




'अपमानित' सिंथेटिक चेहरे चेहरे की पहचान तकनीक को बढ़ा सकते हैं
मिशिगन स्टेट यूनिवर्सिटी के शोधकर्ताओं ने एक नवोन्मेषी तरीका विकसित किया है जिसमें सिंथेटिक चेहरों का उपयोग एक नेक उद्देश्य के लिए किया गया है—छवि पहचान प्रणालियों की सटीकता को बढ़ाना। डीपफेक घटना में योगदान देने के बजाय, इन सिंथेटिक चेहरों को वास्तविक दुनिया के वीडियो निगरानी फुटेज में पाई जाने वाली खामियों की नकल करने के लिए डिज़ाइन किया गया है।
टीम ने एक नियंत्रणीय चेहरा संश्लेषण मॉड्यूल (CFSM) विकसित किया है जो चेहरों को उस शैली में पुनर्जनन कर सकता है जो CCTV सिस्टम की विशिष्ट खामियों को दर्शाता है, जैसे चेहरे का धुंधलापन, कम रिज़ॉल्यूशन, और सेंसर शोर। यह दृष्टिकोण लोकप्रिय डेटासेट से उच्च-गुणवत्ता वाली सेलिब्रिटी छवियों के उपयोग से भिन्न है, जो चेहरे की पहचान प्रणालियों द्वारा सामना की जाने वाली वास्तविक दुनिया की चुनौतियों को कैप्चर नहीं करते।
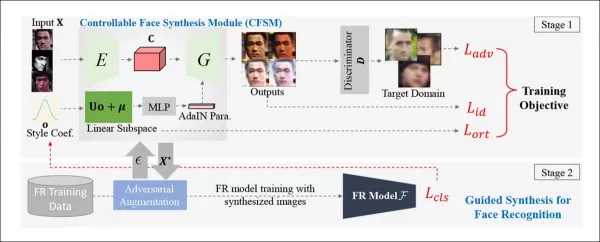 *नियंत्रणीय चेहरा संश्लेषण मॉड्यूल (CFSM) के लिए वैचारिक वास्तुकला।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*नियंत्रणीय चेहरा संश्लेषण मॉड्यूल (CFSM) के लिए वैचारिक वास्तुकला।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
डीपफेक सिस्टमों के विपरीत, जो सिर की मुद्राओं और अभिव्यक्तियों को दोहराने पर ध्यान केंद्रित करते हैं, CFSM का उद्देश्य शैली हस्तांतरण के माध्यम से वैकल्पिक दृश्य उत्पन्न करना है जो लक्ष्य पहचान प्रणाली की शैली से मेल खाता हो। यह मॉड्यूल विशेष रूप से उन पुराने सिस्टमों के लिए उपयोगी है जिन्हें लागत बाधाओं के कारण अपग्रेड करने की संभावना नहीं है, लेकिन फिर भी आधुनिक चेहरा पहचान तकनीकों में योगदान देने की आवश्यकता है।
CFSM के परीक्षण के दौरान, शोधकर्ताओं ने कम-गुणवत्ता वाले डेटा से निपटने वाली छवि पहचान प्रणालियों में महत्वपूर्ण सुधार देखा। उन्होंने एक अप्रत्याशित लाभ भी पाया: लक्ष्य डेटासेट को विशेषता प्रदान करने और तुलना करने की क्षमता, जो विभिन्न CCTV सिस्टमों के लिए बेंचमार्किंग और अनुकूलित डेटासेट बनाने की प्रक्रिया को सरल बनाता है।
 *लक्ष्य प्रणालियों की सीमाओं के अनुकूल होने के लिए चेहरा पहचान मॉडल को प्रशिक्षित करना।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*लक्ष्य प्रणालियों की सीमाओं के अनुकूल होने के लिए चेहरा पहचान मॉडल को प्रशिक्षित करना।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
यह विधि मौजूदा डेटासेट पर भी लागू की जा सकती है, जो डोमेन अनुकूलन को प्रभावी ढंग से करता है ताकि वे चेहरा पहचान के लिए अधिक उपयुक्त हों। शोध, जिसका शीर्षक **नियंत्रणीय और निर्देशित चेहरा संश्लेषण अनियंत्रित चेहरा पहचान के लिए** है, को अमेरिकी राष्ट्रीय खुफिया निदेशक कार्यालय (ODNI, at IARPA) द्वारा आंशिक रूप से समर्थित किया गया है और इसमें MSU के कंप्यूटर विज्ञान और इंजीनियरिंग विभाग के चार शोधकर्ता शामिल हैं।
कम-गुणवत्ता चेहरा पहचान: एक उभरता हुआ क्षेत्र
पिछले कुछ वर्षों में, कम-गुणवत्ता चेहरा पहचान (LQFR) एक महत्वपूर्ण अध्ययन क्षेत्र के रूप में उभरा है। कई पुराने वीडियो निगरानी सिस्टम, जो टिकाऊ और लंबे समय तक चलने के लिए बनाए गए थे, तकनीकी ऋण के कारण पुराने हो गए हैं और मशीन लर्निंग के लिए प्रभावी डेटा स्रोत के रूप में सेवा करने में संघर्ष करते हैं।
 ऐतिहासिक और अधिक हाल के वीडियो निगरानी सिस्टमों में चेहरों के रिज़ॉल्यूशन के विभिन्न स्तर। स्रोत: https://arxiv.org/pdf/1805.11519.pdf
ऐतिहासिक और अधिक हाल के वीडियो निगरानी सिस्टमों में चेहरों के रिज़ॉल्यूशन के विभिन्न स्तर। स्रोत: https://arxiv.org/pdf/1805.11519.pdf
सौभाग्य से, डिफ्यूजन मॉडल और अन्य शोर-आधारित मॉडल इस समस्या को हल करने के लिए उपयुक्त हैं। कई नवीनतम छवि संश्लेषण सिस्टम अपनी प्रक्रिया के हिस्से के रूप में कम-रिज़ॉल्यूशन छवियों को अपस्केलिंग शामिल करते हैं, जो न्यूरल संपीड़न तकनीकों के लिए भी महत्वपूर्ण है।
चेहरा पहचान में चुनौती कम-रिज़ॉल्यूशन छवियों से न्यूनतम संभव विशेषताओं को निकालकर सटीकता को अधिकतम करना है। यह न केवल कम रिज़ॉल्यूशन पर चेहरों की पहचान के लिए उपयोगी है, बल्कि प्रशिक्षण मॉडल के अव्यक्त स्थान में छवि आकार की सीमाओं के कारण भी आवश्यक है।
कंप्यूटर दृष्टि में, 'विशेषताएं' किसी भी छवि की विशिष्ट विशेषताओं को संदर्भित करती हैं, न कि केवल चेहरों की। अपस्केलिंग एल्गोरिदम में प्रगति के साथ, कम-रिज़ॉल्यूशन निगरानी फुटेज को बढ़ाने के लिए विभिन्न विधियां प्रस्तावित की गई हैं, जो संभावित रूप से इसे अपराध स्थल जांच जैसे कानूनी उद्देश्यों के लिए उपयोगी बना सकती हैं।
हालांकि, गलत पहचान का जोखिम है, और आदर्श रूप से, चेहरा पहचान प्रणालियों को सटीक पहचान के लिए उच्च-रिज़ॉल्यूशन छवियों की आवश्यकता नहीं होनी चाहिए। ऐसी परिवर्तन महंगे हैं और उनकी वैधता और कानूनीता के बारे में सवाल उठाते हैं।
अधिक 'डाउन-एट-हील' सेलिब्रिटीज़ की आवश्यकता
यह अधिक लाभकारी होगा यदि चेहरा पहचान प्रणालियां पुराने सिस्टमों के आउटपुट से सीधे विशेषताओं को निकाल सकें बिना छवियों को परिवर्तित करने की आवश्यकता के। इसके लिए उच्च-रिज़ॉल्यूशन पहचानों और मौजूदा निगरानी सिस्टमों से प्राप्त खराब छवियों के बीच संबंध को बेहतर ढंग से समझने की आवश्यकता है।
समस्या मानकों में निहित है: MS-Celeb-1M और WebFace260M जैसे डेटासेट व्यापक रूप से उपयोग किए जाते हैं क्योंकि वे सुसंगत बेंचमार्क प्रदान करते हैं। हालांकि, लेखकों का तर्क है कि इन डेटासेट पर प्रशिक्षित चेहरा पहचान एल्गोरिदम पुराने निगरानी सिस्टमों के दृश्य डोमेन के लिए उपयुक्त नहीं हैं।
 *माइक्रोसॉफ्ट के लोकप्रिय MS-Celeb1m डेटासेट से उदाहरण।* स्रोत: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*माइक्रोसॉफ्ट के लोकप्रिय MS-Celeb1m डेटासेट से उदाहरण।* स्रोत: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
पेपर में उल्लेख किया गया है कि अत्याधुनिक चेहरा पहचान मॉडल वास्तविक दुनिया के निगरानी चित्रों के साथ डोमेन शिफ्ट समस्याओं के कारण संघर्ष करते हैं। ये मॉडल अर्ध-नियंत्रित डेटासेट पर प्रशिक्षित होते हैं जो वास्तविक दुनिया के परिदृश्यों में पाए जाने वाले बदलावों, जैसे सेंसर शोर और गति धुंधलापन, की कमी रखते हैं।
पिछली विधियों ने ऐतिहासिक या कम लागत वाले निगरानी सिस्टमों के आउटपुट से मेल खाने की कोशिश की है, लेकिन ये 'अंधा' वृद्धि थीं। इसके विपरीत, CFSM प्रशिक्षण के दौरान लक्ष्य प्रणाली से प्रत्यक्ष प्रतिक्रिया का उपयोग करता है और उस डोमेन की नकल करने के लिए शैली हस्तांतरण के माध्यम से अनुकूलन करता है।
 *अभिनेत्री नटाली पोर्टमैन, जो कंप्यूटर दृष्टि समुदाय में प्रभुत्व रखने वाले कुछ डेटासेट से अपरिचित नहीं हैं, इस उदाहरण में CFSM द्वारा वास्तविक लक्ष्य मॉडल के डोमेन से प्रतिक्रिया के आधार पर शैली-मिलान डोमेन अनुकूलन करने वाली पहचानों में शामिल हैं।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*अभिनेत्री नटाली पोर्टमैन, जो कंप्यूटर दृष्टि समुदाय में प्रभुत्व रखने वाले कुछ डेटासेट से अपरिचित नहीं हैं, इस उदाहरण में CFSM द्वारा वास्तविक लक्ष्य मॉडल के डोमेन से प्रतिक्रिया के आधार पर शैली-मिलान डोमेन अनुकूलन करने वाली पहचानों में शामिल हैं।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
लेखकों की वास्तुकला फास्ट ग्रेडिएंट साइन मेथड (FGSM) का उपयोग करती है ताकि लक्ष्य प्रणाली के आउटपुट से शैलियों और विशेषताओं को आयात किया जा सके। जैसे-जैसे प्रशिक्षण आगे बढ़ता है, पाइपलाइन का छवि जनन हिस्सा लक्ष्य प्रणाली के प्रति अधिक विश्वसनीय हो जाता है, जिससे चेहरा पहचान प्रदर्शन और सामान्यीकरण क्षमताओं में सुधार होता है।
परीक्षण और परिणाम
शोधकर्ताओं ने MSU के पूर्व कार्य को टेम्पलेट के रूप में उपयोग करके CFSM का परीक्षण किया, जिसमें MS-Celeb-1m और MS1M-V2 को प्रशिक्षण डेटासेट के रूप में उपयोग किया गया। लक्ष्य डेटा हांगकांग की चीनी यूनिवर्सिटी का WiderFace डेटासेट था, जो चुनौतीपूर्ण परिस्थितियों में चेहरा पहचान के लिए डिज़ाइन किया गया था।
सिस्टम का मूल्यांकन चार चेहरा पहचान बेंचमार्क के खिलाफ किया गया: IJB-B, IJB-C, IJB-S, और TinyFace। CFSM को MS-Celeb-1m डेटा के लगभग 10%, लगभग 0.4 मिलियन छवियों के साथ, 125,000 पुनरावृत्तियों के लिए 32 के बैच आकार के साथ Adam ऑप्टिमाइज़र का उपयोग करके 1e-4 की शिक्षण दर के साथ प्रशिक्षित किया गया था।
लक्ष्य चेहरा पहचान मॉडल ने ArcFace हानि फ़ंक्शन के साथ एक संशोधित ResNet-50 का उपयोग किया। तुलना के लिए CFSM के साथ एक अतिरिक्त मॉडल प्रशिक्षित किया गया, जिसे परिणामों में 'ArcFace' के रूप में लेबल किया गया।
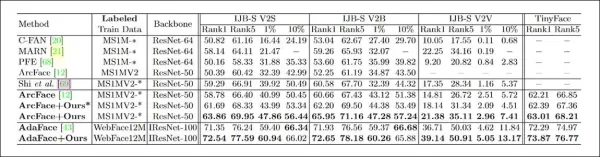 *CFSM के लिए प्राथमिक परीक्षणों के परिणाम। उच्च संख्या बेहतर है।*
*CFSM के लिए प्राथमिक परीक्षणों के परिणाम। उच्च संख्या बेहतर है।*
परिणामों ने दिखाया कि CFSM द्वारा उन्नत ArcFace मॉडल ने चेहरा पहचान और सत्यापन कार्यों में सभी आधार रेखाओं को पीछे छोड़ दिया, जिससे नया अत्याधुनिक प्रदर्शन प्राप्त हुआ।
पुराने निगरानी सिस्टमों की विभिन्न विशेषताओं से डोमेन निकालने की क्षमता भी इन सिस्टमों के बीच वितरण समानता की तुलना और मूल्यांकन करने की अनुमति देती है, प्रत्येक को एक दृश्य शैली के रूप में प्रस्तुत करती है जिसका उपयोग भविष्य के कार्य में किया जा सकता है।
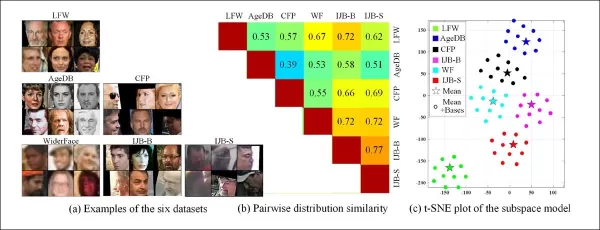 *विभिन्न डेटासेट से उदाहरण स्पष्ट रूप से शैली में अंतर प्रदर्शित करते हैं।*
*विभिन्न डेटासेट से उदाहरण स्पष्ट रूप से शैली में अंतर प्रदर्शित करते हैं।*
लेखकों ने यह भी नोट किया कि CFSM यह प्रदर्शित करता है कि दृष्टि कार्यों में पहचान सटीकता बढ़ाने के लिए प्रतिकूल हेरफेर का उपयोग कैसे किया जा सकता है। उन्होंने सीखे गए शैली आधारों पर आधारित एक डेटासेट समानता मीट्रिक पेश किया, जो लेबल या भविष्यवक्ता-निरपेक्ष तरीके से शैली अंतर को कैप्चर करता है।
शोध अनियंत्रित चेहरा पहचान के लिए नियंत्रणीय और निर्देशित चेहरा संश्लेषण मॉडल की क्षमता को रेखांकित करता है और डेटासेट अंतरों में अंतर्दृष्टि प्रदान करता है।
संबंधित लेख
 Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
सूचना (10)
0/200
Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
सूचना (10)
0/200
![LarryWilliams]() LarryWilliams
LarryWilliams
 27 अप्रैल 2025 1:28:26 अपराह्न IST
27 अप्रैल 2025 1:28:26 अपराह्न IST
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐


 0
0
![CharlesJohnson]() CharlesJohnson
27 अप्रैल 2025 1:27:41 अपराह्न IST
CharlesJohnson
27 अप्रैल 2025 1:27:41 अपराह्न IST
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
0
![MatthewGonzalez]() MatthewGonzalez
27 अप्रैल 2025 1:57:32 पूर्वाह्न IST
MatthewGonzalez
27 अप्रैल 2025 1:57:32 पूर्वाह्न IST
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
0
![FrankSmith]() FrankSmith
26 अप्रैल 2025 9:49:01 अपराह्न IST
FrankSmith
26 अप्रैल 2025 9:49:01 अपराह्न IST
미시간 주립대 연구진이 하는 이 작업은 정말 멋져 보입니다. 인공 얼굴을 이용해 이미지 인식 기술을 개선하려는 목적 자체가 놀랍네요. 실용성 검증이 필요할 것 같아요. 😎💡
0
![FrankJackson]() FrankJackson
26 अप्रैल 2025 7:50:26 अपराह्न IST
FrankJackson
26 अप्रैल 2025 7:50:26 अपराह्न IST
合成顔を使って顔認識技術を向上させるなんて、素晴らしいアイデアだと思う!深偽ではなく、良い目的に使われる技術は嬉しいね。ただ、もう少し使いやすければ完璧だったのに。でも、革新性には拍手を送りたい!👏
0
![SebastianAnderson]() SebastianAnderson
26 अप्रैल 2025 6:30:27 अपराह्न IST
SebastianAnderson
26 अप्रैल 2025 6:30:27 अपराह्न IST
¡Es una idea muy interesante! Usar caras sintéticas para mejorar el reconocimiento facial parece un gran avance. Sin embargo, espero que no genere más problemas de privacidad. 🌟🤔
0
मिशिगन स्टेट यूनिवर्सिटी के शोधकर्ताओं ने एक नवोन्मेषी तरीका विकसित किया है जिसमें सिंथेटिक चेहरों का उपयोग एक नेक उद्देश्य के लिए किया गया है—छवि पहचान प्रणालियों की सटीकता को बढ़ाना। डीपफेक घटना में योगदान देने के बजाय, इन सिंथेटिक चेहरों को वास्तविक दुनिया के वीडियो निगरानी फुटेज में पाई जाने वाली खामियों की नकल करने के लिए डिज़ाइन किया गया है।
टीम ने एक नियंत्रणीय चेहरा संश्लेषण मॉड्यूल (CFSM) विकसित किया है जो चेहरों को उस शैली में पुनर्जनन कर सकता है जो CCTV सिस्टम की विशिष्ट खामियों को दर्शाता है, जैसे चेहरे का धुंधलापन, कम रिज़ॉल्यूशन, और सेंसर शोर। यह दृष्टिकोण लोकप्रिय डेटासेट से उच्च-गुणवत्ता वाली सेलिब्रिटी छवियों के उपयोग से भिन्न है, जो चेहरे की पहचान प्रणालियों द्वारा सामना की जाने वाली वास्तविक दुनिया की चुनौतियों को कैप्चर नहीं करते।
*नियंत्रणीय चेहरा संश्लेषण मॉड्यूल (CFSM) के लिए वैचारिक वास्तुकला।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
डीपफेक सिस्टमों के विपरीत, जो सिर की मुद्राओं और अभिव्यक्तियों को दोहराने पर ध्यान केंद्रित करते हैं, CFSM का उद्देश्य शैली हस्तांतरण के माध्यम से वैकल्पिक दृश्य उत्पन्न करना है जो लक्ष्य पहचान प्रणाली की शैली से मेल खाता हो। यह मॉड्यूल विशेष रूप से उन पुराने सिस्टमों के लिए उपयोगी है जिन्हें लागत बाधाओं के कारण अपग्रेड करने की संभावना नहीं है, लेकिन फिर भी आधुनिक चेहरा पहचान तकनीकों में योगदान देने की आवश्यकता है।
CFSM के परीक्षण के दौरान, शोधकर्ताओं ने कम-गुणवत्ता वाले डेटा से निपटने वाली छवि पहचान प्रणालियों में महत्वपूर्ण सुधार देखा। उन्होंने एक अप्रत्याशित लाभ भी पाया: लक्ष्य डेटासेट को विशेषता प्रदान करने और तुलना करने की क्षमता, जो विभिन्न CCTV सिस्टमों के लिए बेंचमार्किंग और अनुकूलित डेटासेट बनाने की प्रक्रिया को सरल बनाता है।
*लक्ष्य प्रणालियों की सीमाओं के अनुकूल होने के लिए चेहरा पहचान मॉडल को प्रशिक्षित करना।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
यह विधि मौजूदा डेटासेट पर भी लागू की जा सकती है, जो डोमेन अनुकूलन को प्रभावी ढंग से करता है ताकि वे चेहरा पहचान के लिए अधिक उपयुक्त हों। शोध, जिसका शीर्षक **नियंत्रणीय और निर्देशित चेहरा संश्लेषण अनियंत्रित चेहरा पहचान के लिए** है, को अमेरिकी राष्ट्रीय खुफिया निदेशक कार्यालय (ODNI, at IARPA) द्वारा आंशिक रूप से समर्थित किया गया है और इसमें MSU के कंप्यूटर विज्ञान और इंजीनियरिंग विभाग के चार शोधकर्ता शामिल हैं।
कम-गुणवत्ता चेहरा पहचान: एक उभरता हुआ क्षेत्र
पिछले कुछ वर्षों में, कम-गुणवत्ता चेहरा पहचान (LQFR) एक महत्वपूर्ण अध्ययन क्षेत्र के रूप में उभरा है। कई पुराने वीडियो निगरानी सिस्टम, जो टिकाऊ और लंबे समय तक चलने के लिए बनाए गए थे, तकनीकी ऋण के कारण पुराने हो गए हैं और मशीन लर्निंग के लिए प्रभावी डेटा स्रोत के रूप में सेवा करने में संघर्ष करते हैं।
ऐतिहासिक और अधिक हाल के वीडियो निगरानी सिस्टमों में चेहरों के रिज़ॉल्यूशन के विभिन्न स्तर। स्रोत: https://arxiv.org/pdf/1805.11519.pdf
सौभाग्य से, डिफ्यूजन मॉडल और अन्य शोर-आधारित मॉडल इस समस्या को हल करने के लिए उपयुक्त हैं। कई नवीनतम छवि संश्लेषण सिस्टम अपनी प्रक्रिया के हिस्से के रूप में कम-रिज़ॉल्यूशन छवियों को अपस्केलिंग शामिल करते हैं, जो न्यूरल संपीड़न तकनीकों के लिए भी महत्वपूर्ण है।
चेहरा पहचान में चुनौती कम-रिज़ॉल्यूशन छवियों से न्यूनतम संभव विशेषताओं को निकालकर सटीकता को अधिकतम करना है। यह न केवल कम रिज़ॉल्यूशन पर चेहरों की पहचान के लिए उपयोगी है, बल्कि प्रशिक्षण मॉडल के अव्यक्त स्थान में छवि आकार की सीमाओं के कारण भी आवश्यक है।
कंप्यूटर दृष्टि में, 'विशेषताएं' किसी भी छवि की विशिष्ट विशेषताओं को संदर्भित करती हैं, न कि केवल चेहरों की। अपस्केलिंग एल्गोरिदम में प्रगति के साथ, कम-रिज़ॉल्यूशन निगरानी फुटेज को बढ़ाने के लिए विभिन्न विधियां प्रस्तावित की गई हैं, जो संभावित रूप से इसे अपराध स्थल जांच जैसे कानूनी उद्देश्यों के लिए उपयोगी बना सकती हैं।
हालांकि, गलत पहचान का जोखिम है, और आदर्श रूप से, चेहरा पहचान प्रणालियों को सटीक पहचान के लिए उच्च-रिज़ॉल्यूशन छवियों की आवश्यकता नहीं होनी चाहिए। ऐसी परिवर्तन महंगे हैं और उनकी वैधता और कानूनीता के बारे में सवाल उठाते हैं।
अधिक 'डाउन-एट-हील' सेलिब्रिटीज़ की आवश्यकता
यह अधिक लाभकारी होगा यदि चेहरा पहचान प्रणालियां पुराने सिस्टमों के आउटपुट से सीधे विशेषताओं को निकाल सकें बिना छवियों को परिवर्तित करने की आवश्यकता के। इसके लिए उच्च-रिज़ॉल्यूशन पहचानों और मौजूदा निगरानी सिस्टमों से प्राप्त खराब छवियों के बीच संबंध को बेहतर ढंग से समझने की आवश्यकता है।
समस्या मानकों में निहित है: MS-Celeb-1M और WebFace260M जैसे डेटासेट व्यापक रूप से उपयोग किए जाते हैं क्योंकि वे सुसंगत बेंचमार्क प्रदान करते हैं। हालांकि, लेखकों का तर्क है कि इन डेटासेट पर प्रशिक्षित चेहरा पहचान एल्गोरिदम पुराने निगरानी सिस्टमों के दृश्य डोमेन के लिए उपयुक्त नहीं हैं।
*माइक्रोसॉफ्ट के लोकप्रिय MS-Celeb1m डेटासेट से उदाहरण।* स्रोत: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
पेपर में उल्लेख किया गया है कि अत्याधुनिक चेहरा पहचान मॉडल वास्तविक दुनिया के निगरानी चित्रों के साथ डोमेन शिफ्ट समस्याओं के कारण संघर्ष करते हैं। ये मॉडल अर्ध-नियंत्रित डेटासेट पर प्रशिक्षित होते हैं जो वास्तविक दुनिया के परिदृश्यों में पाए जाने वाले बदलावों, जैसे सेंसर शोर और गति धुंधलापन, की कमी रखते हैं।
पिछली विधियों ने ऐतिहासिक या कम लागत वाले निगरानी सिस्टमों के आउटपुट से मेल खाने की कोशिश की है, लेकिन ये 'अंधा' वृद्धि थीं। इसके विपरीत, CFSM प्रशिक्षण के दौरान लक्ष्य प्रणाली से प्रत्यक्ष प्रतिक्रिया का उपयोग करता है और उस डोमेन की नकल करने के लिए शैली हस्तांतरण के माध्यम से अनुकूलन करता है।
*अभिनेत्री नटाली पोर्टमैन, जो कंप्यूटर दृष्टि समुदाय में प्रभुत्व रखने वाले कुछ डेटासेट से अपरिचित नहीं हैं, इस उदाहरण में CFSM द्वारा वास्तविक लक्ष्य मॉडल के डोमेन से प्रतिक्रिया के आधार पर शैली-मिलान डोमेन अनुकूलन करने वाली पहचानों में शामिल हैं।* स्रोत: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
लेखकों की वास्तुकला फास्ट ग्रेडिएंट साइन मेथड (FGSM) का उपयोग करती है ताकि लक्ष्य प्रणाली के आउटपुट से शैलियों और विशेषताओं को आयात किया जा सके। जैसे-जैसे प्रशिक्षण आगे बढ़ता है, पाइपलाइन का छवि जनन हिस्सा लक्ष्य प्रणाली के प्रति अधिक विश्वसनीय हो जाता है, जिससे चेहरा पहचान प्रदर्शन और सामान्यीकरण क्षमताओं में सुधार होता है।
परीक्षण और परिणाम
शोधकर्ताओं ने MSU के पूर्व कार्य को टेम्पलेट के रूप में उपयोग करके CFSM का परीक्षण किया, जिसमें MS-Celeb-1m और MS1M-V2 को प्रशिक्षण डेटासेट के रूप में उपयोग किया गया। लक्ष्य डेटा हांगकांग की चीनी यूनिवर्सिटी का WiderFace डेटासेट था, जो चुनौतीपूर्ण परिस्थितियों में चेहरा पहचान के लिए डिज़ाइन किया गया था।
सिस्टम का मूल्यांकन चार चेहरा पहचान बेंचमार्क के खिलाफ किया गया: IJB-B, IJB-C, IJB-S, और TinyFace। CFSM को MS-Celeb-1m डेटा के लगभग 10%, लगभग 0.4 मिलियन छवियों के साथ, 125,000 पुनरावृत्तियों के लिए 32 के बैच आकार के साथ Adam ऑप्टिमाइज़र का उपयोग करके 1e-4 की शिक्षण दर के साथ प्रशिक्षित किया गया था।
लक्ष्य चेहरा पहचान मॉडल ने ArcFace हानि फ़ंक्शन के साथ एक संशोधित ResNet-50 का उपयोग किया। तुलना के लिए CFSM के साथ एक अतिरिक्त मॉडल प्रशिक्षित किया गया, जिसे परिणामों में 'ArcFace' के रूप में लेबल किया गया।
*CFSM के लिए प्राथमिक परीक्षणों के परिणाम। उच्च संख्या बेहतर है।*
परिणामों ने दिखाया कि CFSM द्वारा उन्नत ArcFace मॉडल ने चेहरा पहचान और सत्यापन कार्यों में सभी आधार रेखाओं को पीछे छोड़ दिया, जिससे नया अत्याधुनिक प्रदर्शन प्राप्त हुआ।
पुराने निगरानी सिस्टमों की विभिन्न विशेषताओं से डोमेन निकालने की क्षमता भी इन सिस्टमों के बीच वितरण समानता की तुलना और मूल्यांकन करने की अनुमति देती है, प्रत्येक को एक दृश्य शैली के रूप में प्रस्तुत करती है जिसका उपयोग भविष्य के कार्य में किया जा सकता है।
*विभिन्न डेटासेट से उदाहरण स्पष्ट रूप से शैली में अंतर प्रदर्शित करते हैं।*
लेखकों ने यह भी नोट किया कि CFSM यह प्रदर्शित करता है कि दृष्टि कार्यों में पहचान सटीकता बढ़ाने के लिए प्रतिकूल हेरफेर का उपयोग कैसे किया जा सकता है। उन्होंने सीखे गए शैली आधारों पर आधारित एक डेटासेट समानता मीट्रिक पेश किया, जो लेबल या भविष्यवक्ता-निरपेक्ष तरीके से शैली अंतर को कैप्चर करता है।
शोध अनियंत्रित चेहरा पहचान के लिए नियंत्रणीय और निर्देशित चेहरा संश्लेषण मॉडल की क्षमता को रेखांकित करता है और डेटासेट अंतरों में अंतर्दृष्टि प्रदान करता है।










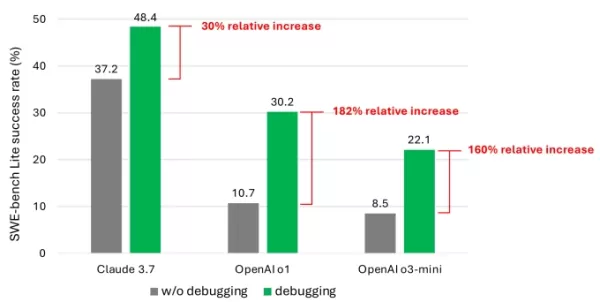 Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI, Anthropic और अन्य प्रमुख AI लैब्स के AI मॉडल कोडिंग कार्यों के लिए तेजी से उपयोग किए जा रहे हैं। Google CEO Sundar Pichai ने अक्टूबर में नोट किया कि AI कंपनी में 25% नए कोड जनरेट करता है, जबकि
AI-चालित समाधान वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकते हैं
लंदन स्कूल ऑफ इकोनॉमिक्स और सिस्टमिक के एक हालिया अध्ययन से पता चलता है कि कृत्रिम बुद्धिमत्ता (AI) आधुनिक सुविधाओं को त्यागे बिना वैश्विक कार्बन उत्सर्जन को काफी हद तक कम कर सकती है, जिससे AI जलवायु
 नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
27 अप्रैल 2025 1:28:26 अपराह्न IST
नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
27 अप्रैल 2025 1:28:26 अपराह्न IST
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
0
27 अप्रैल 2025 1:27:41 अपराह्न IST
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
0
27 अप्रैल 2025 1:57:32 पूर्वाह्न IST
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
0
26 अप्रैल 2025 9:49:01 अपराह्न IST
미시간 주립대 연구진이 하는 이 작업은 정말 멋져 보입니다. 인공 얼굴을 이용해 이미지 인식 기술을 개선하려는 목적 자체가 놀랍네요. 실용성 검증이 필요할 것 같아요. 😎💡
0
26 अप्रैल 2025 7:50:26 अपराह्न IST
合成顔を使って顔認識技術を向上させるなんて、素晴らしいアイデアだと思う!深偽ではなく、良い目的に使われる技術は嬉しいね。ただ、もう少し使いやすければ完璧だったのに。でも、革新性には拍手を送りたい!👏
0
26 अप्रैल 2025 6:30:27 अपराह्न IST
¡Es una idea muy interesante! Usar caras sintéticas para mejorar el reconocimiento facial parece un gran avance. Sin embargo, espero que no genere más problemas de privacidad. 🌟🤔
0













