
















 首頁
首頁“退化”合成面可能會增強面部識別技術
密西根州立大學的研究人員提出了一種創新方法,利用合成面孔提升圖像識別系統的準確性,服務於崇高目標。這些合成面孔並非助長深偽現象,而是模擬現實世界監控錄像中的缺陷。
研究團隊開發了可控面孔合成模組(CFSM),能以反映CCTV系統常見缺陷的風格重新生成面孔,如面部模糊、低解析度和感測器噪聲。此方法不同於使用來自熱門資料集的高品質名人圖像,後者無法捕捉面部識別系統面臨的現實挑戰。
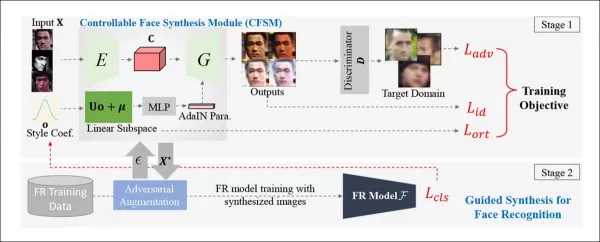 *可控面孔合成模組(CFSM)的概念架構。* 來源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*可控面孔合成模組(CFSM)的概念架構。* 來源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
不同於專注於複製頭部姿勢和表情的深偽系統,CFSM旨在透過風格轉換生成與目標識別系統風格匹配的替代視圖。此模組特別適用於因成本限制難以升級的舊系統,這些系統仍需為現代面部識別技術做出貢獻。
測試CFSM時,研究人員觀察到處理低品質數據的圖像識別系統顯著改進,還發現意外好處:能夠表徵和比較目標資料集,簡化基準測試和為各種CCTV系統創建定制資料集的過程。
 *訓練面部識別模型以適應目標系統的限制。* 來源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*訓練面部識別模型以適應目標系統的限制。* 來源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
此方法也可應用於現有資料集,進行領域適應,使其更適合面部識別。研究題為**可控與引導面孔合成用於無約束面部識別**,部分由美國國家情報總監辦公室(ODNI, at IARPA)資助,涉及密西根州立大學計算機科學與工程系的四位研究人員。
低品質面部識別:新興領域
過去幾年,低品質面部識別(LQFR)成為重要研究領域。許多舊的監控系統因耐用性設計而過時,因技術債務難以作為機器學習的有效數據來源。
 歷史與較新監控系統中面部解析度的不同層次。來源:https://arxiv.org/pdf/1805.11519.pdf
歷史與較新監控系統中面部解析度的不同層次。來源:https://arxiv.org/pdf/1805.11519.pdf
幸運的是,擴散模型和其他基於噪聲的模型適合解決此問題。許多最新圖像合成系統包括提升低解析度圖像的功能,這對神經壓縮技術也至關重要。
面部識別的挑戰在於以最少特徵從低解析度圖像中最大化準確性。這不僅適用於低解析度面部識別,也因訓練模型潛在空間的圖像尺寸限制而必要。
在計算機視覺中,“特徵”指的是任何圖像的顯著特徵,不僅限於面部。隨著上行演算法的進步,提出多種方法來增強低解析度監控錄像,使其可用於犯罪現場調查等法律用途。
然而,存在誤識別風險,理想情況下,面部識別系統不應需要高解析度圖像來實現準確識別。此類轉換成本高昂,且引發關於其有效性和合法性的問題。
需要更多“落魄”名人
若面部識別系統能直接從舊系統輸出中提取特徵而無需轉換圖像,將更具效益。這需要更好地理解高解析度身份與現有監控系統退化圖像之間的關係。
問題在於標準:MS-Celeb-1M和WebFace260M等資料集因提供一致基準而廣泛使用,但作者認為,基於這些資料集訓練的面部識別演算法不適合舊監控系統的視覺領域。
 *來自Microsoft熱門MS-Celeb1m資料集的範例。* 來源:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*來自Microsoft熱門MS-Celeb1m資料集的範例。* 來源:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
論文指出,由於領域轉移問題,最先進的面部識別模型在處理現實世界監控影像時表現不佳。這些模型基於半約束資料集訓練,缺乏現實場景中的變化,如感測器噪聲和運動模糊。
先前方法嘗試匹配歷史或低成本監控系統的輸出,但這些是“盲目”增強。相比之下,CFSM在訓練中利用目標系統的直接反饋,透過風格轉換適應該領域。
 *女演員娜塔莉·波特曼,常見於計算機視覺社群主導的少數資料集中,在此CFSM範例中,基於實際目標模型領域的反饋進行風格匹配的領域適應。*
*女演員娜塔莉·波特曼,常見於計算機視覺社群主導的少數資料集中,在此CFSM範例中,基於實際目標模型領域的反饋進行風格匹配的領域適應。*
作者的架構使用快速梯度符號法(FGSM)導入目標系統輸出的風格和特徵。隨著訓練進展,圖像生成部分對目標系統更加忠實,提升面部識別性能和泛化能力。
測試與結果
研究人員以密西根州立大學先前工作為模板,測試CFSM,使用MS-Celeb-1m和MS1M-V2作為訓練資料集。目標數據為香港中文大學的WiderFace資料集,專為挑戰性場景中的面部檢測設計。
系統針對四個面部識別基準進行評估:IJB-B、IJB-C、IJB-S和TinyFace。CFSM使用約10%的MS-Celeb-1m數據(約40萬張圖像),以批次大小32進行125,000次迭代,使用Adam優化器,學習率為1e-4。
目標面部識別模型使用修改後的ResNet-50,搭配ArcFace損失函數。另訓練一個CFSM模型進行比較,標記為“ArcFace”。
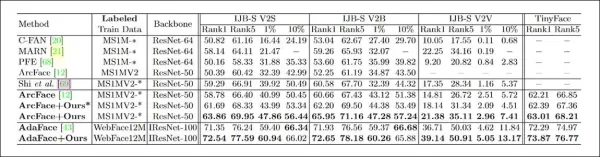 *CFSM主要測試結果。數字越高越好。*
*CFSM主要測試結果。數字越高越好。*
結果顯示,增強型ArcFace模型在面部識別和驗證任務中超越所有基準,達到新的最先進性能。
從舊監控系統各種特徵中提取領域的能力,還允許比較和評估這些系統的分布相似性,以視覺風格呈現,可在未來工作中利用。
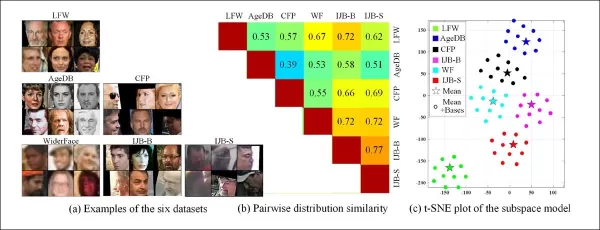 *不同資料集的範例顯示出明顯的風格差異。*
*不同資料集的範例顯示出明顯的風格差異。*
作者還指出,CFSM展示了对抗性操作如何用於提升視覺任務中的識別準確性。他們引入了基於學習風格基礎的資料集相似性度量,以不依賴標籤或預測器的方式捕捉風格差異。
研究強調了可控與引導面孔合成模型在無約束面部識別中的潛力,並提供了資料集差異的洞察。
相關文章
 以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。
人工智慧熱潮引發網路泡沫時期的泡沫憂慮
數十億美元湧入人工智慧領域的投資熱潮,引發一場激烈辯論:該產業是否正走向網路泡沫式的泡沫?投資者正密切關注熱潮是否降溫,或巨額晶片與基礎建設支出未能帶來預期回報的跡象。美銀全球研究近期調查凸顯此種謹慎態度:54%基金經理人認為人工智慧股票已處泡沫期,38%持反對意見。與網路泡沫的相似之處儘管樂觀情緒蔓延,質疑者仍質疑人工智慧的實質影響力,部分人士更直指其為虛張聲勢或即將破裂的泡沫。思科亞太、日本及
程序記憶降低人工智能代理成本和複雜性
由浙江大學和阿里巴巴集團共同研發的一項新技術為大型語言模型(LLM)代理提供了動態記憶,從而提高其處理複雜任務的效率和效能。這種方法被命名為 Memp,它為代理提供了一種 「程序記憶」,這種記憶會隨著代理積累的經驗不斷更新,這與人類通過重複練習學習的方式類似。 Memp 建立了一個終身學習的系統,在這個系統中,代理不再需要從零開始處理每一項新任務。當他們在真實世界環境中面對新的情境時,他們會穩步改
相關專題推薦
視頻創作
以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。
人工智慧熱潮引發網路泡沫時期的泡沫憂慮
數十億美元湧入人工智慧領域的投資熱潮,引發一場激烈辯論:該產業是否正走向網路泡沫式的泡沫?投資者正密切關注熱潮是否降溫,或巨額晶片與基礎建設支出未能帶來預期回報的跡象。美銀全球研究近期調查凸顯此種謹慎態度:54%基金經理人認為人工智慧股票已處泡沫期,38%持反對意見。與網路泡沫的相似之處儘管樂觀情緒蔓延,質疑者仍質疑人工智慧的實質影響力,部分人士更直指其為虛張聲勢或即將破裂的泡沫。思科亞太、日本及
程序記憶降低人工智能代理成本和複雜性
由浙江大學和阿里巴巴集團共同研發的一項新技術為大型語言模型(LLM)代理提供了動態記憶,從而提高其處理複雜任務的效率和效能。這種方法被命名為 Memp,它為代理提供了一種 「程序記憶」,這種記憶會隨著代理積累的經驗不斷更新,這與人類通過重複練習學習的方式類似。 Memp 建立了一個終身學習的系統,在這個系統中,代理不再需要從零開始處理每一項新任務。當他們在真實世界環境中面對新的情境時,他們會穩步改
相關專題推薦
視頻創作
 最適合劇本創作與視覺敘事的 AI 文字轉影片平台
最適合劇本創作與視覺敘事的 AI 文字轉影片平台
2026 年最新最佳 AI 文字轉影片平台:頂級劇本撰寫與視覺敘事工具。探索強大且顛覆傳統的解決方案,將您的文字轉化為引人入勝的影片。透過我們每週更新的排行榜與實際測試,比較免費與付費選項。找到最適合您的平台,提升創造力與生產力。立即探索 XIX.AI 精選推薦。
 10 個工具
10 個工具
 xix.ai
聊天機器人
AI多智慧體編排器:透過自然語言設計複雜的自動化工作流程
xix.ai
聊天機器人
AI多智慧體編排器:透過自然語言設計複雜的自動化工作流程
2026最新資訊:探索最優秀的人工智慧多智慧體協調工具,透過自然語言設計複雜的自動化工作流程。我們精心挑選的列表中包含了評分最高、功能強大的平臺,這些平臺能夠實現無縫的任務自動化和智慧化的流程管理。對比免費與付費選項,並瞭解實際應用中的效果。藉助XIX.AI每週更新的專家排名,讓你在人工智慧領域取得領先優勢。
10 個工具
xix.ai
圖像編輯
最佳AI降噪軟體:消除低光夜間攝影中的顆粒感和偽影
探索2026年最適合低光夜間攝影的AI降噪軟體。我們精心挑選了最受歡迎的免費及付費工具,透過實際測試並每週更新排名來進行對比。輕鬆去除影象中的顆粒感與瑕疵,在XIX.AI上釋放你的AI潛力。
10 個工具
xix.ai
聊天機器人
最佳客製化 AI 女友生成器:設計獨特的個性、興趣與背景故事
在 XIX.AI 探索 2026 年最佳的客製化 AI 女友生成器。瀏覽我們精心挑選的高評分清單,設計獨特的個性、興趣與深入的背景故事。透過實際使用心得,比較免費與付費選項。立即解鎖您完美的創意夥伴。
10 個工具
xix.ai
生產率
AI 架構設計師:運用自然語言建構可擴展的系統架構
立即在 XIX.AI 探索 2026 年最佳 AI 架構設計工具。我們精心挑選並廣受好評的清單,匯集了強大且具革命性的解決方案,讓您能透過自然語言建構可擴展的系統架構。透過實務見解,比較免費與付費選項的差異。立即釋放您的 AI 優勢,並簡化開發流程。
10 個工具
xix.ai
漫畫創作
AI角色建立工具:為漫畫主角生成詳細的背景故事及視覺參考資料
2026年最新最佳AI角色建立工具:發現那些備受好評的工具,它們能夠幫助你為漫畫角色生成詳細的背景故事和視覺素材。我們精心整理的這份每週更新的列表會根據實際測試結果,對比免費與付費選項的優劣。找到這些強大且能改變創作流程的工具,幫助你塑造引人入勝的角色,提升創作效率。立即訪問XIX.AI檢視排名,找到最適合你的故事創作助手吧。
10 個工具
xix.ai

 評論 (13)
0/500
評論 (13)
0/500
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
密西根州立大學的研究人員提出了一種創新方法,利用合成面孔提升圖像識別系統的準確性,服務於崇高目標。這些合成面孔並非助長深偽現象,而是模擬現實世界監控錄像中的缺陷。
研究團隊開發了可控面孔合成模組(CFSM),能以反映CCTV系統常見缺陷的風格重新生成面孔,如面部模糊、低解析度和感測器噪聲。此方法不同於使用來自熱門資料集的高品質名人圖像,後者無法捕捉面部識別系統面臨的現實挑戰。
*可控面孔合成模組(CFSM)的概念架構。* 來源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
不同於專注於複製頭部姿勢和表情的深偽系統,CFSM旨在透過風格轉換生成與目標識別系統風格匹配的替代視圖。此模組特別適用於因成本限制難以升級的舊系統,這些系統仍需為現代面部識別技術做出貢獻。
測試CFSM時,研究人員觀察到處理低品質數據的圖像識別系統顯著改進,還發現意外好處:能夠表徵和比較目標資料集,簡化基準測試和為各種CCTV系統創建定制資料集的過程。
*訓練面部識別模型以適應目標系統的限制。* 來源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
此方法也可應用於現有資料集,進行領域適應,使其更適合面部識別。研究題為**可控與引導面孔合成用於無約束面部識別**,部分由美國國家情報總監辦公室(ODNI, at IARPA)資助,涉及密西根州立大學計算機科學與工程系的四位研究人員。
低品質面部識別:新興領域
過去幾年,低品質面部識別(LQFR)成為重要研究領域。許多舊的監控系統因耐用性設計而過時,因技術債務難以作為機器學習的有效數據來源。
歷史與較新監控系統中面部解析度的不同層次。來源:https://arxiv.org/pdf/1805.11519.pdf
幸運的是,擴散模型和其他基於噪聲的模型適合解決此問題。許多最新圖像合成系統包括提升低解析度圖像的功能,這對神經壓縮技術也至關重要。
面部識別的挑戰在於以最少特徵從低解析度圖像中最大化準確性。這不僅適用於低解析度面部識別,也因訓練模型潛在空間的圖像尺寸限制而必要。
在計算機視覺中,“特徵”指的是任何圖像的顯著特徵,不僅限於面部。隨著上行演算法的進步,提出多種方法來增強低解析度監控錄像,使其可用於犯罪現場調查等法律用途。
然而,存在誤識別風險,理想情況下,面部識別系統不應需要高解析度圖像來實現準確識別。此類轉換成本高昂,且引發關於其有效性和合法性的問題。
需要更多“落魄”名人
若面部識別系統能直接從舊系統輸出中提取特徵而無需轉換圖像,將更具效益。這需要更好地理解高解析度身份與現有監控系統退化圖像之間的關係。
問題在於標準:MS-Celeb-1M和WebFace260M等資料集因提供一致基準而廣泛使用,但作者認為,基於這些資料集訓練的面部識別演算法不適合舊監控系統的視覺領域。
*來自Microsoft熱門MS-Celeb1m資料集的範例。* 來源:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
論文指出,由於領域轉移問題,最先進的面部識別模型在處理現實世界監控影像時表現不佳。這些模型基於半約束資料集訓練,缺乏現實場景中的變化,如感測器噪聲和運動模糊。
先前方法嘗試匹配歷史或低成本監控系統的輸出,但這些是“盲目”增強。相比之下,CFSM在訓練中利用目標系統的直接反饋,透過風格轉換適應該領域。
*女演員娜塔莉·波特曼,常見於計算機視覺社群主導的少數資料集中,在此CFSM範例中,基於實際目標模型領域的反饋進行風格匹配的領域適應。*
作者的架構使用快速梯度符號法(FGSM)導入目標系統輸出的風格和特徵。隨著訓練進展,圖像生成部分對目標系統更加忠實,提升面部識別性能和泛化能力。
測試與結果
研究人員以密西根州立大學先前工作為模板,測試CFSM,使用MS-Celeb-1m和MS1M-V2作為訓練資料集。目標數據為香港中文大學的WiderFace資料集,專為挑戰性場景中的面部檢測設計。
系統針對四個面部識別基準進行評估:IJB-B、IJB-C、IJB-S和TinyFace。CFSM使用約10%的MS-Celeb-1m數據(約40萬張圖像),以批次大小32進行125,000次迭代,使用Adam優化器,學習率為1e-4。
目標面部識別模型使用修改後的ResNet-50,搭配ArcFace損失函數。另訓練一個CFSM模型進行比較,標記為“ArcFace”。
*CFSM主要測試結果。數字越高越好。*
結果顯示,增強型ArcFace模型在面部識別和驗證任務中超越所有基準,達到新的最先進性能。
從舊監控系統各種特徵中提取領域的能力,還允許比較和評估這些系統的分布相似性,以視覺風格呈現,可在未來工作中利用。
*不同資料集的範例顯示出明顯的風格差異。*
作者還指出,CFSM展示了对抗性操作如何用於提升視覺任務中的識別準確性。他們引入了基於學習風格基礎的資料集相似性度量,以不依賴標籤或預測器的方式捕捉風格差異。
研究強調了可控與引導面孔合成模型在無約束面部識別中的潛力,並提供了資料集差異的洞察。










 以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。
以優化為驅動的人工智慧,正成為通用的模型發展新途徑
伊利諾大學厄巴納-香檳分校與維吉尼亞大學的研究人員開發出一種新型模型架構,有望為具備更強推理能力且更具韌性的AI系統鋪平道路。名為「能量基變壓器」(EBT)的架構,能自然運用推論時間擴展性來解決複雜挑戰。對企業而言,這意味著能以成本效益方式部署人工智慧應用,無需專門調校模型即可適應新情境。系統二思維的挑戰在心理學中,人類認知通常分為兩種模式:快速直覺的系統一,以及較緩慢、更刻意且具分析性的系統二。
 人工智慧熱潮引發網路泡沫時期的泡沫憂慮
數十億美元湧入人工智慧領域的投資熱潮,引發一場激烈辯論:該產業是否正走向網路泡沫式的泡沫?投資者正密切關注熱潮是否降溫,或巨額晶片與基礎建設支出未能帶來預期回報的跡象。美銀全球研究近期調查凸顯此種謹慎態度:54%基金經理人認為人工智慧股票已處泡沫期,38%持反對意見。與網路泡沫的相似之處儘管樂觀情緒蔓延,質疑者仍質疑人工智慧的實質影響力,部分人士更直指其為虛張聲勢或即將破裂的泡沫。思科亞太、日本及
人工智慧熱潮引發網路泡沫時期的泡沫憂慮
數十億美元湧入人工智慧領域的投資熱潮,引發一場激烈辯論:該產業是否正走向網路泡沫式的泡沫?投資者正密切關注熱潮是否降溫,或巨額晶片與基礎建設支出未能帶來預期回報的跡象。美銀全球研究近期調查凸顯此種謹慎態度:54%基金經理人認為人工智慧股票已處泡沫期,38%持反對意見。與網路泡沫的相似之處儘管樂觀情緒蔓延,質疑者仍質疑人工智慧的實質影響力,部分人士更直指其為虛張聲勢或即將破裂的泡沫。思科亞太、日本及
 程序記憶降低人工智能代理成本和複雜性
由浙江大學和阿里巴巴集團共同研發的一項新技術為大型語言模型(LLM)代理提供了動態記憶,從而提高其處理複雜任務的效率和效能。這種方法被命名為 Memp,它為代理提供了一種 「程序記憶」,這種記憶會隨著代理積累的經驗不斷更新,這與人類通過重複練習學習的方式類似。 Memp 建立了一個終身學習的系統,在這個系統中,代理不再需要從零開始處理每一項新任務。當他們在真實世界環境中面對新的情境時,他們會穩步改
程序記憶降低人工智能代理成本和複雜性
由浙江大學和阿里巴巴集團共同研發的一項新技術為大型語言模型(LLM)代理提供了動態記憶,從而提高其處理複雜任務的效率和效能。這種方法被命名為 Memp,它為代理提供了一種 「程序記憶」,這種記憶會隨著代理積累的經驗不斷更新,這與人類通過重複練習學習的方式類似。 Memp 建立了一個終身學習的系統,在這個系統中,代理不再需要從零開始處理每一項新任務。當他們在真實世界環境中面對新的情境時,他們會穩步改

2026 年最新最佳 AI 文字轉影片平台:頂級劇本撰寫與視覺敘事工具。探索強大且顛覆傳統的解決方案,將您的文字轉化為引人入勝的影片。透過我們每週更新的排行榜與實際測試,比較免費與付費選項。找到最適合您的平台,提升創造力與生產力。立即探索 XIX.AI 精選推薦。
10 個工具
xix.ai

2026最新資訊:探索最優秀的人工智慧多智慧體協調工具,透過自然語言設計複雜的自動化工作流程。我們精心挑選的列表中包含了評分最高、功能強大的平臺,這些平臺能夠實現無縫的任務自動化和智慧化的流程管理。對比免費與付費選項,並瞭解實際應用中的效果。藉助XIX.AI每週更新的專家排名,讓你在人工智慧領域取得領先優勢。
10 個工具
xix.ai

探索2026年最適合低光夜間攝影的AI降噪軟體。我們精心挑選了最受歡迎的免費及付費工具,透過實際測試並每週更新排名來進行對比。輕鬆去除影象中的顆粒感與瑕疵,在XIX.AI上釋放你的AI潛力。
10 個工具
xix.ai

在 XIX.AI 探索 2026 年最佳的客製化 AI 女友生成器。瀏覽我們精心挑選的高評分清單,設計獨特的個性、興趣與深入的背景故事。透過實際使用心得,比較免費與付費選項。立即解鎖您完美的創意夥伴。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 架構設計工具。我們精心挑選並廣受好評的清單,匯集了強大且具革命性的解決方案,讓您能透過自然語言建構可擴展的系統架構。透過實務見解,比較免費與付費選項的差異。立即釋放您的 AI 優勢,並簡化開發流程。
10 個工具
xix.ai

2026年最新最佳AI角色建立工具:發現那些備受好評的工具,它們能夠幫助你為漫畫角色生成詳細的背景故事和視覺素材。我們精心整理的這份每週更新的列表會根據實際測試結果,對比免費與付費選項的優劣。找到這些強大且能改變創作流程的工具,幫助你塑造引人入勝的角色,提升創作效率。立即訪問XIX.AI檢視排名,找到最適合你的故事創作助手吧。
10 個工具
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













