
















 Maison
MaisonL'annonceur cible les «hiboux et lézards» dans l'analyse d'audience
L'industrie de la publicité en ligne a investi un montant impressionnant de 740,3 milliards de dollars USD dans ses efforts en 2023, ce qui explique pourquoi les entreprises de ce secteur sont si déterminées à faire progresser la recherche en vision par ordinateur. Elles se concentrent particulièrement sur les technologies de reconnaissance faciale et du regard, l'estimation de l'âge jouant un rôle clé dans l'analyse démographique. Cela est crucial pour les annonceurs cherchant à cibler des groupes d'âge spécifiques.
Bien que l'industrie ait tendance à garder ses cartes près du cœur, elle partage occasionnellement des aperçus de ses travaux propriétaires plus avancés à travers des études publiées. Ces études impliquent souvent des participants ayant consenti à faire partie d'analyses pilotées par l'IA, visant à comprendre comment les spectateurs interagissent avec les publicités.
 *L'estimation de l'âge dans un contexte publicitaire en conditions réelles intéresse les annonceurs qui ciblent un groupe démographique particulier. Dans cet exemple expérimental d'estimation automatique de l'âge facial, l'âge de l'artiste Bob Dylan est suivi au fil des années.* Source : https://arxiv.org/pdf/1906.03625
*L'estimation de l'âge dans un contexte publicitaire en conditions réelles intéresse les annonceurs qui ciblent un groupe démographique particulier. Dans cet exemple expérimental d'estimation automatique de l'âge facial, l'âge de l'artiste Bob Dylan est suivi au fil des années.* Source : https://arxiv.org/pdf/1906.03625
L'un des outils fréquemment utilisés dans ces systèmes d'estimation faciale est l'Histogramme des Gradients Orientés (HoG) de Dlib, qui aide à analyser les traits du visage.
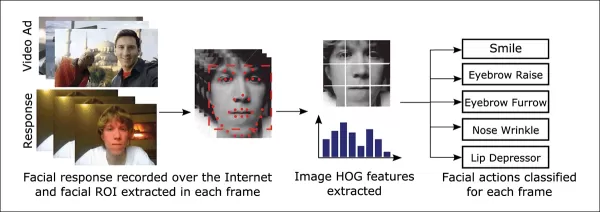 *L'Histogramme des Gradients Orientés (HoG) de Dlib est souvent utilisé dans les systèmes d'estimation faciale.* Source : https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
*L'Histogramme des Gradients Orientés (HoG) de Dlib est souvent utilisé dans les systèmes d'estimation faciale.* Source : https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Instinct animal
En matière de compréhension de l'engagement des spectateurs, l'industrie publicitaire s'intéresse particulièrement à l'identification des faux positifs – des cas où le système interprète mal les actions d'un spectateur – et à l'établissement de critères clairs pour déterminer quand une personne n'est pas pleinement engagée avec une publicité. Cela est particulièrement pertinent dans la publicité sur écran, où les études se concentrent sur deux environnements principaux : le bureau et le mobile, chacun nécessitant des solutions de suivi adaptées.
Les annonceurs classent souvent le désengagement des spectateurs en deux comportements : le « comportement de hibou » et le « comportement de lézard ». Si vous détournez la tête de la publicité, c'est un « comportement de hibou ». Si votre tête reste immobile mais que vos yeux s'éloignent de l'écran, c'est un « comportement de lézard ». Ces comportements sont cruciaux pour que les systèmes les capturent précisément lors des tests de nouvelles publicités dans des conditions contrôlées.
 *Exemples de comportements de « hibou » et de « lézard » chez un sujet d'un projet de recherche publicitaire.* Source : https://arxiv.org/pdf/1508.04028
*Exemples de comportements de « hibou » et de « lézard » chez un sujet d'un projet de recherche publicitaire.* Source : https://arxiv.org/pdf/1508.04028
Un article récent de l'acquisition d'Affectiva par SmartEye aborde ces problèmes de front. Il propose une architecture qui combine plusieurs cadres existants pour créer un ensemble complet de fonctionnalités permettant de détecter l'attention des spectateurs dans différentes conditions et réactions. Ce système peut déterminer si un spectateur est ennuyé, engagé ou distrait par le contenu que l'annonceur souhaite qu'il regarde.
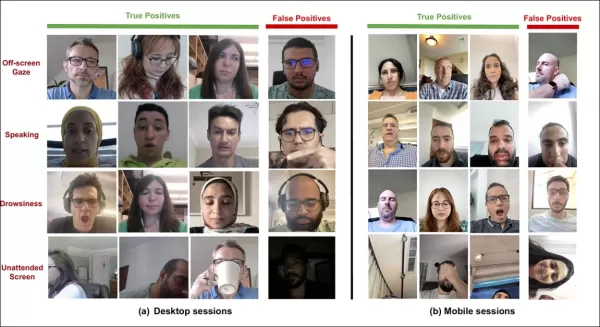 *Exemples de vrais et faux positifs détectés par le nouveau système d'attention pour divers signaux de distraction, présentés séparément pour les appareils de bureau et mobiles.* Source : https://arxiv.org/pdf/2504.06237
*Exemples de vrais et faux positifs détectés par le nouveau système d'attention pour divers signaux de distraction, présentés séparément pour les appareils de bureau et mobiles.* Source : https://arxiv.org/pdf/2504.06237
Les auteurs de l'article soulignent le peu de recherches sur la surveillance de l'attention pendant les publicités en ligne et notent que les études précédentes ont souvent négligé des facteurs critiques comme le type d'appareil, le placement de la caméra et la taille de l'écran. Leur architecture proposée vise à combler ces lacunes en détectant divers distracteurs, y compris les comportements de hibou et de lézard, la parole, la somnolence et les écrans non surveillés, tout en intégrant des fonctionnalités spécifiques à l'appareil pour améliorer la précision.
L'article, intitulé « Surveillance de l'attention des spectateurs pendant les publicités en ligne », a été rédigé par quatre chercheurs d'Affectiva.
Méthode et données
Compte tenu de la nature secrète de ces systèmes, l'article ne compare pas directement son approche avec celle des concurrents, mais présente ses résultats à travers des études d'ablation. Il s'écarte du format typique de la littérature sur la vision par ordinateur, nous explorerons donc la recherche telle qu'elle est présentée.
Les auteurs soulignent que peu d'études ont spécifiquement abordé la détection de l'attention dans le contexte des publicités en ligne. Par exemple, le SDK AFFDEX, qui offre une reconnaissance multifaciale en temps réel, infère l'attention uniquement à partir de la posture de la tête, qualifiant les participants d'inattentifs si l'angle de leur tête dépasse un certain seuil.
 *Un exemple du SDK AFFDEX, un système d'Affectiva qui repose sur la posture de la tête comme indicateur d'attention.* Source : https://www.youtube.com/watch?v=c2CWb5jHmbY
*Un exemple du SDK AFFDEX, un système d'Affectiva qui repose sur la posture de la tête comme indicateur d'attention.* Source : https://www.youtube.com/watch?v=c2CWb5jHmbY
Dans une collaboration de 2019 intitulée « Mesure automatique de l'attention visuelle au contenu vidéo à l'aide de l'apprentissage profond », un ensemble de données d'environ 28 000 participants a été annoté pour divers comportements inattentifs, et un modèle CNN-LSTM a été entraîné pour détecter l'attention à partir de l'apparence faciale au fil du temps.
 *Extrait de l'article de 2019, un exemple illustrant les états d'attention prédits pour un spectateur regardant du contenu vidéo.* Source : https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
*Extrait de l'article de 2019, un exemple illustrant les états d'attention prédits pour un spectateur regardant du contenu vidéo.* Source : https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
Cependant, ces efforts antérieurs n'ont pas pris en compte les facteurs spécifiques à l'appareil, comme si le participant utilisait un ordinateur de bureau ou un appareil mobile, ni la taille de l'écran ou le placement de la caméra. Le système AFFDEX se concentrait uniquement sur l'identification de la diversion du regard, tandis que le travail de 2019 tentait de détecter un ensemble plus large de comportements, mais pouvait être limité par son utilisation d'un seul CNN peu profond.
Les auteurs notent que la plupart des recherches existantes ne sont pas optimisées pour les tests publicitaires, qui ont des besoins uniques par rapport à d'autres domaines comme la conduite ou l'éducation. Ils ont développé une architecture pour détecter l'attention des spectateurs pendant les publicités en ligne, en s'appuyant sur deux boîtes à outils commerciales : AFFDEX 2.0 et SmartEye SDK.
 *Exemples d'analyse faciale d'AFFDEX 2.0.* Source : https://arxiv.org/pdf/2202.12059
*Exemples d'analyse faciale d'AFFDEX 2.0.* Source : https://arxiv.org/pdf/2202.12059
Ces boîtes à outils extraient des caractéristiques de bas niveau comme les expressions faciales, la posture de la tête et la direction du regard, qui sont ensuite traitées pour produire des indicateurs de haut niveau tels que la position du regard sur l'écran, le bâillement et la parole. Le système identifie quatre types de distractions : le regard hors écran, la somnolence, la parole et les écrans non surveillés, ajustant l'analyse du regard en fonction de l'utilisation d'un ordinateur de bureau ou d'un appareil mobile.
Ensembles de données : Regard
Les auteurs ont utilisé quatre ensembles de données pour alimenter et évaluer leur système de détection de l'attention : trois axés sur le comportement du regard, la parole et le bâillement, et un quatrième tiré de sessions réelles de tests publicitaires contenant divers types de distractions. Des ensembles de données personnalisés ont été créés pour chaque catégorie, provenant d'un dépôt propriétaire contenant des millions de sessions enregistrées de participants regardant des publicités dans des environnements domestiques ou professionnels, avec un consentement éclairé.
Pour constituer l'ensemble de données sur le regard, les participants ont suivi un point en mouvement sur l'écran, puis ont regardé ailleurs dans quatre directions. Ce processus a été répété trois fois pour établir la relation entre la capture et la couverture.
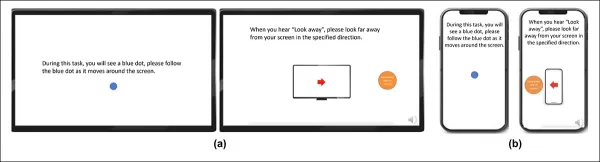 *Captures d'écran montrant le stimulus vidéo de regard sur (a) des ordinateurs de bureau et (b) des appareils mobiles. Les première et troisième images affichent des instructions pour suivre un point en mouvement, tandis que les deuxième et quatrième incitent les participants à détourner le regard de l'écran.*
*Captures d'écran montrant le stimulus vidéo de regard sur (a) des ordinateurs de bureau et (b) des appareils mobiles. Les première et troisième images affichent des instructions pour suivre un point en mouvement, tandis que les deuxième et quatrième incitent les participants à détourner le regard de l'écran.*
Les segments de points en mouvement ont été étiquetés comme attentifs, et les segments hors écran comme inattentifs, créant un ensemble de données étiqueté avec des exemples positifs et négatifs. Chaque vidéo durait environ 160 secondes, avec des versions séparées pour les plateformes de bureau et mobiles. Un total de 609 vidéos a été collecté, réparti en 158 échantillons d'entraînement et 451 pour les tests.
Ensembles de données : Parole
Dans ce contexte, parler pendant plus d'une seconde est considéré comme un signe d'inattention. Puisque l'environnement contrôlé n'enregistre pas l'audio, la parole est inférée en observant le mouvement des repères faciaux estimés. Les auteurs ont créé un ensemble de données basé sur des entrées visuelles, divisé en deux parties : l'une étiquetée manuellement par trois annotateurs, et l'autre étiquetée automatiquement en fonction du type de session.
Ensembles de données : Bâillement
Les ensembles de données existants sur le bâillement n'étaient pas adaptés aux scénarios de tests publicitaires, les auteurs ont donc utilisé 735 vidéos de leur collection interne, se concentrant sur des sessions susceptibles de contenir une ouverture de mâchoire de plus d'une seconde. Chaque vidéo a été étiquetée manuellement par trois annotateurs comme montrant un bâillement actif ou inactif, avec seulement 2,6 % des images contenant des bâillements actifs.
Ensembles de données : Distraction
L'ensemble de données sur les distractions a été tiré du dépôt de tests publicitaires des auteurs, où les participants ont visionné des publicités réelles sans tâches assignées. Un total de 520 sessions ont été sélectionnées au hasard et étiquetées manuellement par trois annotateurs comme attentives ou inattentives, les comportements inattentifs incluant le regard hors écran, la parole, la somnolence et les écrans non surveillés.
Modèles d'attention
Le modèle d'attention proposé traite des caractéristiques visuelles de bas niveau comme les expressions faciales, la posture de la tête et la direction du regard, extraites via AFFDEX 2.0 et SmartEye SDK. Celles-ci sont converties en indicateurs de haut niveau, chaque distracteur étant géré par un classificateur binaire séparé, entraîné sur son propre ensemble de données pour une optimisation et une évaluation indépendantes.
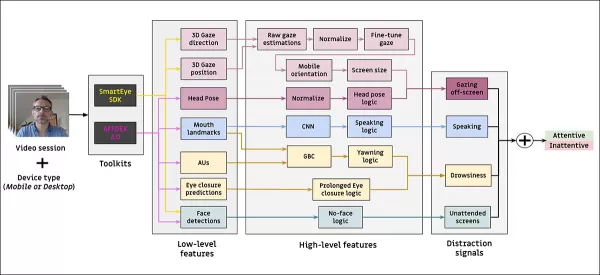 *Schéma du système de surveillance proposé.*
*Schéma du système de surveillance proposé.*
Le modèle de regard détermine si le spectateur regarde l'écran ou ailleurs en utilisant des coordonnées de regard normalisées, avec une calibration séparée pour les ordinateurs de bureau et les appareils mobiles. Une machine à vecteurs de support linéaire (SVM) est utilisée pour lisser les changements rapides de regard.
Pour détecter la parole sans audio, le système utilise des régions de la bouche recadrées et un CNN 3D entraîné sur des segments vidéo conversationnels et non conversationnels. Le bâillement est détecté à l'aide de recadrages d'images de visage complet, avec un CNN 3D entraîné sur des images étiquetées manuellement. L'abandon d'écran est identifié par l'absence de visage ou une posture de tête extrême, avec des prédictions faites par un arbre de décision.
Le statut d'attention final est déterminé par une règle fixe : si un module détecte une inattention, le spectateur est marqué comme inattentif, en privilégiant la sensibilité et ajusté séparément pour les contextes de bureau et mobiles.
Tests
Les tests suivent une méthode ablative, où les composants sont retirés et l'effet sur le résultat est noté. Le modèle de regard a identifié le comportement hors écran à travers trois étapes clés : la normalisation des estimations brutes du regard, l'ajustement fin de la sortie et l'estimation de la taille de l'écran pour les appareils de bureau.
 *Différentes catégories d'inattention perçue identifiées dans l'étude.*
*Différentes catégories d'inattention perçue identifiées dans l'étude.*
Les performances ont diminué lorsque l'une des étapes était omise, la normalisation s'avérant particulièrement précieuse sur les ordinateurs de bureau. L'étude a également évalué comment les caractéristiques visuelles prédisaient l'orientation de la caméra mobile, avec la combinaison de la localisation du visage, de la posture de la tête et du regard atteignant un score de 0,91.
 *Résultats indiquant les performances du modèle de regard complet, ainsi que des versions avec des étapes de traitement individuelles supprimées.*
*Résultats indiquant les performances du modèle de regard complet, ainsi que des versions avec des étapes de traitement individuelles supprimées.*
Le modèle de parole, entraîné sur la distance verticale des lèvres, a atteint un ROC-AUC de 0,97 sur l'ensemble de test étiqueté manuellement et 0,96 sur l'ensemble plus large étiqueté automatiquement. Le modèle de bâillement a atteint un ROC-AUC de 96,6 % en utilisant uniquement le rapport d'aspect de la bouche, s'améliorant à 97,5 % lorsqu'il est combiné avec les prédictions d'unités d'action d'AFFDEX 2.0.
Le modèle d'écran non surveillé a classé les moments comme inattentifs lorsque AFFDEX 2.0 et SmartEye n'ont pas détecté de visage pendant plus d'une seconde. Seulement 27 % des activations « sans visage » étaient dues à des utilisateurs quittant physiquement l'écran.
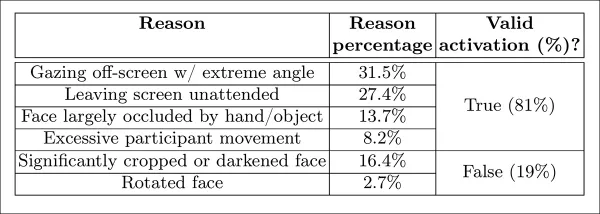 *Diverses raisons obtenues expliquant pourquoi un visage n'a pas été trouvé, dans certains cas.*
*Diverses raisons obtenues expliquant pourquoi un visage n'a pas été trouvé, dans certains cas.*
Les auteurs ont évalué comment l'ajout de différents signaux de distraction affectait les performances globales de leur modèle d'attention. La détection de l'attention s'est améliorée de manière constante à mesure que plus de types de distractions étaient ajoutés, le regard hors écran fournissant la base la plus solide.
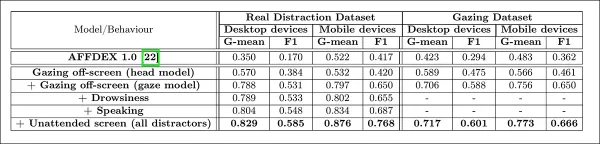 *L'effet de l'ajout de divers signaux de distraction à l'architecture.*
*L'effet de l'ajout de divers signaux de distraction à l'architecture.*
Les auteurs ont comparé leur modèle à AFFDEX 1.0, un système antérieur utilisé dans les tests publicitaires, et ont constaté que même la détection du regard basée sur la tête de leur modèle actuel surpassait AFFDEX 1.0 sur les deux types d'appareils.
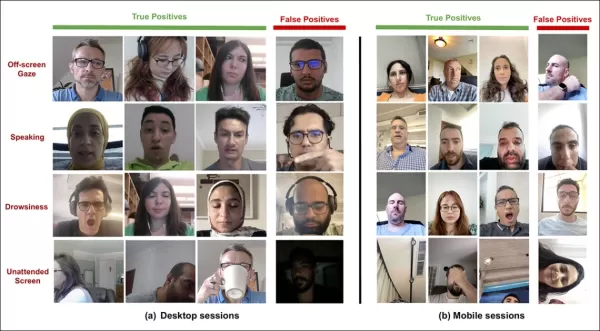 *Exemples de sorties du modèle d'attention sur les ordinateurs de bureau et les appareils mobiles, chaque rangée présentant des exemples de vrais et faux positifs pour différents types de distractions.*
*Exemples de sorties du modèle d'attention sur les ordinateurs de bureau et les appareils mobiles, chaque rangée présentant des exemples de vrais et faux positifs pour différents types de distractions.*
Conclusion
Les résultats représentent une avancée significative par rapport aux travaux antérieurs, offrant un aperçu de la volonté persistante de l'industrie de comprendre l'état interne du spectateur. Bien que les données aient été collectées avec consentement, la méthodologie pointe vers des cadres futurs qui pourraient s'étendre au-delà des contextes structurés de recherche marketing. Cette conclusion est renforcée par la nature secrète de cette recherche, qui reste étroitement gardée par l'industrie.
Article connexe
 Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
La politique rendant obligatoire l'utilisation de la recherche par IA provoque un exode, tandis que DuckDuckGo enregistre une forte augmentation du nombre d'utilisateurs
Suite à l'annonce faite par Google lors de sa conférence I/O 2026 concernant une refonte complète de son moteur de recherche axée sur l'IA, de nombreux utilisateurs se sont mis à rechercher des altern
Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Recommandations de sujets spéciaux liés
Synthèse vocale
Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
La politique rendant obligatoire l'utilisation de la recherche par IA provoque un exode, tandis que DuckDuckGo enregistre une forte augmentation du nombre d'utilisateurs
Suite à l'annonce faite par Google lors de sa conférence I/O 2026 concernant une refonte complète de son moteur de recherche axée sur l'IA, de nombreux utilisateurs se sont mis à rechercher des altern
Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Recommandations de sujets spéciaux liés
Synthèse vocale
 Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Les meilleures applications de synthèse vocale basées sur l'IA pour la dyslexie : un soutien à l'apprentissage et à l'efficacité en lecture pour les élèves
Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
 10 outils
10 outils
 xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
xix.ai
Création de bande dessinée
Les meilleurs générateurs IA pour les mangas shonen : créez des séquences d'action survoltées et des effets d'énergie
Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai
Entreprise
Les meilleurs outils de suivi des dépenses basés sur l'IA : numérisez vos reçus et classez automatiquement les dépenses de l'entreprise
Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai
Entreprise
Les meilleurs outils de recrutement basés sur l'IA : triez les CV et automatisez la planification des entretiens avec les candidats
Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai
Productivité
Coaches IA dédiés au bien-être et à la concentration : gérer l'épuisement professionnel et booster son énergie mentale
Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai
chatbot
Les meilleurs chatbots romantiques basés sur l'IA : nouez des relations durables grâce à des personnalités cohérentes
Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

 commentaires (25)
commentaires (25)
![JustinAnderson]()
¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
![MatthewSanchez]()
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
![StephenGonzalez]()
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
![EdwardRamirez]()
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
![EricLewis]()
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
![JoseLewis]()
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂
L'industrie de la publicité en ligne a investi un montant impressionnant de 740,3 milliards de dollars USD dans ses efforts en 2023, ce qui explique pourquoi les entreprises de ce secteur sont si déterminées à faire progresser la recherche en vision par ordinateur. Elles se concentrent particulièrement sur les technologies de reconnaissance faciale et du regard, l'estimation de l'âge jouant un rôle clé dans l'analyse démographique. Cela est crucial pour les annonceurs cherchant à cibler des groupes d'âge spécifiques.
Bien que l'industrie ait tendance à garder ses cartes près du cœur, elle partage occasionnellement des aperçus de ses travaux propriétaires plus avancés à travers des études publiées. Ces études impliquent souvent des participants ayant consenti à faire partie d'analyses pilotées par l'IA, visant à comprendre comment les spectateurs interagissent avec les publicités.
*L'estimation de l'âge dans un contexte publicitaire en conditions réelles intéresse les annonceurs qui ciblent un groupe démographique particulier. Dans cet exemple expérimental d'estimation automatique de l'âge facial, l'âge de l'artiste Bob Dylan est suivi au fil des années.* Source : https://arxiv.org/pdf/1906.03625
L'un des outils fréquemment utilisés dans ces systèmes d'estimation faciale est l'Histogramme des Gradients Orientés (HoG) de Dlib, qui aide à analyser les traits du visage.
*L'Histogramme des Gradients Orientés (HoG) de Dlib est souvent utilisé dans les systèmes d'estimation faciale.* Source : https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Instinct animal
En matière de compréhension de l'engagement des spectateurs, l'industrie publicitaire s'intéresse particulièrement à l'identification des faux positifs – des cas où le système interprète mal les actions d'un spectateur – et à l'établissement de critères clairs pour déterminer quand une personne n'est pas pleinement engagée avec une publicité. Cela est particulièrement pertinent dans la publicité sur écran, où les études se concentrent sur deux environnements principaux : le bureau et le mobile, chacun nécessitant des solutions de suivi adaptées.
Les annonceurs classent souvent le désengagement des spectateurs en deux comportements : le « comportement de hibou » et le « comportement de lézard ». Si vous détournez la tête de la publicité, c'est un « comportement de hibou ». Si votre tête reste immobile mais que vos yeux s'éloignent de l'écran, c'est un « comportement de lézard ». Ces comportements sont cruciaux pour que les systèmes les capturent précisément lors des tests de nouvelles publicités dans des conditions contrôlées.
*Exemples de comportements de « hibou » et de « lézard » chez un sujet d'un projet de recherche publicitaire.* Source : https://arxiv.org/pdf/1508.04028
Un article récent de l'acquisition d'Affectiva par SmartEye aborde ces problèmes de front. Il propose une architecture qui combine plusieurs cadres existants pour créer un ensemble complet de fonctionnalités permettant de détecter l'attention des spectateurs dans différentes conditions et réactions. Ce système peut déterminer si un spectateur est ennuyé, engagé ou distrait par le contenu que l'annonceur souhaite qu'il regarde.
*Exemples de vrais et faux positifs détectés par le nouveau système d'attention pour divers signaux de distraction, présentés séparément pour les appareils de bureau et mobiles.* Source : https://arxiv.org/pdf/2504.06237
Les auteurs de l'article soulignent le peu de recherches sur la surveillance de l'attention pendant les publicités en ligne et notent que les études précédentes ont souvent négligé des facteurs critiques comme le type d'appareil, le placement de la caméra et la taille de l'écran. Leur architecture proposée vise à combler ces lacunes en détectant divers distracteurs, y compris les comportements de hibou et de lézard, la parole, la somnolence et les écrans non surveillés, tout en intégrant des fonctionnalités spécifiques à l'appareil pour améliorer la précision.
L'article, intitulé « Surveillance de l'attention des spectateurs pendant les publicités en ligne », a été rédigé par quatre chercheurs d'Affectiva.
Méthode et données
Compte tenu de la nature secrète de ces systèmes, l'article ne compare pas directement son approche avec celle des concurrents, mais présente ses résultats à travers des études d'ablation. Il s'écarte du format typique de la littérature sur la vision par ordinateur, nous explorerons donc la recherche telle qu'elle est présentée.
Les auteurs soulignent que peu d'études ont spécifiquement abordé la détection de l'attention dans le contexte des publicités en ligne. Par exemple, le SDK AFFDEX, qui offre une reconnaissance multifaciale en temps réel, infère l'attention uniquement à partir de la posture de la tête, qualifiant les participants d'inattentifs si l'angle de leur tête dépasse un certain seuil.
*Un exemple du SDK AFFDEX, un système d'Affectiva qui repose sur la posture de la tête comme indicateur d'attention.* Source : https://www.youtube.com/watch?v=c2CWb5jHmbY
Dans une collaboration de 2019 intitulée « Mesure automatique de l'attention visuelle au contenu vidéo à l'aide de l'apprentissage profond », un ensemble de données d'environ 28 000 participants a été annoté pour divers comportements inattentifs, et un modèle CNN-LSTM a été entraîné pour détecter l'attention à partir de l'apparence faciale au fil du temps.
*Extrait de l'article de 2019, un exemple illustrant les états d'attention prédits pour un spectateur regardant du contenu vidéo.* Source : https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
Cependant, ces efforts antérieurs n'ont pas pris en compte les facteurs spécifiques à l'appareil, comme si le participant utilisait un ordinateur de bureau ou un appareil mobile, ni la taille de l'écran ou le placement de la caméra. Le système AFFDEX se concentrait uniquement sur l'identification de la diversion du regard, tandis que le travail de 2019 tentait de détecter un ensemble plus large de comportements, mais pouvait être limité par son utilisation d'un seul CNN peu profond.
Les auteurs notent que la plupart des recherches existantes ne sont pas optimisées pour les tests publicitaires, qui ont des besoins uniques par rapport à d'autres domaines comme la conduite ou l'éducation. Ils ont développé une architecture pour détecter l'attention des spectateurs pendant les publicités en ligne, en s'appuyant sur deux boîtes à outils commerciales : AFFDEX 2.0 et SmartEye SDK.
*Exemples d'analyse faciale d'AFFDEX 2.0.* Source : https://arxiv.org/pdf/2202.12059
Ces boîtes à outils extraient des caractéristiques de bas niveau comme les expressions faciales, la posture de la tête et la direction du regard, qui sont ensuite traitées pour produire des indicateurs de haut niveau tels que la position du regard sur l'écran, le bâillement et la parole. Le système identifie quatre types de distractions : le regard hors écran, la somnolence, la parole et les écrans non surveillés, ajustant l'analyse du regard en fonction de l'utilisation d'un ordinateur de bureau ou d'un appareil mobile.
Ensembles de données : Regard
Les auteurs ont utilisé quatre ensembles de données pour alimenter et évaluer leur système de détection de l'attention : trois axés sur le comportement du regard, la parole et le bâillement, et un quatrième tiré de sessions réelles de tests publicitaires contenant divers types de distractions. Des ensembles de données personnalisés ont été créés pour chaque catégorie, provenant d'un dépôt propriétaire contenant des millions de sessions enregistrées de participants regardant des publicités dans des environnements domestiques ou professionnels, avec un consentement éclairé.
Pour constituer l'ensemble de données sur le regard, les participants ont suivi un point en mouvement sur l'écran, puis ont regardé ailleurs dans quatre directions. Ce processus a été répété trois fois pour établir la relation entre la capture et la couverture.
*Captures d'écran montrant le stimulus vidéo de regard sur (a) des ordinateurs de bureau et (b) des appareils mobiles. Les première et troisième images affichent des instructions pour suivre un point en mouvement, tandis que les deuxième et quatrième incitent les participants à détourner le regard de l'écran.*
Les segments de points en mouvement ont été étiquetés comme attentifs, et les segments hors écran comme inattentifs, créant un ensemble de données étiqueté avec des exemples positifs et négatifs. Chaque vidéo durait environ 160 secondes, avec des versions séparées pour les plateformes de bureau et mobiles. Un total de 609 vidéos a été collecté, réparti en 158 échantillons d'entraînement et 451 pour les tests.
Ensembles de données : Parole
Dans ce contexte, parler pendant plus d'une seconde est considéré comme un signe d'inattention. Puisque l'environnement contrôlé n'enregistre pas l'audio, la parole est inférée en observant le mouvement des repères faciaux estimés. Les auteurs ont créé un ensemble de données basé sur des entrées visuelles, divisé en deux parties : l'une étiquetée manuellement par trois annotateurs, et l'autre étiquetée automatiquement en fonction du type de session.
Ensembles de données : Bâillement
Les ensembles de données existants sur le bâillement n'étaient pas adaptés aux scénarios de tests publicitaires, les auteurs ont donc utilisé 735 vidéos de leur collection interne, se concentrant sur des sessions susceptibles de contenir une ouverture de mâchoire de plus d'une seconde. Chaque vidéo a été étiquetée manuellement par trois annotateurs comme montrant un bâillement actif ou inactif, avec seulement 2,6 % des images contenant des bâillements actifs.
Ensembles de données : Distraction
L'ensemble de données sur les distractions a été tiré du dépôt de tests publicitaires des auteurs, où les participants ont visionné des publicités réelles sans tâches assignées. Un total de 520 sessions ont été sélectionnées au hasard et étiquetées manuellement par trois annotateurs comme attentives ou inattentives, les comportements inattentifs incluant le regard hors écran, la parole, la somnolence et les écrans non surveillés.
Modèles d'attention
Le modèle d'attention proposé traite des caractéristiques visuelles de bas niveau comme les expressions faciales, la posture de la tête et la direction du regard, extraites via AFFDEX 2.0 et SmartEye SDK. Celles-ci sont converties en indicateurs de haut niveau, chaque distracteur étant géré par un classificateur binaire séparé, entraîné sur son propre ensemble de données pour une optimisation et une évaluation indépendantes.
*Schéma du système de surveillance proposé.*
Le modèle de regard détermine si le spectateur regarde l'écran ou ailleurs en utilisant des coordonnées de regard normalisées, avec une calibration séparée pour les ordinateurs de bureau et les appareils mobiles. Une machine à vecteurs de support linéaire (SVM) est utilisée pour lisser les changements rapides de regard.
Pour détecter la parole sans audio, le système utilise des régions de la bouche recadrées et un CNN 3D entraîné sur des segments vidéo conversationnels et non conversationnels. Le bâillement est détecté à l'aide de recadrages d'images de visage complet, avec un CNN 3D entraîné sur des images étiquetées manuellement. L'abandon d'écran est identifié par l'absence de visage ou une posture de tête extrême, avec des prédictions faites par un arbre de décision.
Le statut d'attention final est déterminé par une règle fixe : si un module détecte une inattention, le spectateur est marqué comme inattentif, en privilégiant la sensibilité et ajusté séparément pour les contextes de bureau et mobiles.
Tests
Les tests suivent une méthode ablative, où les composants sont retirés et l'effet sur le résultat est noté. Le modèle de regard a identifié le comportement hors écran à travers trois étapes clés : la normalisation des estimations brutes du regard, l'ajustement fin de la sortie et l'estimation de la taille de l'écran pour les appareils de bureau.
*Différentes catégories d'inattention perçue identifiées dans l'étude.*
Les performances ont diminué lorsque l'une des étapes était omise, la normalisation s'avérant particulièrement précieuse sur les ordinateurs de bureau. L'étude a également évalué comment les caractéristiques visuelles prédisaient l'orientation de la caméra mobile, avec la combinaison de la localisation du visage, de la posture de la tête et du regard atteignant un score de 0,91.
*Résultats indiquant les performances du modèle de regard complet, ainsi que des versions avec des étapes de traitement individuelles supprimées.*
Le modèle de parole, entraîné sur la distance verticale des lèvres, a atteint un ROC-AUC de 0,97 sur l'ensemble de test étiqueté manuellement et 0,96 sur l'ensemble plus large étiqueté automatiquement. Le modèle de bâillement a atteint un ROC-AUC de 96,6 % en utilisant uniquement le rapport d'aspect de la bouche, s'améliorant à 97,5 % lorsqu'il est combiné avec les prédictions d'unités d'action d'AFFDEX 2.0.
Le modèle d'écran non surveillé a classé les moments comme inattentifs lorsque AFFDEX 2.0 et SmartEye n'ont pas détecté de visage pendant plus d'une seconde. Seulement 27 % des activations « sans visage » étaient dues à des utilisateurs quittant physiquement l'écran.
*Diverses raisons obtenues expliquant pourquoi un visage n'a pas été trouvé, dans certains cas.*
Les auteurs ont évalué comment l'ajout de différents signaux de distraction affectait les performances globales de leur modèle d'attention. La détection de l'attention s'est améliorée de manière constante à mesure que plus de types de distractions étaient ajoutés, le regard hors écran fournissant la base la plus solide.
*L'effet de l'ajout de divers signaux de distraction à l'architecture.*
Les auteurs ont comparé leur modèle à AFFDEX 1.0, un système antérieur utilisé dans les tests publicitaires, et ont constaté que même la détection du regard basée sur la tête de leur modèle actuel surpassait AFFDEX 1.0 sur les deux types d'appareils.
*Exemples de sorties du modèle d'attention sur les ordinateurs de bureau et les appareils mobiles, chaque rangée présentant des exemples de vrais et faux positifs pour différents types de distractions.*
Conclusion
Les résultats représentent une avancée significative par rapport aux travaux antérieurs, offrant un aperçu de la volonté persistante de l'industrie de comprendre l'état interne du spectateur. Bien que les données aient été collectées avec consentement, la méthodologie pointe vers des cadres futurs qui pourraient s'étendre au-delà des contextes structurés de recherche marketing. Cette conclusion est renforcée par la nature secrète de cette recherche, qui reste étroitement gardée par l'industrie.









 Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
Bain prévoit un marché du SaaS de 100 milliards de dollars dans le domaine de l'automatisation par l'IA agentique
Bain & Company a estimé à 100 milliards de dollars la taille du marché américain pour les entreprises SaaS exploitant l'IA agentique. Selon le cabinet, ce marché résulte de l'automatisation des tâches
 La politique rendant obligatoire l'utilisation de la recherche par IA provoque un exode, tandis que DuckDuckGo enregistre une forte augmentation du nombre d'utilisateurs
Suite à l'annonce faite par Google lors de sa conférence I/O 2026 concernant une refonte complète de son moteur de recherche axée sur l'IA, de nombreux utilisateurs se sont mis à rechercher des altern
La politique rendant obligatoire l'utilisation de la recherche par IA provoque un exode, tandis que DuckDuckGo enregistre une forte augmentation du nombre d'utilisateurs
Suite à l'annonce faite par Google lors de sa conférence I/O 2026 concernant une refonte complète de son moteur de recherche axée sur l'IA, de nombreux utilisateurs se sont mis à rechercher des altern
 Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr
Xiaohongshu se restructure : Conan nommé président, création d'un département dédié à l'IA et d'une division internationale Rednote
Le 30 avril, Xiaohongshu a adressé une note interne à l'ensemble de ses employés pour annoncer le lancement d'une nouvelle restructuration organisationnelle. Au cœur de cette évolution figure l'intégr

Découvrez les meilleures applications de synthèse vocale par IA de 2026, spécialement sélectionnées pour aider les personnes dyslexiques. Notre classement d'experts compare les outils gratuits et payants, en mettant en avant des fonctionnalités performantes qui améliorent l'efficacité de la lecture et l'apprentissage. Découvrez des solutions révolutionnaires à ne pas manquer pour libérer le potentiel des élèves. Commencez votre parcours sur XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs générateurs IA de mangas shonen de 2026 sur XIX.AI. Notre sélection triée sur le volet comprend des outils performants pour créer des séquences d'action à couper le souffle et des effets d'énergie dynamiques. Comparez les options gratuites et payantes grâce à des tests concrets. Libérez votre potentiel créatif et commencez dès aujourd'hui à créer des mangas épiques !
15 outils
xix.ai

Les meilleurs outils de gestion des dépenses basés sur l'IA en 2026 : les outils les mieux notés pour numériser vos reçus et classer automatiquement les dépenses de votre entreprise. Découvrez des solutions puissantes et révolutionnaires pour une gestion des dépenses sans effort, un suivi financier précis et une conformité simplifiée. Notre comparatif, mis à jour chaque semaine, qui oppose les options gratuites aux options payantes, vous aide à trouver la solution qui vous convient le mieux. Tirez pleinement parti de l'IA grâce aux recommandations d'experts de XIX.AI.
10 outils
xix.ai

Découvrez les meilleurs outils de recrutement basés sur l'IA de 2026 sur XIX.AI. Notre sélection propose des solutions performantes et révolutionnaires pour l'analyse des CV et l'automatisation de la planification des entretiens avec les candidats. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez l'assistant de recrutement idéal et optimisez votre processus de recrutement dès aujourd'hui !
10 outils
xix.ai

Découvrez sur XIX.AI les meilleurs coachs IA de 2026 spécialisés dans le bien-être personnel et la concentration. Notre classement, soigneusement établi, présente les outils les mieux notés et les plus innovants pour gérer le surmenage et booster votre énergie mentale. Comparez les options gratuites et payantes grâce à des avis concrets. Ouvrez-vous dès aujourd’hui la voie vers une productivité et un bien-être optimaux.
10 outils
xix.ai

Découvrez les meilleurs chatbots romantiques basés sur l'IA de 2026, sélectionnés pour vous aider à nouer des relations authentiques et durables. Notre sélection comprend des personnalités fortes et cohérentes, des comparaisons entre versions gratuites et payantes, ainsi que des tests en conditions réelles. Trouvez le compagnon idéal et commencez dès aujourd'hui sur XIX.AI.
10 outils
xix.ai

¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂













