
















 Lar
LarO anunciando alvos de corujas e lagartos na análise do público
A indústria de publicidade online investiu impressionantes US$740,3 bilhões em seus esforços em 2023, deixando claro por que as empresas nesse setor estão tão interessadas em avançar a pesquisa em visão computacional. Elas estão particularmente focadas em tecnologias de reconhecimento facial e de direção do olhar, com a estimativa de idade desempenhando um papel central na análise demográfica. Isso é crucial para anunciantes que buscam atingir grupos etários específicos.
Embora a indústria tenda a manter suas cartas na manga, ocasionalmente compartilha vislumbres de seus trabalhos proprietários mais avançados por meio de estudos publicados. Esses estudos frequentemente envolvem participantes que concordaram em fazer parte de análises conduzidas por IA, que visam entender como os espectadores interagem com os anúncios.
 *Estimar a idade em um contexto de publicidade em ambiente natural é de interesse para anunciantes que podem estar mirando um grupo demográfico específico. Neste exemplo experimental de estimativa automática de idade facial, a idade do artista Bob Dylan é rastreada ao longo dos anos.* Fonte: https://arxiv.org/pdf/1906.03625
*Estimar a idade em um contexto de publicidade em ambiente natural é de interesse para anunciantes que podem estar mirando um grupo demográfico específico. Neste exemplo experimental de estimativa automática de idade facial, a idade do artista Bob Dylan é rastreada ao longo dos anos.* Fonte: https://arxiv.org/pdf/1906.03625
Uma das ferramentas frequentemente usadas nesses sistemas de estimativa facial é o Histograma de Gradientes Orientados (HoG) do Dlib, que auxilia na análise de características faciais.
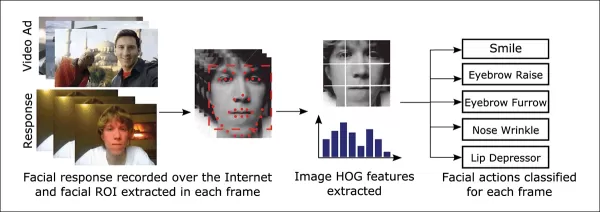 *O Histograma de Gradientes Orientados (HoG) do Dlib é frequentemente usado em sistemas de estimativa facial.* Fonte: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
*O Histograma de Gradientes Orientados (HoG) do Dlib é frequentemente usado em sistemas de estimativa facial.* Fonte: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Instinto Animal
Quando se trata de entender o engajamento do espectador, a indústria de publicidade está particularmente interessada em identificar falsos positivos — casos em que o sistema interpreta erroneamente as ações de um espectador — e estabelecer critérios claros para quando alguém não está totalmente engajado com um anúncio. Isso é especialmente relevante em publicidade baseada em tela, onde os estudos focam em dois ambientes principais: desktop e móvel, cada um exigindo soluções de rastreamento personalizadas.
Os anunciantes frequentemente categorizam o desengajamento do espectador em dois comportamentos: 'comportamento de coruja' e 'comportamento de lagarto'. Se você vira a cabeça para longe do anúncio, isso é 'comportamento de coruja'. Se sua cabeça permanece parada, mas seus olhos desviam da tela, isso é 'comportamento de lagarto'. Esses comportamentos são cruciais para os sistemas capturarem com precisão ao testar novos anúncios em condições controladas.
 *Exemplos de comportamento de 'coruja' e 'lagarto' em um sujeito de um projeto de pesquisa de publicidade.* Fonte: https://arxiv.org/pdf/1508.04028
*Exemplos de comportamento de 'coruja' e 'lagarto' em um sujeito de um projeto de pesquisa de publicidade.* Fonte: https://arxiv.org/pdf/1508.04028
Um artigo recente da aquisição da Affectiva pela SmartEye aborda essas questões diretamente. Ele propõe uma arquitetura que combina vários frameworks existentes para criar um conjunto abrangente de recursos para detectar a atenção do espectador em diferentes condições e reações. Esse sistema pode determinar se um espectador está entediado, engajado ou distraído do conteúdo que o anunciante deseja que ele foque.
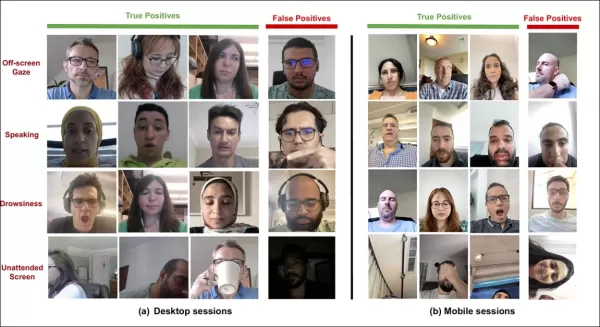 *Exemplos de verdadeiros e falsos positivos detectados pelo novo sistema de atenção para vários sinais de distração, mostrados separadamente para dispositivos desktop e móveis.* Fonte: https://arxiv.org/pdf/2504.06237
*Exemplos de verdadeiros e falsos positivos detectados pelo novo sistema de atenção para vários sinais de distração, mostrados separadamente para dispositivos desktop e móveis.* Fonte: https://arxiv.org/pdf/2504.06237
Os autores do artigo destacam a pesquisa limitada sobre monitoramento da atenção durante anúncios online e notam que estudos anteriores frequentemente ignoraram fatores críticos como tipo de dispositivo, posicionamento da câmera e tamanho da tela. A arquitetura proposta visa abordar essas lacunas detectando vários distratores, incluindo comportamentos de coruja e lagarto, fala, sonolência e telas desatendidas, enquanto integra recursos específicos do dispositivo para aumentar a precisão.
O artigo, intitulado "Monitoramento da Atenção do Espectador Durante Anúncios Online", foi escrito por quatro pesquisadores da Affectiva.
Método e Dados
Dada a natureza secreta desses sistemas, o artigo não compara diretamente sua abordagem com concorrentes, mas apresenta suas descobertas por meio de estudos de ablação. Ele se desvia do formato típico da literatura de Visão Computacional, então exploraremos a pesquisa como apresentada.
Os autores apontam que poucos estudos abordaram especificamente a detecção de atenção no contexto de anúncios online. Por exemplo, o AFFDEX SDK, que oferece reconhecimento facial múltiplo em tempo real, infere atenção apenas a partir da pose da cabeça, rotulando participantes como desatentos se o ângulo da cabeça exceder um certo limite.
 *Um exemplo do AFFDEX SDK, um sistema da Affectiva que depende da pose da cabeça como indicador de atenção.* Fonte: https://www.youtube.com/watch?v=c2CWb5jHmbY
*Um exemplo do AFFDEX SDK, um sistema da Affectiva que depende da pose da cabeça como indicador de atenção.* Fonte: https://www.youtube.com/watch?v=c2CWb5jHmbY
Em uma colaboração de 2019 intitulada "Medição Automática da Atenção Visual ao Conteúdo de Vídeo usando Deep Learning", um conjunto de dados de cerca de 28.000 participantes foi anotado para vários comportamentos desatentos, e um modelo CNN-LSTM foi treinado para detectar atenção a partir da aparência facial ao longo do tempo.
 *Do artigo de 2019, um exemplo ilustrando estados de atenção previstos para um espectador assistindo a conteúdo de vídeo.* Fonte: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
*Do artigo de 2019, um exemplo ilustrando estados de atenção previstos para um espectador assistindo a conteúdo de vídeo.* Fonte: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
No entanto, esses esforços anteriores não consideraram fatores específicos do dispositivo, como se o participante estava usando um desktop ou dispositivo móvel, nem levaram em conta o tamanho da tela ou o posicionamento da câmera. O sistema AFFDEX focava apenas em identificar a diversão do olhar, enquanto o trabalho de 2019 tentou detectar um conjunto mais amplo de comportamentos, mas pode ter sido limitado pelo uso de uma única CNN rasa.
Os autores observam que grande parte da pesquisa existente não é otimizada para testes de anúncios, que têm necessidades únicas em comparação com outros domínios como direção ou educação. Eles desenvolveram uma arquitetura para detectar a atenção do espectador durante anúncios online, aproveitando dois kits de ferramentas comerciais: AFFDEX 2.0 e SmartEye SDK.
 *Exemplos de análise facial do AFFDEX 2.0.* Fonte: https://arxiv.org/pdf/2202.12059
*Exemplos de análise facial do AFFDEX 2.0.* Fonte: https://arxiv.org/pdf/2202.12059
Esses kits de ferramentas extraem recursos de baixo nível como expressões faciais, pose da cabeça e direção do olhar, que são então processados para produzir indicadores de alto nível, como posição do olhar na tela, bocejo e fala. O sistema identifica quatro tipos de distrações: olhar fora da tela, sonolência, fala e telas desatendidas, ajustando a análise do olhar com base em se o espectador está usando um desktop ou dispositivo móvel.
Conjuntos de Dados: Olhar
Os autores usaram quatro conjuntos de dados para alimentar e avaliar seu sistema de detecção de atenção: três focados em comportamento de olhar, fala e bocejo, e um quarto extraído de sessões reais de teste de anúncios contendo vários tipos de distração. Conjuntos de dados personalizados foram criados para cada categoria, obtidos de um repositório proprietário com milhões de sessões gravadas de participantes assistindo a anúncios em ambientes domésticos ou de trabalho, com consentimento informado.
Para construir o conjunto de dados de olhar, os participantes seguiram um ponto em movimento na tela e depois olharam para fora em quatro direções. Esse processo foi repetido três vezes para estabelecer a relação entre captura e cobertura.
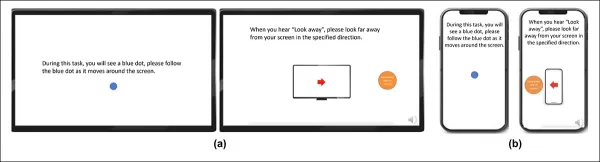 *Capturas de tela mostrando o estímulo de vídeo de olhar em (a) desktop e (b) dispositivos móveis. Os primeiro e terceiro quadros exibem instruções para seguir um ponto em movimento, enquanto o segundo e o quarto solicitam que os participantes olhem para fora da tela.*
*Capturas de tela mostrando o estímulo de vídeo de olhar em (a) desktop e (b) dispositivos móveis. Os primeiro e terceiro quadros exibem instruções para seguir um ponto em movimento, enquanto o segundo e o quarto solicitam que os participantes olhem para fora da tela.*
Os segmentos de ponto em movimento foram rotulados como atentos, e os segmentos fora da tela como desatentos, criando um conjunto de dados rotulado com exemplos positivos e negativos. Cada vídeo durou cerca de 160 segundos, com versões separadas para plataformas desktop e móveis. Um total de 609 vídeos foi coletado, dividido em 158 amostras de treinamento e 451 para teste.
Conjuntos de Dados: Fala
Neste contexto, falar por mais de um segundo é considerado um sinal de desatenção. Como o ambiente controlado não registra áudio, a fala é inferida observando o movimento de marcos faciais estimados. Os autores criaram um conjunto de dados baseado em entrada visual, dividido em duas partes: uma rotulada manualmente por três anotadores, e a outra rotulada automaticamente com base no tipo de sessão.
Conjuntos de Dados: Bocejo
Os conjuntos de dados de bocejo existentes não eram adequados para cenários de teste de anúncios, então os autores usaram 735 vídeos de sua coleção interna, focando em sessões propensas a conter uma abertura de mandíbula por mais de um segundo. Cada vídeo foi rotulado manualmente por três anotadores como mostrando bocejo ativo ou inativo, com apenas 2,6 por cento dos quadros contendo bocejos ativos.
Conjuntos de Dados: Distração
O conjunto de dados de distração foi extraído do repositório de testes de anúncios dos autores, onde os participantes visualizaram anúncios reais sem tarefas atribuídas. Um total de 520 sessões foi selecionado aleatoriamente e rotulado manualmente por três anotadores como atento ou desatento, com comportamento desatento incluindo olhar fora da tela, fala, sonolência e telas desatendidas.
Modelos de Atenção
O modelo de atenção proposto processa recursos visuais de baixo nível, como expressões faciais, pose da cabeça e direção do olhar, extraídos por meio do AFFDEX 2.0 e SmartEye SDK. Esses são convertidos em indicadores de alto nível, com cada distrator tratado por um classificador binário separado treinado em seu próprio conjunto de dados para otimização e avaliação independentes.
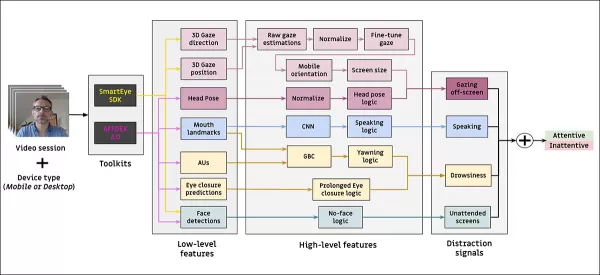 *Esquema para o sistema de monitoramento proposto.*
*Esquema para o sistema de monitoramento proposto.*
O modelo de olhar determina se o espectador está olhando para ou fora da tela usando coordenadas de olhar normalizadas, com calibragem separada para dispositivos desktop e móveis. Uma Máquina de Vetores de Suporte (SVM) linear é usada para suavizar mudanças rápidas de olhar.
Para detectar fala sem áudio, o sistema usa regiões recortadas da boca e uma 3D-CNN treinada em segmentos de vídeo conversacionais e não conversacionais. O bocejo é detectado usando recortes de imagem de rosto completo, com uma 3D-CNN treinada em quadros rotulados manualmente. O abandono da tela é identificado pela ausência de um rosto ou pose extrema da cabeça, com previsões feitas por uma árvore de decisão.
O status final de atenção é determinado usando uma regra fixa: se qualquer módulo detectar desatenção, o espectador é marcado como desatento, priorizando a sensibilidade e ajustado separadamente para contextos desktop e móveis.
Testes
Os testes seguem um método ablativo, onde componentes são removidos e o efeito no resultado é observado. O modelo de olhar identificou comportamento fora da tela por meio de três etapas principais: normalização de estimativas brutas de olhar, ajuste fino da saída e estimativa do tamanho da tela para dispositivos desktop.
 *Diferentes categorias de desatenção percebida identificadas no estudo.*
*Diferentes categorias de desatenção percebida identificadas no estudo.*
O desempenho caiu quando qualquer etapa foi omitida, com a normalização sendo especialmente valiosa em desktops. O estudo também avaliou como os recursos visuais previram a orientação da câmera móvel, com a combinação de localização facial, pose da cabeça e olhar alcançando uma pontuação de 0,91.
 *Resultados indicando o desempenho do modelo de olhar completo, ao lado de versões com etapas de processamento individuais removidas.*
*Resultados indicando o desempenho do modelo de olhar completo, ao lado de versões com etapas de processamento individuais removidas.*
O modelo de fala, treinado na distância vertical dos lábios, alcançou um ROC-AUC de 0,97 no conjunto de teste rotulado manualmente e 0,96 no conjunto maior rotulado automaticamente. O modelo de bocejo alcançou um ROC-AUC de 96,6 por cento usando apenas a proporção de aspecto da boca, melhorando para 97,5 por cento quando combinado com previsões de unidades de ação do AFFDEX 2.0.
O modelo de tela desatendida classificou momentos como desatentos quando ambos AFFDEX 2.0 e SmartEye falharam em detectar um rosto por mais de um segundo. Apenas 27 por cento das ativações de 'sem rosto' foram devido a usuários saindo fisicamente da tela.
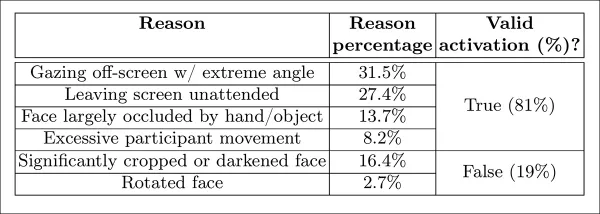 *Diversas razões obtidas por que um rosto não foi encontrado, em certos casos.*
*Diversas razões obtidas por que um rosto não foi encontrado, em certos casos.*
Os autores avaliaram como a adição de diferentes sinais de distração afetou o desempenho geral de seu modelo de atenção. A detecção de atenção melhorou consistentemente à medida que mais tipos de distração foram adicionados, com o olhar fora da tela fornecendo a linha de base mais forte.
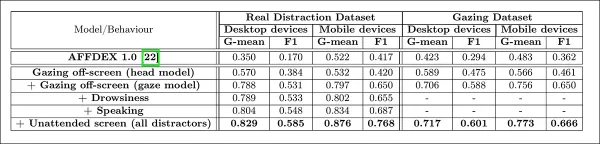 *O efeito de adicionar diversos sinais de distração à arquitetura.*
*O efeito de adicionar diversos sinais de distração à arquitetura.*
Os autores compararam seu modelo ao AFFDEX 1.0, um sistema anterior usado em testes de anúncios, e descobriram que até mesmo a detecção de olhar baseada na cabeça do modelo atual superou o AFFDEX 1.0 em ambos os tipos de dispositivos.
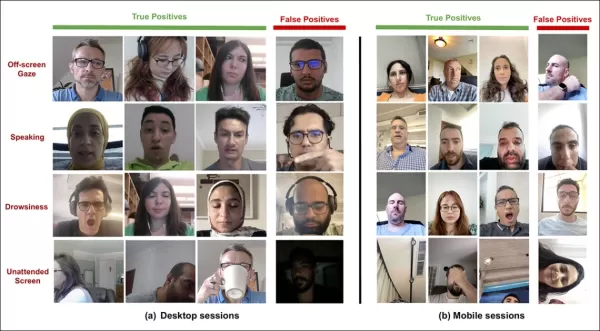 *Saídas de amostra do modelo de atenção em dispositivos desktop e móveis, com cada linha apresentando exemplos de verdadeiros e falsos positivos para diferentes tipos de distração.*
*Saídas de amostra do modelo de atenção em dispositivos desktop e móveis, com cada linha apresentando exemplos de verdadeiros e falsos positivos para diferentes tipos de distração.*
Conclusão
Os resultados representam um avanço significativo em relação ao trabalho anterior, oferecendo um vislumbre do impulso persistente da indústria para entender o estado interno do espectador. Embora os dados tenham sido coletados com consentimento, a metodologia aponta para frameworks futuros que podem se estender além de configurações estruturadas de pesquisa de mercado. Essa conclusão é reforçada pela natureza secreta dessa pesquisa, que permanece rigorosamente protegida pela indústria.
Artigo relacionado
 Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã
Principal investidor da Suno: a exclusão de publicações não resolverá o problema do processo por violação de direitos autorais
A tão esperada plataforma de geração musical por IA, Suno, enfrenta uma dura batalha judicial sobre direitos autorais, e um comentário sincero de seu principal investidor pode ter dado ao lado adversá
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã
Principal investidor da Suno: a exclusão de publicações não resolverá o problema do processo por violação de direitos autorais
A tão esperada plataforma de geração musical por IA, Suno, enfrenta uma dura batalha judicial sobre direitos autorais, e um comentário sincero de seu principal investidor pode ter dado ao lado adversá
Recomendações de tópicos especiais relacionados
Criação de quadrinhos
 Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Os melhores geradores de IA para mangás shonen: crie sequências de ação cheias de adrenalina e efeitos de energia
Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
 15 ferramentas
15 ferramentas
 xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
xix.ai
Negócios
Os melhores aplicativos de controle de despesas com IA: digitalize recibos e categorize automaticamente as despesas corporativas
Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai
Negócios
As melhores ferramentas de recrutamento com IA: analise currículos e automatize o agendamento de entrevistas com candidatos
Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai
Produtividade
Treinadores de bem-estar e concentração com IA: controle o esgotamento e aumente os níveis de energia mental
Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai
chatbot
Os melhores chatbots românticos com IA: construa relacionamentos duradouros com personalidades consistentes
Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai
Educação e Aprendizagem
Os melhores mentores em ciência de dados e inteligência artificial: domínio avançado em SQL, Pandas e fluxos de trabalho de aprendizado de máquina
Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

 Comentários (25)
Comentários (25)
![JustinAnderson]()
¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
![MatthewSanchez]()
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
![StephenGonzalez]()
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
![EdwardRamirez]()
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
![EricLewis]()
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
![JoseLewis]()
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂
A indústria de publicidade online investiu impressionantes US$740,3 bilhões em seus esforços em 2023, deixando claro por que as empresas nesse setor estão tão interessadas em avançar a pesquisa em visão computacional. Elas estão particularmente focadas em tecnologias de reconhecimento facial e de direção do olhar, com a estimativa de idade desempenhando um papel central na análise demográfica. Isso é crucial para anunciantes que buscam atingir grupos etários específicos.
Embora a indústria tenda a manter suas cartas na manga, ocasionalmente compartilha vislumbres de seus trabalhos proprietários mais avançados por meio de estudos publicados. Esses estudos frequentemente envolvem participantes que concordaram em fazer parte de análises conduzidas por IA, que visam entender como os espectadores interagem com os anúncios.
*Estimar a idade em um contexto de publicidade em ambiente natural é de interesse para anunciantes que podem estar mirando um grupo demográfico específico. Neste exemplo experimental de estimativa automática de idade facial, a idade do artista Bob Dylan é rastreada ao longo dos anos.* Fonte: https://arxiv.org/pdf/1906.03625
Uma das ferramentas frequentemente usadas nesses sistemas de estimativa facial é o Histograma de Gradientes Orientados (HoG) do Dlib, que auxilia na análise de características faciais.
*O Histograma de Gradientes Orientados (HoG) do Dlib é frequentemente usado em sistemas de estimativa facial.* Fonte: https://www.computer.org/csdl/journal/ta/2017/02/07475863/13rRUNvyarN
Instinto Animal
Quando se trata de entender o engajamento do espectador, a indústria de publicidade está particularmente interessada em identificar falsos positivos — casos em que o sistema interpreta erroneamente as ações de um espectador — e estabelecer critérios claros para quando alguém não está totalmente engajado com um anúncio. Isso é especialmente relevante em publicidade baseada em tela, onde os estudos focam em dois ambientes principais: desktop e móvel, cada um exigindo soluções de rastreamento personalizadas.
Os anunciantes frequentemente categorizam o desengajamento do espectador em dois comportamentos: 'comportamento de coruja' e 'comportamento de lagarto'. Se você vira a cabeça para longe do anúncio, isso é 'comportamento de coruja'. Se sua cabeça permanece parada, mas seus olhos desviam da tela, isso é 'comportamento de lagarto'. Esses comportamentos são cruciais para os sistemas capturarem com precisão ao testar novos anúncios em condições controladas.
*Exemplos de comportamento de 'coruja' e 'lagarto' em um sujeito de um projeto de pesquisa de publicidade.* Fonte: https://arxiv.org/pdf/1508.04028
Um artigo recente da aquisição da Affectiva pela SmartEye aborda essas questões diretamente. Ele propõe uma arquitetura que combina vários frameworks existentes para criar um conjunto abrangente de recursos para detectar a atenção do espectador em diferentes condições e reações. Esse sistema pode determinar se um espectador está entediado, engajado ou distraído do conteúdo que o anunciante deseja que ele foque.
*Exemplos de verdadeiros e falsos positivos detectados pelo novo sistema de atenção para vários sinais de distração, mostrados separadamente para dispositivos desktop e móveis.* Fonte: https://arxiv.org/pdf/2504.06237
Os autores do artigo destacam a pesquisa limitada sobre monitoramento da atenção durante anúncios online e notam que estudos anteriores frequentemente ignoraram fatores críticos como tipo de dispositivo, posicionamento da câmera e tamanho da tela. A arquitetura proposta visa abordar essas lacunas detectando vários distratores, incluindo comportamentos de coruja e lagarto, fala, sonolência e telas desatendidas, enquanto integra recursos específicos do dispositivo para aumentar a precisão.
O artigo, intitulado "Monitoramento da Atenção do Espectador Durante Anúncios Online", foi escrito por quatro pesquisadores da Affectiva.
Método e Dados
Dada a natureza secreta desses sistemas, o artigo não compara diretamente sua abordagem com concorrentes, mas apresenta suas descobertas por meio de estudos de ablação. Ele se desvia do formato típico da literatura de Visão Computacional, então exploraremos a pesquisa como apresentada.
Os autores apontam que poucos estudos abordaram especificamente a detecção de atenção no contexto de anúncios online. Por exemplo, o AFFDEX SDK, que oferece reconhecimento facial múltiplo em tempo real, infere atenção apenas a partir da pose da cabeça, rotulando participantes como desatentos se o ângulo da cabeça exceder um certo limite.
*Um exemplo do AFFDEX SDK, um sistema da Affectiva que depende da pose da cabeça como indicador de atenção.* Fonte: https://www.youtube.com/watch?v=c2CWb5jHmbY
Em uma colaboração de 2019 intitulada "Medição Automática da Atenção Visual ao Conteúdo de Vídeo usando Deep Learning", um conjunto de dados de cerca de 28.000 participantes foi anotado para vários comportamentos desatentos, e um modelo CNN-LSTM foi treinado para detectar atenção a partir da aparência facial ao longo do tempo.
*Do artigo de 2019, um exemplo ilustrando estados de atenção previstos para um espectador assistindo a conteúdo de vídeo.* Fonte: https://www.jeffcohn.net/wp-content/uploads/2019/07/Attention-13.pdf.pdf
No entanto, esses esforços anteriores não consideraram fatores específicos do dispositivo, como se o participante estava usando um desktop ou dispositivo móvel, nem levaram em conta o tamanho da tela ou o posicionamento da câmera. O sistema AFFDEX focava apenas em identificar a diversão do olhar, enquanto o trabalho de 2019 tentou detectar um conjunto mais amplo de comportamentos, mas pode ter sido limitado pelo uso de uma única CNN rasa.
Os autores observam que grande parte da pesquisa existente não é otimizada para testes de anúncios, que têm necessidades únicas em comparação com outros domínios como direção ou educação. Eles desenvolveram uma arquitetura para detectar a atenção do espectador durante anúncios online, aproveitando dois kits de ferramentas comerciais: AFFDEX 2.0 e SmartEye SDK.
*Exemplos de análise facial do AFFDEX 2.0.* Fonte: https://arxiv.org/pdf/2202.12059
Esses kits de ferramentas extraem recursos de baixo nível como expressões faciais, pose da cabeça e direção do olhar, que são então processados para produzir indicadores de alto nível, como posição do olhar na tela, bocejo e fala. O sistema identifica quatro tipos de distrações: olhar fora da tela, sonolência, fala e telas desatendidas, ajustando a análise do olhar com base em se o espectador está usando um desktop ou dispositivo móvel.
Conjuntos de Dados: Olhar
Os autores usaram quatro conjuntos de dados para alimentar e avaliar seu sistema de detecção de atenção: três focados em comportamento de olhar, fala e bocejo, e um quarto extraído de sessões reais de teste de anúncios contendo vários tipos de distração. Conjuntos de dados personalizados foram criados para cada categoria, obtidos de um repositório proprietário com milhões de sessões gravadas de participantes assistindo a anúncios em ambientes domésticos ou de trabalho, com consentimento informado.
Para construir o conjunto de dados de olhar, os participantes seguiram um ponto em movimento na tela e depois olharam para fora em quatro direções. Esse processo foi repetido três vezes para estabelecer a relação entre captura e cobertura.
*Capturas de tela mostrando o estímulo de vídeo de olhar em (a) desktop e (b) dispositivos móveis. Os primeiro e terceiro quadros exibem instruções para seguir um ponto em movimento, enquanto o segundo e o quarto solicitam que os participantes olhem para fora da tela.*
Os segmentos de ponto em movimento foram rotulados como atentos, e os segmentos fora da tela como desatentos, criando um conjunto de dados rotulado com exemplos positivos e negativos. Cada vídeo durou cerca de 160 segundos, com versões separadas para plataformas desktop e móveis. Um total de 609 vídeos foi coletado, dividido em 158 amostras de treinamento e 451 para teste.
Conjuntos de Dados: Fala
Neste contexto, falar por mais de um segundo é considerado um sinal de desatenção. Como o ambiente controlado não registra áudio, a fala é inferida observando o movimento de marcos faciais estimados. Os autores criaram um conjunto de dados baseado em entrada visual, dividido em duas partes: uma rotulada manualmente por três anotadores, e a outra rotulada automaticamente com base no tipo de sessão.
Conjuntos de Dados: Bocejo
Os conjuntos de dados de bocejo existentes não eram adequados para cenários de teste de anúncios, então os autores usaram 735 vídeos de sua coleção interna, focando em sessões propensas a conter uma abertura de mandíbula por mais de um segundo. Cada vídeo foi rotulado manualmente por três anotadores como mostrando bocejo ativo ou inativo, com apenas 2,6 por cento dos quadros contendo bocejos ativos.
Conjuntos de Dados: Distração
O conjunto de dados de distração foi extraído do repositório de testes de anúncios dos autores, onde os participantes visualizaram anúncios reais sem tarefas atribuídas. Um total de 520 sessões foi selecionado aleatoriamente e rotulado manualmente por três anotadores como atento ou desatento, com comportamento desatento incluindo olhar fora da tela, fala, sonolência e telas desatendidas.
Modelos de Atenção
O modelo de atenção proposto processa recursos visuais de baixo nível, como expressões faciais, pose da cabeça e direção do olhar, extraídos por meio do AFFDEX 2.0 e SmartEye SDK. Esses são convertidos em indicadores de alto nível, com cada distrator tratado por um classificador binário separado treinado em seu próprio conjunto de dados para otimização e avaliação independentes.
*Esquema para o sistema de monitoramento proposto.*
O modelo de olhar determina se o espectador está olhando para ou fora da tela usando coordenadas de olhar normalizadas, com calibragem separada para dispositivos desktop e móveis. Uma Máquina de Vetores de Suporte (SVM) linear é usada para suavizar mudanças rápidas de olhar.
Para detectar fala sem áudio, o sistema usa regiões recortadas da boca e uma 3D-CNN treinada em segmentos de vídeo conversacionais e não conversacionais. O bocejo é detectado usando recortes de imagem de rosto completo, com uma 3D-CNN treinada em quadros rotulados manualmente. O abandono da tela é identificado pela ausência de um rosto ou pose extrema da cabeça, com previsões feitas por uma árvore de decisão.
O status final de atenção é determinado usando uma regra fixa: se qualquer módulo detectar desatenção, o espectador é marcado como desatento, priorizando a sensibilidade e ajustado separadamente para contextos desktop e móveis.
Testes
Os testes seguem um método ablativo, onde componentes são removidos e o efeito no resultado é observado. O modelo de olhar identificou comportamento fora da tela por meio de três etapas principais: normalização de estimativas brutas de olhar, ajuste fino da saída e estimativa do tamanho da tela para dispositivos desktop.
*Diferentes categorias de desatenção percebida identificadas no estudo.*
O desempenho caiu quando qualquer etapa foi omitida, com a normalização sendo especialmente valiosa em desktops. O estudo também avaliou como os recursos visuais previram a orientação da câmera móvel, com a combinação de localização facial, pose da cabeça e olhar alcançando uma pontuação de 0,91.
*Resultados indicando o desempenho do modelo de olhar completo, ao lado de versões com etapas de processamento individuais removidas.*
O modelo de fala, treinado na distância vertical dos lábios, alcançou um ROC-AUC de 0,97 no conjunto de teste rotulado manualmente e 0,96 no conjunto maior rotulado automaticamente. O modelo de bocejo alcançou um ROC-AUC de 96,6 por cento usando apenas a proporção de aspecto da boca, melhorando para 97,5 por cento quando combinado com previsões de unidades de ação do AFFDEX 2.0.
O modelo de tela desatendida classificou momentos como desatentos quando ambos AFFDEX 2.0 e SmartEye falharam em detectar um rosto por mais de um segundo. Apenas 27 por cento das ativações de 'sem rosto' foram devido a usuários saindo fisicamente da tela.
*Diversas razões obtidas por que um rosto não foi encontrado, em certos casos.*
Os autores avaliaram como a adição de diferentes sinais de distração afetou o desempenho geral de seu modelo de atenção. A detecção de atenção melhorou consistentemente à medida que mais tipos de distração foram adicionados, com o olhar fora da tela fornecendo a linha de base mais forte.
*O efeito de adicionar diversos sinais de distração à arquitetura.*
Os autores compararam seu modelo ao AFFDEX 1.0, um sistema anterior usado em testes de anúncios, e descobriram que até mesmo a detecção de olhar baseada na cabeça do modelo atual superou o AFFDEX 1.0 em ambos os tipos de dispositivos.
*Saídas de amostra do modelo de atenção em dispositivos desktop e móveis, com cada linha apresentando exemplos de verdadeiros e falsos positivos para diferentes tipos de distração.*
Conclusão
Os resultados representam um avanço significativo em relação ao trabalho anterior, oferecendo um vislumbre do impulso persistente da indústria para entender o estado interno do espectador. Embora os dados tenham sido coletados com consentimento, a metodologia aponta para frameworks futuros que podem se estender além de configurações estruturadas de pesquisa de mercado. Essa conclusão é reforçada pela natureza secreta dessa pesquisa, que permanece rigorosamente protegida pela indústria.










 Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
Xiaohongshu passa por reestruturação: Conan é nomeado presidente, cria o Departamento de IA e a Divisão Internacional Rednote
Em 30 de abril, a Xiaohongshu enviou um memorando interno a todos os funcionários anunciando o lançamento de uma nova reestruturação organizacional. O cerne dessa mudança envolve a integração total de
 O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã
O jogo "Xiaolongxia", da Tencent, supera as expectativas; equipe amplia capacidade em 10 vezes, pede desculpas e oferece indenização
A Tencent lançou oficialmente o WorkBuddy, um agente inteligente de IA para todos os cenários, marcando uma nova fase na corrida pela camada de aplicação de modelos de grande porte, com alta integraçã
 Principal investidor da Suno: a exclusão de publicações não resolverá o problema do processo por violação de direitos autorais
A tão esperada plataforma de geração musical por IA, Suno, enfrenta uma dura batalha judicial sobre direitos autorais, e um comentário sincero de seu principal investidor pode ter dado ao lado adversá
Principal investidor da Suno: a exclusão de publicações não resolverá o problema do processo por violação de direitos autorais
A tão esperada plataforma de geração musical por IA, Suno, enfrenta uma dura batalha judicial sobre direitos autorais, e um comentário sincero de seu principal investidor pode ter dado ao lado adversá

Descubra os melhores geradores de IA para mangás shonen de 2026 no XIX.AI. Nossa lista selecionada e com as melhores avaliações apresenta ferramentas poderosas para criar sequências de ação cheias de adrenalina e efeitos dinâmicos de energia. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a criar mangás épicos hoje mesmo!
15 ferramentas
xix.ai

Os melhores gerenciadores de despesas com IA de 2026: as ferramentas mais bem avaliadas para digitalizar recibos e categorizar despesas corporativas automaticamente. Descubra soluções poderosas e revolucionárias para uma gestão de despesas sem esforço, um acompanhamento financeiro preciso e uma conformidade simplificada. Nossa comparação, cuidadosamente selecionada e atualizada semanalmente, entre opções gratuitas e pagas ajuda você a encontrar a solução ideal. Aproveite ao máximo as vantagens da IA com as recomendações dos especialistas da XIX.AI.
10 ferramentas
xix.ai

Descubra as melhores ferramentas de recrutamento com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta soluções poderosas e revolucionárias para a triagem de currículos e a automação do agendamento de entrevistas com candidatos. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre o seu assistente de contratação ideal e otimize seu processo de recrutamento hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores coaches de bem-estar pessoal e concentração com IA de 2026 no XIX.AI. Nossos rankings selecionados apresentam ferramentas de ponta e revolucionárias para lidar com o esgotamento e aumentar a energia mental. Compare opções gratuitas e pagas com informações reais. Descubra hoje mesmo o caminho para atingir o máximo de produtividade e bem-estar.
10 ferramentas
xix.ai

Descubra os melhores chatbots românticos com IA de 2026 para construir relacionamentos genuínos e duradouros. Nossa lista selecionada apresenta personalidades marcantes e consistentes, comparações entre versões gratuitas e pagas, além de testes práticos. Encontre seu companheiro ideal e comece a construir seu relacionamento hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Descubra os melhores mentores em ciência de dados com IA para 2026, que o ajudarão a dominar SQL, Pandas e fluxos de trabalho de aprendizado de máquina. Conheça nossa seleção cuidadosamente elaborada e altamente avaliada no XIX.AI para obter orientações poderosas e revolucionárias. Compare opções gratuitas e pagas com informações valiosas da prática real. Domine a ciência de dados hoje mesmo.
10 ferramentas
xix.ai

¡Qué locura que los anunciantes estén agrupando a la gente como 'búhos y lagartijas'! 🦉🦎 Me pregunto qué otros animales raros usan para segmentar audiencias... ¿Habrá categorías como 'armadillos nocturnos' o 'gatos dormilones'? Al final terminaremos siendo etiquetados como mascotas virtuales 😂
Whoa, $740.3 billion on ads in 2023? That’s wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you. 😬 Are we all just owls and lizards to these companies now?
This article's wild! $740B on ads in 2023? No wonder they're obsessed with eye-gaze tech. Kinda creepy how they track faces to guess ages, though—Big Brother vibes! 😬
Whoa, $740B on ads? That's wild! Eye-gaze tech sounds cool but kinda creepy—imagine ads staring back at you! 😆 Curious how accurate their age guesses are.
Esta herramienta para segmentar 'búhos y lagartos' en el análisis de audiencia es un poco rara pero genial. Es increíble cómo usan el reconocimiento facial y de mirada para segmentar grupos específicos. Es un poco escalofriante, pero tengo que admitir que es efectiva. Tal vez puedan usarla para segmentar otros animales también, como 'unicornios'? 😂
This tool for targeting 'Owls and Lizards' in audience analysis is kinda weird but cool! It's amazing how they use facial and eye-gaze recognition to target specific groups. It's a bit creepy, but I gotta admit, it's effective. Maybe they could use it to target other animals too, like 'unicorns'? 😂













