
















 Heim
Heim
'Erniedrigte' synthetische Gesichter können die Gesichtserkennungstechnologie verbessern
Forscher an der Michigan State University haben einen innovativen Ansatz entwickelt, um synthetische Gesichter für einen edlen Zweck zu nutzen – die Verbesserung der Genauigkeit von Bilderkennungssystemen. Anstatt zum Phänomen der Deepfakes beizutragen, sind diese synthetischen Gesichter darauf ausgelegt, die Unvollkommenheiten nachzuahmen, die in realen Videoüberwachungsaufnahmen vorkommen.
Das Team hat ein Kontrollierbares Gesichtssynthese-Modul (CFSM) entwickelt, das Gesichter in einem Stil regenerieren kann, der die typischen Mängel von CCTV-Systemen widerspiegelt, wie Gesichtsunschärfe, niedrige Auflösung und Sensorauschen. Dieser Ansatz unterscheidet sich von der Verwendung hochqualitativer Prominentenbilder aus populären Datensätzen, die die realen Herausforderungen von Gesichtserkennungssystemen nicht abbilden.
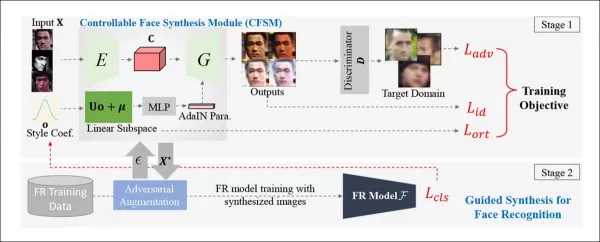 *Konzeptionelle Architektur für das Kontrollierbare Gesichtssynthese-Modul (CFSM).* Quelle: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*Konzeptionelle Architektur für das Kontrollierbare Gesichtssynthese-Modul (CFSM).* Quelle: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Im Gegensatz zu Deepfake-Systemen, die sich auf die Nachbildung von Kopfhaltungen und Ausdrücken konzentrieren, zielt CFSM darauf ab, alternative Ansichten zu generieren, die dem Stil des Zielerkennungssystems durch Stilübertragung entsprechen. Dieses Modul ist besonders nützlich, um sich an ältere Systeme anzupassen, die aufgrund von Kostenbeschränkungen wahrscheinlich nicht aufgerüstet werden, aber dennoch zu modernen Gesichtserkennungstechnologien beitragen müssen.
Bei der Erprobung von CFSM stellten die Forscher signifikante Verbesserungen bei Bilderkennungssystemen fest, die mit Daten niedriger Qualität arbeiten. Sie entdeckten auch einen unerwarteten Vorteil: die Fähigkeit, Zieldatensätze zu charakterisieren und zu vergleichen, was den Prozess der Leistungsbewertung und Erstellung maßgeschneiderter Datensätze für verschiedene CCTV-Systeme vereinfacht.
 *Training der Gesichtserkennungsmodelle, um sich an die Einschränkungen der Zielsysteme anzupassen.* Quelle: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*Training der Gesichtserkennungsmodelle, um sich an die Einschränkungen der Zielsysteme anzupassen.* Quelle: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
Die Methode kann auch auf bestehende Datensätze angewendet werden, um eine effektive Domänenanpassung durchzuführen und sie für die Gesichtserkennung geeigneter zu machen. Die Forschung, betitelt **Kontrollierte und geführte Gesichtssynthese für uneingeschränkte Gesichtserkennung**, wird teilweise vom US Office of the Director of National Intelligence (ODNI, bei IARPA) unterstützt und umfasst vier Forscher aus der Abteilung für Informatik und Ingenieurwissenschaften der MSU.
Gesichtserkennung bei niedriger Qualität: Ein wachsendes Forschungsfeld
In den letzten Jahren hat die Gesichtserkennung bei niedriger Qualität (LQFR) als bedeutendes Studiengebiet an Bedeutung gewonnen. Viele ältere Videoüberwachungssysteme, die auf Langlebigkeit ausgelegt sind, sind veraltet und können aufgrund technischer Schulden nur schwer als effektive Datenquellen für maschinelles Lernen dienen.
 Unterschiedliche Stufen der Gesichtsauflösung bei einer Reihe historischer und neuerer Videoüberwachungssysteme. Quelle: https://arxiv.org/pdf/1805.11519.pdf
Unterschiedliche Stufen der Gesichtsauflösung bei einer Reihe historischer und neuerer Videoüberwachungssysteme. Quelle: https://arxiv.org/pdf/1805.11519.pdf
Glücklicherweise sind Diffusionsmodelle und andere rausbasierte Modelle gut geeignet, dieses Problem anzugehen. Viele der neuesten Bildsynthesesysteme beinhalten das Hochskalieren von Bildern niedriger Auflösung als Teil ihres Prozesses, was auch für neuronale Kompressionstechniken entscheidend ist.
Die Herausforderung bei der Gesichtserkennung besteht darin, die Genauigkeit mit möglichst wenigen aus Bildern niedriger Auflösung extrahierten Merkmalen zu maximieren. Dies ist nicht nur nützlich für die Identifizierung von Gesichtern bei niedriger Auflösung, sondern auch notwendig aufgrund von Einschränkungen der Bildgröße im latenten Raum der Trainingsmodelle.
In der Computer Vision beziehen sich 'Merkmale' auf unterscheidende Charakteristika eines beliebigen Bildes, nicht nur von Gesichtern. Mit Fortschritten bei Hochskalierungsalgorithmen wurden verschiedene Methoden vorgeschlagen, um Videoüberwachungsaufnahmen niedriger Auflösung zu verbessern, was sie potenziell für rechtliche Zwecke wie Tatortuntersuchungen nutzbar macht.
Es besteht jedoch das Risiko einer Fehlidentifikation, und idealerweise sollten Gesichtserkennungssysteme keine hochauflösenden Bilder benötigen, um genaue Identifikationen durchzuführen. Solche Transformationen sind kostspielig und werfen Fragen nach ihrer Gültigkeit und Legalität auf.
Die Notwendigkeit für mehr 'heruntergekommene' Prominente
Es wäre vorteilhafter, wenn Gesichtserkennungssysteme Merkmale direkt aus der Ausgabe älterer Systeme extrahieren könnten, ohne die Bilder transformieren zu müssen. Dies erfordert ein besseres Verständnis der Beziehung zwischen hochauflösenden Identitäten und den degradierten Bildern bestehender Überwachungssysteme.
Das Problem liegt in den Standards: Datensätze wie MS-Celeb-1M und WebFace260M werden weitgehend verwendet, weil sie konsistente Benchmarks bieten. Die Autoren argumentieren jedoch, dass auf diesen Datensätzen trainierte Gesichtserkennungsalgorithmen nicht für die visuellen Domänen älterer Überwachungssysteme geeignet sind.
 *Beispiele aus Microsofts populärem MS-Celeb1m-Datensatz.* Quelle: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*Beispiele aus Microsofts populärem MS-Celeb1m-Datensatz.* Quelle: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
Das Papier hebt hervor, dass hochmoderne Gesichtserkennungsmodelle mit realen Überwachungsbildern aufgrund von Domänenverschiebungsproblemen Schwierigkeiten haben. Diese Modelle werden auf halb-eingeschränkten Datensätzen trainiert, die die in realen Szenarien vorkommenden Variationen wie Sensorauschen und Bewegungsunschärfe nicht abbilden.
Frühere Methoden haben versucht, die Ausgaben historischer oder kostengünstiger Überwachungssysteme anzugleichen, aber dies waren 'blinde' Erweiterungen. Im Gegensatz dazu nutzt CFSM direktes Feedback vom Zielsystem während des Trainings und passt sich durch Stilübertragung an diese Domäne an.
 *Schauspielerin Natalie Portman, keine Unbekannte in den wenigen Datensätzen, die die Computer-Vision-Community dominieren, gehört zu den Identitäten in diesem Beispiel von CFSM, das eine stilangepasste Domänenanpassung basierend auf Feedback aus der Domäne des tatsächlichen Zielmodells durchführt.*
*Schauspielerin Natalie Portman, keine Unbekannte in den wenigen Datensätzen, die die Computer-Vision-Community dominieren, gehört zu den Identitäten in diesem Beispiel von CFSM, das eine stilangepasste Domänenanpassung basierend auf Feedback aus der Domäne des tatsächlichen Zielmodells durchführt.*
Die Architektur der Autoren verwendet die Fast Gradient Sign Method (FGSM), um Stile und Charakteristika aus der Ausgabe des Zielsystems zu importieren. Mit fortschreitendem Training wird der Bildgenerierungsteil der Pipeline dem Zielsystem treuer, was die Leistung und Verallgemeinerungsfähigkeit der Gesichtserkennung verbessert.
Tests und Ergebnisse
Die Forscher testeten CFSM unter Verwendung früherer Arbeiten der MSU als Vorlage und nutzten MS-Celeb-1m und MS1M-V2 als Trainingsdatensätze. Die Zieldaten waren der WiderFace-Datensatz der Chinese University of Hong Kong, der für die Gesichtserkennung in anspruchsvollen Situationen entwickelt wurde.
Das System wurde anhand von vier Gesichtserkennungs-Benchmarks bewertet: IJB-B, IJB-C, IJB-S und TinyFace. CFSM wurde mit etwa 10% der MS-Celeb-1m-Daten, rund 0,4 Millionen Bildern, für 125.000 Iterationen bei einer Batchgröße von 32 mit dem Adam-Optimierer und einer Lernrate von 1e-4 trainiert.
Das Zielgesichtserkennungsmodell verwendete ein modifiziertes ResNet-50 mit ArcFace-Verlustfunktion. Ein zusätzliches Modell wurde mit CFSM trainiert, um einen Vergleich zu ermöglichen, in den Ergebnissen als 'ArcFace' bezeichnet.
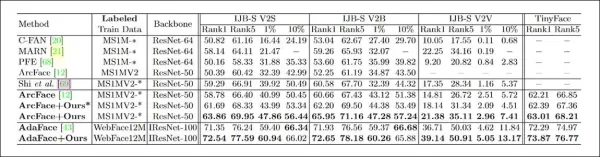 *Ergebnisse der Haupttests für CFSM. Höhere Zahlen sind besser.*
*Ergebnisse der Haupttests für CFSM. Höhere Zahlen sind besser.*
Die Ergebnisse zeigten, dass das durch CFSM verbesserte ArcFace-Modell alle Basislinien sowohl bei der Gesichtsidentifikation als auch bei der Verifikation übertraf und eine neue Spitzenleistung erreichte.
Die Fähigkeit, Domänen aus verschiedenen Charakteristika älterer Überwachungssysteme zu extrahieren, ermöglicht auch den Vergleich und die Bewertung der Verteilungsgleichheit zwischen diesen Systemen und stellt sie jeweils in Form eines visuellen Stils dar, der in zukünftigen Arbeiten genutzt werden kann.
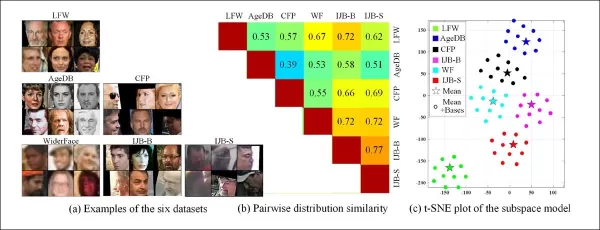 *Beispiele aus verschiedenen Datensätzen zeigen klare Stilunterschiede.*
*Beispiele aus verschiedenen Datensätzen zeigen klare Stilunterschiede.*
Die Autoren stellten auch fest, dass CFSM zeigt, wie adversariale Manipulation genutzt werden kann, um die Erkennungsgenauigkeit bei visuellen Aufgaben zu erhöhen. Sie führten eine Datensatzähnlichkeitsmetrik basierend auf gelernten Stilbasen ein, die Stilunterschiede auf eine label- oder prädiktorunabhängige Weise erfasst.
Die Forschung unterstreicht das Potenzial kontrollierter und geführter Gesichtssynthesemodelle für uneingeschränkte Gesichtserkennung und liefert Einblicke in Datensatzunterschiede.
Verwandter Artikel
 Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
Der KI-Boom weckt Erinnerungen an die Dotcom-Blase
Der Zufluss von Investitionen in Höhe von mehreren Milliarden Dollar in KI hat eine hitzige Debatte ausgelöst: Steuert die Branche auf eine Blase im Stil der Dotcom-Ära zu?Investoren beobachten aufmer
Prozedurales Gedächtnis senkt Kosten und Komplexität von KI-Agenten
Eine neue Technik, die von der Universität Zhejiang und der Alibaba Group entwickelt wurde, stattet Agenten für große Sprachmodelle (Large Language Model, LLM) mit einem dynamischen Gedächtnis aus und
Empfehlungen zu verwandten Spezialthemen
Bildbearbeitung
Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
Der KI-Boom weckt Erinnerungen an die Dotcom-Blase
Der Zufluss von Investitionen in Höhe von mehreren Milliarden Dollar in KI hat eine hitzige Debatte ausgelöst: Steuert die Branche auf eine Blase im Stil der Dotcom-Ära zu?Investoren beobachten aufmer
Prozedurales Gedächtnis senkt Kosten und Komplexität von KI-Agenten
Eine neue Technik, die von der Universität Zhejiang und der Alibaba Group entwickelt wurde, stattet Agenten für große Sprachmodelle (Large Language Model, LLM) mit einem dynamischen Gedächtnis aus und
Empfehlungen zu verwandten Spezialthemen
Bildbearbeitung
 KI-gestützte Kunstgeneratoren für Kurzdramen-Storyboarding: Charaktere aus Fantasy- und Stadtliebesgeschichten
KI-gestützte Kunstgeneratoren für Kurzdramen-Storyboarding: Charaktere aus Fantasy- und Stadtliebesgeschichten
2026 Neuestes: Entdecken Sie die besten KI-Kunstgeneratoren für Storyboards zu Kurzgeschichten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete Tools zur Erstellung fesselnder Charaktere in Fantasy- und Urban-Romance-Geschichten. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich tatsächliche Testergebnisse an und finden Sie den perfekten kreativen Partner für Ihre Projekte. Erhalten Sie wöchentlich aktualisierte Rankings sowie Expertenmeinungen von XIX.AI. Beginnen Sie noch heute, Ihre Geschichten visuell zu gestalten!
 10 Tools
10 Tools
 xix.ai
Schreiben
Die besten AI-Skripting-Tools für Radio und Podcasting: Erstellen Sie ansprechende Audowerbung.
xix.ai
Schreiben
Die besten AI-Skripting-Tools für Radio und Podcasting: Erstellen Sie ansprechende Audowerbung.
Entdecken Sie die besten KI-Skripting-Tools für Radio und Podcasting im Jahr 2026 bei XIX.AI. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, mit denen Sie ansprechende Audio-Werbespots schnell erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie noch heute Ihr kreatives Potenzial!
10 Tools
xix.ai
Geschäft
Die beste KI-Software zur Vertragsprüfung: Erkennen Sie rechtliche Lücken und Compliance-Risiken sofort
Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
10 Tools
xix.ai
Animationserstellung
AI-Anime-Generator für Donghua: Erstellen Sie Charaktere für Web-Romane und Comic-Avatare
Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai
Comic-Erstellung
Die besten KI-Tools zur automatischen Kolorierung von Manga: Flache Farben ohne Konsistenzfehler anwenden
Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai
Schreiben
Die besten KI-Profilersteller: Erstellen Sie konsistente Charaktermotivationen und fatale Schwächen
Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

 Kommentare (13)
Kommentare (13)
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
Forscher an der Michigan State University haben einen innovativen Ansatz entwickelt, um synthetische Gesichter für einen edlen Zweck zu nutzen – die Verbesserung der Genauigkeit von Bilderkennungssystemen. Anstatt zum Phänomen der Deepfakes beizutragen, sind diese synthetischen Gesichter darauf ausgelegt, die Unvollkommenheiten nachzuahmen, die in realen Videoüberwachungsaufnahmen vorkommen.
Das Team hat ein Kontrollierbares Gesichtssynthese-Modul (CFSM) entwickelt, das Gesichter in einem Stil regenerieren kann, der die typischen Mängel von CCTV-Systemen widerspiegelt, wie Gesichtsunschärfe, niedrige Auflösung und Sensorauschen. Dieser Ansatz unterscheidet sich von der Verwendung hochqualitativer Prominentenbilder aus populären Datensätzen, die die realen Herausforderungen von Gesichtserkennungssystemen nicht abbilden.
*Konzeptionelle Architektur für das Kontrollierbare Gesichtssynthese-Modul (CFSM).* Quelle: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Im Gegensatz zu Deepfake-Systemen, die sich auf die Nachbildung von Kopfhaltungen und Ausdrücken konzentrieren, zielt CFSM darauf ab, alternative Ansichten zu generieren, die dem Stil des Zielerkennungssystems durch Stilübertragung entsprechen. Dieses Modul ist besonders nützlich, um sich an ältere Systeme anzupassen, die aufgrund von Kostenbeschränkungen wahrscheinlich nicht aufgerüstet werden, aber dennoch zu modernen Gesichtserkennungstechnologien beitragen müssen.
Bei der Erprobung von CFSM stellten die Forscher signifikante Verbesserungen bei Bilderkennungssystemen fest, die mit Daten niedriger Qualität arbeiten. Sie entdeckten auch einen unerwarteten Vorteil: die Fähigkeit, Zieldatensätze zu charakterisieren und zu vergleichen, was den Prozess der Leistungsbewertung und Erstellung maßgeschneiderter Datensätze für verschiedene CCTV-Systeme vereinfacht.
*Training der Gesichtserkennungsmodelle, um sich an die Einschränkungen der Zielsysteme anzupassen.* Quelle: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
Die Methode kann auch auf bestehende Datensätze angewendet werden, um eine effektive Domänenanpassung durchzuführen und sie für die Gesichtserkennung geeigneter zu machen. Die Forschung, betitelt **Kontrollierte und geführte Gesichtssynthese für uneingeschränkte Gesichtserkennung**, wird teilweise vom US Office of the Director of National Intelligence (ODNI, bei IARPA) unterstützt und umfasst vier Forscher aus der Abteilung für Informatik und Ingenieurwissenschaften der MSU.
Gesichtserkennung bei niedriger Qualität: Ein wachsendes Forschungsfeld
In den letzten Jahren hat die Gesichtserkennung bei niedriger Qualität (LQFR) als bedeutendes Studiengebiet an Bedeutung gewonnen. Viele ältere Videoüberwachungssysteme, die auf Langlebigkeit ausgelegt sind, sind veraltet und können aufgrund technischer Schulden nur schwer als effektive Datenquellen für maschinelles Lernen dienen.
Unterschiedliche Stufen der Gesichtsauflösung bei einer Reihe historischer und neuerer Videoüberwachungssysteme. Quelle: https://arxiv.org/pdf/1805.11519.pdf
Glücklicherweise sind Diffusionsmodelle und andere rausbasierte Modelle gut geeignet, dieses Problem anzugehen. Viele der neuesten Bildsynthesesysteme beinhalten das Hochskalieren von Bildern niedriger Auflösung als Teil ihres Prozesses, was auch für neuronale Kompressionstechniken entscheidend ist.
Die Herausforderung bei der Gesichtserkennung besteht darin, die Genauigkeit mit möglichst wenigen aus Bildern niedriger Auflösung extrahierten Merkmalen zu maximieren. Dies ist nicht nur nützlich für die Identifizierung von Gesichtern bei niedriger Auflösung, sondern auch notwendig aufgrund von Einschränkungen der Bildgröße im latenten Raum der Trainingsmodelle.
In der Computer Vision beziehen sich 'Merkmale' auf unterscheidende Charakteristika eines beliebigen Bildes, nicht nur von Gesichtern. Mit Fortschritten bei Hochskalierungsalgorithmen wurden verschiedene Methoden vorgeschlagen, um Videoüberwachungsaufnahmen niedriger Auflösung zu verbessern, was sie potenziell für rechtliche Zwecke wie Tatortuntersuchungen nutzbar macht.
Es besteht jedoch das Risiko einer Fehlidentifikation, und idealerweise sollten Gesichtserkennungssysteme keine hochauflösenden Bilder benötigen, um genaue Identifikationen durchzuführen. Solche Transformationen sind kostspielig und werfen Fragen nach ihrer Gültigkeit und Legalität auf.
Die Notwendigkeit für mehr 'heruntergekommene' Prominente
Es wäre vorteilhafter, wenn Gesichtserkennungssysteme Merkmale direkt aus der Ausgabe älterer Systeme extrahieren könnten, ohne die Bilder transformieren zu müssen. Dies erfordert ein besseres Verständnis der Beziehung zwischen hochauflösenden Identitäten und den degradierten Bildern bestehender Überwachungssysteme.
Das Problem liegt in den Standards: Datensätze wie MS-Celeb-1M und WebFace260M werden weitgehend verwendet, weil sie konsistente Benchmarks bieten. Die Autoren argumentieren jedoch, dass auf diesen Datensätzen trainierte Gesichtserkennungsalgorithmen nicht für die visuellen Domänen älterer Überwachungssysteme geeignet sind.
*Beispiele aus Microsofts populärem MS-Celeb1m-Datensatz.* Quelle: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
Das Papier hebt hervor, dass hochmoderne Gesichtserkennungsmodelle mit realen Überwachungsbildern aufgrund von Domänenverschiebungsproblemen Schwierigkeiten haben. Diese Modelle werden auf halb-eingeschränkten Datensätzen trainiert, die die in realen Szenarien vorkommenden Variationen wie Sensorauschen und Bewegungsunschärfe nicht abbilden.
Frühere Methoden haben versucht, die Ausgaben historischer oder kostengünstiger Überwachungssysteme anzugleichen, aber dies waren 'blinde' Erweiterungen. Im Gegensatz dazu nutzt CFSM direktes Feedback vom Zielsystem während des Trainings und passt sich durch Stilübertragung an diese Domäne an.
*Schauspielerin Natalie Portman, keine Unbekannte in den wenigen Datensätzen, die die Computer-Vision-Community dominieren, gehört zu den Identitäten in diesem Beispiel von CFSM, das eine stilangepasste Domänenanpassung basierend auf Feedback aus der Domäne des tatsächlichen Zielmodells durchführt.*
Die Architektur der Autoren verwendet die Fast Gradient Sign Method (FGSM), um Stile und Charakteristika aus der Ausgabe des Zielsystems zu importieren. Mit fortschreitendem Training wird der Bildgenerierungsteil der Pipeline dem Zielsystem treuer, was die Leistung und Verallgemeinerungsfähigkeit der Gesichtserkennung verbessert.
Tests und Ergebnisse
Die Forscher testeten CFSM unter Verwendung früherer Arbeiten der MSU als Vorlage und nutzten MS-Celeb-1m und MS1M-V2 als Trainingsdatensätze. Die Zieldaten waren der WiderFace-Datensatz der Chinese University of Hong Kong, der für die Gesichtserkennung in anspruchsvollen Situationen entwickelt wurde.
Das System wurde anhand von vier Gesichtserkennungs-Benchmarks bewertet: IJB-B, IJB-C, IJB-S und TinyFace. CFSM wurde mit etwa 10% der MS-Celeb-1m-Daten, rund 0,4 Millionen Bildern, für 125.000 Iterationen bei einer Batchgröße von 32 mit dem Adam-Optimierer und einer Lernrate von 1e-4 trainiert.
Das Zielgesichtserkennungsmodell verwendete ein modifiziertes ResNet-50 mit ArcFace-Verlustfunktion. Ein zusätzliches Modell wurde mit CFSM trainiert, um einen Vergleich zu ermöglichen, in den Ergebnissen als 'ArcFace' bezeichnet.
*Ergebnisse der Haupttests für CFSM. Höhere Zahlen sind besser.*
Die Ergebnisse zeigten, dass das durch CFSM verbesserte ArcFace-Modell alle Basislinien sowohl bei der Gesichtsidentifikation als auch bei der Verifikation übertraf und eine neue Spitzenleistung erreichte.
Die Fähigkeit, Domänen aus verschiedenen Charakteristika älterer Überwachungssysteme zu extrahieren, ermöglicht auch den Vergleich und die Bewertung der Verteilungsgleichheit zwischen diesen Systemen und stellt sie jeweils in Form eines visuellen Stils dar, der in zukünftigen Arbeiten genutzt werden kann.
*Beispiele aus verschiedenen Datensätzen zeigen klare Stilunterschiede.*
Die Autoren stellten auch fest, dass CFSM zeigt, wie adversariale Manipulation genutzt werden kann, um die Erkennungsgenauigkeit bei visuellen Aufgaben zu erhöhen. Sie führten eine Datensatzähnlichkeitsmetrik basierend auf gelernten Stilbasen ein, die Stilunterschiede auf eine label- oder prädiktorunabhängige Weise erfasst.
Die Forschung unterstreicht das Potenzial kontrollierter und geführter Gesichtssynthesemodelle für uneingeschränkte Gesichtserkennung und liefert Einblicke in Datensatzunterschiede.










 Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
Optimierungsorientierte KI als neuer Weg zu Allzweckmodellen
Forscher der University of Illinois Urbana-Champaign und der University of Virginia haben eine neue Modellarchitektur entwickelt, die den Weg für widerstandsfähigere KI-Systeme mit verbesserter Schlus
 Der KI-Boom weckt Erinnerungen an die Dotcom-Blase
Der Zufluss von Investitionen in Höhe von mehreren Milliarden Dollar in KI hat eine hitzige Debatte ausgelöst: Steuert die Branche auf eine Blase im Stil der Dotcom-Ära zu?Investoren beobachten aufmer
Der KI-Boom weckt Erinnerungen an die Dotcom-Blase
Der Zufluss von Investitionen in Höhe von mehreren Milliarden Dollar in KI hat eine hitzige Debatte ausgelöst: Steuert die Branche auf eine Blase im Stil der Dotcom-Ära zu?Investoren beobachten aufmer
 Prozedurales Gedächtnis senkt Kosten und Komplexität von KI-Agenten
Eine neue Technik, die von der Universität Zhejiang und der Alibaba Group entwickelt wurde, stattet Agenten für große Sprachmodelle (Large Language Model, LLM) mit einem dynamischen Gedächtnis aus und
Prozedurales Gedächtnis senkt Kosten und Komplexität von KI-Agenten
Eine neue Technik, die von der Universität Zhejiang und der Alibaba Group entwickelt wurde, stattet Agenten für große Sprachmodelle (Large Language Model, LLM) mit einem dynamischen Gedächtnis aus und

2026 Neuestes: Entdecken Sie die besten KI-Kunstgeneratoren für Storyboards zu Kurzgeschichten. Unsere sorgfältig ausgewählte Liste enthält hochbewertete Tools zur Erstellung fesselnder Charaktere in Fantasy- und Urban-Romance-Geschichten. Vergleichen Sie kostenlose und kostenpflichtige Optionen, sehen Sie sich tatsächliche Testergebnisse an und finden Sie den perfekten kreativen Partner für Ihre Projekte. Erhalten Sie wöchentlich aktualisierte Rankings sowie Expertenmeinungen von XIX.AI. Beginnen Sie noch heute, Ihre Geschichten visuell zu gestalten!
10 Tools
xix.ai

Entdecken Sie die besten KI-Skripting-Tools für Radio und Podcasting im Jahr 2026 bei XIX.AI. Unsere sorgfältig ausgewählte, hochbewertete Liste bietet leistungsstarke Lösungen, mit denen Sie ansprechende Audio-Werbespots schnell erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von tatsächlichen Tests sowie wöchentlich aktualisierten Rankings. Entfalten Sie noch heute Ihr kreatives Potenzial!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die beste KI-Software zur Vertragsprüfung für 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools, die rechtliche Lücken und Compliance-Risiken sofort aufdecken. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihre bahnbrechende Lösung für eine sichere und effiziente Vertragsanalyse. Entdecken Sie jetzt den ultimativen Leitfaden.
10 Tools
xix.ai

Entdecken Sie die besten AI-Anime-Generatoren für Donghua im Jahr 2026. Unsere hochbewertete, sorgfältig ausgewählte Liste bietet leistungsstarke Tools, mit denen Sie atemberaubende Charaktere für Webromane und Comic-Avatare erstellen können. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand realer Tests. Finden Sie Ihren perfekten kreativen Partner und bringen Sie Ihre Geschichten noch heute bei XIX.AI zum Leben.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Tools zur automatischen Kolorierung von Manga für das Jahr 2026. Unsere sorgfältig zusammengestellte Liste enthält erstklassige, bahnbrechende Lösungen, die flächige Farben ohne Konsistenzfehler auftragen und so Ihre Produktivität steigern. Entdecken Sie Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten, Praxistests und wöchentlich aktualisierte Rankings, um das für Sie perfekte Tool zu finden. Nutzen Sie noch heute Ihren KI-Vorteil.
10 Tools
xix.ai

Entdecken Sie die besten KI-Tools zur Charakterentwicklung für 2026, mit denen Sie facettenreiche Figuren erschaffen können. Die von XIX.AI zusammengestellte Liste enthält erstklassige, bahnbrechende Tools, die konsistente Motivationen und fatale Schwächen generieren. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie jetzt Ihr Potenzial als Geschichtenerzähler.
10 Tools
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













