
















 家
家「分解された」合成面は、顔認識技術を強化する可能性があります
ミシガン州立大学の研究者たちは、合成顔を高貴な目的で使用する革新的な方法を考案しました。それは、画像認識システムの精度を向上させることです。ディープフェイク現象に寄与する代わりに、これらの合成顔は、実際のビデオ監視映像に見られる不完全さを模倣するように設計されています。
チームは、顔のぼやけ、低解像度、センサーノイズなど、CCTVシステムの典型的な欠点を反映したスタイルで顔を再生成できる制御可能な顔合成モジュール(CFSM)を開発しました。このアプローチは、人気のあるデータセットの高品質なセレブリティ画像を使用する従来の方法とは異なり、顔認識システムが直面する現実の課題を捉えていません。
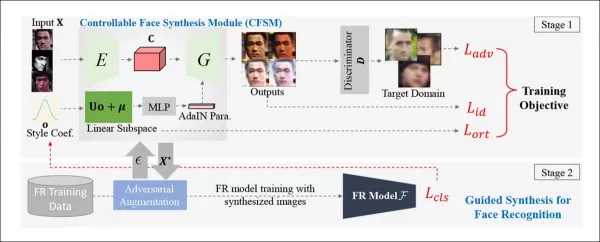 *制御可能な顔合成モジュール(CFSM)の概念的アーキテクチャ。* 出典:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*制御可能な顔合成モジュール(CFSM)の概念的アーキテクチャ。* 出典:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
頭のポーズや表情を再現することに焦点を当てるディープフェイクシステムとは異なり、CFSMはスタイル転送を通じて、対象となる認識システムのスタイルに一致する代替ビューを生成することを目指しています。このモジュールは、コスト制約によりアップグレードが難しいレガシーシステムに適応するのに特に有用で、現代の顔認識技術に貢献する必要があります。
CFSMをテストした際、研究者たちは低品質データの処理において画像認識システムが大幅に改善されることを観察しました。また、予期せぬ利点として、対象データセットの特性評価と比較が可能になり、さまざまなCCTVシステム向けにカスタマイズされたデータセットの作成やベンチマークのプロセスが簡素化されることがわかりました。
 *対象システムの制限に適応するように顔認識モデルを訓練する。* 出典:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*対象システムの制限に適応するように顔認識モデルを訓練する。* 出典:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
この方法は、既存のデータセットにも適用でき、顔認識に適したドメイン適応を効果的に実行します。**制御可能かつ誘導された顔合成による制約のない顔認識**と題されたこの研究は、米国国家情報長官室(ODNI、IARPA)から部分的な支援を受けており、MSUのコンピュータサイエンスおよび工学部の4人の研究者が関与しています。
低品質顔認識:成長する分野
過去数年間で、低品質顔認識(LQFR)は重要な研究分野として浮上しています。耐久性と長期使用を目的に構築された多くの古いビデオ監視システムは、技術的負債により時代遅れになり、機械学習の有効なデータソースとして機能するのに苦労しています。
 歴史的および最近のビデオ監視システムにおける顔の解像度の多様なレベル。出典:https://arxiv.org/pdf/1805.11519.pdf
歴史的および最近のビデオ監視システムにおける顔の解像度の多様なレベル。出典:https://arxiv.org/pdf/1805.11519.pdf
幸いにも、拡散モデルやその他のノイズベースのモデルは、この問題に対処するのに適しています。最新の画像合成システムの多くは、プロセスに低解像度画像のアップスケーリングを含めており、これはニューラル圧縮技術にとっても重要です。
顔認識の課題は、低解像度画像から抽出可能な最も少ない特徴で精度を最大化することです。これは低解像度での顔の識別に役立つだけでなく、訓練モデルの潜在空間における画像サイズの制限により必要でもあります。
コンピュータビジョンにおいて、「特徴」とは、顔だけでなく任意の画像から識別される特徴を指します。アップスケーリングアルゴリズムの進歩により、低解像度の監視映像を強化するさまざまな方法が提案されており、犯罪現場の調査などの法的目的で使用可能になる可能性があります。
しかし、誤認識のリスクがあり、理想的には、顔認識システムは正確な識別を行うために高解像度の画像を必要としないはずです。このような変換はコストがかかり、その有効性や合法性について疑問を投げかけます。
「みすぼらしい」セレブリティの必要性
顔認識システムが、画像を変換せずにレガシーシステムの出力から直接特徴を抽出できれば、より有益です。これには、高解像度のアイデンティティと既存の監視システムからの劣化した画像との関係をよりよく理解する必要があります。
問題は標準にあります。MS-Celeb-1MやWebFace260Mのようなデータセットは、一貫したベンチマークを提供するため広く使用されています。しかし、著者たちは、これらのデータセットで訓練された顔認識アルゴリズムは、古い監視システムの視覚的ドメインには適していないと主張しています。
 *マイクロソフトの人気のあるMS-Celeb1mデータセットの例。* 出典:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*マイクロソフトの人気のあるMS-Celeb1mデータセットの例。* 出典:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
論文では、最先端の顔認識モデルが、ドメインシフトの問題により現実の監視映像で苦戦していると指摘しています。これらのモデルは、センサーノイズや動きのぼやけなど、現実のシナリオに見られる変動が欠けている半制約的なデータセットで訓練されています。
従来の方法では、歴史的または低コストの監視システムの出力を一致させようとしていましたが、これらは「盲目的」な拡張でした。対照的に、CFSMは訓練中に対象システムからの直接的なフィードバックを使用し、スタイル転送を通じてそのドメインを模倣するように適応します。
 *コンピュータビジョンコミュニティを支配する少数のデータセットに慣れている女優ナタリー・ポートマンが、CFSMが実際の対象モデルのドメインからのフィードバックに基づいてスタイル一致のドメイン適応を行う例に登場しています。*
*コンピュータビジョンコミュニティを支配する少数のデータセットに慣れている女優ナタリー・ポートマンが、CFSMが実際の対象モデルのドメインからのフィードバックに基づいてスタイル一致のドメイン適応を行う例に登場しています。*
著者のアーキテクチャは、Fast Gradient Sign Method(FGSM)を使用して、対象システムの出力からスタイルと特性を取り込みます。訓練が進むにつれて、パイプラインの画像生成部分は対象システムにより忠実になり、顔認識のパフォーマンスと一般化能力が向上します。
テストと結果
研究者たちは、MSUの以前の研究をテンプレートとして使用し、MS-Celeb-1mとMS1M-V2を訓練データセットとしてCFSMをテストしました。対象データは、香港中文大学のWiderFaceデータセットで、困難な状況での顔検出用に設計されています。
システムは、IJB-B、IJB-C、IJB-S、TinyFaceの4つの顔認識ベンチマークに対して評価されました。CFSMは、MS-Celeb-1mデータの約10%、約40万枚の画像を、Adamオプティマイザを使用してバッチサイズ32、学習率1e-4で125,000イテレーション訓練しました。
対象の顔認識モデルは、ArcFace損失関数を備えた変更されたResNet-50を使用しました。比較のために、CFSMで訓練された追加のモデルが「ArcFace」として結果にラベル付けされました。
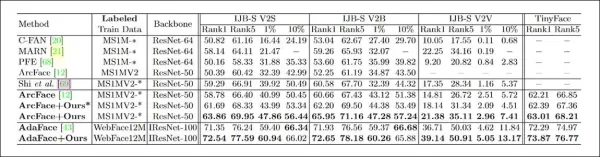 *CFSMの主要テストの結果。数値が高いほど良い。*
*CFSMの主要テストの結果。数値が高いほど良い。*
結果は、CFSMで強化されたArcFaceモデルが、顔の識別および検証タスクの両方ですべてのベースラインを上回り、新たな最先端のパフォーマンスを達成したことを示しました。
レガシー監視システムのさまざまな特性からドメインを抽出する能力は、これらのシステム間の分布の類似性を比較および評価することも可能にし、将来の研究で活用できる視覚的スタイルとしてそれぞれを提示します。
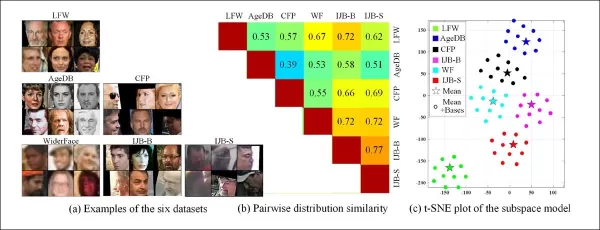 *さまざまなデータセットの例は、スタイルの明確な違いを示しています。*
*さまざまなデータセットの例は、スタイルの明確な違いを示しています。*
著者たちはまた、CFSMが敵対的操作を使用してビジョンタスクの認識精度を高める方法を示していると述べました。彼らは、学習されたスタイルベースに基づくデータセット類似性メトリックを導入し、ラベルや予測に依存しない方法でスタイルの違いを捉えました。
この研究は、制約のない顔認識のための制御可能かつ誘導された顔合成モデルの可能性を強調し、データセットの違いに関する洞察を提供します。
関連記事
 最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト
AIブームがドットコムバブル時代の懸念を想起させる
人工知能(AI)分野への数十億ドル規模の投資流入が、業界がドットコムバブルのような過熱状態に向かっているのかという激しい議論を巻き起こしている。投資家は熱狂の冷めや、チップやインフラへの巨額支出が期待通りのリターンを生んでいない兆候に警戒している。米バンク・オブ・アメリカ(BofA)グローバルリサーチの最近の調査はこの警戒感を裏付けており、ファンドマネージャーの54%がAI株は既にバブル状態にある
手続き的記憶がAIエージェントのコストと複雑さを削減する
浙江大学とアリババ・グループが開発した新しい技術は、大規模言語モデル(LLM)エージェントにダイナミック・メモリーを装備させ、複雑なタスクを処理する効率と効果を高める。Mempと名付けられたこのアプローチは、エージェントが経験を蓄積するにつれて継続的に更新される「手続き記憶」を提供するもので、人間が反復練習を通じて学習する方法を反映している。 Mempは、エージェントが新しいタスクごとにゼロから始
関連特集おすすめ
健康とウェルネス
最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト
AIブームがドットコムバブル時代の懸念を想起させる
人工知能(AI)分野への数十億ドル規模の投資流入が、業界がドットコムバブルのような過熱状態に向かっているのかという激しい議論を巻き起こしている。投資家は熱狂の冷めや、チップやインフラへの巨額支出が期待通りのリターンを生んでいない兆候に警戒している。米バンク・オブ・アメリカ(BofA)グローバルリサーチの最近の調査はこの警戒感を裏付けており、ファンドマネージャーの54%がAI株は既にバブル状態にある
手続き的記憶がAIエージェントのコストと複雑さを削減する
浙江大学とアリババ・グループが開発した新しい技術は、大規模言語モデル(LLM)エージェントにダイナミック・メモリーを装備させ、複雑なタスクを処理する効率と効果を高める。Mempと名付けられたこのアプローチは、エージェントが経験を蓄積するにつれて継続的に更新される「手続き記憶」を提供するもので、人間が反復練習を通じて学習する方法を反映している。 Mempは、エージェントが新しいタスクごとにゼロから始
関連特集おすすめ
健康とウェルネス
 AI妊娠サポートツール:妊娠期間ごとの安全な運動・栄養プランを生成
AI妊娠サポートツール:妊娠期間ごとの安全な運動・栄養プランを生成
2026年版、安全で個人に合わせた妊娠期間ごとの運動・栄養プランを提供する、最高のAI妊娠サポートツールを発見しましょう。高評価の厳選されたおすすめツールに加え、無料版と有料版の比較や実際の利用体験に基づくインサイトもご提供します。XIX.AIの専門家によるガイドで、最も健康的な妊娠生活を手に入れましょう。今すぐチェックしてみてください。
 10 ツール
10 ツール
 xix.ai
書き込み
最高の無料AI検出回避ツール:機械的な下書きを自然で人間らしい文章に変える
xix.ai
書き込み
最高の無料AI検出回避ツール:機械的な下書きを自然で人間らしい文章に変える
XIX.AIで、2026年最高の無料・検出されないAIライティングツールを発見しましょう。厳選された高評価のリストを活用すれば、機械的な下書きを自然で人間らしい文章へと変えることができます。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較が可能です。今すぐAIライティングの真価を解き放ちましょう。
10 ツール
xix.ai
画像編集
AIアートジェネレーターを活用した短編ドラマのストーリーボード制作:ファンタジーおよびアーバンロマンスキャラクター
2026年最新情報:短編ドラマのストーリーボード作成に最適なAIアートジェネレーターを発見しましょう。当社が厳選したリストには、魅力的なファンタジーやアーバンロマンスキャラクターを制作するための高評価ツールが掲載されています。無料版と有料版を比較し、実際のテスト結果を確認して、自分に最適な創作ツールを見つけましょう。XIX.AIから毎週更新されるランキングや専門家の意見もご覧いただけます。今日からあなたの物語を視覚化し始めましょう!
10 ツール
xix.ai
書き込み
ラジオおよびポッドキャスト用の最適なAIスクリプティングツール:魅力的なオーディオコマーシャルを作成する
XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
10 ツール
xix.ai
仕事
最高のAI契約書レビューソフトウェア:法的な抜け穴やコンプライアンス上のリスクを即座に特定
XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai
アニメーション制作
東華向けAIアニメジェネレーター:ウェブ小説のキャラクターやコミックのアバターを作成する
2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

 コメント (13)
0/500
コメント (13)
0/500
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
ミシガン州立大学の研究者たちは、合成顔を高貴な目的で使用する革新的な方法を考案しました。それは、画像認識システムの精度を向上させることです。ディープフェイク現象に寄与する代わりに、これらの合成顔は、実際のビデオ監視映像に見られる不完全さを模倣するように設計されています。
チームは、顔のぼやけ、低解像度、センサーノイズなど、CCTVシステムの典型的な欠点を反映したスタイルで顔を再生成できる制御可能な顔合成モジュール(CFSM)を開発しました。このアプローチは、人気のあるデータセットの高品質なセレブリティ画像を使用する従来の方法とは異なり、顔認識システムが直面する現実の課題を捉えていません。
*制御可能な顔合成モジュール(CFSM)の概念的アーキテクチャ。* 出典:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
頭のポーズや表情を再現することに焦点を当てるディープフェイクシステムとは異なり、CFSMはスタイル転送を通じて、対象となる認識システムのスタイルに一致する代替ビューを生成することを目指しています。このモジュールは、コスト制約によりアップグレードが難しいレガシーシステムに適応するのに特に有用で、現代の顔認識技術に貢献する必要があります。
CFSMをテストした際、研究者たちは低品質データの処理において画像認識システムが大幅に改善されることを観察しました。また、予期せぬ利点として、対象データセットの特性評価と比較が可能になり、さまざまなCCTVシステム向けにカスタマイズされたデータセットの作成やベンチマークのプロセスが簡素化されることがわかりました。
*対象システムの制限に適応するように顔認識モデルを訓練する。* 出典:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
この方法は、既存のデータセットにも適用でき、顔認識に適したドメイン適応を効果的に実行します。**制御可能かつ誘導された顔合成による制約のない顔認識**と題されたこの研究は、米国国家情報長官室(ODNI、IARPA)から部分的な支援を受けており、MSUのコンピュータサイエンスおよび工学部の4人の研究者が関与しています。
低品質顔認識:成長する分野
過去数年間で、低品質顔認識(LQFR)は重要な研究分野として浮上しています。耐久性と長期使用を目的に構築された多くの古いビデオ監視システムは、技術的負債により時代遅れになり、機械学習の有効なデータソースとして機能するのに苦労しています。
歴史的および最近のビデオ監視システムにおける顔の解像度の多様なレベル。出典:https://arxiv.org/pdf/1805.11519.pdf
幸いにも、拡散モデルやその他のノイズベースのモデルは、この問題に対処するのに適しています。最新の画像合成システムの多くは、プロセスに低解像度画像のアップスケーリングを含めており、これはニューラル圧縮技術にとっても重要です。
顔認識の課題は、低解像度画像から抽出可能な最も少ない特徴で精度を最大化することです。これは低解像度での顔の識別に役立つだけでなく、訓練モデルの潜在空間における画像サイズの制限により必要でもあります。
コンピュータビジョンにおいて、「特徴」とは、顔だけでなく任意の画像から識別される特徴を指します。アップスケーリングアルゴリズムの進歩により、低解像度の監視映像を強化するさまざまな方法が提案されており、犯罪現場の調査などの法的目的で使用可能になる可能性があります。
しかし、誤認識のリスクがあり、理想的には、顔認識システムは正確な識別を行うために高解像度の画像を必要としないはずです。このような変換はコストがかかり、その有効性や合法性について疑問を投げかけます。
「みすぼらしい」セレブリティの必要性
顔認識システムが、画像を変換せずにレガシーシステムの出力から直接特徴を抽出できれば、より有益です。これには、高解像度のアイデンティティと既存の監視システムからの劣化した画像との関係をよりよく理解する必要があります。
問題は標準にあります。MS-Celeb-1MやWebFace260Mのようなデータセットは、一貫したベンチマークを提供するため広く使用されています。しかし、著者たちは、これらのデータセットで訓練された顔認識アルゴリズムは、古い監視システムの視覚的ドメインには適していないと主張しています。
*マイクロソフトの人気のあるMS-Celeb1mデータセットの例。* 出典:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
論文では、最先端の顔認識モデルが、ドメインシフトの問題により現実の監視映像で苦戦していると指摘しています。これらのモデルは、センサーノイズや動きのぼやけなど、現実のシナリオに見られる変動が欠けている半制約的なデータセットで訓練されています。
従来の方法では、歴史的または低コストの監視システムの出力を一致させようとしていましたが、これらは「盲目的」な拡張でした。対照的に、CFSMは訓練中に対象システムからの直接的なフィードバックを使用し、スタイル転送を通じてそのドメインを模倣するように適応します。
*コンピュータビジョンコミュニティを支配する少数のデータセットに慣れている女優ナタリー・ポートマンが、CFSMが実際の対象モデルのドメインからのフィードバックに基づいてスタイル一致のドメイン適応を行う例に登場しています。*
著者のアーキテクチャは、Fast Gradient Sign Method(FGSM)を使用して、対象システムの出力からスタイルと特性を取り込みます。訓練が進むにつれて、パイプラインの画像生成部分は対象システムにより忠実になり、顔認識のパフォーマンスと一般化能力が向上します。
テストと結果
研究者たちは、MSUの以前の研究をテンプレートとして使用し、MS-Celeb-1mとMS1M-V2を訓練データセットとしてCFSMをテストしました。対象データは、香港中文大学のWiderFaceデータセットで、困難な状況での顔検出用に設計されています。
システムは、IJB-B、IJB-C、IJB-S、TinyFaceの4つの顔認識ベンチマークに対して評価されました。CFSMは、MS-Celeb-1mデータの約10%、約40万枚の画像を、Adamオプティマイザを使用してバッチサイズ32、学習率1e-4で125,000イテレーション訓練しました。
対象の顔認識モデルは、ArcFace損失関数を備えた変更されたResNet-50を使用しました。比較のために、CFSMで訓練された追加のモデルが「ArcFace」として結果にラベル付けされました。
*CFSMの主要テストの結果。数値が高いほど良い。*
結果は、CFSMで強化されたArcFaceモデルが、顔の識別および検証タスクの両方ですべてのベースラインを上回り、新たな最先端のパフォーマンスを達成したことを示しました。
レガシー監視システムのさまざまな特性からドメインを抽出する能力は、これらのシステム間の分布の類似性を比較および評価することも可能にし、将来の研究で活用できる視覚的スタイルとしてそれぞれを提示します。
*さまざまなデータセットの例は、スタイルの明確な違いを示しています。*
著者たちはまた、CFSMが敵対的操作を使用してビジョンタスクの認識精度を高める方法を示していると述べました。彼らは、学習されたスタイルベースに基づくデータセット類似性メトリックを導入し、ラベルや予測に依存しない方法でスタイルの違いを捉えました。
この研究は、制約のない顔認識のための制御可能かつ誘導された顔合成モデルの可能性を強調し、データセットの違いに関する洞察を提供します。










 最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト
最適化主導型AIが汎用モデルへの新たな道として台頭
イリノイ大学アーバナ・シャンペーン校とバージニア大学の研究者らは、強化された推論能力を備えたより強靭なAIシステムへの道を開く可能性のある新たなモデルアーキテクチャを開発した。エネルギーベーストランスフォーマー(EBT)と名付けられたこのアーキテクチャは、推論時のスケーリングを自然に活用して複雑な課題に対処する。企業にとっては、専用に微調整されたモデルを必要とせず、新たなシナリオに適応できるコスト
 AIブームがドットコムバブル時代の懸念を想起させる
人工知能(AI)分野への数十億ドル規模の投資流入が、業界がドットコムバブルのような過熱状態に向かっているのかという激しい議論を巻き起こしている。投資家は熱狂の冷めや、チップやインフラへの巨額支出が期待通りのリターンを生んでいない兆候に警戒している。米バンク・オブ・アメリカ(BofA)グローバルリサーチの最近の調査はこの警戒感を裏付けており、ファンドマネージャーの54%がAI株は既にバブル状態にある
AIブームがドットコムバブル時代の懸念を想起させる
人工知能(AI)分野への数十億ドル規模の投資流入が、業界がドットコムバブルのような過熱状態に向かっているのかという激しい議論を巻き起こしている。投資家は熱狂の冷めや、チップやインフラへの巨額支出が期待通りのリターンを生んでいない兆候に警戒している。米バンク・オブ・アメリカ(BofA)グローバルリサーチの最近の調査はこの警戒感を裏付けており、ファンドマネージャーの54%がAI株は既にバブル状態にある
 手続き的記憶がAIエージェントのコストと複雑さを削減する
浙江大学とアリババ・グループが開発した新しい技術は、大規模言語モデル(LLM)エージェントにダイナミック・メモリーを装備させ、複雑なタスクを処理する効率と効果を高める。Mempと名付けられたこのアプローチは、エージェントが経験を蓄積するにつれて継続的に更新される「手続き記憶」を提供するもので、人間が反復練習を通じて学習する方法を反映している。 Mempは、エージェントが新しいタスクごとにゼロから始
手続き的記憶がAIエージェントのコストと複雑さを削減する
浙江大学とアリババ・グループが開発した新しい技術は、大規模言語モデル(LLM)エージェントにダイナミック・メモリーを装備させ、複雑なタスクを処理する効率と効果を高める。Mempと名付けられたこのアプローチは、エージェントが経験を蓄積するにつれて継続的に更新される「手続き記憶」を提供するもので、人間が反復練習を通じて学習する方法を反映している。 Mempは、エージェントが新しいタスクごとにゼロから始

2026年版、安全で個人に合わせた妊娠期間ごとの運動・栄養プランを提供する、最高のAI妊娠サポートツールを発見しましょう。高評価の厳選されたおすすめツールに加え、無料版と有料版の比較や実際の利用体験に基づくインサイトもご提供します。XIX.AIの専門家によるガイドで、最も健康的な妊娠生活を手に入れましょう。今すぐチェックしてみてください。
10 ツール
xix.ai

XIX.AIで、2026年最高の無料・検出されないAIライティングツールを発見しましょう。厳選された高評価のリストを活用すれば、機械的な下書きを自然で人間らしい文章へと変えることができます。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較が可能です。今すぐAIライティングの真価を解き放ちましょう。
10 ツール
xix.ai

2026年最新情報:短編ドラマのストーリーボード作成に最適なAIアートジェネレーターを発見しましょう。当社が厳選したリストには、魅力的なファンタジーやアーバンロマンスキャラクターを制作するための高評価ツールが掲載されています。無料版と有料版を比較し、実際のテスト結果を確認して、自分に最適な創作ツールを見つけましょう。XIX.AIから毎週更新されるランキングや専門家の意見もご覧いただけます。今日からあなたの物語を視覚化し始めましょう!
10 ツール
xix.ai

XIX.AIで2026年に最も優れたAIスクリプティングツールを探そう。厳選された高評価のリストには、魅力的なオーディオコマーシャルを迅速に作成するための強力で革新的なソリューションが掲載されている。無料版と有料版を実際のテストと毎週更新されるランキングで比較してみよう。今日からあなたの創造性を解き放ってください!
10 ツール
xix.ai

XIX.AIで、2026年最高のAI契約書レビューソフトウェアを見つけましょう。厳選された高評価のリストには、法的抜け穴やコンプライアンス上のリスクを瞬時に特定する強力なツールが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。安全かつ効率的な契約書分析を実現する、画期的なソリューションを見つけましょう。今すぐ決定版ガイドをご覧ください。
10 ツール
xix.ai

2026年に最も優れたAIアニメーション生成ツールを探そう。当社が厳選したリストには、見事なウェブ小説のキャラクターやコミックのアバターを作成するための強力なツールが揃っています。無料オプションと有料オプションを実際のテストで比較し、自分に最適な創造的なパートナーを見つけて、今日すぐにXIX.AIであなたの物語を形にしてみましょう。
10 ツール
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













