: etiquetas y descripciones creadas por personas que toman decisiones subjetivas en entornos imperfectos.
Los sistemas que intentan imitar el comportamiento de los anotadores para reemplazar a los humanos y escalar el etiquetado preciso enfrentan dificultades con datos no incluidos en los ejemplos proporcionados por humanos. La similitud no equivale a equivalencia, y la consistencia entre dominios sigue siendo esquiva en la visión por computadora.
En última instancia, el juicio humano define los datos que dan forma a los sistemas de IA.
Soluciones RAG
Hasta hace poco, los errores en las anotaciones de conjuntos de datos se toleraban como compensaciones menores, dado los resultados imperfectos pero comercializables de la IA generativa.
Un estudio de Singapur de 2025 encontró que las alucinaciones —la IA generando resultados falsos— son inherentes al diseño de estos sistemas.
Los agentes basados en RAG, que verifican hechos mediante búsquedas en internet, están ganando tracción en aplicaciones de investigación y comerciales, pero aumentan los costos de recursos y los retrasos en las consultas. La nueva información aplicada a modelos entrenados carece de la profundidad de las conexiones nativas del modelo.
Las anotaciones defectuosas socavan el rendimiento del modelo, y mejorar su calidad, aunque imperfecta debido a la subjetividad humana, es crítico.
Perspectivas de RePOPE
Un estudio alemán expone fallos en conjuntos de datos antiguos, enfocándose en la precisión de las descripciones de imágenes en puntos de referencia como MSCOCO. Revela cómo los errores en las etiquetas distorsionan las evaluaciones de alucinaciones en modelos de visión-lenguaje.

Ejemplos de un estudio reciente que muestra una identificación incorrecta de objetos en las descripciones del conjunto de datos MSCOCO. Las revisiones manuales al punto de referencia POPE destacan las trampas de reducir costos en la curación de anotaciones. Fuente: https://arxiv.org/pdf/2504.15707
Considera una IA evaluando una imagen de una escena callejera en busca de una bicicleta. Si el modelo dice sí pero el conjunto de datos afirma no, se marca como incorrecto. Sin embargo, si una bicicleta está visiblemente presente pero no se anotó, el modelo es correcto y el conjunto de datos está defectuoso. Tales errores sesgan la precisión del modelo y las métricas de alucinación.
Las anotaciones incorrectas o vagas pueden hacer que modelos precisos parezcan propensos a errores o que modelos defectuosos parezcan fiables, complicando el diagnóstico de alucinaciones y la clasificación de modelos.
El estudio revisita el punto de referencia de Evaluación de Sondeo de Objetos basado en Encuestas (POPE), que prueba la capacidad de los modelos de visión-lenguaje para identificar objetos en imágenes usando etiquetas de MSCOCO.
POPE replantea la alucinación como una tarea de clasificación sí/no, preguntando a los modelos si objetos específicos aparecen en las imágenes, usando prompts como “¿Hay un en la imagen?”

Ejemplos de alucinación de objetos en modelos de visión-lenguaje. Las etiquetas en negrita marcan objetos en las anotaciones originales; las etiquetas rojas destacan objetos alucinados por el modelo. El ejemplo de la izquierda usa una evaluación tradicional, mientras que los tres de la derecha provienen de variantes de POPE. Fuente: https://aclanthology.org/2023.emnlp-main.20.pdf
Los objetos de verdad (respuesta: Sí) se emparejan con objetos inexistentes (respuesta: No), seleccionados aleatoriamente, frecuentemente o basados en co-ocurrencia. Esto permite una evaluación de alucinaciones estable e independiente de prompts sin un análisis complejo de descripciones.
El estudio, RePOPE: Impacto de los Errores de Anotación en el Punto de Referencia POPE, revisa las etiquetas de MSCOCO y encuentra muchos errores o ambigüedades.

Imágenes del conjunto de datos MSCOCO de 2014. Fuente: https://arxiv.org/pdf/1405.0312
Estos errores alteran las clasificaciones de modelos, con algunos de los mejores desempeños cayendo al evaluarse contra etiquetas corregidas.
Las pruebas en modelos de visión-lenguaje de peso abierto usando el POPE original y el RePOPE reetiquetado muestran cambios significativos en las clasificaciones, especialmente en las puntuaciones F1, con varios modelos cayendo en rendimiento.
El estudio argumenta que los errores de anotación ocultan la verdadera alucinación del modelo, presentando a RePOPE como una herramienta de evaluación más precisa.

Ejemplos del estudio que muestran descripciones de POPE que omiten objetos sutiles, como una persona cerca de la cabina de un tranvía o una silla oscurecida por un tenista.
Metodología y Pruebas
Los investigadores reetiquetaron las anotaciones de MSCOCO con dos revisores humanos por instancia. Los casos ambiguos, como los descritos a continuación, fueron excluidos de las pruebas.

Casos ambiguos en POPE con etiquetas poco claras, como osos de peluche como osos o motocicletas como bicicletas, excluidos de RePOPE debido a clasificaciones subjetivas e inconsistencias de MSCOCO.
El artículo señala:
“Los anotadores originales pasaron por alto personas en el fondo o detrás de cristales, sillas oscurecidas por un tenista, o una zanahoria tenue en una ensalada de col.”
“Las etiquetas inconsistentes de MSCOCO, como clasificar un oso de peluche como oso o una motocicleta como bicicleta, provienen de definiciones de objetos variables, marcando tales casos como ambiguos.”
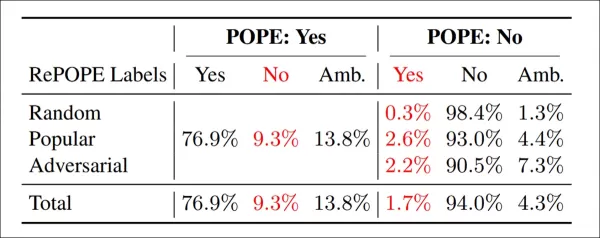
Resultados de la re-anotación: En las variantes de POPE, el 9.3% de las etiquetas ‘Sí’ fueron incorrectas, el 13.8% ambiguas; el 1.7% de las etiquetas ‘No’ estaban mal etiquetadas, el 4.3% ambiguas.
El equipo probó modelos de peso abierto, incluyendo InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B y PaliGemma2, en POPE y RePOPE.
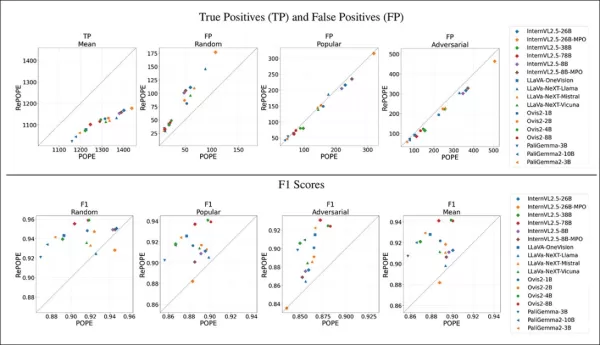
Los resultados muestran que los errores de etiquetas originales causaron una caída en los verdaderos positivos. Los falsos positivos se duplicaron en el subconjunto aleatorio, se mantuvieron estables en el subconjunto popular y disminuyeron ligeramente en el subconjunto adversario. El reetiquetado cambió las clasificaciones F1, con modelos como Ovis2-4B y -8B subiendo a la cima.
Los gráficos muestran que los verdaderos positivos cayeron en todos los modelos, ya que las respuestas correctas a menudo se basaban en etiquetas defectuosas, mientras que los falsos positivos variaron.
En el subconjunto aleatorio de POPE, los falsos positivos casi se duplicaron, revelando objetos presentes pero omitidos en las anotaciones originales. En el subconjunto adversario, los falsos positivos disminuyeron, ya que los objetos ausentes a menudo no estaban etiquetados pero presentes.
La precisión y el recuerdo se vieron afectados, pero las clasificaciones de modelos permanecieron estables. Las puntuaciones F1, la métrica clave de POPE, cambiaron significativamente, con los mejores modelos como InternVL2.5-8B cayendo y Ovis2-4B y -8B subiendo.
Las puntuaciones de precisión fueron menos fiables debido a ejemplos positivos y negativos desiguales en el conjunto de datos corregido.
El estudio enfatiza la necesidad de anotaciones de alta calidad y comparte etiquetas corregidas en GitHub, señalando que RePOPE por sí solo no aborda completamente la saturación de puntos de referencia, ya que los modelos aún obtienen más del 90% en verdaderos positivos y negativos. Se recomiendan puntos de referencia adicionales como DASH-B.
Conclusión
Este estudio, factible debido al pequeño conjunto de datos, destaca los desafíos de escalar a conjuntos de datos de hiperescala, donde aislar datos representativos es difícil y puede sesgar los resultados.
Incluso si es factible, los métodos actuales apuntan a la necesidad de una anotación humana mejor y más extensa.
‘Mejor’ y ‘más’ plantean desafíos distintos. Las plataformas de bajo costo como Amazon Mechanical Turk arriesgan anotaciones de mala calidad, mientras que la subcontratación a diferentes regiones puede no alinearse con el caso de uso previsto del modelo.
Esto sigue siendo un problema central y no resuelto en la economía del aprendizaje automático.
Publicado por primera vez el miércoles, 23 de abril de 2025
Artículo relacionado
 Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Recomendaciones de temas especiales relacionados
Negocio
Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Recomendaciones de temas especiales relacionados
Negocio
 Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
 10 herramientas
10 herramientas
 xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai
chatbot
Los mejores entrenadores de IA para ligar y conversar: mejora tu carisma social y tu confianza en tiempo real
Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

 comentario (2)
0/500
comentario (2)
0/500
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
La investigación en aprendizaje automático a menudo asume que la IA puede mejorar las anotaciones de conjuntos de datos, especialmente las descripciones de imágenes para modelos de visión-lenguaje (VLMs), para reducir costos y la carga de supervisión humana.
Esto recuerda al meme de principios de los 2000 "descarga más RAM", que se burlaba de la idea de que el software podía solucionar los límites del hardware.
Sin embargo, la calidad de la anotación a menudo se pasa por alto, opacada por el entusiasmo por los nuevos modelos de IA, a pesar de su papel crítico en los procesos de aprendizaje automático.
La capacidad de la IA para identificar y replicar patrones depende de anotaciones humanas de alta calidad y consistentes: etiquetas y descripciones creadas por personas que toman decisiones subjetivas en entornos imperfectos.
Los sistemas que intentan imitar el comportamiento de los anotadores para reemplazar a los humanos y escalar el etiquetado preciso enfrentan dificultades con datos no incluidos en los ejemplos proporcionados por humanos. La similitud no equivale a equivalencia, y la consistencia entre dominios sigue siendo esquiva en la visión por computadora.
En última instancia, el juicio humano define los datos que dan forma a los sistemas de IA.
Soluciones RAG
Hasta hace poco, los errores en las anotaciones de conjuntos de datos se toleraban como compensaciones menores, dado los resultados imperfectos pero comercializables de la IA generativa.
Un estudio de Singapur de 2025 encontró que las alucinaciones —la IA generando resultados falsos— son inherentes al diseño de estos sistemas.
Los agentes basados en RAG, que verifican hechos mediante búsquedas en internet, están ganando tracción en aplicaciones de investigación y comerciales, pero aumentan los costos de recursos y los retrasos en las consultas. La nueva información aplicada a modelos entrenados carece de la profundidad de las conexiones nativas del modelo.
Las anotaciones defectuosas socavan el rendimiento del modelo, y mejorar su calidad, aunque imperfecta debido a la subjetividad humana, es crítico.
Perspectivas de RePOPE
Un estudio alemán expone fallos en conjuntos de datos antiguos, enfocándose en la precisión de las descripciones de imágenes en puntos de referencia como MSCOCO. Revela cómo los errores en las etiquetas distorsionan las evaluaciones de alucinaciones en modelos de visión-lenguaje.
Ejemplos de un estudio reciente que muestra una identificación incorrecta de objetos en las descripciones del conjunto de datos MSCOCO. Las revisiones manuales al punto de referencia POPE destacan las trampas de reducir costos en la curación de anotaciones. Fuente: https://arxiv.org/pdf/2504.15707
Considera una IA evaluando una imagen de una escena callejera en busca de una bicicleta. Si el modelo dice sí pero el conjunto de datos afirma no, se marca como incorrecto. Sin embargo, si una bicicleta está visiblemente presente pero no se anotó, el modelo es correcto y el conjunto de datos está defectuoso. Tales errores sesgan la precisión del modelo y las métricas de alucinación.
Las anotaciones incorrectas o vagas pueden hacer que modelos precisos parezcan propensos a errores o que modelos defectuosos parezcan fiables, complicando el diagnóstico de alucinaciones y la clasificación de modelos.
El estudio revisita el punto de referencia de Evaluación de Sondeo de Objetos basado en Encuestas (POPE), que prueba la capacidad de los modelos de visión-lenguaje para identificar objetos en imágenes usando etiquetas de MSCOCO.
POPE replantea la alucinación como una tarea de clasificación sí/no, preguntando a los modelos si objetos específicos aparecen en las imágenes, usando prompts como “¿Hay un
Ejemplos de alucinación de objetos en modelos de visión-lenguaje. Las etiquetas en negrita marcan objetos en las anotaciones originales; las etiquetas rojas destacan objetos alucinados por el modelo. El ejemplo de la izquierda usa una evaluación tradicional, mientras que los tres de la derecha provienen de variantes de POPE. Fuente: https://aclanthology.org/2023.emnlp-main.20.pdf
Los objetos de verdad (respuesta: Sí) se emparejan con objetos inexistentes (respuesta: No), seleccionados aleatoriamente, frecuentemente o basados en co-ocurrencia. Esto permite una evaluación de alucinaciones estable e independiente de prompts sin un análisis complejo de descripciones.
El estudio, RePOPE: Impacto de los Errores de Anotación en el Punto de Referencia POPE, revisa las etiquetas de MSCOCO y encuentra muchos errores o ambigüedades.
Imágenes del conjunto de datos MSCOCO de 2014. Fuente: https://arxiv.org/pdf/1405.0312
Estos errores alteran las clasificaciones de modelos, con algunos de los mejores desempeños cayendo al evaluarse contra etiquetas corregidas.
Las pruebas en modelos de visión-lenguaje de peso abierto usando el POPE original y el RePOPE reetiquetado muestran cambios significativos en las clasificaciones, especialmente en las puntuaciones F1, con varios modelos cayendo en rendimiento.
El estudio argumenta que los errores de anotación ocultan la verdadera alucinación del modelo, presentando a RePOPE como una herramienta de evaluación más precisa.
Ejemplos del estudio que muestran descripciones de POPE que omiten objetos sutiles, como una persona cerca de la cabina de un tranvía o una silla oscurecida por un tenista.
Metodología y Pruebas
Los investigadores reetiquetaron las anotaciones de MSCOCO con dos revisores humanos por instancia. Los casos ambiguos, como los descritos a continuación, fueron excluidos de las pruebas.
Casos ambiguos en POPE con etiquetas poco claras, como osos de peluche como osos o motocicletas como bicicletas, excluidos de RePOPE debido a clasificaciones subjetivas e inconsistencias de MSCOCO.
El artículo señala:
“Los anotadores originales pasaron por alto personas en el fondo o detrás de cristales, sillas oscurecidas por un tenista, o una zanahoria tenue en una ensalada de col.”
“Las etiquetas inconsistentes de MSCOCO, como clasificar un oso de peluche como oso o una motocicleta como bicicleta, provienen de definiciones de objetos variables, marcando tales casos como ambiguos.”
Resultados de la re-anotación: En las variantes de POPE, el 9.3% de las etiquetas ‘Sí’ fueron incorrectas, el 13.8% ambiguas; el 1.7% de las etiquetas ‘No’ estaban mal etiquetadas, el 4.3% ambiguas.
El equipo probó modelos de peso abierto, incluyendo InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B y PaliGemma2, en POPE y RePOPE.
Los resultados muestran que los errores de etiquetas originales causaron una caída en los verdaderos positivos. Los falsos positivos se duplicaron en el subconjunto aleatorio, se mantuvieron estables en el subconjunto popular y disminuyeron ligeramente en el subconjunto adversario. El reetiquetado cambió las clasificaciones F1, con modelos como Ovis2-4B y -8B subiendo a la cima.
Los gráficos muestran que los verdaderos positivos cayeron en todos los modelos, ya que las respuestas correctas a menudo se basaban en etiquetas defectuosas, mientras que los falsos positivos variaron.
En el subconjunto aleatorio de POPE, los falsos positivos casi se duplicaron, revelando objetos presentes pero omitidos en las anotaciones originales. En el subconjunto adversario, los falsos positivos disminuyeron, ya que los objetos ausentes a menudo no estaban etiquetados pero presentes.
La precisión y el recuerdo se vieron afectados, pero las clasificaciones de modelos permanecieron estables. Las puntuaciones F1, la métrica clave de POPE, cambiaron significativamente, con los mejores modelos como InternVL2.5-8B cayendo y Ovis2-4B y -8B subiendo.
Las puntuaciones de precisión fueron menos fiables debido a ejemplos positivos y negativos desiguales en el conjunto de datos corregido.
El estudio enfatiza la necesidad de anotaciones de alta calidad y comparte etiquetas corregidas en GitHub, señalando que RePOPE por sí solo no aborda completamente la saturación de puntos de referencia, ya que los modelos aún obtienen más del 90% en verdaderos positivos y negativos. Se recomiendan puntos de referencia adicionales como DASH-B.
Conclusión
Este estudio, factible debido al pequeño conjunto de datos, destaca los desafíos de escalar a conjuntos de datos de hiperescala, donde aislar datos representativos es difícil y puede sesgar los resultados.
Incluso si es factible, los métodos actuales apuntan a la necesidad de una anotación humana mejor y más extensa.
‘Mejor’ y ‘más’ plantean desafíos distintos. Las plataformas de bajo costo como Amazon Mechanical Turk arriesgan anotaciones de mala calidad, mientras que la subcontratación a diferentes regiones puede no alinearse con el caso de uso previsto del modelo.
Esto sigue siendo un problema central y no resuelto en la economía del aprendizaje automático.
Publicado por primera vez el miércoles, 23 de abril de 2025










 Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
Haier lanza el robot exoesqueleto deportivo con IA más ligero del mundo, con un peso de tan solo 1,75 kg
El Grupo Haier ha presentado el robot exoesqueleto con inteligencia artificial más ligero del mundo para el deporte: el Haier Exoskeleton Robot W3. Este lanzamiento establece un nuevo récord del secto
 La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
La primera serie de AIGC de Yaoke Media, «El misterio del bronce en Qinling», se estrena hoy con protagonistas creados por IA
Hoy se estrena oficialmente la miniserie de misterio y fantasía con IA generativa (AIGC) de Yaoke Media, «La historia secreta del bronce de Qinling». Protagonizada por los dos primeros actores de IA c
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

Descubre los mejores cursos de 2026 sobre coqueteo y conversación con IA en XIX.AI. Nuestra selección, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a desarrollar tu carisma social y tu confianza en tiempo real. Explora herramientas imprescindibles y revolucionarias con comparativas entre versiones gratuitas y de pago, y clasificaciones que se actualizan semanalmente. Potencia hoy mismo tus habilidades sociales.
10 herramientas
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













