
















 Hogar
HogarEl anunciante 'Owls and Lizards' en el análisis de la audiencia
La industria de la publicidad en línea invirtió una asombrosa cantidad de 740.3 mil millones de dólares en sus esfuerzos en 2023, dejando claro por qué las empresas en este sector están tan interesadas en avanzar en la investigación de visión por computadora. Están particularmente enfocadas en tecnologías de reconocimiento facial y de seguimiento ocular, con la estimación de edad jugando un papel crucial en el análisis demográfico. Esto es fundamental para los anunciantes que buscan dirigirse a grupos de edad específicos.
Aunque la industria tiende a mantener sus cartas cerca del pecho, ocasionalmente comparte destellos de su trabajo propietario más avanzado a través de estudios publicados. Estos estudios a menudo involucran a participantes que han aceptado ser parte de análisis impulsados por IA, los cuales buscan entender cómo los espectadores interactúan con los anuncios.
 *Estimar la edad en un contexto publicitario en condiciones reales interesa a los anunciantes que pueden estar dirigiendo sus esfuerzos a un grupo demográfico particular. En este ejemplo experimental de estimación automática de edad facial, se sigue la edad del intérprete Bob Dylan a lo largo de los años.* Fuente: https://arxiv.org/pdf/1906.03625
*Estimar la edad en un contexto publicitario en condiciones reales interesa a los anunciantes que pueden estar dirigiendo sus esfuerzos a un grupo demográfico particular. En este ejemplo experimental de estimación automática de edad facial, se sigue la edad del intérprete Bob Dylan a lo largo de los años.* Fuente: https://arxiv.org/pdf/1906.03625
Una de las herramientas frecuentemente utilizadas en estos sistemas de estimación facial es el Histograma de Gradientes Orientados (HoG) de Dlib, que ayuda en el análisis de características faciales.
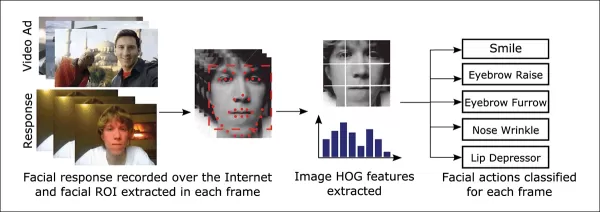 *El Histograma de Gradientes Orientados (HoG) de Dlib es frecuentemente utilizado en sistemas de estimación facial.* Fuente: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
*El Histograma de Gradientes Orientados (HoG) de Dlib es frecuentemente utilizado en sistemas de estimación facial.* Fuente: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Instinto Animal
Cuando se trata de entender el compromiso del espectador, la industria publicitaria está particularmente interesada en identificar falsos positivos—casos en los que el sistema malinterpreta las acciones de un espectador—y establecer criterios claros para cuando alguien no está completamente comprometido con un anuncio. Esto es especialmente relevante en la publicidad basada en pantallas, donde los estudios se centran en dos entornos principales: escritorio y móvil, cada uno requiriendo soluciones de seguimiento adaptadas.
Los anunciantes a menudo clasifican el desinterés del espectador en dos comportamientos: 'comportamiento de búho' y 'comportamiento de lagarto.' Si giras la cabeza alejándote del anuncio, eso es 'comportamiento de búho.' Si tu cabeza permanece quieta pero tus ojos se desvían de la pantalla, eso es 'comportamiento de lagarto.' Estos comportamientos son cruciales para que los sistemas los capturen con precisión al probar nuevos anuncios bajo condiciones controladas.
 *Ejemplos de comportamiento de 'búho' y 'lagarto' en un sujeto de un proyecto de investigación publicitaria.* Fuente: https://arxiv.org/pdf/1508.04028
*Ejemplos de comportamiento de 'búho' y 'lagarto' en un sujeto de un proyecto de investigación publicitaria.* Fuente: https://arxiv.org/pdf/1508.04028
Un artículo reciente de la adquisición de Affectiva por SmartEye aborda estos problemas directamente. Propone una arquitectura que combina varios marcos existentes para crear un conjunto completo de características para detectar la atención del espectador en diferentes condiciones y reacciones. Este sistema puede determinar si un espectador está aburrido, comprometido o distraído del contenido que el anunciante desea que se enfoque.
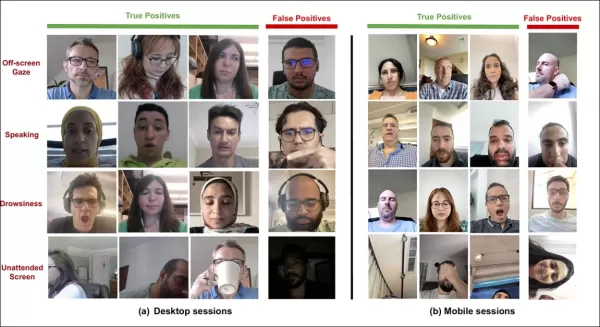 *Ejemplos de verdaderos y falsos positivos detectados por el nuevo sistema de atención para varias señales de distracción, mostrados por separado para dispositivos de escritorio y móviles.* Fuente: https://arxiv.org/pdf/2504.06237
*Ejemplos de verdaderos y falsos positivos detectados por el nuevo sistema de atención para varias señales de distracción, mostrados por separado para dispositivos de escritorio y móviles.* Fuente: https://arxiv.org/pdf/2504.06237
Los autores del artículo destacan la investigación limitada sobre el monitoreo de la atención durante los anuncios en línea y señalan que estudios anteriores a menudo pasaron por alto factores críticos como el tipo de dispositivo, la colocación de la cámara y el tamaño de la pantalla. Su arquitectura propuesta busca abordar estas brechas detectando varios distractores, incluidos los comportamientos de búho y lagarto, hablar, somnolencia y pantallas desatendidas, mientras integra características específicas del dispositivo para mejorar la precisión.
El artículo, titulado "Monitoreo de la Atención del Espectador Durante Anuncios en Línea," fue escrito por cuatro investigadores en Affectiva.
Método y Datos
Dada la naturaleza reservada de estos sistemas, el artículo no compara directamente su enfoque con el de competidores, pero presenta sus hallazgos a través de estudios de ablación. Se desvía del formato típico de la literatura de Visión por Computadora, por lo que exploraremos la investigación tal como se presenta.
Los autores señalan que solo unos pocos estudios han abordado específicamente la detección de atención en el contexto de anuncios en línea. Por ejemplo, el AFFDEX SDK, que ofrece reconocimiento facial múltiple en tiempo real, infiere la atención únicamente a partir de la postura de la cabeza, etiquetando a los participantes como desatentos si el ángulo de su cabeza excede un cierto umbral.
 *Un ejemplo del AFFDEX SDK, un sistema de Affectiva que utiliza la postura de la cabeza como indicador de atención.* Fuente: https://www.youtube.com/watch?v=c2CWb5jHmbY
*Un ejemplo del AFFDEX SDK, un sistema de Affectiva que utiliza la postura de la cabeza como indicador de atención.* Fuente: https://www.youtube.com/watch?v=c2CWb5jHmbY
En una colaboración de 2019 titulada "Medición Automática de la Atención Visual al Contenido de Video usando Aprendizaje Profundo," un conjunto de datos de alrededor de 28,000 participantes fue anotado para varios comportamientos desatentos, y se entrenó un modelo CNN-LSTM para detectar la atención a partir de la apariencia facial a lo largo del tiempo.
 *Del artículo de 2019, un ejemplo que ilustra estados de atención predichos para un espectador viendo contenido de video.* Fuente: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
*Del artículo de 2019, un ejemplo que ilustra estados de atención predichos para un espectador viendo contenido de video.* Fuente: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
Sin embargo, estos esfuerzos anteriores no consideraron factores específicos del dispositivo, como si el participante estaba usando un dispositivo de escritorio o móvil, ni tomaron en cuenta el tamaño de la pantalla o la colocación de la cámara. El sistema AFFDEX se enfocó solo en identificar la desviación de la mirada, mientras que el trabajo de 2019 intentó detectar un conjunto más amplio de comportamientos, pero pudo haber estado limitado por su uso de una CNN superficial única.
Los autores señalan que gran parte de la investigación existente no está optimizada para pruebas de anuncios, que tienen necesidades únicas en comparación con otros dominios como la conducción o la educación. Han desarrollado una arquitectura para detectar la atención del espectador durante anuncios en línea, aprovechando dos kits de herramientas comerciales: AFFDEX 2.0 y SmartEye SDK.
 *Ejemplos de análisis facial de AFFDEX 2.0.* Fuente: https://arxiv.org/pdf/2202.12059
*Ejemplos de análisis facial de AFFDEX 2.0.* Fuente: https://arxiv.org/pdf/2202.12059
Estos kits de herramientas extraen características de bajo nivel como expresiones faciales, postura de la cabeza y dirección de la mirada, que luego se procesan para producir indicadores de alto nivel como la posición de la mirada en la pantalla, bostezos y hablar. El sistema identifica cuatro tipos de distracciones: mirada fuera de la pantalla, somnolencia, hablar y pantallas desatendidas, ajustando el análisis de la mirada según si el espectador está usando un dispositivo de escritorio o móvil.
Conjuntos de Datos: Mirada
Los autores utilizaron cuatro conjuntos de datos para alimentar y evaluar su sistema de detección de atención: tres enfocados en el comportamiento de la mirada, hablar y bostezar, y un cuarto extraído de sesiones reales de prueba de anuncios que contienen varios tipos de distracciones. Se crearon conjuntos de datos personalizados para cada categoría, obtenidos de un repositorio propietario con millones de sesiones grabadas de participantes viendo anuncios en entornos domésticos o laborales, con consentimiento informado.
Para construir el conjunto de datos de mirada, los participantes siguieron un punto en movimiento a través de la pantalla y luego miraron hacia otro lado en cuatro direcciones. Este proceso se repitió tres veces para establecer la relación entre captura y cobertura.
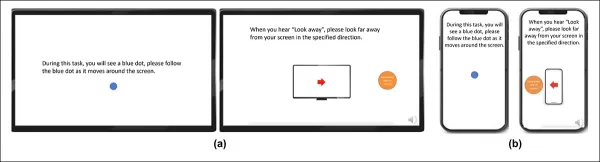 *Capturas de pantalla que muestran el estímulo de video de mirada en (a) dispositivos de escritorio y (b) móviles. Los primeros y terceros fotogramas muestran instrucciones para seguir un punto en movimiento, mientras que los segundos y cuartos piden a los participantes que miren fuera de la pantalla.*
*Capturas de pantalla que muestran el estímulo de video de mirada en (a) dispositivos de escritorio y (b) móviles. Los primeros y terceros fotogramas muestran instrucciones para seguir un punto en movimiento, mientras que los segundos y cuartos piden a los participantes que miren fuera de la pantalla.*
Los segmentos de punto en movimiento se etiquetaron como atentos, y los segmentos fuera de la pantalla como desatentos, creando un conjunto de datos etiquetado con ejemplos tanto positivos como negativos. Cada video duró aproximadamente 160 segundos, con versiones separadas para plataformas de escritorio y móviles. Se recolectaron un total de 609 videos, divididos en 158 muestras de entrenamiento y 451 para pruebas.
Conjuntos de Datos: Hablar
En este contexto, hablar durante más de un segundo se considera una señal de inatención. Dado que el entorno controlado no graba audio, el habla se infiere observando el movimiento de puntos de referencia faciales estimados. Los autores crearon un conjunto de datos basado en entrada visual, dividido en dos partes: una etiquetada manualmente por tres anotadores, y la otra etiquetada automáticamente según el tipo de sesión.
Conjuntos de Datos: Bostezar
Los conjuntos de datos de bostezos existentes no eran adecuados para escenarios de prueba de anuncios, por lo que los autores utilizaron 735 videos de su colección interna, enfocándose en sesiones propensas a contener una caída de mandíbula que dure más de un segundo. Cada video fue etiquetado manualmente por tres anotadores como mostrando bostezos activos o inactivos, con solo el 2.6 por ciento de los fotogramas conteniendo bostezos activos.
Conjuntos de Datos: Distracción
El conjunto de datos de distracción se extrajo del repositorio de pruebas de anuncios de los autores, donde los participantes vieron anuncios reales sin tareas asignadas. Se seleccionaron aleatoriamente un total de 520 sesiones y se etiquetaron manualmente por tres anotadores como atentas o desatentas, con comportamientos desatentos que incluyen mirada fuera de la pantalla, hablar, somnolencia y pantallas desatendidas.
Modelos de Atención
El modelo de atención propuesto procesa características visuales de bajo nivel como expresiones faciales, postura de la cabeza y dirección de la mirada, extraídas a través de AFFDEX 2.0 y SmartEye SDK. Estas se convierten en indicadores de alto nivel, con cada distractor manejado por un clasificador binario separado entrenado en su propio conjunto de datos para optimización y evaluación independientes.
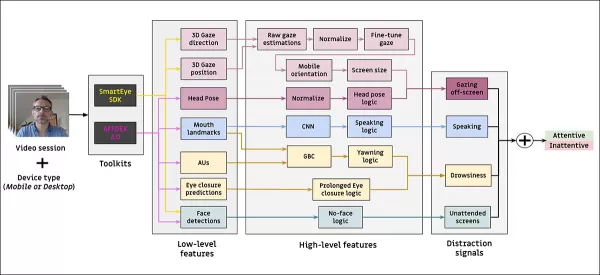 *Esquema del sistema de monitoreo propuesto.*
*Esquema del sistema de monitoreo propuesto.*
El modelo de mirada determina si el espectador está mirando hacia o fuera de la pantalla utilizando coordenadas de mirada normalizadas, con calibración separada para dispositivos de escritorio y móviles. Se utiliza una Máquina de Soporte Vectorial (SVM) lineal para suavizar los cambios rápidos de mirada.
Para detectar el habla sin audio, el sistema usa regiones recortadas de la boca y una CNN-3D entrenada en segmentos de video conversacionales y no conversacionales. El bostezo se detecta usando recortes de imágenes de rostros completos, con una CNN-3D entrenada en fotogramas etiquetados manualmente. El abandono de la pantalla se identifica por la ausencia de un rostro o una postura extrema de la cabeza, con predicciones realizadas por un árbol de decisión.
El estado de atención final se determina utilizando una regla fija: si algún módulo detecta inatención, el espectador se marca como desatento, priorizando la sensibilidad y ajustado por separado para contextos de escritorio y móviles.
Pruebas
Las pruebas siguen un método ablativo, donde se eliminan componentes y se observa el efecto en el resultado. El modelo de mirada identificó el comportamiento fuera de la pantalla a través de tres pasos clave: normalización de estimaciones de mirada crudas, ajuste fino de la salida y estimación del tamaño de la pantalla para dispositivos de escritorio.
 *Diferentes categorías de inatención percibida identificadas en el estudio.*
*Diferentes categorías de inatención percibida identificadas en el estudio.*
El rendimiento disminuyó cuando se omitió algún paso, con la normalización resultando especialmente valiosa en escritorios. El estudio también evaluó cómo las características visuales predijeron la orientación de la cámara móvil, con la combinación de ubicación del rostro, postura de la cabeza y mirada ocular alcanzando una puntuación de 0.91.
 *Resultados que indican el rendimiento del modelo de mirada completo, junto con versiones con pasos de procesamiento individuales eliminados.*
*Resultados que indican el rendimiento del modelo de mirada completo, junto con versiones con pasos de procesamiento individuales eliminados.*
El modelo de habla, entrenado en la distancia vertical de los labios, logró un ROC-AUC de 0.97 en el conjunto de prueba etiquetado manualmente y 0.96 en el conjunto de datos etiquetado automáticamente más grande. El modelo de bostezo alcanzó un ROC-AUC de 96.6 por ciento usando solo la proporción de aspecto de la boca, mejorando a 97.5 por ciento cuando se combinó con predicciones de unidades de acción de AFFDEX 2.0.
El modelo de pantalla desatendida clasificó los momentos como desatentos cuando tanto AFFDEX 2.0 como SmartEye no detectaron un rostro durante más de un segundo. Solo el 27 por ciento de las activaciones de 'sin rostro' se debieron a que los usuarios abandonaron físicamente la pantalla.
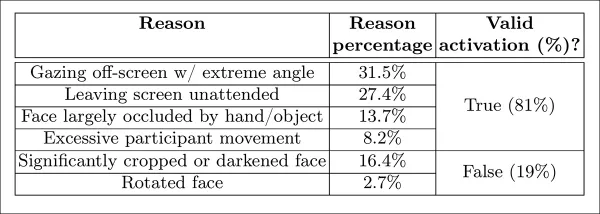 *Diversas razones obtenidas por las cuales no se encontró un rostro, en ciertos casos.*
*Diversas razones obtenidas por las cuales no se encontró un rostro, en ciertos casos.*
Los autores evaluaron cómo la adición de diferentes señales de distracción afectó el rendimiento general de su modelo de atención. La detección de atención mejoró consistentemente a medida que se añadían más tipos de distracciones, con la mirada fuera de la pantalla proporcionando la base más sólida.
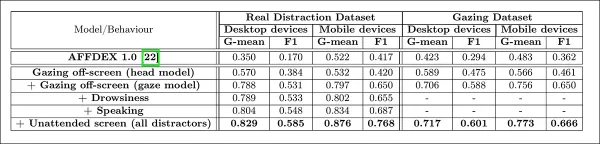 *El efecto de añadir diversas señales de distracción a la arquitectura.*
*El efecto de añadir diversas señales de distracción a la arquitectura.*
Los autores compararon su modelo con AFFDEX 1.0, un sistema anterior utilizado en pruebas de anuncios, y encontraron que incluso la detección de mirada basada en la cabeza del modelo actual superó a AFFDEX 1.0 en ambos tipos de dispositivos.
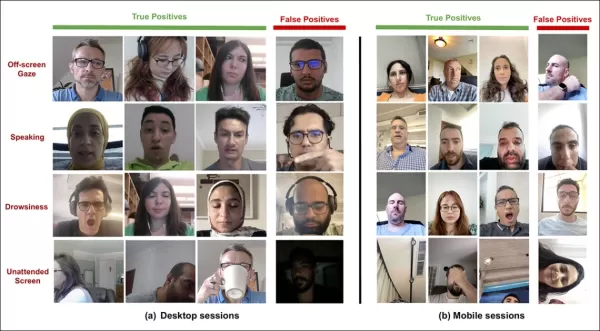 *Salidas de muestra del modelo de atención en dispositivos de escritorio y móviles, con cada fila presentando ejemplos de verdaderos y falsos positivos para diferentes tipos de distracciones.*
*Salidas de muestra del modelo de atención en dispositivos de escritorio y móviles, con cada fila presentando ejemplos de verdaderos y falsos positivos para diferentes tipos de distracciones.*
Conclusión
Los resultados representan un avance significativo sobre trabajos anteriores, ofreciendo un vistazo al impulso persistente de la industria por entender el estado interno del espectador. Aunque los datos se recopilaron con consentimiento, la metodología apunta hacia marcos futuros que podrían extenderse más allá de entornos estructurados de investigación de mercado. Esta conclusión se ve reforzada por la naturaleza reservada de esta investigación, que permanece celosamente guardada por la industria.
Artículo relacionado
 Xiaohongshu se reestructura: Conan es nombrado presidente y crea el departamento principal de IA «Dots» y la división internacional «Rednote»
El 30 de abril, Xiaohongshu envió una nota interna a todos los empleados en la que anunciaba el lanzamiento de una nueva reestructuración organizativa. El núcleo de este cambio consiste en integrar pl
El juego «Xiaolongxia» de Tencent supera todas las expectativas; el equipo multiplica por diez su capacidad, pide disculpas y ofrece compensaciones
Tencent ha lanzado oficialmente WorkBuddy, un agente inteligente basado en IA para todo tipo de situaciones, lo que marca una nueva etapa en la carrera por la capa de aplicación de los modelos a gran
El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l
Recomendaciones de temas especiales relacionados
Creación de cómics
Xiaohongshu se reestructura: Conan es nombrado presidente y crea el departamento principal de IA «Dots» y la división internacional «Rednote»
El 30 de abril, Xiaohongshu envió una nota interna a todos los empleados en la que anunciaba el lanzamiento de una nueva reestructuración organizativa. El núcleo de este cambio consiste en integrar pl
El juego «Xiaolongxia» de Tencent supera todas las expectativas; el equipo multiplica por diez su capacidad, pide disculpas y ofrece compensaciones
Tencent ha lanzado oficialmente WorkBuddy, un agente inteligente basado en IA para todo tipo de situaciones, lo que marca una nueva etapa en la carrera por la capa de aplicación de los modelos a gran
El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l
Recomendaciones de temas especiales relacionados
Creación de cómics
 Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
 15 herramientas
15 herramientas
 xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai
Educación y aprendizaje
Los mejores mentores en ciencia de datos y IA: dominan SQL, Pandas y flujos de trabajo de aprendizaje automático.
Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

 comentario (25)
0/500
comentario (25)
0/500
![JustinAnderson]()
¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
![MatthewSanchez]()
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
![StephenGonzalez]()
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
![EdwardRamirez]()
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
![EricLewis]()
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
![JoseLewis]()
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂
La industria de la publicidad en línea invirtió una asombrosa cantidad de 740.3 mil millones de dólares en sus esfuerzos en 2023, dejando claro por qué las empresas en este sector están tan interesadas en avanzar en la investigación de visión por computadora. Están particularmente enfocadas en tecnologías de reconocimiento facial y de seguimiento ocular, con la estimación de edad jugando un papel crucial en el análisis demográfico. Esto es fundamental para los anunciantes que buscan dirigirse a grupos de edad específicos.
Aunque la industria tiende a mantener sus cartas cerca del pecho, ocasionalmente comparte destellos de su trabajo propietario más avanzado a través de estudios publicados. Estos estudios a menudo involucran a participantes que han aceptado ser parte de análisis impulsados por IA, los cuales buscan entender cómo los espectadores interactúan con los anuncios.
*Estimar la edad en un contexto publicitario en condiciones reales interesa a los anunciantes que pueden estar dirigiendo sus esfuerzos a un grupo demográfico particular. En este ejemplo experimental de estimación automática de edad facial, se sigue la edad del intérprete Bob Dylan a lo largo de los años.* Fuente: https://arxiv.org/pdf/1906.03625
Una de las herramientas frecuentemente utilizadas en estos sistemas de estimación facial es el Histograma de Gradientes Orientados (HoG) de Dlib, que ayuda en el análisis de características faciales.
*El Histograma de Gradientes Orientados (HoG) de Dlib es frecuentemente utilizado en sistemas de estimación facial.* Fuente: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Instinto Animal
Cuando se trata de entender el compromiso del espectador, la industria publicitaria está particularmente interesada en identificar falsos positivos—casos en los que el sistema malinterpreta las acciones de un espectador—y establecer criterios claros para cuando alguien no está completamente comprometido con un anuncio. Esto es especialmente relevante en la publicidad basada en pantallas, donde los estudios se centran en dos entornos principales: escritorio y móvil, cada uno requiriendo soluciones de seguimiento adaptadas.
Los anunciantes a menudo clasifican el desinterés del espectador en dos comportamientos: 'comportamiento de búho' y 'comportamiento de lagarto.' Si giras la cabeza alejándote del anuncio, eso es 'comportamiento de búho.' Si tu cabeza permanece quieta pero tus ojos se desvían de la pantalla, eso es 'comportamiento de lagarto.' Estos comportamientos son cruciales para que los sistemas los capturen con precisión al probar nuevos anuncios bajo condiciones controladas.
*Ejemplos de comportamiento de 'búho' y 'lagarto' en un sujeto de un proyecto de investigación publicitaria.* Fuente: https://arxiv.org/pdf/1508.04028
Un artículo reciente de la adquisición de Affectiva por SmartEye aborda estos problemas directamente. Propone una arquitectura que combina varios marcos existentes para crear un conjunto completo de características para detectar la atención del espectador en diferentes condiciones y reacciones. Este sistema puede determinar si un espectador está aburrido, comprometido o distraído del contenido que el anunciante desea que se enfoque.
*Ejemplos de verdaderos y falsos positivos detectados por el nuevo sistema de atención para varias señales de distracción, mostrados por separado para dispositivos de escritorio y móviles.* Fuente: https://arxiv.org/pdf/2504.06237
Los autores del artículo destacan la investigación limitada sobre el monitoreo de la atención durante los anuncios en línea y señalan que estudios anteriores a menudo pasaron por alto factores críticos como el tipo de dispositivo, la colocación de la cámara y el tamaño de la pantalla. Su arquitectura propuesta busca abordar estas brechas detectando varios distractores, incluidos los comportamientos de búho y lagarto, hablar, somnolencia y pantallas desatendidas, mientras integra características específicas del dispositivo para mejorar la precisión.
El artículo, titulado "Monitoreo de la Atención del Espectador Durante Anuncios en Línea," fue escrito por cuatro investigadores en Affectiva.
Método y Datos
Dada la naturaleza reservada de estos sistemas, el artículo no compara directamente su enfoque con el de competidores, pero presenta sus hallazgos a través de estudios de ablación. Se desvía del formato típico de la literatura de Visión por Computadora, por lo que exploraremos la investigación tal como se presenta.
Los autores señalan que solo unos pocos estudios han abordado específicamente la detección de atención en el contexto de anuncios en línea. Por ejemplo, el AFFDEX SDK, que ofrece reconocimiento facial múltiple en tiempo real, infiere la atención únicamente a partir de la postura de la cabeza, etiquetando a los participantes como desatentos si el ángulo de su cabeza excede un cierto umbral.
*Un ejemplo del AFFDEX SDK, un sistema de Affectiva que utiliza la postura de la cabeza como indicador de atención.* Fuente: https://www.youtube.com/watch?v=c2CWb5jHmbY
En una colaboración de 2019 titulada "Medición Automática de la Atención Visual al Contenido de Video usando Aprendizaje Profundo," un conjunto de datos de alrededor de 28,000 participantes fue anotado para varios comportamientos desatentos, y se entrenó un modelo CNN-LSTM para detectar la atención a partir de la apariencia facial a lo largo del tiempo.
*Del artículo de 2019, un ejemplo que ilustra estados de atención predichos para un espectador viendo contenido de video.* Fuente: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
Sin embargo, estos esfuerzos anteriores no consideraron factores específicos del dispositivo, como si el participante estaba usando un dispositivo de escritorio o móvil, ni tomaron en cuenta el tamaño de la pantalla o la colocación de la cámara. El sistema AFFDEX se enfocó solo en identificar la desviación de la mirada, mientras que el trabajo de 2019 intentó detectar un conjunto más amplio de comportamientos, pero pudo haber estado limitado por su uso de una CNN superficial única.
Los autores señalan que gran parte de la investigación existente no está optimizada para pruebas de anuncios, que tienen necesidades únicas en comparación con otros dominios como la conducción o la educación. Han desarrollado una arquitectura para detectar la atención del espectador durante anuncios en línea, aprovechando dos kits de herramientas comerciales: AFFDEX 2.0 y SmartEye SDK.
*Ejemplos de análisis facial de AFFDEX 2.0.* Fuente: https://arxiv.org/pdf/2202.12059
Estos kits de herramientas extraen características de bajo nivel como expresiones faciales, postura de la cabeza y dirección de la mirada, que luego se procesan para producir indicadores de alto nivel como la posición de la mirada en la pantalla, bostezos y hablar. El sistema identifica cuatro tipos de distracciones: mirada fuera de la pantalla, somnolencia, hablar y pantallas desatendidas, ajustando el análisis de la mirada según si el espectador está usando un dispositivo de escritorio o móvil.
Conjuntos de Datos: Mirada
Los autores utilizaron cuatro conjuntos de datos para alimentar y evaluar su sistema de detección de atención: tres enfocados en el comportamiento de la mirada, hablar y bostezar, y un cuarto extraído de sesiones reales de prueba de anuncios que contienen varios tipos de distracciones. Se crearon conjuntos de datos personalizados para cada categoría, obtenidos de un repositorio propietario con millones de sesiones grabadas de participantes viendo anuncios en entornos domésticos o laborales, con consentimiento informado.
Para construir el conjunto de datos de mirada, los participantes siguieron un punto en movimiento a través de la pantalla y luego miraron hacia otro lado en cuatro direcciones. Este proceso se repitió tres veces para establecer la relación entre captura y cobertura.
*Capturas de pantalla que muestran el estímulo de video de mirada en (a) dispositivos de escritorio y (b) móviles. Los primeros y terceros fotogramas muestran instrucciones para seguir un punto en movimiento, mientras que los segundos y cuartos piden a los participantes que miren fuera de la pantalla.*
Los segmentos de punto en movimiento se etiquetaron como atentos, y los segmentos fuera de la pantalla como desatentos, creando un conjunto de datos etiquetado con ejemplos tanto positivos como negativos. Cada video duró aproximadamente 160 segundos, con versiones separadas para plataformas de escritorio y móviles. Se recolectaron un total de 609 videos, divididos en 158 muestras de entrenamiento y 451 para pruebas.
Conjuntos de Datos: Hablar
En este contexto, hablar durante más de un segundo se considera una señal de inatención. Dado que el entorno controlado no graba audio, el habla se infiere observando el movimiento de puntos de referencia faciales estimados. Los autores crearon un conjunto de datos basado en entrada visual, dividido en dos partes: una etiquetada manualmente por tres anotadores, y la otra etiquetada automáticamente según el tipo de sesión.
Conjuntos de Datos: Bostezar
Los conjuntos de datos de bostezos existentes no eran adecuados para escenarios de prueba de anuncios, por lo que los autores utilizaron 735 videos de su colección interna, enfocándose en sesiones propensas a contener una caída de mandíbula que dure más de un segundo. Cada video fue etiquetado manualmente por tres anotadores como mostrando bostezos activos o inactivos, con solo el 2.6 por ciento de los fotogramas conteniendo bostezos activos.
Conjuntos de Datos: Distracción
El conjunto de datos de distracción se extrajo del repositorio de pruebas de anuncios de los autores, donde los participantes vieron anuncios reales sin tareas asignadas. Se seleccionaron aleatoriamente un total de 520 sesiones y se etiquetaron manualmente por tres anotadores como atentas o desatentas, con comportamientos desatentos que incluyen mirada fuera de la pantalla, hablar, somnolencia y pantallas desatendidas.
Modelos de Atención
El modelo de atención propuesto procesa características visuales de bajo nivel como expresiones faciales, postura de la cabeza y dirección de la mirada, extraídas a través de AFFDEX 2.0 y SmartEye SDK. Estas se convierten en indicadores de alto nivel, con cada distractor manejado por un clasificador binario separado entrenado en su propio conjunto de datos para optimización y evaluación independientes.
*Esquema del sistema de monitoreo propuesto.*
El modelo de mirada determina si el espectador está mirando hacia o fuera de la pantalla utilizando coordenadas de mirada normalizadas, con calibración separada para dispositivos de escritorio y móviles. Se utiliza una Máquina de Soporte Vectorial (SVM) lineal para suavizar los cambios rápidos de mirada.
Para detectar el habla sin audio, el sistema usa regiones recortadas de la boca y una CNN-3D entrenada en segmentos de video conversacionales y no conversacionales. El bostezo se detecta usando recortes de imágenes de rostros completos, con una CNN-3D entrenada en fotogramas etiquetados manualmente. El abandono de la pantalla se identifica por la ausencia de un rostro o una postura extrema de la cabeza, con predicciones realizadas por un árbol de decisión.
El estado de atención final se determina utilizando una regla fija: si algún módulo detecta inatención, el espectador se marca como desatento, priorizando la sensibilidad y ajustado por separado para contextos de escritorio y móviles.
Pruebas
Las pruebas siguen un método ablativo, donde se eliminan componentes y se observa el efecto en el resultado. El modelo de mirada identificó el comportamiento fuera de la pantalla a través de tres pasos clave: normalización de estimaciones de mirada crudas, ajuste fino de la salida y estimación del tamaño de la pantalla para dispositivos de escritorio.
*Diferentes categorías de inatención percibida identificadas en el estudio.*
El rendimiento disminuyó cuando se omitió algún paso, con la normalización resultando especialmente valiosa en escritorios. El estudio también evaluó cómo las características visuales predijeron la orientación de la cámara móvil, con la combinación de ubicación del rostro, postura de la cabeza y mirada ocular alcanzando una puntuación de 0.91.
*Resultados que indican el rendimiento del modelo de mirada completo, junto con versiones con pasos de procesamiento individuales eliminados.*
El modelo de habla, entrenado en la distancia vertical de los labios, logró un ROC-AUC de 0.97 en el conjunto de prueba etiquetado manualmente y 0.96 en el conjunto de datos etiquetado automáticamente más grande. El modelo de bostezo alcanzó un ROC-AUC de 96.6 por ciento usando solo la proporción de aspecto de la boca, mejorando a 97.5 por ciento cuando se combinó con predicciones de unidades de acción de AFFDEX 2.0.
El modelo de pantalla desatendida clasificó los momentos como desatentos cuando tanto AFFDEX 2.0 como SmartEye no detectaron un rostro durante más de un segundo. Solo el 27 por ciento de las activaciones de 'sin rostro' se debieron a que los usuarios abandonaron físicamente la pantalla.
*Diversas razones obtenidas por las cuales no se encontró un rostro, en ciertos casos.*
Los autores evaluaron cómo la adición de diferentes señales de distracción afectó el rendimiento general de su modelo de atención. La detección de atención mejoró consistentemente a medida que se añadían más tipos de distracciones, con la mirada fuera de la pantalla proporcionando la base más sólida.
*El efecto de añadir diversas señales de distracción a la arquitectura.*
Los autores compararon su modelo con AFFDEX 1.0, un sistema anterior utilizado en pruebas de anuncios, y encontraron que incluso la detección de mirada basada en la cabeza del modelo actual superó a AFFDEX 1.0 en ambos tipos de dispositivos.
*Salidas de muestra del modelo de atención en dispositivos de escritorio y móviles, con cada fila presentando ejemplos de verdaderos y falsos positivos para diferentes tipos de distracciones.*
Conclusión
Los resultados representan un avance significativo sobre trabajos anteriores, ofreciendo un vistazo al impulso persistente de la industria por entender el estado interno del espectador. Aunque los datos se recopilaron con consentimiento, la metodología apunta hacia marcos futuros que podrían extenderse más allá de entornos estructurados de investigación de mercado. Esta conclusión se ve reforzada por la naturaleza reservada de esta investigación, que permanece celosamente guardada por la industria.










 Xiaohongshu se reestructura: Conan es nombrado presidente y crea el departamento principal de IA «Dots» y la división internacional «Rednote»
El 30 de abril, Xiaohongshu envió una nota interna a todos los empleados en la que anunciaba el lanzamiento de una nueva reestructuración organizativa. El núcleo de este cambio consiste en integrar pl
Xiaohongshu se reestructura: Conan es nombrado presidente y crea el departamento principal de IA «Dots» y la división internacional «Rednote»
El 30 de abril, Xiaohongshu envió una nota interna a todos los empleados en la que anunciaba el lanzamiento de una nueva reestructuración organizativa. El núcleo de este cambio consiste en integrar pl
 El juego «Xiaolongxia» de Tencent supera todas las expectativas; el equipo multiplica por diez su capacidad, pide disculpas y ofrece compensaciones
Tencent ha lanzado oficialmente WorkBuddy, un agente inteligente basado en IA para todo tipo de situaciones, lo que marca una nueva etapa en la carrera por la capa de aplicación de los modelos a gran
El juego «Xiaolongxia» de Tencent supera todas las expectativas; el equipo multiplica por diez su capacidad, pide disculpas y ofrece compensaciones
Tencent ha lanzado oficialmente WorkBuddy, un agente inteligente basado en IA para todo tipo de situaciones, lo que marca una nueva etapa en la carrera por la capa de aplicación de los modelos a gran
 El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l
El principal inversor de Suno: eliminar las publicaciones no tapará el agujero de la demanda por derechos de autor
La tan esperada plataforma de generación musical con IA, Suno, se enfrenta a una dura batalla por los derechos de autor, y un comentario sincero de su principal inversor podría haber proporcionado a l

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Descubra a los mejores mentores en ciencia de datos y AI de 2026 para dominar SQL, Pandas y flujos de trabajo de aprendizaje automático. Explore nuestra selección cuidadosamente seleccionada y altamente valorada en XIX.AI para obtener orientación poderosa que cambie completamente la situación. Compare las opciones gratuitas con las pagadas y obtenga información basada en casos reales. Desbloquee su dominio de la ciencia de datos hoy mismo.
10 herramientas
xix.ai

¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂













