
















 Hogar
Hogar
Las caras sintéticas 'degradadas' pueden mejorar la tecnología de reconocimiento facial
Investigadores de la Universidad Estatal de Michigan han ideado una forma innovadora de usar rostros sintéticos para una causa noble: mejorar la precisión de los sistemas de reconocimiento de imágenes. En lugar de contribuir al fenómeno de los deepfakes, estos rostros sintéticos están diseñados para imitar las imperfecciones que se encuentran en las grabaciones de videovigilancia del mundo real.
El equipo ha desarrollado un Módulo de Síntesis de Rostros Controlable (CFSM) que puede regenerar rostros en un estilo que refleja los defectos típicos de los sistemas de CCTV, como desenfoque facial, baja resolución y ruido del sensor. Este enfoque difiere del uso de imágenes de celebridades de alta calidad de conjuntos de datos populares, que no capturan los desafíos del mundo real que enfrentan los sistemas de reconocimiento facial.
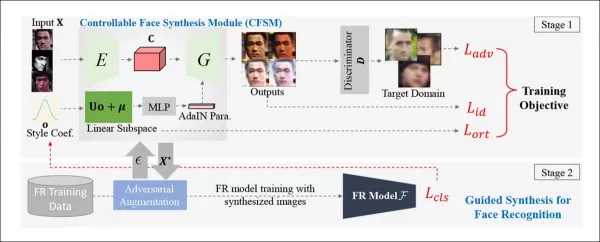 *Arquitectura conceptual para el Módulo de Síntesis de Rostros Controlable (CFSM).* Fuente: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*Arquitectura conceptual para el Módulo de Síntesis de Rostros Controlable (CFSM).* Fuente: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
A diferencia de los sistemas de deepfake que se centran en replicar poses de cabeza y expresiones, CFSM busca generar vistas alternativas que coincidan con el estilo del sistema de reconocimiento objetivo a través de la transferencia de estilo. Este módulo es particularmente útil para adaptarse a sistemas heredados que probablemente no se actualizarán debido a restricciones de costos, pero que aún necesitan contribuir a las tecnologías modernas de reconocimiento facial.
Al probar CFSM, los investigadores observaron mejoras significativas en los sistemas de reconocimiento de imágenes que manejan datos de baja calidad. También descubrieron un beneficio inesperado: la capacidad de caracterizar y comparar conjuntos de datos objetivo, lo que simplifica el proceso de evaluación comparativa y la creación de conjuntos de datos personalizados para diversos sistemas de CCTV.
 *Entrenamiento de los modelos de reconocimiento facial para adaptarse a las limitaciones de los sistemas objetivo.* Fuente: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*Entrenamiento de los modelos de reconocimiento facial para adaptarse a las limitaciones de los sistemas objetivo.* Fuente: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
El método también se puede aplicar a conjuntos de datos existentes, realizando efectivamente una adaptación de dominio para hacerlos más adecuados para el reconocimiento facial. La investigación, titulada **Síntesis de Rostros Controlable y Guiada para el Reconocimiento Facial sin Restricciones**, cuenta con el apoyo parcial de la Oficina del Director de Inteligencia Nacional de EE. UU. (ODNI, en IARPA) e involucra a cuatro investigadores del departamento de Ciencias de la Computación e Ingeniería de MSU.
Reconocimiento Facial de Baja Calidad: Un Campo en Crecimiento
En los últimos años, el reconocimiento facial de baja calidad (LQFR) ha surgido como un área de estudio significativa. Muchos sistemas de videovigilancia más antiguos, diseñados para ser duraderos y de larga duración, han quedado obsoletos y luchan por servir como fuentes de datos efectivas para el aprendizaje automático debido a la deuda técnica.
 Niveles variables de resolución facial en una gama de sistemas de videovigilancia históricos y más recientes. Fuente: https://arxiv.org/pdf/1805.11519.pdf
Niveles variables de resolución facial en una gama de sistemas de videovigilancia históricos y más recientes. Fuente: https://arxiv.org/pdf/1805.11519.pdf
Afortunadamente, los modelos de difusión y otros modelos basados en ruido están bien adaptados para abordar este problema. Muchos de los últimos sistemas de síntesis de imágenes incluyen la mejora de imágenes de baja resolución como parte de su proceso, lo cual también es crucial para las técnicas de compresión neuronal.
El desafío en el reconocimiento facial es maximizar la precisión con la menor cantidad posible de características extraídas de imágenes de baja resolución. Esto no solo es útil para identificar rostros en baja resolución, sino que también es necesario debido a las limitaciones en el tamaño de la imagen en el espacio latente de los modelos de entrenamiento.
En visión por computadora, las 'características' se refieren a las características distintivas de cualquier imagen, no solo rostros. Con los avances en algoritmos de mejora de resolución, se han propuesto varios métodos para mejorar las grabaciones de vigilancia de baja resolución, lo que potencialmente las hace utilizables para fines legales como investigaciones de escenas de crímenes.
Sin embargo, existe el riesgo de identificación errónea, y lo ideal es que los sistemas de reconocimiento facial no requieran imágenes de alta resolución para realizar identificaciones precisas. Tales transformaciones son costosas y plantean preguntas sobre su validez y legalidad.
La Necesidad de Más Celebridades 'Desgastadas'
Sería más beneficioso si los sistemas de reconocimiento facial pudieran extraer características directamente de la salida de los sistemas heredados sin necesidad de transformar las imágenes. Esto requiere una mejor comprensión de la relación entre las identidades de alta resolución y las imágenes degradadas de los sistemas de vigilancia existentes.
El problema radica en los estándares: conjuntos de datos como MS-Celeb-1M y WebFace260M son ampliamente utilizados porque proporcionan puntos de referencia consistentes. Sin embargo, los autores argumentan que los algoritmos de reconocimiento facial entrenados con estos conjuntos de datos no son adecuados para los dominios visuales de los sistemas de vigilancia más antiguos.
 *Ejemplos del popular conjunto de datos MS-Celeb1m de Microsoft.* Fuente: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*Ejemplos del popular conjunto de datos MS-Celeb1m de Microsoft.* Fuente: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
El artículo destaca que los modelos de reconocimiento facial de última generación tienen dificultades con las imágenes de vigilancia del mundo real debido a problemas de cambio de dominio. Estos modelos están entrenados con conjuntos de datos semi-restringidos que carecen de las variaciones encontradas en escenarios del mundo real, como el ruido del sensor y el desenfoque por movimiento.
Los métodos anteriores han intentado igualar las salidas de los sistemas de vigilancia históricos o de bajo costo, pero estas eran aumentaciones 'ciegas'. En contraste, CFSM utiliza retroalimentación directa del sistema objetivo durante el entrenamiento y se adapta mediante transferencia de estilo para imitar ese dominio.
 *La actriz Natalie Portman, no extraña a los pocos conjuntos de datos que dominan la comunidad de visión por computadora, aparece entre las identidades en este ejemplo de CFSM realizando una adaptación de dominio basada en el estilo con retroalimentación del dominio del modelo objetivo real.*
*La actriz Natalie Portman, no extraña a los pocos conjuntos de datos que dominan la comunidad de visión por computadora, aparece entre las identidades en este ejemplo de CFSM realizando una adaptación de dominio basada en el estilo con retroalimentación del dominio del modelo objetivo real.*
La arquitectura de los autores utiliza el Método del Signo del Gradiente Rápido (FGSM) para importar estilos y características de la salida del sistema objetivo. A medida que avanza el entrenamiento, la parte de generación de imágenes del proceso se vuelve más fiel al sistema objetivo, mejorando el rendimiento y las capacidades de generalización del reconocimiento facial.
Pruebas y Resultados
Los investigadores probaron CFSM utilizando trabajos previos de MSU como plantilla, empleando MS-Celeb-1m y MS1M-V2 como conjuntos de datos de entrenamiento. Los datos objetivo fueron el conjunto de datos WiderFace de la Universidad China de Hong Kong, diseñado para la detección de rostros en situaciones desafiantes.
El sistema fue evaluado contra cuatro puntos de referencia de reconocimiento facial: IJB-B, IJB-C, IJB-S y TinyFace. CFSM fue entrenado con aproximadamente el 10% de los datos de MS-Celeb-1m, alrededor de 0.4 millones de imágenes, durante 125,000 iteraciones con un tamaño de lote de 32 utilizando el optimizador Adam con una tasa de aprendizaje de 1e-4.
El modelo de reconocimiento facial objetivo utilizó una ResNet-50 modificada con la función de pérdida ArcFace. Un modelo adicional fue entrenado con CFSM para comparación, etiquetado como 'ArcFace' en los resultados.
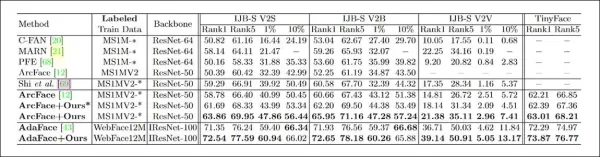 *Resultados de las pruebas principales para CFSM. Números más altos son mejores.*
*Resultados de las pruebas principales para CFSM. Números más altos son mejores.*
Los resultados mostraron que el modelo ArcFace, mejorado por CFSM, superó a todos los puntos de referencia en las tareas de identificación y verificación facial, logrando un nuevo rendimiento de vanguardia.
La capacidad de extraer dominios de diversas características de los sistemas de vigilancia heredados también permite comparar y evaluar la similitud de distribución entre estos sistemas, presentando cada uno en términos de un estilo visual que puede aprovecharse en trabajos futuros.
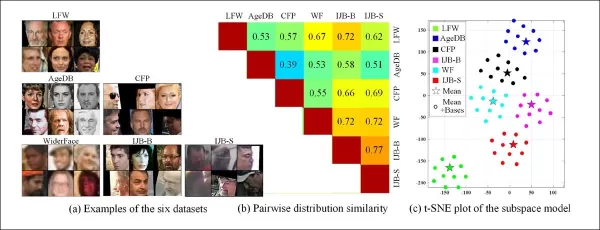 *Ejemplos de varios conjuntos de datos muestran claras diferencias en estilo.*
*Ejemplos de varios conjuntos de datos muestran claras diferencias en estilo.*
Los autores también señalaron que CFSM demuestra cómo la manipulación adversaria puede usarse para aumentar las precisiones de reconocimiento en tareas de visión. Introdujeron una métrica de similitud de conjuntos de datos basada en bases de estilo aprendidas, capturando diferencias de estilo de manera agnóstica a etiquetas o predictores.
La investigación subraya el potencial de los modelos de síntesis de rostros controlables y guiados para el reconocimiento facial sin restricciones y proporciona conocimientos sobre las diferencias entre conjuntos de datos.
Artículo relacionado
 La IA basada en la optimización surge como una nueva vía hacia los modelos de uso general
Investigadores de la Universidad de Illinois Urbana-Champaign y la Universidad de Virginia han creado una nueva arquitectura de modelo que podría allanar el camino para sistemas de IA más resilientes
El auge de la IA recuerda las preocupaciones sobre la burbuja de la era puntocom
La afluencia de inversiones multimillonarias en IA ha alimentado un acalorado debate: ¿se encamina la industria hacia una burbuja similar a la de las puntocom?Los inversores están atentos a cualquier
La memoria procedimental reduce los costes y la complejidad de los agentes de IA
Una nueva técnica desarrollada por la Universidad de Zhejiang y Alibaba Group dota a los agentes de grandes modelos lingüísticos (LLM) de memoria dinámica, lo que aumenta su eficiencia y eficacia a la
Recomendaciones de temas especiales relacionados
Salud y bienestar
La IA basada en la optimización surge como una nueva vía hacia los modelos de uso general
Investigadores de la Universidad de Illinois Urbana-Champaign y la Universidad de Virginia han creado una nueva arquitectura de modelo que podría allanar el camino para sistemas de IA más resilientes
El auge de la IA recuerda las preocupaciones sobre la burbuja de la era puntocom
La afluencia de inversiones multimillonarias en IA ha alimentado un acalorado debate: ¿se encamina la industria hacia una burbuja similar a la de las puntocom?Los inversores están atentos a cualquier
La memoria procedimental reduce los costes y la complejidad de los agentes de IA
Una nueva técnica desarrollada por la Universidad de Zhejiang y Alibaba Group dota a los agentes de grandes modelos lingüísticos (LLM) de memoria dinámica, lo que aumenta su eficiencia y eficacia a la
Recomendaciones de temas especiales relacionados
Salud y bienestar
 Asistentes de IA para el embarazo: genera planes seguros de entrenamiento y nutrición trimestre a trimestre
Asistentes de IA para el embarazo: genera planes seguros de entrenamiento y nutrición trimestre a trimestre
Descubre los mejores asistentes de IA para el embarazo de 2026, que te ofrecen planes de entrenamiento y nutrición seguros y personalizados trimestre a trimestre. Obtén recomendaciones cuidadosamente seleccionadas y con las mejores valoraciones, con comparativas entre opciones gratuitas y de pago, y opiniones reales. Disfruta de un embarazo más saludable con la guía de expertos de XIX.AI. Explora ahora.
 10 herramientas
10 herramientas
 xix.ai
escribiendo
Los mejores generadores de texto gratuitos e indetectables por la IA: convierte borradores robóticos en prosa natural y de estilo humano
xix.ai
escribiendo
Los mejores generadores de texto gratuitos e indetectables por la IA: convierte borradores robóticos en prosa natural y de estilo humano
Descubre los mejores generadores de texto con IA indetectables y gratuitos de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a transformar borradores robóticos en prosa natural y de estilo humano. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo las ventajas de la escritura con IA.
10 herramientas
xix.ai
Edición de imágenes
Generadores de arte por IA para guiones de cortometrajes: Personajes de fantasía y romance urbano
2026 Últimas novedades: Descubra los mejores generadores de arte por IA para guiones de historias cortas. Nuestra lista seleccionada incluye las herramientas más valoradas para crear personajes fascinantes de fantasía y romance urbano. Compare opciones gratuitas y pagas, vea resultados de pruebas reales y encuentre el compañero creativo perfecto para usted. Reciba clasificaciones actualizadas semanalmente y opiniones de expertos de XIX.AI. ¡Comience a visualizar su historia hoy mismo!
10 herramientas
xix.ai
escribiendo
Los mejores herramientas de scripting AI para la radio y los podcasts: Crea anuncios de audio atractivos.
Descubra los mejores herramientas de scripting de IA para la radio y los podcasts en 2026 en XIX.AI. Nuestra lista seleccionada y altamente valorada incluye soluciones poderosas que cambiarán completamente la forma en que crea anuncios de audio atractivos. Compare opciones gratuitas y pagadas mediante pruebas reales y clasificaciones actualizadas semanalmente. ¡Despliegue todo su potencial creativo hoy mismo!
10 herramientas
xix.ai
Negocio
El mejor software de revisión de contratos con IA: detecta al instante las lagunas legales y los riesgos de cumplimiento normativo
Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
10 herramientas
xix.ai
Creación de animación
Generador de anime AI para Donghua: Crea personajes para novelas web y avatares para cómics
Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai

 comentario (13)
0/500
comentario (13)
0/500
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
Investigadores de la Universidad Estatal de Michigan han ideado una forma innovadora de usar rostros sintéticos para una causa noble: mejorar la precisión de los sistemas de reconocimiento de imágenes. En lugar de contribuir al fenómeno de los deepfakes, estos rostros sintéticos están diseñados para imitar las imperfecciones que se encuentran en las grabaciones de videovigilancia del mundo real.
El equipo ha desarrollado un Módulo de Síntesis de Rostros Controlable (CFSM) que puede regenerar rostros en un estilo que refleja los defectos típicos de los sistemas de CCTV, como desenfoque facial, baja resolución y ruido del sensor. Este enfoque difiere del uso de imágenes de celebridades de alta calidad de conjuntos de datos populares, que no capturan los desafíos del mundo real que enfrentan los sistemas de reconocimiento facial.
*Arquitectura conceptual para el Módulo de Síntesis de Rostros Controlable (CFSM).* Fuente: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
A diferencia de los sistemas de deepfake que se centran en replicar poses de cabeza y expresiones, CFSM busca generar vistas alternativas que coincidan con el estilo del sistema de reconocimiento objetivo a través de la transferencia de estilo. Este módulo es particularmente útil para adaptarse a sistemas heredados que probablemente no se actualizarán debido a restricciones de costos, pero que aún necesitan contribuir a las tecnologías modernas de reconocimiento facial.
Al probar CFSM, los investigadores observaron mejoras significativas en los sistemas de reconocimiento de imágenes que manejan datos de baja calidad. También descubrieron un beneficio inesperado: la capacidad de caracterizar y comparar conjuntos de datos objetivo, lo que simplifica el proceso de evaluación comparativa y la creación de conjuntos de datos personalizados para diversos sistemas de CCTV.
*Entrenamiento de los modelos de reconocimiento facial para adaptarse a las limitaciones de los sistemas objetivo.* Fuente: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
El método también se puede aplicar a conjuntos de datos existentes, realizando efectivamente una adaptación de dominio para hacerlos más adecuados para el reconocimiento facial. La investigación, titulada **Síntesis de Rostros Controlable y Guiada para el Reconocimiento Facial sin Restricciones**, cuenta con el apoyo parcial de la Oficina del Director de Inteligencia Nacional de EE. UU. (ODNI, en IARPA) e involucra a cuatro investigadores del departamento de Ciencias de la Computación e Ingeniería de MSU.
Reconocimiento Facial de Baja Calidad: Un Campo en Crecimiento
En los últimos años, el reconocimiento facial de baja calidad (LQFR) ha surgido como un área de estudio significativa. Muchos sistemas de videovigilancia más antiguos, diseñados para ser duraderos y de larga duración, han quedado obsoletos y luchan por servir como fuentes de datos efectivas para el aprendizaje automático debido a la deuda técnica.
Niveles variables de resolución facial en una gama de sistemas de videovigilancia históricos y más recientes. Fuente: https://arxiv.org/pdf/1805.11519.pdf
Afortunadamente, los modelos de difusión y otros modelos basados en ruido están bien adaptados para abordar este problema. Muchos de los últimos sistemas de síntesis de imágenes incluyen la mejora de imágenes de baja resolución como parte de su proceso, lo cual también es crucial para las técnicas de compresión neuronal.
El desafío en el reconocimiento facial es maximizar la precisión con la menor cantidad posible de características extraídas de imágenes de baja resolución. Esto no solo es útil para identificar rostros en baja resolución, sino que también es necesario debido a las limitaciones en el tamaño de la imagen en el espacio latente de los modelos de entrenamiento.
En visión por computadora, las 'características' se refieren a las características distintivas de cualquier imagen, no solo rostros. Con los avances en algoritmos de mejora de resolución, se han propuesto varios métodos para mejorar las grabaciones de vigilancia de baja resolución, lo que potencialmente las hace utilizables para fines legales como investigaciones de escenas de crímenes.
Sin embargo, existe el riesgo de identificación errónea, y lo ideal es que los sistemas de reconocimiento facial no requieran imágenes de alta resolución para realizar identificaciones precisas. Tales transformaciones son costosas y plantean preguntas sobre su validez y legalidad.
La Necesidad de Más Celebridades 'Desgastadas'
Sería más beneficioso si los sistemas de reconocimiento facial pudieran extraer características directamente de la salida de los sistemas heredados sin necesidad de transformar las imágenes. Esto requiere una mejor comprensión de la relación entre las identidades de alta resolución y las imágenes degradadas de los sistemas de vigilancia existentes.
El problema radica en los estándares: conjuntos de datos como MS-Celeb-1M y WebFace260M son ampliamente utilizados porque proporcionan puntos de referencia consistentes. Sin embargo, los autores argumentan que los algoritmos de reconocimiento facial entrenados con estos conjuntos de datos no son adecuados para los dominios visuales de los sistemas de vigilancia más antiguos.
*Ejemplos del popular conjunto de datos MS-Celeb1m de Microsoft.* Fuente: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
El artículo destaca que los modelos de reconocimiento facial de última generación tienen dificultades con las imágenes de vigilancia del mundo real debido a problemas de cambio de dominio. Estos modelos están entrenados con conjuntos de datos semi-restringidos que carecen de las variaciones encontradas en escenarios del mundo real, como el ruido del sensor y el desenfoque por movimiento.
Los métodos anteriores han intentado igualar las salidas de los sistemas de vigilancia históricos o de bajo costo, pero estas eran aumentaciones 'ciegas'. En contraste, CFSM utiliza retroalimentación directa del sistema objetivo durante el entrenamiento y se adapta mediante transferencia de estilo para imitar ese dominio.
*La actriz Natalie Portman, no extraña a los pocos conjuntos de datos que dominan la comunidad de visión por computadora, aparece entre las identidades en este ejemplo de CFSM realizando una adaptación de dominio basada en el estilo con retroalimentación del dominio del modelo objetivo real.*
La arquitectura de los autores utiliza el Método del Signo del Gradiente Rápido (FGSM) para importar estilos y características de la salida del sistema objetivo. A medida que avanza el entrenamiento, la parte de generación de imágenes del proceso se vuelve más fiel al sistema objetivo, mejorando el rendimiento y las capacidades de generalización del reconocimiento facial.
Pruebas y Resultados
Los investigadores probaron CFSM utilizando trabajos previos de MSU como plantilla, empleando MS-Celeb-1m y MS1M-V2 como conjuntos de datos de entrenamiento. Los datos objetivo fueron el conjunto de datos WiderFace de la Universidad China de Hong Kong, diseñado para la detección de rostros en situaciones desafiantes.
El sistema fue evaluado contra cuatro puntos de referencia de reconocimiento facial: IJB-B, IJB-C, IJB-S y TinyFace. CFSM fue entrenado con aproximadamente el 10% de los datos de MS-Celeb-1m, alrededor de 0.4 millones de imágenes, durante 125,000 iteraciones con un tamaño de lote de 32 utilizando el optimizador Adam con una tasa de aprendizaje de 1e-4.
El modelo de reconocimiento facial objetivo utilizó una ResNet-50 modificada con la función de pérdida ArcFace. Un modelo adicional fue entrenado con CFSM para comparación, etiquetado como 'ArcFace' en los resultados.
*Resultados de las pruebas principales para CFSM. Números más altos son mejores.*
Los resultados mostraron que el modelo ArcFace, mejorado por CFSM, superó a todos los puntos de referencia en las tareas de identificación y verificación facial, logrando un nuevo rendimiento de vanguardia.
La capacidad de extraer dominios de diversas características de los sistemas de vigilancia heredados también permite comparar y evaluar la similitud de distribución entre estos sistemas, presentando cada uno en términos de un estilo visual que puede aprovecharse en trabajos futuros.
*Ejemplos de varios conjuntos de datos muestran claras diferencias en estilo.*
Los autores también señalaron que CFSM demuestra cómo la manipulación adversaria puede usarse para aumentar las precisiones de reconocimiento en tareas de visión. Introdujeron una métrica de similitud de conjuntos de datos basada en bases de estilo aprendidas, capturando diferencias de estilo de manera agnóstica a etiquetas o predictores.
La investigación subraya el potencial de los modelos de síntesis de rostros controlables y guiados para el reconocimiento facial sin restricciones y proporciona conocimientos sobre las diferencias entre conjuntos de datos.










 La IA basada en la optimización surge como una nueva vía hacia los modelos de uso general
Investigadores de la Universidad de Illinois Urbana-Champaign y la Universidad de Virginia han creado una nueva arquitectura de modelo que podría allanar el camino para sistemas de IA más resilientes
La IA basada en la optimización surge como una nueva vía hacia los modelos de uso general
Investigadores de la Universidad de Illinois Urbana-Champaign y la Universidad de Virginia han creado una nueva arquitectura de modelo que podría allanar el camino para sistemas de IA más resilientes
 El auge de la IA recuerda las preocupaciones sobre la burbuja de la era puntocom
La afluencia de inversiones multimillonarias en IA ha alimentado un acalorado debate: ¿se encamina la industria hacia una burbuja similar a la de las puntocom?Los inversores están atentos a cualquier
El auge de la IA recuerda las preocupaciones sobre la burbuja de la era puntocom
La afluencia de inversiones multimillonarias en IA ha alimentado un acalorado debate: ¿se encamina la industria hacia una burbuja similar a la de las puntocom?Los inversores están atentos a cualquier
 La memoria procedimental reduce los costes y la complejidad de los agentes de IA
Una nueva técnica desarrollada por la Universidad de Zhejiang y Alibaba Group dota a los agentes de grandes modelos lingüísticos (LLM) de memoria dinámica, lo que aumenta su eficiencia y eficacia a la
La memoria procedimental reduce los costes y la complejidad de los agentes de IA
Una nueva técnica desarrollada por la Universidad de Zhejiang y Alibaba Group dota a los agentes de grandes modelos lingüísticos (LLM) de memoria dinámica, lo que aumenta su eficiencia y eficacia a la

Descubre los mejores asistentes de IA para el embarazo de 2026, que te ofrecen planes de entrenamiento y nutrición seguros y personalizados trimestre a trimestre. Obtén recomendaciones cuidadosamente seleccionadas y con las mejores valoraciones, con comparativas entre opciones gratuitas y de pago, y opiniones reales. Disfruta de un embarazo más saludable con la guía de expertos de XIX.AI. Explora ahora.
10 herramientas
xix.ai

Descubre los mejores generadores de texto con IA indetectables y gratuitos de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, te ayuda a transformar borradores robóticos en prosa natural y de estilo humano. Compara las opciones gratuitas con las de pago mediante pruebas reales y clasificaciones que se actualizan semanalmente. Aprovecha hoy mismo las ventajas de la escritura con IA.
10 herramientas
xix.ai

2026 Últimas novedades: Descubra los mejores generadores de arte por IA para guiones de historias cortas. Nuestra lista seleccionada incluye las herramientas más valoradas para crear personajes fascinantes de fantasía y romance urbano. Compare opciones gratuitas y pagas, vea resultados de pruebas reales y encuentre el compañero creativo perfecto para usted. Reciba clasificaciones actualizadas semanalmente y opiniones de expertos de XIX.AI. ¡Comience a visualizar su historia hoy mismo!
10 herramientas
xix.ai

Descubra los mejores herramientas de scripting de IA para la radio y los podcasts en 2026 en XIX.AI. Nuestra lista seleccionada y altamente valorada incluye soluciones poderosas que cambiarán completamente la forma en que crea anuncios de audio atractivos. Compare opciones gratuitas y pagadas mediante pruebas reales y clasificaciones actualizadas semanalmente. ¡Despliegue todo su potencial creativo hoy mismo!
10 herramientas
xix.ai

Descubre el mejor software de revisión de contratos con IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas que detectan al instante las lagunas legales y los riesgos de cumplimiento normativo. Compara las opciones gratuitas con las de pago gracias a pruebas en condiciones reales y a clasificaciones que se actualizan semanalmente. Encuentra la solución revolucionaria que necesitas para un análisis de contratos seguro y eficiente. Explora ahora la guía definitiva.
10 herramientas
xix.ai

Descubra los mejores generadores de anime de IA para donghua en 2026. Nuestra lista seleccionada y calificada incluye herramientas poderosas para crear increíbles personajes para novelas web y avatares de cómics. Compare opciones gratuitas y pagadas a través de pruebas reales. Encuentre su compañero creativo ideal y dé vida a sus historias hoy mismo en XIX.AI.
10 herramientas
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













