
















 首页
首页AI标注挑战:自动化标注的神话
机器学习研究常常假设AI可以增强数据集标注,特别是视觉-语言模型(VLM)的图像描述,以降低成本和减少人工监督负担。
这让人想起2000年代初的“下载更多RAM”迷因,嘲笑软件可以解决硬件限制的想法。
然而,标注质量常常被忽视,被新AI模型的热潮所掩盖,尽管它在机器学习流程中扮演着关键角色。
AI识别和复制模式的能力依赖于高质量、一致的人工标注——由人在不完美环境中做出的主观判断所创建的标签和描述。
旨在模仿标注者行为以取代人工并扩展准确标注的系统,在面对未包含在人工提供示例中的数据时会遇到困难。相似性并不等同于等价性,跨领域一致性在计算机视觉中仍难以实现。
最终,人类判断定义了塑造AI系统的数据。
RAG解决方案
直到最近,数据集标注中的错误被视为次要权衡,因为生成式AI的输出虽不完美但具有市场价值。
2025年新加坡的一项研究发现,幻觉——AI生成虚假输出——是这些系统设计中固有的问题。
基于RAG的代理通过网络搜索验证事实,在研究和商业应用中逐渐受到关注,但增加了资源成本和查询延迟。新信息应用于训练模型时缺乏原生模型连接的深度。
有缺陷的标注会削弱模型性能,提高标注质量虽然因人类主观性而不完美,但至关重要。
RePOPE洞察
德国的一项研究揭示了旧数据集的缺陷,重点关注MSCOCO等基准测试中的图像描述准确性。它展示了标签错误如何扭曲视觉-语言模型的幻觉评估。

近期研究中的示例,显示MSCOCO数据集描述中物体识别错误。对POPE基准的手动修订凸显了在标注管理上节省成本的弊端。 来源:https://arxiv.org/pdf/2504.15707
考虑一个AI评估街景图像是否存在自行车。如果模型说是,但数据集声称否,则被标记为错误。然而,如果图像中明显存在自行车但标注遗漏,模型是正确的,而数据集有缺陷。此类错误会扭曲模型准确性和幻觉指标。
不正确或模糊的标注可能使准确的模型看似错误,或使有缺陷的模型看似可靠,复杂化幻觉诊断和模型排名。
该研究重新审视了基于投票的对象探测评估(POPE)基准,测试视觉-语言模型使用MSCOCO标签识别图像中物体的能力。
POPE将幻觉重新定义为是/否分类任务,通过提示如“图像中有吗?”询问模型特定物体是否出现在图像中。

视觉-语言模型中的物体幻觉示例。加粗标签标记原始标注中的物体;红色标签高亮模型产生的幻觉物体。左侧示例使用传统评估,右侧三个示例来自POPE变体。 来源:https://aclanthology.org/2023.emnlp-main.20.pdf
真实物体(答案:是)与不存在的物体(答案:否)配对,随机、频繁或基于共现选择。这实现了无需复杂描述分析的稳定、与提示无关的幻觉评估。
该研究,RePOPE:标注错误对POPE基准的影响,重新检查MSCOCO标签,发现许多错误或模糊之处。

2014年MSCOCO数据集中的图像。 来源:https://arxiv.org/pdf/1405.0312
这些错误改变了模型排名,一些高性能模型在针对修正标签评估时排名下降。
在原始POPE和重新标注的RePOPE上测试开源视觉-语言模型,显示排名显著变化,特别是在F1分数上,几个模型性能下降。
该研究认为,标注错误掩盖了模型的真实幻觉,提出RePOPE作为更准确的评估工具。

研究中的示例显示POPE描述遗漏了细微物体,如有轨电车车厢旁的人或被网球选手遮挡的椅子。
方法与测试
研究人员为MSCOCO标注重新标注,每实例由两名人工审查员处理。模糊案例,如下所述,被排除在测试之外。

POPE中的模糊案例,如泰迪熊被标注为熊或摩托车被标注为自行车,因主观分类和MSCOCO不一致而被RePOPE排除。
论文指出:
“原始标注者忽略了背景中的人或玻璃后的人,被网球选手遮挡的椅子,或凉拌卷心菜中模糊的胡萝卜。”
“MSCOCO标签不一致,如将泰迪熊分类为熊或摩托车分类为自行车,源于不同的物体定义,使此类案例被标记为模糊。”
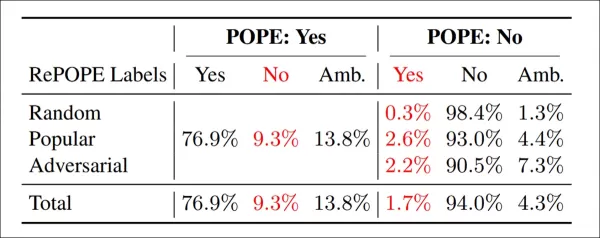
重新标注结果:在POPE变体中,‘是’标签中有9.3%不正确,13.8%模糊;‘否’标签中有1.7%错误,4.3%模糊。
团队测试了开源模型,包括InternVL2.5、LLaVA-NeXT、Vicuna、Mistral 7b、Llama、LLaVA-OneVision、Ovis2、PaliGemma-3B和PaliGemma2,跨POPE和RePOPE进行测试。
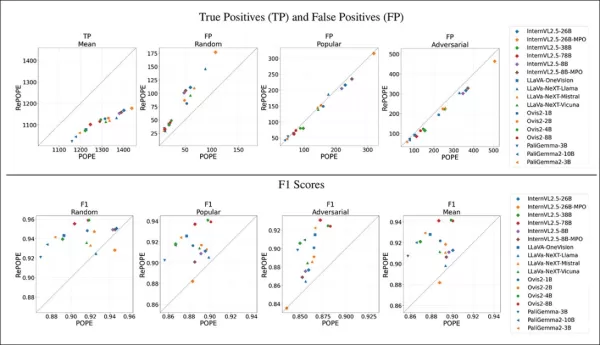
结果显示,原始标签错误导致真正例下降。虚假正例在随机子集上翻倍,流行子集上保持稳定,对抗子集上略降。重新标注改变了F1排名,Ovis2-4B和-8B等模型名列前茅。
图表显示,真正例在所有模型中下降,因为正确答案往往基于错误标签,而虚假正例变化不一。
在POPE的随机子集中,虚假正例几乎翻倍,揭示了存在但原始标注遗漏的物体。在对抗子集中,虚假正例下降,因为未标注但存在的物体常被忽略。
精确度和召回率受到影响,但模型排名保持稳定。F1分数,POPE的关键指标,显著变化,顶级模型如InternVL2.5-8B下降,Ovis2-4B和-8B上升。
由于修正数据集中正负样本不平衡,准确度分数可靠性较低。
该研究强调高质量标注的必要性,并在GitHub上共享了修正标签,指出RePOPE单独无法完全解决基准饱和问题,因为模型在真正例和负例上仍得分超过90%。建议使用DASH-B等额外基准。
结论
这项研究因数据集较小而可行,突显了扩展到超大规模数据集的挑战,隔离代表性数据很困难,可能导致结果偏差。
即使可行,当前方法表明需要更好、更广泛的人工标注。
“更好”和“更多”带来了不同挑战。像Amazon Mechanical Turk这样的低成本平台可能导致标注质量差,而外包到不同地区可能与模型预期用例不符。
这仍是机器学习经济学中一个核心、未解决的问题。
首次发布于2025年4月23日,星期三
相关文章
 小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
相关专题推荐
漫画创作
小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
相关专题推荐
漫画创作
 少年漫画顶级AI生成器:打造高能动作场面与特效
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
 15 个工具
15 个工具
 xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai
生产率
AI个人健康与专注力教练:缓解倦怠,提升精神能量
立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai
聊天机器人
备受好评的AI浪漫聊天机器人:凭借稳定的个性建立长期关系
探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai
教育与学习
最佳AI数据科学导师:精通SQL、Pandas及机器学习工作流程
探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

 评论 (2)
0/500
评论 (2)
0/500
![RaymondWalker]()
Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
![KeithSanchez]()
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?
机器学习研究常常假设AI可以增强数据集标注,特别是视觉-语言模型(VLM)的图像描述,以降低成本和减少人工监督负担。
这让人想起2000年代初的“下载更多RAM”迷因,嘲笑软件可以解决硬件限制的想法。
然而,标注质量常常被忽视,被新AI模型的热潮所掩盖,尽管它在机器学习流程中扮演着关键角色。
AI识别和复制模式的能力依赖于高质量、一致的人工标注——由人在不完美环境中做出的主观判断所创建的标签和描述。
旨在模仿标注者行为以取代人工并扩展准确标注的系统,在面对未包含在人工提供示例中的数据时会遇到困难。相似性并不等同于等价性,跨领域一致性在计算机视觉中仍难以实现。
最终,人类判断定义了塑造AI系统的数据。
RAG解决方案
直到最近,数据集标注中的错误被视为次要权衡,因为生成式AI的输出虽不完美但具有市场价值。
2025年新加坡的一项研究发现,幻觉——AI生成虚假输出——是这些系统设计中固有的问题。
基于RAG的代理通过网络搜索验证事实,在研究和商业应用中逐渐受到关注,但增加了资源成本和查询延迟。新信息应用于训练模型时缺乏原生模型连接的深度。
有缺陷的标注会削弱模型性能,提高标注质量虽然因人类主观性而不完美,但至关重要。
RePOPE洞察
德国的一项研究揭示了旧数据集的缺陷,重点关注MSCOCO等基准测试中的图像描述准确性。它展示了标签错误如何扭曲视觉-语言模型的幻觉评估。
近期研究中的示例,显示MSCOCO数据集描述中物体识别错误。对POPE基准的手动修订凸显了在标注管理上节省成本的弊端。 来源:https://arxiv.org/pdf/2504.15707
考虑一个AI评估街景图像是否存在自行车。如果模型说是,但数据集声称否,则被标记为错误。然而,如果图像中明显存在自行车但标注遗漏,模型是正确的,而数据集有缺陷。此类错误会扭曲模型准确性和幻觉指标。
不正确或模糊的标注可能使准确的模型看似错误,或使有缺陷的模型看似可靠,复杂化幻觉诊断和模型排名。
该研究重新审视了基于投票的对象探测评估(POPE)基准,测试视觉-语言模型使用MSCOCO标签识别图像中物体的能力。
POPE将幻觉重新定义为是/否分类任务,通过提示如“图像中有吗?”询问模型特定物体是否出现在图像中。
视觉-语言模型中的物体幻觉示例。加粗标签标记原始标注中的物体;红色标签高亮模型产生的幻觉物体。左侧示例使用传统评估,右侧三个示例来自POPE变体。 来源:https://aclanthology.org/2023.emnlp-main.20.pdf
真实物体(答案:是)与不存在的物体(答案:否)配对,随机、频繁或基于共现选择。这实现了无需复杂描述分析的稳定、与提示无关的幻觉评估。
该研究,RePOPE:标注错误对POPE基准的影响,重新检查MSCOCO标签,发现许多错误或模糊之处。
2014年MSCOCO数据集中的图像。 来源:https://arxiv.org/pdf/1405.0312
这些错误改变了模型排名,一些高性能模型在针对修正标签评估时排名下降。
在原始POPE和重新标注的RePOPE上测试开源视觉-语言模型,显示排名显著变化,特别是在F1分数上,几个模型性能下降。
该研究认为,标注错误掩盖了模型的真实幻觉,提出RePOPE作为更准确的评估工具。
研究中的示例显示POPE描述遗漏了细微物体,如有轨电车车厢旁的人或被网球选手遮挡的椅子。
方法与测试
研究人员为MSCOCO标注重新标注,每实例由两名人工审查员处理。模糊案例,如下所述,被排除在测试之外。
POPE中的模糊案例,如泰迪熊被标注为熊或摩托车被标注为自行车,因主观分类和MSCOCO不一致而被RePOPE排除。
论文指出:
“原始标注者忽略了背景中的人或玻璃后的人,被网球选手遮挡的椅子,或凉拌卷心菜中模糊的胡萝卜。”
“MSCOCO标签不一致,如将泰迪熊分类为熊或摩托车分类为自行车,源于不同的物体定义,使此类案例被标记为模糊。”
重新标注结果:在POPE变体中,‘是’标签中有9.3%不正确,13.8%模糊;‘否’标签中有1.7%错误,4.3%模糊。
团队测试了开源模型,包括InternVL2.5、LLaVA-NeXT、Vicuna、Mistral 7b、Llama、LLaVA-OneVision、Ovis2、PaliGemma-3B和PaliGemma2,跨POPE和RePOPE进行测试。
结果显示,原始标签错误导致真正例下降。虚假正例在随机子集上翻倍,流行子集上保持稳定,对抗子集上略降。重新标注改变了F1排名,Ovis2-4B和-8B等模型名列前茅。
图表显示,真正例在所有模型中下降,因为正确答案往往基于错误标签,而虚假正例变化不一。
在POPE的随机子集中,虚假正例几乎翻倍,揭示了存在但原始标注遗漏的物体。在对抗子集中,虚假正例下降,因为未标注但存在的物体常被忽略。
精确度和召回率受到影响,但模型排名保持稳定。F1分数,POPE的关键指标,显著变化,顶级模型如InternVL2.5-8B下降,Ovis2-4B和-8B上升。
由于修正数据集中正负样本不平衡,准确度分数可靠性较低。
该研究强调高质量标注的必要性,并在GitHub上共享了修正标签,指出RePOPE单独无法完全解决基准饱和问题,因为模型在真正例和负例上仍得分超过90%。建议使用DASH-B等额外基准。
结论
这项研究因数据集较小而可行,突显了扩展到超大规模数据集的挑战,隔离代表性数据很困难,可能导致结果偏差。
即使可行,当前方法表明需要更好、更广泛的人工标注。
“更好”和“更多”带来了不同挑战。像Amazon Mechanical Turk这样的低成本平台可能导致标注质量差,而外包到不同地区可能与模型预期用例不符。
这仍是机器学习经济学中一个核心、未解决的问题。
首次发布于2025年4月23日,星期三










 小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
小红书进行组织架构调整:柯南出任总裁,新设AI主营部门Dots及海外业务部门Rednote
4月30日,小红书向全体员工发布内部通告,宣布启动新一轮组织架构调整。此次调整的核心在于将社区、电商和商业化三大业务线与公司的技术系统全面整合。 公司新设了名为“Dots”的AI优先部门,这标志着小红书已正式将AI提升为最高战略优先级,旨在使其从工具性功能转变为核心生产力。在人事任命方面,南(丁玲)被任命为小红书总裁,负责公司核心业务运营,并直接向CEO邢宇汇报。 各业务板块负责人也已明确:智恒将
 腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
腾讯旗下“小龙虾”表现远超预期,团队将运力扩大10倍,并致歉及提供补偿
腾讯正式推出全场景AI智能助手“WorkBuddy”,凭借高度集成和低部署门槛,标志着大型模型应用层竞争进入新阶段。该产品在发布当天便引发了业界广泛关注。 用户流量远超预期,导致相关产品腾讯云代码助手(CodeBuddy)出现登录故障及服务不稳定。腾讯云团队随后发布致歉声明,表示技术团队已紧急将容量扩容十倍,目前服务已全面恢复。受影响用户获得了5,000腾讯云代金券作为补偿。业界观察人士将Work
 Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争
Suno领投方:删除帖子无法填补版权诉讼的漏洞
备受瞩目的AI音乐生成平台Suno正面临一场艰难的版权诉讼,而其领投投资人的坦率言论,可能恰恰为对方提供了他们梦寐以求的证据。 Menlo Ventures(Suno的核心投资者)合伙人C.C. Gong近日删除了一个推文,该推文与公司当前的法律辩护策略直接相悖。在之前的版权诉讼中,Suno的辩护主要依赖“合理使用”的论点,声称AI生成的音乐仅仅是一种“工具”,既不会直接与受版权保护的原创作品竞争

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

立即访问 XIX.AI,探索 2026 年最优秀的 AI 个人健康与专注力教练。我们的精选排行榜汇集了广受好评、具有颠覆性意义的工具,助您缓解倦怠、提升精神能量。通过真实案例分析,对比免费与付费选项。立即开启通往巅峰生产力和身心健康的道路。
10 个工具
xix.ai

探索2026年最新、评价最高的人工智能浪漫聊天机器人,助您建立真实而长久的联系。我们的精选清单涵盖了功能强大且性格鲜明的聊天机器人,并提供了免费与付费版本的对比分析以及实际测试结果。在XIX.AI上找到您的完美伴侣,立即开始建立联系吧。
10 个工具
xix.ai

探索2026年最优秀的人工智能数据科学导师,帮助他们掌握SQL、Pandas以及机器学习工作流程。在XIX.AI上查看我们精心挑选的顶级导师名单,获得强大而具有变革性的指导。通过对比免费和付费选项,并结合实际应用案例进行了解,今天就开启你的数据科学精通之路吧。
10 个工具
xix.ai

Qué interesante plantean esto de la anotación automatizada. A veces da la sensación de que solo queremos reemplazar el trabajo humano sin pensar en las consecuencias... ¿Realmente es más preciso dejarle todo a la IA? 🤔 Me pregunto si esto no terminará generando más problemas de los que resuelve.
L'article sur les défis de l'annotation par IA est super intéressant ! 😊 J'avais jamais réalisé à quel point l'étiquetage automatique pouvait être un casse-tête. Ça me fait penser : est-ce qu'on surestime trop les capacités de l'IA dans ce domaine ?













