
















 Home
HomeAdvertiser Targets 'Owls and Lizards' in Audience Analysis
The online advertising industry poured a staggering $740.3 billion USD into its efforts in 2023, making it clear why companies in this space are so keen on advancing computer vision research. They're particularly focused on facial and eye-gaze recognition technologies, with age estimation playing a pivotal role in demographic analytics. This is crucial for advertisers aiming to target specific age groups.
Though the industry tends to keep its cards close to the chest, it occasionally shares glimpses of its more advanced proprietary work through published studies. These studies often involve participants who have agreed to be part of AI-driven analyses, which aim to understand how viewers interact with advertisements.
 *Estimating age in an in-the-wild advertising context is of interest to advertisers who may be targeting a particular age demographic. In this experimental example of automatic facial age estimation, the age of performer Bob Dylan is tracked across the years.* Source: https://arxiv.org/pdf/1906.03625
*Estimating age in an in-the-wild advertising context is of interest to advertisers who may be targeting a particular age demographic. In this experimental example of automatic facial age estimation, the age of performer Bob Dylan is tracked across the years.* Source: https://arxiv.org/pdf/1906.03625
One of the tools frequently used in these facial estimation systems is Dlib's Histogram of Oriented Gradients (HoG), which helps in analyzing facial features.
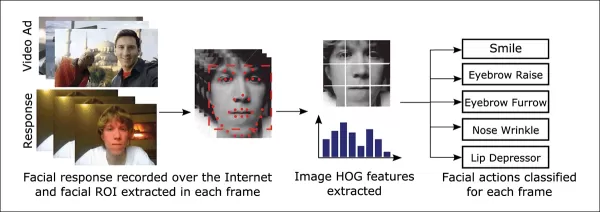 *Dlib's Histogram of Oriented Gradients (HoG) is often used in facial estimation systems.* Source: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
*Dlib's Histogram of Oriented Gradients (HoG) is often used in facial estimation systems.* Source: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Animal Instinct
When it comes to understanding viewer engagement, the advertising industry is particularly interested in identifying false positives—instances where the system misinterprets a viewer's actions—and establishing clear criteria for when someone isn't fully engaged with an ad. This is especially relevant in screen-based advertising, where studies focus on two main environments: desktop and mobile, each requiring tailored tracking solutions.
Advertisers often categorize viewer disengagement into two behaviors: 'owl behavior' and 'lizard behavior.' If you're turning your head away from the ad, that's 'owl behavior.' If your head stays still but your eyes wander off the screen, that's 'lizard behavior.' These behaviors are crucial for systems to capture accurately when testing new ads under controlled conditions.
 *Examples of 'Owl' and 'Lizard' behavior in a subject of an advertising research project.* Source: https://arxiv.org/pdf/1508.04028
*Examples of 'Owl' and 'Lizard' behavior in a subject of an advertising research project.* Source: https://arxiv.org/pdf/1508.04028
A recent paper from SmartEye's Affectiva acquisition tackles these issues head-on. It proposes an architecture that combines several existing frameworks to create a comprehensive feature set for detecting viewer attention across different conditions and reactions. This system can tell if a viewer is bored, engaged, or distracted from the content the advertiser wants them to focus on.
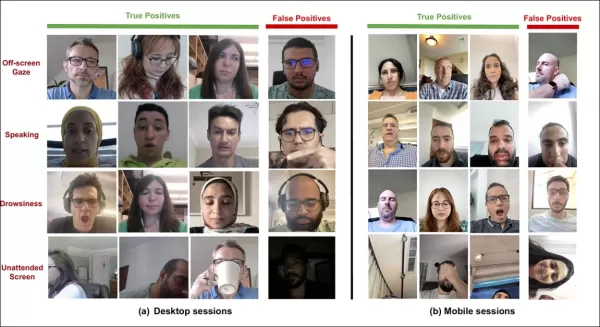 *Examples of true and false positives detected by the new attention system for various distraction signals, shown separately for desktop and mobile devices.* Source: https://arxiv.org/pdf/2504.06237
*Examples of true and false positives detected by the new attention system for various distraction signals, shown separately for desktop and mobile devices.* Source: https://arxiv.org/pdf/2504.06237
The authors of the paper highlight the limited research on monitoring attention during online ads and note that previous studies often overlooked critical factors like device type, camera placement, and screen size. Their proposed architecture aims to address these gaps by detecting various distractors, including owl and lizard behaviors, speaking, drowsiness, and unattended screens, while integrating device-specific features to enhance accuracy.
The paper, titled "Monitoring Viewer Attention During Online Ads," was authored by four researchers at Affectiva.
Method and Data
Given the secretive nature of these systems, the paper doesn't directly compare its approach with competitors but presents its findings through ablation studies. It deviates from the typical format of Computer Vision literature, so we'll explore the research as it's presented.
The authors point out that only a few studies have specifically addressed attention detection in the context of online ads. For instance, the AFFDEX SDK, which offers real-time multi-face recognition, infers attention solely from head pose, labeling participants as inattentive if their head angle exceeds a certain threshold.
 *An example from the AFFDEX SDK, an Affectiva system which relies on head pose as an indicator of attention.* Source: https://www.youtube.com/watch?v=c2CWb5jHmbY
*An example from the AFFDEX SDK, an Affectiva system which relies on head pose as an indicator of attention.* Source: https://www.youtube.com/watch?v=c2CWb5jHmbY
In a 2019 collaboration titled "Automatic Measurement of Visual Attention to Video Content using Deep Learning," a dataset of around 28,000 participants was annotated for various inattentive behaviors, and a CNN-LSTM model was trained to detect attention from facial appearance over time.
 *From the 2019 paper, an example illustrating predicted attention states for a viewer watching video content.* Source: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
*From the 2019 paper, an example illustrating predicted attention states for a viewer watching video content.* Source: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
However, these earlier efforts didn't account for device-specific factors like whether the participant was using a desktop or mobile device, nor did they consider screen size or camera placement. The AFFDEX system focused only on identifying gaze diversion, while the 2019 work attempted to detect a broader set of behaviors but may have been limited by its use of a single shallow CNN.
The authors note that much of the existing research isn't optimized for ad testing, which has unique needs compared to other domains like driving or education. They've developed an architecture for detecting viewer attention during online ads, leveraging two commercial toolkits: AFFDEX 2.0 and SmartEye SDK.
 *Examples of facial analysis from AFFDEX 2.0.* Source: https://arxiv.org/pdf/2202.12059
*Examples of facial analysis from AFFDEX 2.0.* Source: https://arxiv.org/pdf/2202.12059
These toolkits extract low-level features like facial expressions, head pose, and gaze direction, which are then processed to produce higher-level indicators such as gaze position on the screen, yawning, and speaking. The system identifies four types of distractions: off-screen gaze, drowsiness, speaking, and unattended screens, adjusting gaze analysis based on whether the viewer is using a desktop or mobile device.
Datasets: Gaze
The authors used four datasets to power and evaluate their attention-detection system: three focusing on gaze behavior, speaking, and yawning, and a fourth drawn from real-world ad-testing sessions containing various distraction types. Custom datasets were created for each category, sourced from a proprietary repository featuring millions of recorded sessions of participants watching ads in home or workplace environments, with informed consent.
To construct the gaze dataset, participants followed a moving dot across the screen and then looked away in four directions. This process was repeated three times to establish the relationship between capture and coverage.
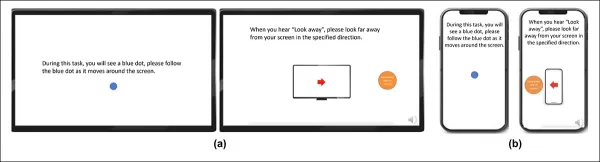 *Screenshots showing the gaze video stimulus on (a) desktop and (b) mobile devices. The first and third frames display instructions to follow a moving dot, while the second and fourth prompt participants to look away from the screen.*
*Screenshots showing the gaze video stimulus on (a) desktop and (b) mobile devices. The first and third frames display instructions to follow a moving dot, while the second and fourth prompt participants to look away from the screen.*
The moving-dot segments were labeled as attentive, and the off-screen segments as inattentive, creating a labeled dataset of both positive and negative examples. Each video lasted about 160 seconds, with separate versions for desktop and mobile platforms. A total of 609 videos were collected, split into 158 training samples and 451 for testing.
Datasets: Speaking
In this context, speaking for longer than one second is considered a sign of inattention. Since the controlled environment doesn't record audio, speech is inferred by observing the movement of estimated facial landmarks. The authors created a dataset based on visual input, divided into two parts: one manually labeled by three annotators, and the other automatically labeled based on session type.
Datasets: Yawning
Existing yawning datasets weren't suitable for ad-testing scenarios, so the authors used 735 videos from their internal collection, focusing on sessions likely to contain a jaw drop lasting more than one second. Each video was manually labeled by three annotators as either showing active or inactive yawning, with only 2.6 percent of frames containing active yawns.
Datasets: Distraction
The distraction dataset was drawn from the authors' ad-testing repository, where participants viewed actual advertisements without assigned tasks. A total of 520 sessions were randomly selected and manually labeled by three annotators as either attentive or inattentive, with inattentive behavior including off-screen gaze, speaking, drowsiness, and unattended screens.
Attention Models
The proposed attention model processes low-level visual features like facial expressions, head pose, and gaze direction, extracted through AFFDEX 2.0 and SmartEye SDK. These are converted into high-level indicators, with each distractor handled by a separate binary classifier trained on its own dataset for independent optimization and evaluation.
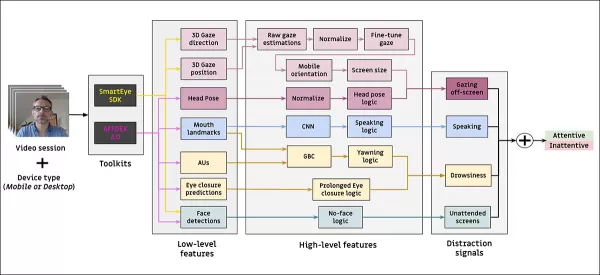 *Schema for the proposed monitoring system.*
*Schema for the proposed monitoring system.*
The gaze model determines whether the viewer is looking at or away from the screen using normalized gaze coordinates, with separate calibration for desktop and mobile devices. A linear Support Vector Machine (SVM) is used to smooth rapid gaze shifts.
To detect speaking without audio, the system uses cropped mouth regions and a 3D-CNN trained on both conversational and non-conversational video segments. Yawning is detected using full-face image crops, with a 3D-CNN trained on manually labeled frames. Screen abandonment is identified through the absence of a face or extreme head pose, with predictions made by a decision tree.
Final attention status is determined using a fixed rule: if any module detects inattention, the viewer is marked as inattentive, prioritizing sensitivity and tuned separately for desktop and mobile contexts.
Tests
The tests follow an ablative method, where components are removed and the effect on the outcome noted. The gaze model identified off-screen behavior through three key steps: normalizing raw gaze estimates, fine-tuning the output, and estimating screen size for desktop devices.
 *Different categories of perceived inattention identified in the study.*
*Different categories of perceived inattention identified in the study.*
Performance declined when any step was omitted, with normalization proving especially valuable on desktops. The study also assessed how visual features predicted mobile camera orientation, with the combination of face location, head pose, and eye gaze reaching a score of 0.91.
 *Results indicating the performance of the full gaze model, alongside versions with individual processing steps removed.*
*Results indicating the performance of the full gaze model, alongside versions with individual processing steps removed.*
The speaking model, trained on vertical lip distance, achieved a ROC-AUC of 0.97 on the manually labeled test set and 0.96 on the larger automatically labeled dataset. The yawning model reached a ROC-AUC of 96.6 percent using mouth aspect ratio alone, improving to 97.5 percent when combined with action unit predictions from AFFDEX 2.0.
The unattended-screen model classified moments as inattentive when both AFFDEX 2.0 and SmartEye failed to detect a face for more than one second. Only 27 percent of 'no-face' activations were due to users physically leaving the screen.
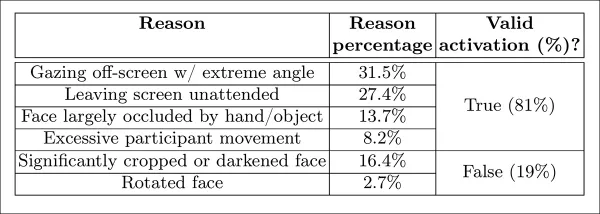 *Diverse obtained reasons why a face was not found, in certain instances.*
*Diverse obtained reasons why a face was not found, in certain instances.*
The authors evaluated how adding different distraction signals affected the overall performance of their attention model. Attention detection improved consistently as more distraction types were added, with off-screen gaze providing the strongest baseline.
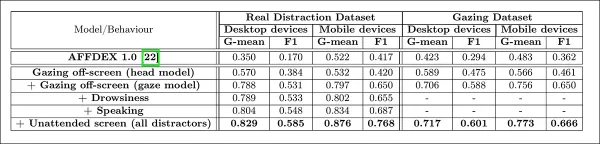 *The effect of adding diverse distraction signals to the architecture.*
*The effect of adding diverse distraction signals to the architecture.*
The authors compared their model to AFFDEX 1.0, a prior system used in ad testing, and found that even the current model's head-based gaze detection outperformed AFFDEX 1.0 across both device types.
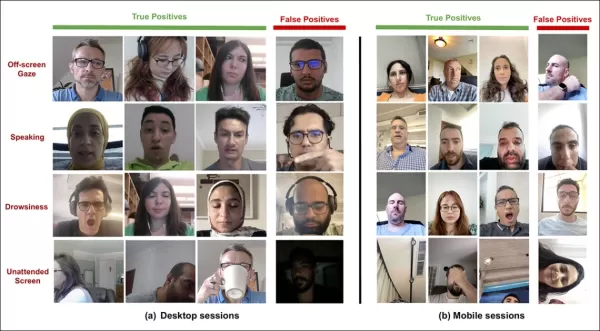 *Sample outputs from the attention model across desktop and mobile devices, with each row presenting examples of true and false positives for different distraction types.*
*Sample outputs from the attention model across desktop and mobile devices, with each row presenting examples of true and false positives for different distraction types.*
Conclusion
The results represent a meaningful advance over prior work, offering a glimpse into the industry's persistent drive to understand the viewer's internal state. Although the data was gathered with consent, the methodology points toward future frameworks that could extend beyond structured, market-research settings. This conclusion is reinforced by the secretive nature of this research, which remains closely guarded by the industry.
Related article
 Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Related Special Topic Recommendations
Business
Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Related Special Topic Recommendations
Business
 Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
 10 tools
10 tools
 xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

 Comments (25)
0/500
Comments (25)
0/500
![JustinAnderson]()
¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
![MatthewSanchez]()
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
![StephenGonzalez]()
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
![EdwardRamirez]()
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
![EricLewis]()
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
![JoseLewis]()
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂
The online advertising industry poured a staggering $740.3 billion USD into its efforts in 2023, making it clear why companies in this space are so keen on advancing computer vision research. They're particularly focused on facial and eye-gaze recognition technologies, with age estimation playing a pivotal role in demographic analytics. This is crucial for advertisers aiming to target specific age groups.
Though the industry tends to keep its cards close to the chest, it occasionally shares glimpses of its more advanced proprietary work through published studies. These studies often involve participants who have agreed to be part of AI-driven analyses, which aim to understand how viewers interact with advertisements.
*Estimating age in an in-the-wild advertising context is of interest to advertisers who may be targeting a particular age demographic. In this experimental example of automatic facial age estimation, the age of performer Bob Dylan is tracked across the years.* Source: https://arxiv.org/pdf/1906.03625
One of the tools frequently used in these facial estimation systems is Dlib's Histogram of Oriented Gradients (HoG), which helps in analyzing facial features.
*Dlib's Histogram of Oriented Gradients (HoG) is often used in facial estimation systems.* Source: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Animal Instinct
When it comes to understanding viewer engagement, the advertising industry is particularly interested in identifying false positives—instances where the system misinterprets a viewer's actions—and establishing clear criteria for when someone isn't fully engaged with an ad. This is especially relevant in screen-based advertising, where studies focus on two main environments: desktop and mobile, each requiring tailored tracking solutions.
Advertisers often categorize viewer disengagement into two behaviors: 'owl behavior' and 'lizard behavior.' If you're turning your head away from the ad, that's 'owl behavior.' If your head stays still but your eyes wander off the screen, that's 'lizard behavior.' These behaviors are crucial for systems to capture accurately when testing new ads under controlled conditions.
*Examples of 'Owl' and 'Lizard' behavior in a subject of an advertising research project.* Source: https://arxiv.org/pdf/1508.04028
A recent paper from SmartEye's Affectiva acquisition tackles these issues head-on. It proposes an architecture that combines several existing frameworks to create a comprehensive feature set for detecting viewer attention across different conditions and reactions. This system can tell if a viewer is bored, engaged, or distracted from the content the advertiser wants them to focus on.
*Examples of true and false positives detected by the new attention system for various distraction signals, shown separately for desktop and mobile devices.* Source: https://arxiv.org/pdf/2504.06237
The authors of the paper highlight the limited research on monitoring attention during online ads and note that previous studies often overlooked critical factors like device type, camera placement, and screen size. Their proposed architecture aims to address these gaps by detecting various distractors, including owl and lizard behaviors, speaking, drowsiness, and unattended screens, while integrating device-specific features to enhance accuracy.
The paper, titled "Monitoring Viewer Attention During Online Ads," was authored by four researchers at Affectiva.
Method and Data
Given the secretive nature of these systems, the paper doesn't directly compare its approach with competitors but presents its findings through ablation studies. It deviates from the typical format of Computer Vision literature, so we'll explore the research as it's presented.
The authors point out that only a few studies have specifically addressed attention detection in the context of online ads. For instance, the AFFDEX SDK, which offers real-time multi-face recognition, infers attention solely from head pose, labeling participants as inattentive if their head angle exceeds a certain threshold.
*An example from the AFFDEX SDK, an Affectiva system which relies on head pose as an indicator of attention.* Source: https://www.youtube.com/watch?v=c2CWb5jHmbY
In a 2019 collaboration titled "Automatic Measurement of Visual Attention to Video Content using Deep Learning," a dataset of around 28,000 participants was annotated for various inattentive behaviors, and a CNN-LSTM model was trained to detect attention from facial appearance over time.
*From the 2019 paper, an example illustrating predicted attention states for a viewer watching video content.* Source: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
However, these earlier efforts didn't account for device-specific factors like whether the participant was using a desktop or mobile device, nor did they consider screen size or camera placement. The AFFDEX system focused only on identifying gaze diversion, while the 2019 work attempted to detect a broader set of behaviors but may have been limited by its use of a single shallow CNN.
The authors note that much of the existing research isn't optimized for ad testing, which has unique needs compared to other domains like driving or education. They've developed an architecture for detecting viewer attention during online ads, leveraging two commercial toolkits: AFFDEX 2.0 and SmartEye SDK.
*Examples of facial analysis from AFFDEX 2.0.* Source: https://arxiv.org/pdf/2202.12059
These toolkits extract low-level features like facial expressions, head pose, and gaze direction, which are then processed to produce higher-level indicators such as gaze position on the screen, yawning, and speaking. The system identifies four types of distractions: off-screen gaze, drowsiness, speaking, and unattended screens, adjusting gaze analysis based on whether the viewer is using a desktop or mobile device.
Datasets: Gaze
The authors used four datasets to power and evaluate their attention-detection system: three focusing on gaze behavior, speaking, and yawning, and a fourth drawn from real-world ad-testing sessions containing various distraction types. Custom datasets were created for each category, sourced from a proprietary repository featuring millions of recorded sessions of participants watching ads in home or workplace environments, with informed consent.
To construct the gaze dataset, participants followed a moving dot across the screen and then looked away in four directions. This process was repeated three times to establish the relationship between capture and coverage.
*Screenshots showing the gaze video stimulus on (a) desktop and (b) mobile devices. The first and third frames display instructions to follow a moving dot, while the second and fourth prompt participants to look away from the screen.*
The moving-dot segments were labeled as attentive, and the off-screen segments as inattentive, creating a labeled dataset of both positive and negative examples. Each video lasted about 160 seconds, with separate versions for desktop and mobile platforms. A total of 609 videos were collected, split into 158 training samples and 451 for testing.
Datasets: Speaking
In this context, speaking for longer than one second is considered a sign of inattention. Since the controlled environment doesn't record audio, speech is inferred by observing the movement of estimated facial landmarks. The authors created a dataset based on visual input, divided into two parts: one manually labeled by three annotators, and the other automatically labeled based on session type.
Datasets: Yawning
Existing yawning datasets weren't suitable for ad-testing scenarios, so the authors used 735 videos from their internal collection, focusing on sessions likely to contain a jaw drop lasting more than one second. Each video was manually labeled by three annotators as either showing active or inactive yawning, with only 2.6 percent of frames containing active yawns.
Datasets: Distraction
The distraction dataset was drawn from the authors' ad-testing repository, where participants viewed actual advertisements without assigned tasks. A total of 520 sessions were randomly selected and manually labeled by three annotators as either attentive or inattentive, with inattentive behavior including off-screen gaze, speaking, drowsiness, and unattended screens.
Attention Models
The proposed attention model processes low-level visual features like facial expressions, head pose, and gaze direction, extracted through AFFDEX 2.0 and SmartEye SDK. These are converted into high-level indicators, with each distractor handled by a separate binary classifier trained on its own dataset for independent optimization and evaluation.
*Schema for the proposed monitoring system.*
The gaze model determines whether the viewer is looking at or away from the screen using normalized gaze coordinates, with separate calibration for desktop and mobile devices. A linear Support Vector Machine (SVM) is used to smooth rapid gaze shifts.
To detect speaking without audio, the system uses cropped mouth regions and a 3D-CNN trained on both conversational and non-conversational video segments. Yawning is detected using full-face image crops, with a 3D-CNN trained on manually labeled frames. Screen abandonment is identified through the absence of a face or extreme head pose, with predictions made by a decision tree.
Final attention status is determined using a fixed rule: if any module detects inattention, the viewer is marked as inattentive, prioritizing sensitivity and tuned separately for desktop and mobile contexts.
Tests
The tests follow an ablative method, where components are removed and the effect on the outcome noted. The gaze model identified off-screen behavior through three key steps: normalizing raw gaze estimates, fine-tuning the output, and estimating screen size for desktop devices.
*Different categories of perceived inattention identified in the study.*
Performance declined when any step was omitted, with normalization proving especially valuable on desktops. The study also assessed how visual features predicted mobile camera orientation, with the combination of face location, head pose, and eye gaze reaching a score of 0.91.
*Results indicating the performance of the full gaze model, alongside versions with individual processing steps removed.*
The speaking model, trained on vertical lip distance, achieved a ROC-AUC of 0.97 on the manually labeled test set and 0.96 on the larger automatically labeled dataset. The yawning model reached a ROC-AUC of 96.6 percent using mouth aspect ratio alone, improving to 97.5 percent when combined with action unit predictions from AFFDEX 2.0.
The unattended-screen model classified moments as inattentive when both AFFDEX 2.0 and SmartEye failed to detect a face for more than one second. Only 27 percent of 'no-face' activations were due to users physically leaving the screen.
*Diverse obtained reasons why a face was not found, in certain instances.*
The authors evaluated how adding different distraction signals affected the overall performance of their attention model. Attention detection improved consistently as more distraction types were added, with off-screen gaze providing the strongest baseline.
*The effect of adding diverse distraction signals to the architecture.*
The authors compared their model to AFFDEX 1.0, a prior system used in ad testing, and found that even the current model's head-based gaze detection outperformed AFFDEX 1.0 across both device types.
*Sample outputs from the attention model across desktop and mobile devices, with each row presenting examples of true and false positives for different distraction types.*
Conclusion
The results represent a meaningful advance over prior work, offering a glimpse into the industry's persistent drive to understand the viewer's internal state. Although the data was gathered with consent, the methodology points toward future frameworks that could extend beyond structured, market-research settings. This conclusion is reinforced by the secretive nature of this research, which remains closely guarded by the industry.










 Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
Haier Launches World's Lightest AI Sports Exoskeleton Robot, Weighing Just 1.75 kg
Haier Group has introduced the world's lightest AI-powered exoskeleton robot for sports — the Haier Exoskeleton Robot W3. This launch sets a new industry record for lightness, marking a major breakthrough in lightweight design and intelligent human m
 Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
Yaoke Media's First AIGC Drama 'The Mystery of the Bronze in Qinling' Launches Today with AI-Signed Leads
Today marks the official launch of Yaoke Media's AIGC fantasy mystery short drama, "The Secret Story of the Qinling Bronze." Starring the company's first two signed AI actors, Qin Lingyue and Lin Xiyanyan, the story unfolds in the enigmatic Qinling m
 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂













