
















 집
집광고주는 청중 분석에서 '올빼미와 도마뱀'을 대상으로합니다
온라인 광고 산업은 2023년에 7,403억 달러라는 놀라운 금액을 노력에 투입했으며, 이로 인해 이 분야의 기업들이 컴퓨터 비전 연구를 발전시키는 데 열중하는 이유가 분명해졌습니다. 그들은 특히 얼굴 및 시선 인식 기술에 집중하고 있으며, 연령 추정은 인구통계 분석에서 중요한 역할을 합니다. 이는 특정 연령대를 타겟팅하려는 광고주들에게 매우 중요합니다.
이 산업은 비밀을 유지하는 경향이 있지만, 가끔씩 출판된 연구를 통해 보다 발전된 독점 작업의 일부를 공개합니다. 이러한 연구는 종종 AI 기반 분석에 참여하기로 동의한 참가자들을 포함하며, 시청자가 광고와 어떻게 상호작용하는지 이해하려는 것을 목표로 합니다.
 *야외 광고 상황에서 연령 추정은 특정 인구통계를 타겟팅하려는 광고주들에게 관심의 대상입니다. 이 자동 얼굴 연령 추정의 실험적 예에서, 공연자 Bob Dylan의 연령이 여러 해에 걸쳐 추적됩니다.* 출처: https://arxiv.org/pdf/1906.03625
*야외 광고 상황에서 연령 추정은 특정 인구통계를 타겟팅하려는 광고주들에게 관심의 대상입니다. 이 자동 얼굴 연령 추정의 실험적 예에서, 공연자 Bob Dylan의 연령이 여러 해에 걸쳐 추적됩니다.* 출처: https://arxiv.org/pdf/1906.03625
이러한 얼굴 추정 시스템에서 자주 사용되는 도구 중 하나는 Dlib의 방향성 그라디언트 히스토그램(HoG)으로, 얼굴 특징을 분석하는 데 도움을 줍니다.
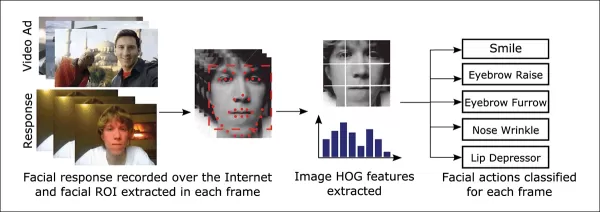 *Dlib의 방향성 그라디언트 히스토그램(HoG)은 얼굴 추정 시스템에서 자주 사용됩니다.* 출처: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
*Dlib의 방향성 그라디언트 히스토그램(HoG)은 얼굴 추정 시스템에서 자주 사용됩니다.* 출처: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
동물적 본능
시청자 참여를 이해하는 데 있어, 광고 산업은 특히 시스템이 시청자의 행동을 잘못 해석하는 오탐지(false positives)를 식별하고, 누군가가 광고에 완전히 몰입하지 않은 경우를 명확히 하기 위한 기준을 설정하는 데 관심이 많습니다. 이는 특히 데스크톱과 모바일, 두 가지 주요 환경에 초점을 맞춘 스크린 기반 광고에서 중요하며, 각각 맞춤형 추적 솔루션이 필요합니다.
광고주들은 시청자의 비참여를 두 가지 행동으로 분류합니다: '부엉이 행동'과 '도마뱀 행동'입니다. 광고에서 고개를 돌리면 '부엉이 행동'이고, 고개는 가만히 있지만 눈이 화면 밖으로 향하면 '도마뱀 행동'입니다. 이러한 행동은 새로운 광고를 통제된 조건에서 테스트할 때 시스템이 정확히 포착해야 할 중요한 요소입니다.
 *'부엉이'와 '도마뱀' 행동의 예, 광고 연구 프로젝트의 대상에서.* 출처: https://arxiv.org/pdf/1508.04028
*'부엉이'와 '도마뱀' 행동의 예, 광고 연구 프로젝트의 대상에서.* 출처: https://arxiv.org/pdf/1508.04028
SmartEye의 Affectiva 인수에서 나온 최근 논문은 이러한 문제를 정면으로 다룹니다. 이 논문은 다양한 조건과 반응에서 시청자의 주의를 감지하기 위한 포괄적인 기능 세트를 만들기 위해 여러 기존 프레임워크를 결합한 아키텍처를 제안합니다. 이 시스템은 시청자가 지루해하거나, 몰입하거나, 광고주가 집중시키고자 하는 콘텐츠에서 주의가 분산되었는지 알 수 있습니다.
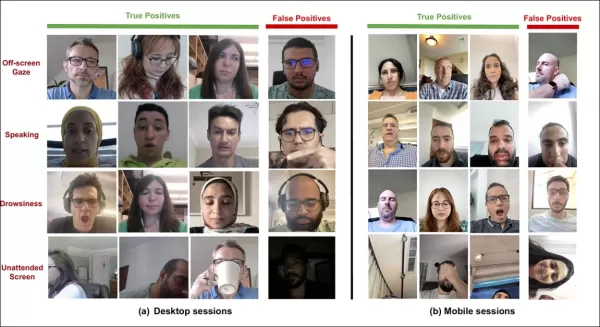 *다양한 주의 분산 신호에 대해 새로운 주의 시스템이 감지한 참과 오탐지의 예, 데스크톱과 모바일 장치에 대해 별도로 표시.* 출처: https://arxiv.org/pdf/2504.06237
*다양한 주의 분산 신호에 대해 새로운 주의 시스템이 감지한 참과 오탐지의 예, 데스크톱과 모바일 장치에 대해 별도로 표시.* 출처: https://arxiv.org/pdf/2504.06237
논문의 저자들은 온라인 광고 중 주의 모니터링에 대한 연구가 제한적이며, 이전 연구들은 장치 유형, 카메라 위치, 화면 크기와 같은 중요한 요소를 간과했다고 지적합니다. 그들의 제안된 아키텍처는 부엉이와 도마뱀 행동, 말하기, 졸림, 무인 화면 등을 포함한 다양한 주의 분산 요소를 감지하고, 장치별 기능을 통합하여 정확도를 높이는 것을 목표로 합니다.
이 논문, "온라인 광고 중 시청자 주의 모니터링"은 Affectiva의 네 명의 연구자에 의해 작성되었습니다.
방법과 데이터
이러한 시스템의 비밀스러운 특성을 고려할 때, 논문은 경쟁자와의 직접적인 비교는 하지 않지만 절제 연구를 통해 결과를 제시합니다. 이는 컴퓨터 비전 문헌의 전형적인 형식에서 벗어나므로, 제시된 대로 연구를 탐구할 것입니다.
저자들은 온라인 광고 맥락에서 주의 감지에 특화된 연구가 소수에 불과하다고 지적합니다. 예를 들어, AFFDEX SDK는 실시간 다중 얼굴 인식을 제공하며, 머리 자세만으로 주의를 추론하여 참가자의 머리 각도가 특정 임계값을 초과하면 부주의로 분류합니다.
 *AFFDEX SDK의 예, Affectiva 시스템으로 머리 자세를 주의의 지표로 사용.* 출처: https://www.youtube.com/watch?v=c2CWb5jHmbY
*AFFDEX SDK의 예, Affectiva 시스템으로 머리 자세를 주의의 지표로 사용.* 출처: https://www.youtube.com/watch?v=c2CWb5jHmbY
2019년 협업 논문 "비디오 콘텐츠에 대한 시각적 주의의 자동 측정"에서는 약 28,000명의 참가자 데이터셋이 다양한 부주의 행동으로 주석 처리되었으며, 얼굴 외관을 통해 시간을 거쳐 주의를 감지하기 위해 CNN-LSTM 모델이 훈련되었습니다.
 *2019년 논문에서, 비디오 콘텐츠를 시청하는 시청자의 예측된 주의 상태를 보여주는 예.* 출처: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
*2019년 논문에서, 비디오 콘텐츠를 시청하는 시청자의 예측된 주의 상태를 보여주는 예.* 출처: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
그러나 이러한 초기 노력은 참가자가 데스크톱 또는 모바일 장치를 사용하는지, 화면 크기나 카메라 배치를 고려하지 않았습니다. AFFDEX 시스템은 시선 전환 식별에만 초점을 맞췄으며, 2019년 연구는 더 광범위한 행동을 감지하려 했지만 단일 얕은 CNN 사용으로 인해 제한되었을 수 있습니다.
저자들은 기존 연구의 대부분이 광고 테스트에 최적화되지 않았으며, 이는 운전이나 교육과 같은 다른 도메인과 비교해 독특한 요구사항이 있다고 지적합니다. 그들은 AFFDEX 2.0과 SmartEye SDK, 두 개의 상용 툴킷을 활용하여 온라인 광고 중 시청자 주의를 감지하는 아키텍처를 개발했습니다.
 *AFFDEX 2.0의 얼굴 분석 예.* 출처: https://arxiv.org/pdf/2202.12059
*AFFDEX 2.0의 얼굴 분석 예.* 출처: https://arxiv.org/pdf/2202.12059
이러한 툴킷은 얼굴 표정, 머리 자세, 시선 방향과 같은 저수준 기능을 추출하며, 이는 화면상의 시선 위치, 하품, 말하기와 같은 고수준 지표로 처리됩니다. 시스템은 화면 밖 시선, 졸림, 말하기, 무인 화면의 네 가지 주의 분산 유형을 식별하며, 시청자가 데스크톱 또는 모바일 장치를 사용하는지에 따라 시선 분석을 조정합니다.
데이터셋: 시선
저자들은 주의 감지 시스템을 구동하고 평가하기 위해 네 개의 데이터셋을 사용했습니다: 시선 행동, 말하기, 하품에 초점을 맞춘 세 개와 다양한 주의 분산 유형을 포함하는 실제 광고 테스트 세션에서 추출된 네 번째 데이터셋입니다. 각 카테고리에 대해 수백만 개의 광고 시청 세션이 기록된 독점 저장소에서 맞춤형 데이터셋이 생성되었으며, 참가자의 동의가 포함되었습니다.
시선 데이터셋을 구성하기 위해, 참가자들은 화면을 가로지르는 움직이는 점을 따라가고, 네 방향으로 시선을 돌렸습니다. 이 과정은 캡처와 커버리지 간의 관계를 설정하기 위해 세 번 반복되었습니다.
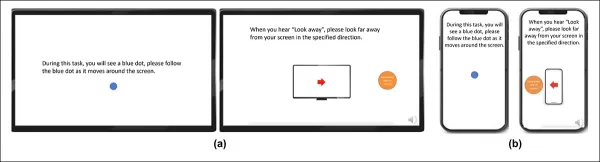 *(a) 데스크톱과 (b) 모바일 장치에서 시선 비디오 자극을 보여주는 스크린샷. 첫 번째와 세 번째 프레임은 움직이는 점을 따라가라는 지침을 표시하며, 두 번째와 네 번째는 화면 밖을 보라는 프롬프트를 표시합니다.*
*(a) 데스크톱과 (b) 모바일 장치에서 시선 비디오 자극을 보여주는 스크린샷. 첫 번째와 세 번째 프레임은 움직이는 점을 따라가라는 지침을 표시하며, 두 번째와 네 번째는 화면 밖을 보라는 프롬프트를 표시합니다.*
움직이는 점 세그먼트는 주의 집중으로, 화면 밖 세그먼트는 부주의로 라벨링되어 긍정적 및 부정적 예를 포함한 라벨링된 데이터셋을 생성했습니다. 각 비디오는 약 160초로, 데스크톱과 모바일 플랫폼용으로 별도의 버전이 있었습니다. 총 609개의 비디오가 수집되었으며, 158개는 훈련 샘플로, 451개는 테스트용으로 분할되었습니다.
데이터셋: 말하기
이 맥락에서 1초 이상 말하는 것은 부주의의 신호로 간주됩니다. 통제된 환경에서는 오디오를 녹음하지 않으므로, 추정된 얼굴 랜드마크의 움직임을 관찰하여 말을 추론합니다. 저자들은 시각 입력을 기반으로 데이터셋을 생성했으며, 이는 두 부분으로 나뉩니다: 하나는 세 명의 주석자가 수동으로 라벨링한 부분이고, 다른 하나는 세션 유형에 따라 자동으로 라벨링된 부분입니다.
데이터셋: 하품
기존 하품 데이터셋은 광고 테스트 시나리오에 적합하지 않았으므로, 저자들은 내부 컬렉션에서 735개의 비디오를 사용했으며, 1초 이상 지속되는 턱 움직임이 포함될 가능성이 높은 세션에 초점을 맞췄습니다. 각 비디오는 세 명의 주석자가 활성 또는 비활성 하품으로 수동 라벨링했으며, 활성 하품은 프레임의 2.6%만 포함했습니다.
데이터셋: 주의 분산
주의 분산 데이터셋은 저자의 광고 테스트 저장소에서 추출되었으며, 참가자들이 과제를 지정받지 않고 실제 광고를 시청했습니다. 총 520개의 세션이 무작위로 선택되었으며, 세 명의 주석자가 주의 집중 또는 부주의로 수동 라벨링했으며, 부주의 행동에는 화면 밖 시선, 말하기, 졸림, 무인 화면이 포함되었습니다.
주의 모델
제안된 주의 모델은 AFFDEX 2.0과 SmartEye SDK를 통해 추출된 얼굴 표정, 머리 자세, 시선 방향과 같은 저수준 시각 기능을 처리합니다. 이는 고수준 지표로 변환되며, 각 주의 분산 요소는 독립적인 최적화와 평가를 위해 자체 데이터셋으로 훈련된 별도의 이진 분류기로 처리됩니다.
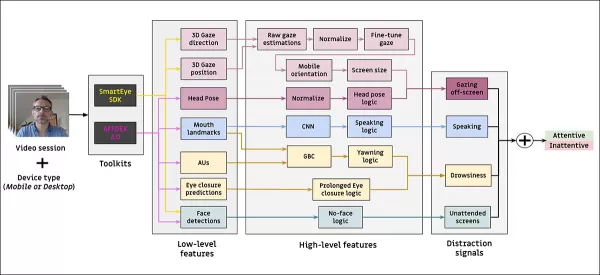 *제안된 모니터링 시스템의 스키마.*
*제안된 모니터링 시스템의 스키마.*
시선 모델은 정규화된 시선 좌표를 사용하여 시청자가 화면을 보고 있는지 또는 밖을 보고 있는지를 판단하며, 데스크톱과 모바일 장치에 대해 별도의 보정이 이루어집니다. 선형 서포트 벡터 머신(SVM)은 빠른 시선 이동을 부드럽게 하기 위해 사용됩니다.
오디오 없이 말하기를 감지하기 위해, 시스템은 입술 영역을 자르고 대화 및 비대화 비디오 세그먼트를 모두 훈련한 3D-CNN을 사용합니다. 하품은 전체 얼굴 이미지 자르기를 사용하여 감지되며, 수동으로 라벨링된 프레임으로 훈련된 3D-CNN을 사용합니다. 화면 이탈은 얼굴이 없거나 극단적인 머리 자세로 식별되며, 의사결정 트리로 예측됩니다.
최종 주의 상태는 고정된 규칙을 사용하여 결정됩니다: 어떤 모듈이 부주의를 감지하면 시청자는 부주의로 표시되며, 민감도를 우선시하고 데스크톱 및 모바일 컨텍스트에 대해 별도로 조정됩니다.
테스트
테스트는 구성 요소를 제거하고 결과에 미치는 영향을 기록하는 절제 방법을 따릅니다. 시선 모델은 원시 시선 추정을 정규화하고, 출력을 미세 조정하며, 데스크톱 장치의 화면 크기를 추정하는 세 가지 주요 단계를 통해 화면 밖 행동을 식별했습니다.
 *연구에서 식별된 다양한 부주의 인식 카테고리.*
*연구에서 식별된 다양한 부주의 인식 카테고리.*
어느 단계라도 생략하면 성능이 저하되었으며, 특히 데스크톱에서 정규화가 특히 가치 있음이 입증되었습니다. 연구는 또한 얼굴 위치, 머리 자세, 시선이 모바일 카메라 방향을 예측하는 데 어떻게 기여했는지 평가했으며, 이 조합은 0.91의 점수를 달성했습니다.
 *전체 시선 모델의 성능을 나타내는 결과, 개별 처리 단계를 제거한 버전과 함께.*
*전체 시선 모델의 성능을 나타내는 결과, 개별 처리 단계를 제거한 버전과 함께.*
수직 입술 거리로 훈련된 말하기 모델은 수동 라벨링된 테스트 세트에서 ROC-AUC 0.97을, 더 큰 자동 라벨링 데이터셋에서 0.96을 달성했습니다. 하품 모델은 입술 비율만으로 ROC-AUC 96.6%를 달성했으며, AFFDEX 2.0의 액션 유닛 예측과 결합하면 97.5%로 향상되었습니다.
무인 화면 모델은 AFFDEX 2.0과 SmartEye가 1초 이상 얼굴을 감지하지 못하면 부주의로 분류했습니다. '얼굴 없음' 활성화의 27%만이 사용자가 실제로 화면을 떠난 경우였습니다.
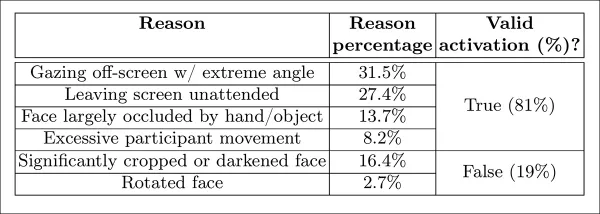 *특정 경우에 얼굴이 발견되지 않은 다양한 이유.*
*특정 경우에 얼굴이 발견되지 않은 다양한 이유.*
저자들은 다양한 주의 분산 신호를 추가하는 것이 주의 모델의 전체 성능에 어떤 영향을 미치는지 평가했습니다. 주의 감지는 더 많은 주의 분산 유형이 추가될수록 일관되게 개선되었으며, 화면 밖 시선이 가장 강력한 기준선을 제공했습니다.
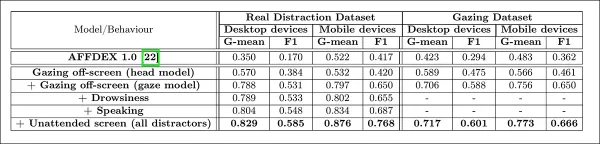 *아키텍처에 다양한 주의 분산 신호를 추가하는 효과.*
*아키텍처에 다양한 주의 분산 신호를 추가하는 효과.*
저자들은 자신들의 모델을 광고 테스트에 사용된 이전 시스템인 AFFDEX 1.0과 비교했으며, 현재 모델의 머리 기반 시선 감지가 두 장치 유형 모두에서 AFFDEX 1.0을 능가함을 발견했습니다.
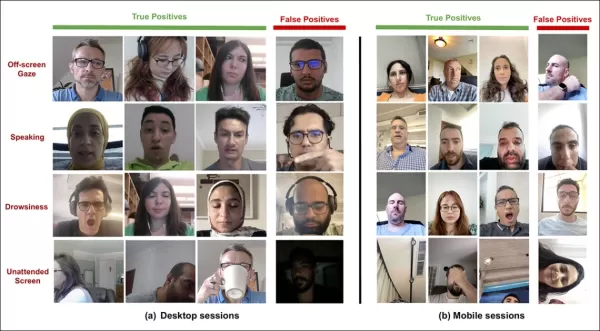 *데스크톱과 모바일 장치에서 주의 모델의 샘플 출력, 각 행은 다양한 주의 분산 유형에 대한 참과 오탐지 예를 제시.*
*데스크톱과 모바일 장치에서 주의 모델의 샘플 출력, 각 행은 다양한 주의 분산 유형에 대한 참과 오탐지 예를 제시.*
결론
결과는 이전 연구에 비해 의미 있는 발전을 나타내며, 산업이 시청자의 내부 상태를 이해하려는 지속적인 노력을 엿볼 수 있게 합니다. 데이터는 동의 하에 수집되었지만, 방법론은 구조화된 시장 조사 설정을 넘어 확장될 수 있는 미래 프레임워크를 시사합니다. 이 결론은 산업이 철저히 보호하는 이 연구의 비밀스러운 특성에 의해 강화됩니다.
관련 기사
 텐센트의 ‘샤오롱샤’가 예상을 뛰어넘는 급성장을 기록하자, 운영팀은 처리 용량을 10배로 확대하고 사과와 함께 보상 조치를 취했다
텐센트는 모든 시나리오를 아우르는 AI 지능형 에이전트인 ‘WorkBuddy’를 공식 출시하며, 높은 통합성과 낮은 도입 장벽을 바탕으로 대규모 모델 애플리케이션 레이어 경쟁의 새로운 국면을 열었다.출시 당일 이 제품은 업계의 즉각적인 관심을 끌었다. 사용자 트래픽이 예상을 훨씬 뛰어넘으면서 관련 서비스인 텐센트 클라우드 코드 어시스턴트(CodeBuddy)
수노(Suno)의 주요 투자자: 게시물 삭제로는 저작권 소송의 허점을 메울 수 없다
많은 기대를 모았던 AI 음악 생성 플랫폼 ‘수노(Suno)’가 치열한 저작권 분쟁에 휘말린 가운데, 이 플랫폼의 주요 투자자가 한 솔직한 발언이 상대방 측이 바랐던 바로 그 증거를 제공해 준 것으로 보인다. Suno의 핵심 투자사인 멘로 벤처스(Menlo Ventures)의 파트너 C.C. 공은 최근 회사의 현재 법적 방어 전략과 정면으로 배치되는 트윗을
클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
관련 특별 주제 추천
만화 창작
텐센트의 ‘샤오롱샤’가 예상을 뛰어넘는 급성장을 기록하자, 운영팀은 처리 용량을 10배로 확대하고 사과와 함께 보상 조치를 취했다
텐센트는 모든 시나리오를 아우르는 AI 지능형 에이전트인 ‘WorkBuddy’를 공식 출시하며, 높은 통합성과 낮은 도입 장벽을 바탕으로 대규모 모델 애플리케이션 레이어 경쟁의 새로운 국면을 열었다.출시 당일 이 제품은 업계의 즉각적인 관심을 끌었다. 사용자 트래픽이 예상을 훨씬 뛰어넘으면서 관련 서비스인 텐센트 클라우드 코드 어시스턴트(CodeBuddy)
수노(Suno)의 주요 투자자: 게시물 삭제로는 저작권 소송의 허점을 메울 수 없다
많은 기대를 모았던 AI 음악 생성 플랫폼 ‘수노(Suno)’가 치열한 저작권 분쟁에 휘말린 가운데, 이 플랫폼의 주요 투자자가 한 솔직한 발언이 상대방 측이 바랐던 바로 그 증거를 제공해 준 것으로 보인다. Suno의 핵심 투자사인 멘로 벤처스(Menlo Ventures)의 파트너 C.C. 공은 최근 회사의 현재 법적 방어 전략과 정면으로 배치되는 트윗을
클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
관련 특별 주제 추천
만화 창작
 소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
 15 도구
15 도구
 xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

 의견 (25)
0/500
의견 (25)
0/500
![JustinAnderson]()
¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
![MatthewSanchez]()
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
![StephenGonzalez]()
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
![EdwardRamirez]()
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
![EricLewis]()
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
![JoseLewis]()
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂
온라인 광고 산업은 2023년에 7,403억 달러라는 놀라운 금액을 노력에 투입했으며, 이로 인해 이 분야의 기업들이 컴퓨터 비전 연구를 발전시키는 데 열중하는 이유가 분명해졌습니다. 그들은 특히 얼굴 및 시선 인식 기술에 집중하고 있으며, 연령 추정은 인구통계 분석에서 중요한 역할을 합니다. 이는 특정 연령대를 타겟팅하려는 광고주들에게 매우 중요합니다.
이 산업은 비밀을 유지하는 경향이 있지만, 가끔씩 출판된 연구를 통해 보다 발전된 독점 작업의 일부를 공개합니다. 이러한 연구는 종종 AI 기반 분석에 참여하기로 동의한 참가자들을 포함하며, 시청자가 광고와 어떻게 상호작용하는지 이해하려는 것을 목표로 합니다.
*야외 광고 상황에서 연령 추정은 특정 인구통계를 타겟팅하려는 광고주들에게 관심의 대상입니다. 이 자동 얼굴 연령 추정의 실험적 예에서, 공연자 Bob Dylan의 연령이 여러 해에 걸쳐 추적됩니다.* 출처: https://arxiv.org/pdf/1906.03625
이러한 얼굴 추정 시스템에서 자주 사용되는 도구 중 하나는 Dlib의 방향성 그라디언트 히스토그램(HoG)으로, 얼굴 특징을 분석하는 데 도움을 줍니다.
*Dlib의 방향성 그라디언트 히스토그램(HoG)은 얼굴 추정 시스템에서 자주 사용됩니다.* 출처: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
동물적 본능
시청자 참여를 이해하는 데 있어, 광고 산업은 특히 시스템이 시청자의 행동을 잘못 해석하는 오탐지(false positives)를 식별하고, 누군가가 광고에 완전히 몰입하지 않은 경우를 명확히 하기 위한 기준을 설정하는 데 관심이 많습니다. 이는 특히 데스크톱과 모바일, 두 가지 주요 환경에 초점을 맞춘 스크린 기반 광고에서 중요하며, 각각 맞춤형 추적 솔루션이 필요합니다.
광고주들은 시청자의 비참여를 두 가지 행동으로 분류합니다: '부엉이 행동'과 '도마뱀 행동'입니다. 광고에서 고개를 돌리면 '부엉이 행동'이고, 고개는 가만히 있지만 눈이 화면 밖으로 향하면 '도마뱀 행동'입니다. 이러한 행동은 새로운 광고를 통제된 조건에서 테스트할 때 시스템이 정확히 포착해야 할 중요한 요소입니다.
*'부엉이'와 '도마뱀' 행동의 예, 광고 연구 프로젝트의 대상에서.* 출처: https://arxiv.org/pdf/1508.04028
SmartEye의 Affectiva 인수에서 나온 최근 논문은 이러한 문제를 정면으로 다룹니다. 이 논문은 다양한 조건과 반응에서 시청자의 주의를 감지하기 위한 포괄적인 기능 세트를 만들기 위해 여러 기존 프레임워크를 결합한 아키텍처를 제안합니다. 이 시스템은 시청자가 지루해하거나, 몰입하거나, 광고주가 집중시키고자 하는 콘텐츠에서 주의가 분산되었는지 알 수 있습니다.
*다양한 주의 분산 신호에 대해 새로운 주의 시스템이 감지한 참과 오탐지의 예, 데스크톱과 모바일 장치에 대해 별도로 표시.* 출처: https://arxiv.org/pdf/2504.06237
논문의 저자들은 온라인 광고 중 주의 모니터링에 대한 연구가 제한적이며, 이전 연구들은 장치 유형, 카메라 위치, 화면 크기와 같은 중요한 요소를 간과했다고 지적합니다. 그들의 제안된 아키텍처는 부엉이와 도마뱀 행동, 말하기, 졸림, 무인 화면 등을 포함한 다양한 주의 분산 요소를 감지하고, 장치별 기능을 통합하여 정확도를 높이는 것을 목표로 합니다.
이 논문, "온라인 광고 중 시청자 주의 모니터링"은 Affectiva의 네 명의 연구자에 의해 작성되었습니다.
방법과 데이터
이러한 시스템의 비밀스러운 특성을 고려할 때, 논문은 경쟁자와의 직접적인 비교는 하지 않지만 절제 연구를 통해 결과를 제시합니다. 이는 컴퓨터 비전 문헌의 전형적인 형식에서 벗어나므로, 제시된 대로 연구를 탐구할 것입니다.
저자들은 온라인 광고 맥락에서 주의 감지에 특화된 연구가 소수에 불과하다고 지적합니다. 예를 들어, AFFDEX SDK는 실시간 다중 얼굴 인식을 제공하며, 머리 자세만으로 주의를 추론하여 참가자의 머리 각도가 특정 임계값을 초과하면 부주의로 분류합니다.
*AFFDEX SDK의 예, Affectiva 시스템으로 머리 자세를 주의의 지표로 사용.* 출처: https://www.youtube.com/watch?v=c2CWb5jHmbY
2019년 협업 논문 "비디오 콘텐츠에 대한 시각적 주의의 자동 측정"에서는 약 28,000명의 참가자 데이터셋이 다양한 부주의 행동으로 주석 처리되었으며, 얼굴 외관을 통해 시간을 거쳐 주의를 감지하기 위해 CNN-LSTM 모델이 훈련되었습니다.
*2019년 논문에서, 비디오 콘텐츠를 시청하는 시청자의 예측된 주의 상태를 보여주는 예.* 출처: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
그러나 이러한 초기 노력은 참가자가 데스크톱 또는 모바일 장치를 사용하는지, 화면 크기나 카메라 배치를 고려하지 않았습니다. AFFDEX 시스템은 시선 전환 식별에만 초점을 맞췄으며, 2019년 연구는 더 광범위한 행동을 감지하려 했지만 단일 얕은 CNN 사용으로 인해 제한되었을 수 있습니다.
저자들은 기존 연구의 대부분이 광고 테스트에 최적화되지 않았으며, 이는 운전이나 교육과 같은 다른 도메인과 비교해 독특한 요구사항이 있다고 지적합니다. 그들은 AFFDEX 2.0과 SmartEye SDK, 두 개의 상용 툴킷을 활용하여 온라인 광고 중 시청자 주의를 감지하는 아키텍처를 개발했습니다.
*AFFDEX 2.0의 얼굴 분석 예.* 출처: https://arxiv.org/pdf/2202.12059
이러한 툴킷은 얼굴 표정, 머리 자세, 시선 방향과 같은 저수준 기능을 추출하며, 이는 화면상의 시선 위치, 하품, 말하기와 같은 고수준 지표로 처리됩니다. 시스템은 화면 밖 시선, 졸림, 말하기, 무인 화면의 네 가지 주의 분산 유형을 식별하며, 시청자가 데스크톱 또는 모바일 장치를 사용하는지에 따라 시선 분석을 조정합니다.
데이터셋: 시선
저자들은 주의 감지 시스템을 구동하고 평가하기 위해 네 개의 데이터셋을 사용했습니다: 시선 행동, 말하기, 하품에 초점을 맞춘 세 개와 다양한 주의 분산 유형을 포함하는 실제 광고 테스트 세션에서 추출된 네 번째 데이터셋입니다. 각 카테고리에 대해 수백만 개의 광고 시청 세션이 기록된 독점 저장소에서 맞춤형 데이터셋이 생성되었으며, 참가자의 동의가 포함되었습니다.
시선 데이터셋을 구성하기 위해, 참가자들은 화면을 가로지르는 움직이는 점을 따라가고, 네 방향으로 시선을 돌렸습니다. 이 과정은 캡처와 커버리지 간의 관계를 설정하기 위해 세 번 반복되었습니다.
*(a) 데스크톱과 (b) 모바일 장치에서 시선 비디오 자극을 보여주는 스크린샷. 첫 번째와 세 번째 프레임은 움직이는 점을 따라가라는 지침을 표시하며, 두 번째와 네 번째는 화면 밖을 보라는 프롬프트를 표시합니다.*
움직이는 점 세그먼트는 주의 집중으로, 화면 밖 세그먼트는 부주의로 라벨링되어 긍정적 및 부정적 예를 포함한 라벨링된 데이터셋을 생성했습니다. 각 비디오는 약 160초로, 데스크톱과 모바일 플랫폼용으로 별도의 버전이 있었습니다. 총 609개의 비디오가 수집되었으며, 158개는 훈련 샘플로, 451개는 테스트용으로 분할되었습니다.
데이터셋: 말하기
이 맥락에서 1초 이상 말하는 것은 부주의의 신호로 간주됩니다. 통제된 환경에서는 오디오를 녹음하지 않으므로, 추정된 얼굴 랜드마크의 움직임을 관찰하여 말을 추론합니다. 저자들은 시각 입력을 기반으로 데이터셋을 생성했으며, 이는 두 부분으로 나뉩니다: 하나는 세 명의 주석자가 수동으로 라벨링한 부분이고, 다른 하나는 세션 유형에 따라 자동으로 라벨링된 부분입니다.
데이터셋: 하품
기존 하품 데이터셋은 광고 테스트 시나리오에 적합하지 않았으므로, 저자들은 내부 컬렉션에서 735개의 비디오를 사용했으며, 1초 이상 지속되는 턱 움직임이 포함될 가능성이 높은 세션에 초점을 맞췄습니다. 각 비디오는 세 명의 주석자가 활성 또는 비활성 하품으로 수동 라벨링했으며, 활성 하품은 프레임의 2.6%만 포함했습니다.
데이터셋: 주의 분산
주의 분산 데이터셋은 저자의 광고 테스트 저장소에서 추출되었으며, 참가자들이 과제를 지정받지 않고 실제 광고를 시청했습니다. 총 520개의 세션이 무작위로 선택되었으며, 세 명의 주석자가 주의 집중 또는 부주의로 수동 라벨링했으며, 부주의 행동에는 화면 밖 시선, 말하기, 졸림, 무인 화면이 포함되었습니다.
주의 모델
제안된 주의 모델은 AFFDEX 2.0과 SmartEye SDK를 통해 추출된 얼굴 표정, 머리 자세, 시선 방향과 같은 저수준 시각 기능을 처리합니다. 이는 고수준 지표로 변환되며, 각 주의 분산 요소는 독립적인 최적화와 평가를 위해 자체 데이터셋으로 훈련된 별도의 이진 분류기로 처리됩니다.
*제안된 모니터링 시스템의 스키마.*
시선 모델은 정규화된 시선 좌표를 사용하여 시청자가 화면을 보고 있는지 또는 밖을 보고 있는지를 판단하며, 데스크톱과 모바일 장치에 대해 별도의 보정이 이루어집니다. 선형 서포트 벡터 머신(SVM)은 빠른 시선 이동을 부드럽게 하기 위해 사용됩니다.
오디오 없이 말하기를 감지하기 위해, 시스템은 입술 영역을 자르고 대화 및 비대화 비디오 세그먼트를 모두 훈련한 3D-CNN을 사용합니다. 하품은 전체 얼굴 이미지 자르기를 사용하여 감지되며, 수동으로 라벨링된 프레임으로 훈련된 3D-CNN을 사용합니다. 화면 이탈은 얼굴이 없거나 극단적인 머리 자세로 식별되며, 의사결정 트리로 예측됩니다.
최종 주의 상태는 고정된 규칙을 사용하여 결정됩니다: 어떤 모듈이 부주의를 감지하면 시청자는 부주의로 표시되며, 민감도를 우선시하고 데스크톱 및 모바일 컨텍스트에 대해 별도로 조정됩니다.
테스트
테스트는 구성 요소를 제거하고 결과에 미치는 영향을 기록하는 절제 방법을 따릅니다. 시선 모델은 원시 시선 추정을 정규화하고, 출력을 미세 조정하며, 데스크톱 장치의 화면 크기를 추정하는 세 가지 주요 단계를 통해 화면 밖 행동을 식별했습니다.
*연구에서 식별된 다양한 부주의 인식 카테고리.*
어느 단계라도 생략하면 성능이 저하되었으며, 특히 데스크톱에서 정규화가 특히 가치 있음이 입증되었습니다. 연구는 또한 얼굴 위치, 머리 자세, 시선이 모바일 카메라 방향을 예측하는 데 어떻게 기여했는지 평가했으며, 이 조합은 0.91의 점수를 달성했습니다.
*전체 시선 모델의 성능을 나타내는 결과, 개별 처리 단계를 제거한 버전과 함께.*
수직 입술 거리로 훈련된 말하기 모델은 수동 라벨링된 테스트 세트에서 ROC-AUC 0.97을, 더 큰 자동 라벨링 데이터셋에서 0.96을 달성했습니다. 하품 모델은 입술 비율만으로 ROC-AUC 96.6%를 달성했으며, AFFDEX 2.0의 액션 유닛 예측과 결합하면 97.5%로 향상되었습니다.
무인 화면 모델은 AFFDEX 2.0과 SmartEye가 1초 이상 얼굴을 감지하지 못하면 부주의로 분류했습니다. '얼굴 없음' 활성화의 27%만이 사용자가 실제로 화면을 떠난 경우였습니다.
*특정 경우에 얼굴이 발견되지 않은 다양한 이유.*
저자들은 다양한 주의 분산 신호를 추가하는 것이 주의 모델의 전체 성능에 어떤 영향을 미치는지 평가했습니다. 주의 감지는 더 많은 주의 분산 유형이 추가될수록 일관되게 개선되었으며, 화면 밖 시선이 가장 강력한 기준선을 제공했습니다.
*아키텍처에 다양한 주의 분산 신호를 추가하는 효과.*
저자들은 자신들의 모델을 광고 테스트에 사용된 이전 시스템인 AFFDEX 1.0과 비교했으며, 현재 모델의 머리 기반 시선 감지가 두 장치 유형 모두에서 AFFDEX 1.0을 능가함을 발견했습니다.
*데스크톱과 모바일 장치에서 주의 모델의 샘플 출력, 각 행은 다양한 주의 분산 유형에 대한 참과 오탐지 예를 제시.*
결론
결과는 이전 연구에 비해 의미 있는 발전을 나타내며, 산업이 시청자의 내부 상태를 이해하려는 지속적인 노력을 엿볼 수 있게 합니다. 데이터는 동의 하에 수집되었지만, 방법론은 구조화된 시장 조사 설정을 넘어 확장될 수 있는 미래 프레임워크를 시사합니다. 이 결론은 산업이 철저히 보호하는 이 연구의 비밀스러운 특성에 의해 강화됩니다.










 텐센트의 ‘샤오롱샤’가 예상을 뛰어넘는 급성장을 기록하자, 운영팀은 처리 용량을 10배로 확대하고 사과와 함께 보상 조치를 취했다
텐센트는 모든 시나리오를 아우르는 AI 지능형 에이전트인 ‘WorkBuddy’를 공식 출시하며, 높은 통합성과 낮은 도입 장벽을 바탕으로 대규모 모델 애플리케이션 레이어 경쟁의 새로운 국면을 열었다.출시 당일 이 제품은 업계의 즉각적인 관심을 끌었다. 사용자 트래픽이 예상을 훨씬 뛰어넘으면서 관련 서비스인 텐센트 클라우드 코드 어시스턴트(CodeBuddy)
텐센트의 ‘샤오롱샤’가 예상을 뛰어넘는 급성장을 기록하자, 운영팀은 처리 용량을 10배로 확대하고 사과와 함께 보상 조치를 취했다
텐센트는 모든 시나리오를 아우르는 AI 지능형 에이전트인 ‘WorkBuddy’를 공식 출시하며, 높은 통합성과 낮은 도입 장벽을 바탕으로 대규모 모델 애플리케이션 레이어 경쟁의 새로운 국면을 열었다.출시 당일 이 제품은 업계의 즉각적인 관심을 끌었다. 사용자 트래픽이 예상을 훨씬 뛰어넘으면서 관련 서비스인 텐센트 클라우드 코드 어시스턴트(CodeBuddy)
 수노(Suno)의 주요 투자자: 게시물 삭제로는 저작권 소송의 허점을 메울 수 없다
많은 기대를 모았던 AI 음악 생성 플랫폼 ‘수노(Suno)’가 치열한 저작권 분쟁에 휘말린 가운데, 이 플랫폼의 주요 투자자가 한 솔직한 발언이 상대방 측이 바랐던 바로 그 증거를 제공해 준 것으로 보인다. Suno의 핵심 투자사인 멘로 벤처스(Menlo Ventures)의 파트너 C.C. 공은 최근 회사의 현재 법적 방어 전략과 정면으로 배치되는 트윗을
수노(Suno)의 주요 투자자: 게시물 삭제로는 저작권 소송의 허점을 메울 수 없다
많은 기대를 모았던 AI 음악 생성 플랫폼 ‘수노(Suno)’가 치열한 저작권 분쟁에 휘말린 가운데, 이 플랫폼의 주요 투자자가 한 솔직한 발언이 상대방 측이 바랐던 바로 그 증거를 제공해 준 것으로 보인다. Suno의 핵심 투자사인 멘로 벤처스(Menlo Ventures)의 파트너 C.C. 공은 최근 회사의 현재 법적 방어 전략과 정면으로 배치되는 트윗을
 클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho
클로드 오푸스 4.7, 인공지능보다 신뢰성을 중시하며 출시
Anthropic은 올해도 거의 이틀에 한 번꼴로 새로운 기능을 출시하며 공격적인 행보를 이어가고 있습니다. 많은 기대를 모았던 Claude Opus 4.7이 방금 공식 출시되었는데, 흥미롭게도 Anthropic은 발표문에서 “이 모델이 우리가 개발한 가장 강력한 모델은 아닙니다”라고 솔직하게 밝혔습니다. 소문으로만 돌던 더 강력한 'Claude Mytho

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂













