
















 집
집AI 주석 도전: 자동 라벨링의 신화
기계 학습 연구에서는 AI가 데이터셋 주석, 특히 시각-언어 모델(VLM)을 위한 이미지 캡션을 개선하여 비용을 절감하고 인간 감독 부담을 줄일 수 있다고 가정합니다.
이는 2000년대 초반 'RAM 더 다운로드' 밈을 떠올리게 하며, 소프트웨어가 하드웨어 한계를 해결할 수 있다는 아이디어를 비웃습니다.
그러나 주석 품질은 종종 간과되며, 새로운 AI 모델에 대한 소음에 묻혀 기계 학습 파이프라인에서 중요한 역할을 합니다.
AI가 패턴을 식별하고 복제하는 능력은 고품질의 일관된 인간 주석—사람들이 불완전한 환경에서 주관적인 판단으로 만든 라벨과 설명—에 달려 있습니다.
인간을 대체하고 정확한 라벨링을 확장하기 위해 주석자 행동을 모방하려는 시스템은 인간이 제공한 예시에 포함되지 않은 데이터에 직면하면 어려움을 겪습니다. 유사성은 동일성을 의미하지 않으며, 컴퓨터 비전에서 도메인 간 일관성은 여전히 어렵습니다.
궁극적으로 인간의 판단은 AI 시스템을 형성하는 데이터를 정의합니다.
RAG 솔루션
최근까지 데이터셋 주석의 오류는 생성 AI의 불완전하지만 시장성 있는 출력으로 인해 사소한 타협으로 용인되었습니다.
2025년 싱가포르 연구는 환각—AI가 잘못된 출력을 생성하는 것—이 이러한 시스템 설계에 내재되어 있음을 발견했습니다.
인터넷 검색을 통해 사실을 검증하는 RAG 기반 에이전트는 연구 및 상업 응용에서 주목받고 있지만, 자원 비용과 쿼리 지연을 증가시킵니다. 훈련된 모델에 적용된 새로운 정보는 네이티브 모델 연결의 깊이를 가지지 않습니다.
잘못된 주석은 모델 성능을 저해하며, 인간의 주관성으로 인해 불완전하지만 주석 품질을 개선하는 것이 중요합니다.
RePOPE 통찰
독일 연구는 오래된 데이터셋의 결함을 드러내며, MSCOCO와 같은 벤치마크에서 이미지 캡션 정확도에 초점을 맞췄습니다. 이는 라벨 오류가 시각-언어 모델의 환각 평가를 왜곡함을 보여줍니다.

최근 연구에서 MSCOCO 데이터셋 캡션의 잘못된 객체 식별을 보여주는 예시. POPE 벤치마크의 수동 수정은 주석 큐레이션 비용 절감의 함정을 강조합니다. 출처: https://arxiv.org/pdf/2504.15707
AI가 자전거가 있는 거리 장면 이미지를 평가한다고 가정해 봅시다. 모델이 예라고 답했지만 데이터셋이 아니오라고 주장하면 잘못된 것으로 표시됩니다. 그러나 자전거가 명확히 존재하지만 주석에서 누락되었다면, 모델은 맞고 데이터셋은 잘못된 것입니다. 이러한 오류는 모델 정확도와 환각 메트릭을 왜곡합니다.
부정확하거나 모호한 주석은 정확한 모델을 오류가 있는 것처럼 보이게 하거나, 잘못된 모델을 신뢰할 수 있는 것처럼 보이게 하여 환각 진단과 모델 순위를 복잡하게 합니다.
이 연구는 MSCOCO 라벨을 사용하여 이미지에서 객체 식별 능력을 테스트하는 POPE(폴링 기반 객체 탐지 평가) 벤치마크를 재검토합니다.
POPE는 환각을 예/아니오 분류 작업으로 재구성하여, “이미지에 가 있나요?”와 같은 프롬프트를 사용해 모델이 이미지에서 특정 객체를 식별하는지 묻습니다.

시각-언어 모델에서 객체 환각의 예시. 굵은 라벨은 원래 주석의 객체를 표시하고, 빨간 라벨은 모델이 환각한 객체를 강조합니다. 왼쪽 예시는 전통적인 평가를 사용하며, 오른쪽 세 예시는 POPE 변형에서 가져왔습니다. 출처: https://aclanthology.org/2023.emnlp-main.20.pdf
참인 객체(답변: 예)는 존재하지 않는 객체(답변: 아니오)와 쌍을 이루며, 무작위, 빈번, 또는 동시 발생을 기반으로 선택됩니다. 이를 통해 복잡한 캡션 분석 없이 안정적이고 프롬프트 독립적인 환각 평가가 가능합니다.
RePOPE: POPE 벤치마크에서 주석 오류의 영향 연구는 MSCOCO 라벨을 재검사하여 많은 오류와 모호성을 발견했습니다.

2014 MSCOCO 데이터셋의 이미지. 출처: https://arxiv.org/pdf/1405.0312
이러한 오류는 모델 순위를 변경하며, 일부 상위 모델은 수정된 라벨로 평가 시 순위가 하락했습니다.
원래 POPE와 재라벨링된 RePOPE를 사용한 오픈 웨이트 시각-언어 모델 테스트는 특히 F1 점수에서 큰 순위 변화를 보여주며, 여러 모델의 성능이 하락했습니다.
이 연구는 주석 오류가 실제 모델 환각을 숨긴다고 주장하며, RePOPE를 더 정확한 평가 도구로 제시합니다.

연구에서 POPE 캡션이 트램 객실 근처의 사람이나 테니스 선수에 가려진 의자와 같은 미묘한 객체를 놓친 예시.
방법론 및 테스트
연구자들은 인스턴스당 두 명의 인간 검토자를 통해 MSCOCO 주석을 재라벨링했습니다. 아래와 같은 모호한 사례는 테스트에서 제외되었습니다.

POPE에서 불명확한 라벨로 인한 모호한 사례, 예를 들어 테디베어가 곰으로, 오토바이가 자전거로 라벨링된 경우는 MSCOCO의 불일치와 주관적 분류로 인해 RePOPE에서 제외되었습니다.
논문은 다음과 같이 언급합니다:
“원래 주석자는 배경이나 유리 뒤의 사람, 테니스 선수에 가려진 의자, 또는 양배추 샐러드의 희미한 당근을 간과했습니다.”
“테디베어를 곰으로, 오토바이를 자전거로 분류하는 등 MSCOCO의 일관되지 않은 라벨은 객체 정의의 다양성에서 비롯되며, 이러한 사례를 모호한 것으로 표시합니다.”
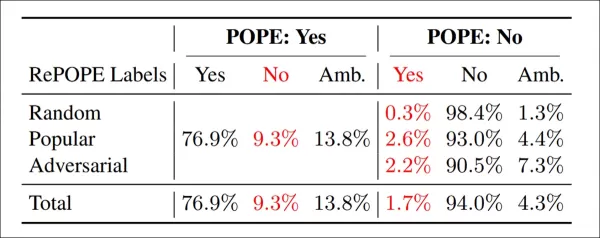
재주석 결과: POPE 변형에서 ‘예’ 라벨의 9.3%가 잘못, 13.8%가 모호; ‘아니오’ 라벨의 1.7%가 잘못, 4.3%가 모호.
팀은 InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B, PaliGemma2를 포함한 오픈 웨이트 모델을 POPE와 RePOPE에서 테스트했습니다.
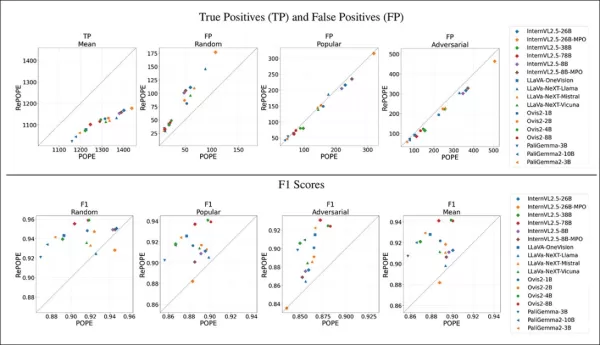
결과는 원래 라벨 오류로 인해 참 긍정이 하락했음을 보여줍니다. 거짓 긍정은 무작위 하위 집합에서 두 배가 되었고, 인기 하위 집합에서는 안정적이며, 적대적 하위 집합에서는 약간 감소했습니다. 재라벨링은 F1 순위를 변화시켰으며, Ovis2-4B와 -8B가 상위로 올라갔습니다.
그래프는 참 긍정이 모델 전반에서 하락했으며, 올바른 답변이 종종 잘못된 라벨에 기반했음을 보여줍니다. 거짓 긍정은 다양했습니다.
POPE의 무작위 하위 집합에서 거짓 긍정은 거의 두 배가 되었으며, 원래 주석에서 누락된 객체가 존재함을 드러냅니다. 적대적 하위 집합에서는 거짓 긍정이 감소했으며, 부재한 객체가 종종 라벨링되지 않았지만 존재했습니다.
정밀도와 재현율이 영향을 받았지만, 모델 순위는 안정적이었습니다. POPE의 주요 메트릭인 F1 점수는 크게 변화했으며, InternVL2.5-8B와 같은 상위 모델이 하락하고 Ovis2-4B와 -8B가 상승했습니다.
정확도 점수는 수정된 데이터셋의 불균등한 긍정 및 부정 예시로 인해 덜 신뢰할 수 있었습니다.
연구는 고품질 주석의 필요성을 강조하며, 수정된 라벨을 GitHub에 공유합니다. RePOPE만으로는 벤치마크 포화 문제를 완전히 해결하지 못하며, 모델은 여전히 참 긍정과 부정에서 90% 이상을 기록합니다. DASH-B와 같은 추가 벤치마크가 권장됩니다.
결론
이 연구는 소규모 데이터셋으로 인해 가능했으며, 대표 데이터를 분리하기 어려운 초대규모 데이터셋으로 확장하는 데 어려움을 강조합니다.
가능하더라도 현재 방법은 더 나은, 더 광범위한 인간 주석의 필요성을 나타냅니다.
‘더 나은’과 ‘더 많은’은 별개의 도전을 제기합니다. Amazon Mechanical Turk와 같은 저비용 플랫폼은 품질 낮은 주석의 위험을 초래하며, 다른 지역으로 아웃소싱하면 모델의 의도된 사용 사례와 맞지 않을 수 있습니다.
이는 기계 학습 경제학의 핵심적이고 해결되지 않은 문제로 남아 있습니다.
2025년 4월 23일 수요일 처음 게시됨
관련 기사
 클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
관련 특별 주제 추천
만화 창작
클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
관련 특별 주제 추천
만화 창작
 소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
 15 도구
15 도구
 xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

 의견 (2)
0/500
의견 (2)
0/500
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
기계 학습 연구에서는 AI가 데이터셋 주석, 특히 시각-언어 모델(VLM)을 위한 이미지 캡션을 개선하여 비용을 절감하고 인간 감독 부담을 줄일 수 있다고 가정합니다.
이는 2000년대 초반 'RAM 더 다운로드' 밈을 떠올리게 하며, 소프트웨어가 하드웨어 한계를 해결할 수 있다는 아이디어를 비웃습니다.
그러나 주석 품질은 종종 간과되며, 새로운 AI 모델에 대한 소음에 묻혀 기계 학습 파이프라인에서 중요한 역할을 합니다.
AI가 패턴을 식별하고 복제하는 능력은 고품질의 일관된 인간 주석—사람들이 불완전한 환경에서 주관적인 판단으로 만든 라벨과 설명—에 달려 있습니다.
인간을 대체하고 정확한 라벨링을 확장하기 위해 주석자 행동을 모방하려는 시스템은 인간이 제공한 예시에 포함되지 않은 데이터에 직면하면 어려움을 겪습니다. 유사성은 동일성을 의미하지 않으며, 컴퓨터 비전에서 도메인 간 일관성은 여전히 어렵습니다.
궁극적으로 인간의 판단은 AI 시스템을 형성하는 데이터를 정의합니다.
RAG 솔루션
최근까지 데이터셋 주석의 오류는 생성 AI의 불완전하지만 시장성 있는 출력으로 인해 사소한 타협으로 용인되었습니다.
2025년 싱가포르 연구는 환각—AI가 잘못된 출력을 생성하는 것—이 이러한 시스템 설계에 내재되어 있음을 발견했습니다.
인터넷 검색을 통해 사실을 검증하는 RAG 기반 에이전트는 연구 및 상업 응용에서 주목받고 있지만, 자원 비용과 쿼리 지연을 증가시킵니다. 훈련된 모델에 적용된 새로운 정보는 네이티브 모델 연결의 깊이를 가지지 않습니다.
잘못된 주석은 모델 성능을 저해하며, 인간의 주관성으로 인해 불완전하지만 주석 품질을 개선하는 것이 중요합니다.
RePOPE 통찰
독일 연구는 오래된 데이터셋의 결함을 드러내며, MSCOCO와 같은 벤치마크에서 이미지 캡션 정확도에 초점을 맞췄습니다. 이는 라벨 오류가 시각-언어 모델의 환각 평가를 왜곡함을 보여줍니다.
최근 연구에서 MSCOCO 데이터셋 캡션의 잘못된 객체 식별을 보여주는 예시. POPE 벤치마크의 수동 수정은 주석 큐레이션 비용 절감의 함정을 강조합니다. 출처: https://arxiv.org/pdf/2504.15707
AI가 자전거가 있는 거리 장면 이미지를 평가한다고 가정해 봅시다. 모델이 예라고 답했지만 데이터셋이 아니오라고 주장하면 잘못된 것으로 표시됩니다. 그러나 자전거가 명확히 존재하지만 주석에서 누락되었다면, 모델은 맞고 데이터셋은 잘못된 것입니다. 이러한 오류는 모델 정확도와 환각 메트릭을 왜곡합니다.
부정확하거나 모호한 주석은 정확한 모델을 오류가 있는 것처럼 보이게 하거나, 잘못된 모델을 신뢰할 수 있는 것처럼 보이게 하여 환각 진단과 모델 순위를 복잡하게 합니다.
이 연구는 MSCOCO 라벨을 사용하여 이미지에서 객체 식별 능력을 테스트하는 POPE(폴링 기반 객체 탐지 평가) 벤치마크를 재검토합니다.
POPE는 환각을 예/아니오 분류 작업으로 재구성하여, “이미지에 가 있나요?”와 같은 프롬프트를 사용해 모델이 이미지에서 특정 객체를 식별하는지 묻습니다.
시각-언어 모델에서 객체 환각의 예시. 굵은 라벨은 원래 주석의 객체를 표시하고, 빨간 라벨은 모델이 환각한 객체를 강조합니다. 왼쪽 예시는 전통적인 평가를 사용하며, 오른쪽 세 예시는 POPE 변형에서 가져왔습니다. 출처: https://aclanthology.org/2023.emnlp-main.20.pdf
참인 객체(답변: 예)는 존재하지 않는 객체(답변: 아니오)와 쌍을 이루며, 무작위, 빈번, 또는 동시 발생을 기반으로 선택됩니다. 이를 통해 복잡한 캡션 분석 없이 안정적이고 프롬프트 독립적인 환각 평가가 가능합니다.
RePOPE: POPE 벤치마크에서 주석 오류의 영향 연구는 MSCOCO 라벨을 재검사하여 많은 오류와 모호성을 발견했습니다.
2014 MSCOCO 데이터셋의 이미지. 출처: https://arxiv.org/pdf/1405.0312
이러한 오류는 모델 순위를 변경하며, 일부 상위 모델은 수정된 라벨로 평가 시 순위가 하락했습니다.
원래 POPE와 재라벨링된 RePOPE를 사용한 오픈 웨이트 시각-언어 모델 테스트는 특히 F1 점수에서 큰 순위 변화를 보여주며, 여러 모델의 성능이 하락했습니다.
이 연구는 주석 오류가 실제 모델 환각을 숨긴다고 주장하며, RePOPE를 더 정확한 평가 도구로 제시합니다.
연구에서 POPE 캡션이 트램 객실 근처의 사람이나 테니스 선수에 가려진 의자와 같은 미묘한 객체를 놓친 예시.
방법론 및 테스트
연구자들은 인스턴스당 두 명의 인간 검토자를 통해 MSCOCO 주석을 재라벨링했습니다. 아래와 같은 모호한 사례는 테스트에서 제외되었습니다.
POPE에서 불명확한 라벨로 인한 모호한 사례, 예를 들어 테디베어가 곰으로, 오토바이가 자전거로 라벨링된 경우는 MSCOCO의 불일치와 주관적 분류로 인해 RePOPE에서 제외되었습니다.
논문은 다음과 같이 언급합니다:
“원래 주석자는 배경이나 유리 뒤의 사람, 테니스 선수에 가려진 의자, 또는 양배추 샐러드의 희미한 당근을 간과했습니다.”
“테디베어를 곰으로, 오토바이를 자전거로 분류하는 등 MSCOCO의 일관되지 않은 라벨은 객체 정의의 다양성에서 비롯되며, 이러한 사례를 모호한 것으로 표시합니다.”
재주석 결과: POPE 변형에서 ‘예’ 라벨의 9.3%가 잘못, 13.8%가 모호; ‘아니오’ 라벨의 1.7%가 잘못, 4.3%가 모호.
팀은 InternVL2.5, LLaVA-NeXT, Vicuna, Mistral 7b, Llama, LLaVA-OneVision, Ovis2, PaliGemma-3B, PaliGemma2를 포함한 오픈 웨이트 모델을 POPE와 RePOPE에서 테스트했습니다.
결과는 원래 라벨 오류로 인해 참 긍정이 하락했음을 보여줍니다. 거짓 긍정은 무작위 하위 집합에서 두 배가 되었고, 인기 하위 집합에서는 안정적이며, 적대적 하위 집합에서는 약간 감소했습니다. 재라벨링은 F1 순위를 변화시켰으며, Ovis2-4B와 -8B가 상위로 올라갔습니다.
그래프는 참 긍정이 모델 전반에서 하락했으며, 올바른 답변이 종종 잘못된 라벨에 기반했음을 보여줍니다. 거짓 긍정은 다양했습니다.
POPE의 무작위 하위 집합에서 거짓 긍정은 거의 두 배가 되었으며, 원래 주석에서 누락된 객체가 존재함을 드러냅니다. 적대적 하위 집합에서는 거짓 긍정이 감소했으며, 부재한 객체가 종종 라벨링되지 않았지만 존재했습니다.
정밀도와 재현율이 영향을 받았지만, 모델 순위는 안정적이었습니다. POPE의 주요 메트릭인 F1 점수는 크게 변화했으며, InternVL2.5-8B와 같은 상위 모델이 하락하고 Ovis2-4B와 -8B가 상승했습니다.
정확도 점수는 수정된 데이터셋의 불균등한 긍정 및 부정 예시로 인해 덜 신뢰할 수 있었습니다.
연구는 고품질 주석의 필요성을 강조하며, 수정된 라벨을 GitHub에 공유합니다. RePOPE만으로는 벤치마크 포화 문제를 완전히 해결하지 못하며, 모델은 여전히 참 긍정과 부정에서 90% 이상을 기록합니다. DASH-B와 같은 추가 벤치마크가 권장됩니다.
결론
이 연구는 소규모 데이터셋으로 인해 가능했으며, 대표 데이터를 분리하기 어려운 초대규모 데이터셋으로 확장하는 데 어려움을 강조합니다.
가능하더라도 현재 방법은 더 나은, 더 광범위한 인간 주석의 필요성을 나타냅니다.
‘더 나은’과 ‘더 많은’은 별개의 도전을 제기합니다. Amazon Mechanical Turk와 같은 저비용 플랫폼은 품질 낮은 주석의 위험을 초래하며, 다른 지역으로 아웃소싱하면 모델의 의도된 사용 사례와 맞지 않을 수 있습니다.
이는 기계 학습 경제학의 핵심적이고 해결되지 않은 문제로 남아 있습니다.
2025년 4월 23일 수요일 처음 게시됨










 클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
 하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
하이얼, 무게가 단 1.75kg에 불과한 세계에서 가장 가벼운 AI 스포츠 외골격 로봇 출시
하이얼 그룹은 세계에서 가장 가벼운 AI 기반 스포츠용 외골격 로봇인 ‘하이얼 외골격 로봇 W3’를 선보였습니다. 이번 출시로 경량성 부문에서 업계 신기록을 세우며, 경량 설계 및 지능형 인간 동작 강화 분야에서 획기적인 진전을 이루었습니다.고급 소재가 구현한 초경량 디자인W3는 풀 카본 파이버와 티타늄 합금을 결합한 혁신적인 일체형 제조 공정을 적용했습니
 야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의
야오크 미디어의 첫 AIGC 드라마 '진링의 청동 미스터리'가 오늘 AI가 연기한 주연 배우들과 함께 공개된다
오늘, 야오케 미디어의 AIGC 판타지 미스터리 단편 드라마 《진링 청동의 비밀》이 공식 공개됩니다. 이 작품은 회사 최초의 AI 배우 두 명인 진링위예와 린시야녠이 주연을 맡았으며, 신비로운 진링 광산 지역을 배경으로 이야기가 펼쳐집니다. 은퇴한 정보 요원 진웨가 팀을 이끌고 이 지역 깊숙이 들어가, 오랫동안 묻혀 있던 광산 참사와 두 세대에 걸친 피의

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













