
















 Maison
Maison
Les visages synthétiques «dégradés» peuvent améliorer la technologie de reconnaissance faciale
Des chercheurs de l'Université d'État du Michigan ont mis au point une méthode innovante pour utiliser des visages synthétiques dans une noble cause : améliorer la précision des systèmes de reconnaissance d'images. Au lieu de contribuer au phénomène des deepfakes, ces visages synthétiques sont conçus pour imiter les imperfections présentes dans les séquences de surveillance vidéo du monde réel.
L'équipe a développé un Module de Synthèse de Visages Contrôlable (CFSM) capable de régénérer des visages dans un style reflétant les défauts typiques des systèmes de vidéosurveillance, tels que le flou facial, la basse résolution et le bruit des capteurs. Cette approche diffère de l'utilisation d'images de célébrités de haute qualité provenant de datasets populaires, qui ne capturent pas les défis du monde réel rencontrés par les systèmes de reconnaissance faciale.
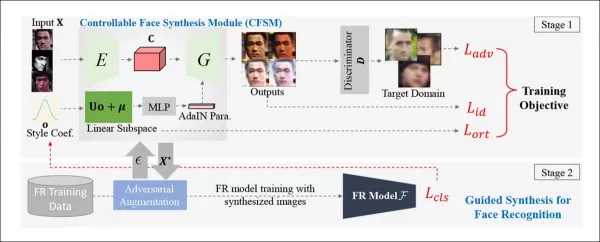 *Architecture conceptuelle du Module de Synthèse de Visages Contrôlable (CFSM).* Source : http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*Architecture conceptuelle du Module de Synthèse de Visages Contrôlable (CFSM).* Source : http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Contrairement aux systèmes de deepfake qui se concentrent sur la réplication des poses de tête et des expressions, le CFSM vise à générer des vues alternatives correspondant au style du système de reconnaissance cible grâce au transfert de style. Ce module est particulièrement utile pour s'adapter aux systèmes hérités qui ne seront probablement pas mis à niveau en raison de contraintes budgétaires, mais qui doivent néanmoins contribuer aux technologies modernes de reconnaissance faciale.
Lors des tests du CFSM, les chercheurs ont observé des améliorations significatives dans les systèmes de reconnaissance d'images traitant des données de basse qualité. Ils ont également découvert un avantage inattendu : la capacité à caractériser et comparer les datasets cibles, ce qui simplifie le processus d'évaluation comparative et de création de datasets adaptés à divers systèmes de vidéosurveillance.
 *Entraînement des modèles de reconnaissance faciale pour s'adapter aux limitations des systèmes cibles.* Source : http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*Entraînement des modèles de reconnaissance faciale pour s'adapter aux limitations des systèmes cibles.* Source : http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
La méthode peut également être appliquée aux datasets existants, effectuant une adaptation de domaine pour les rendre plus adaptés à la reconnaissance faciale. La recherche, intitulée **Synthèse de Visages Contrôlable et Guidée pour la Reconnaissance Faciale Non Contrôlée**, est partiellement soutenue par le Bureau du Directeur du Renseignement National des États-Unis (ODNI, à IARPA) et implique quatre chercheurs du département d'informatique et d'ingénierie de MSU.
Reconnaissance Faciale de Basse Qualité : Un Domaine en Croissance
Au cours des dernières années, la reconnaissance faciale de basse qualité (LQFR) est devenue un domaine d'étude important. De nombreux systèmes de vidéosurveillance plus anciens, conçus pour être durables et à longue durée de vie, sont devenus obsolètes et peinent à servir de sources de données efficaces pour l'apprentissage automatique en raison de la dette technique.
 Niveaux variables de résolution faciale à travers une gamme de systèmes de vidéosurveillance historiques et plus récents. Source : https://arxiv.org/pdf/1805.11519.pdf
Niveaux variables de résolution faciale à travers une gamme de systèmes de vidéosurveillance historiques et plus récents. Source : https://arxiv.org/pdf/1805.11519.pdf
Heureusement, les modèles de diffusion et autres modèles basés sur le bruit sont bien adaptés pour résoudre ce problème. De nombreux systèmes de synthèse d'images les plus récents incluent l'agrandissement d'images à basse résolution dans leur processus, ce qui est également crucial pour les techniques de compression neurale.
Le défi de la reconnaissance faciale est de maximiser la précision avec le moins de caractéristiques possibles extraites des images à basse résolution. Cela est non seulement utile pour identifier les visages à basse résolution, mais aussi nécessaire en raison des limitations de taille d'image dans l'espace latent des modèles d'entraînement.
En vision par ordinateur, les « caractéristiques » font référence aux traits distinctifs de n'importe quelle image, pas seulement des visages. Avec l'avancement des algorithmes d'agrandissement, diverses méthodes ont été proposées pour améliorer les séquences de surveillance à basse résolution, les rendant potentiellement utilisables à des fins légales comme les enquêtes sur les scènes de crime.
Cependant, il existe un risque d'erreur d'identification, et idéalement, les systèmes de reconnaissance faciale ne devraient pas nécessiter d'images à haute résolution pour effectuer des identifications précises. De telles transformations sont coûteuses et soulèvent des questions sur leur validité et leur légalité.
Le Besoin de Célébrités Plus « Usées »
Il serait plus bénéfique que les systèmes de reconnaissance faciale puissent extraire des caractéristiques directement à partir de la sortie des systèmes hérités sans avoir besoin de transformer les images. Cela nécessite une meilleure compréhension de la relation entre les identités à haute résolution et les images dégradées des systèmes de surveillance existants.
Le problème réside dans les normes : des datasets comme MS-Celeb-1M et WebFace260M sont largement utilisés car ils offrent des références cohérentes. Cependant, les auteurs soutiennent que les algorithmes de reconnaissance faciale entraînés sur ces datasets ne sont pas adaptés aux domaines visuels des systèmes de surveillance plus anciens.
 *Exemples du dataset populaire MS-Celeb1m de Microsoft.* Source : https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*Exemples du dataset populaire MS-Celeb1m de Microsoft.* Source : https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
Le document souligne que les modèles de reconnaissance faciale de pointe ont du mal avec les images de surveillance du monde réel en raison de problèmes de décalage de domaine. Ces modèles sont entraînés sur des datasets semi-contraints qui manquent des variations trouvées dans les scénarios réels, comme le bruit des capteurs et le flou de mouvement.
Les méthodes précédentes ont tenté de correspondre aux sorties des systèmes de surveillance historiques ou à faible coût, mais il s'agissait d'augmentations « aveugles ». En revanche, le CFSM utilise un retour direct du système cible pendant l'entraînement et s'adapte via un transfert de style pour imiter ce domaine.
 *L'actrice Natalie Portman, bien connue des quelques datasets qui dominent la communauté de la vision par ordinateur, figure parmi les identités dans cet exemple de CFSM effectuant une adaptation de domaine basée sur le style, en fonction du retour du domaine du modèle cible réel.*
*L'actrice Natalie Portman, bien connue des quelques datasets qui dominent la communauté de la vision par ordinateur, figure parmi les identités dans cet exemple de CFSM effectuant une adaptation de domaine basée sur le style, en fonction du retour du domaine du modèle cible réel.*
L'architecture des auteurs utilise la Méthode du Signe de Gradient Rapide (FGSM) pour importer les styles et les caractéristiques de la sortie du système cible. À mesure que l'entraînement progresse, la partie de génération d'images du pipeline devient plus fidèle au système cible, améliorant les performances de reconnaissance faciale et les capacités de généralisation.
Tests et Résultats
Les chercheurs ont testé le CFSM en utilisant les travaux antérieurs de MSU comme modèle, en employant MS-Celeb-1m et MS1M-V2 comme datasets d'entraînement. Les données cibles étaient le dataset WiderFace de l'Université chinoise de Hong Kong, conçu pour la détection de visages dans des situations difficiles.
Le système a été évalué par rapport à quatre benchmarks de reconnaissance faciale : IJB-B, IJB-C, IJB-S et TinyFace. Le CFSM a été entraîné avec environ 10 % des données de MS-Celeb-1m, soit environ 0,4 million d'images, pendant 125 000 itérations avec une taille de lot de 32, en utilisant l'optimiseur Adam avec un taux d'apprentissage de 1e-4.
Le modèle de reconnaissance faciale cible utilisait un ResNet-50 modifié avec une fonction de perte ArcFace. Un modèle supplémentaire a été entraîné avec le CFSM pour comparaison, étiqueté comme « ArcFace » dans les résultats.
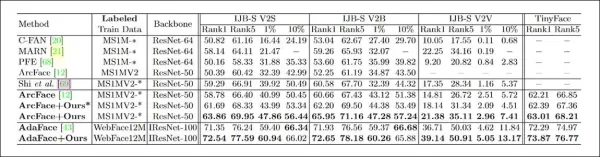 *Résultats des tests principaux pour le CFSM. Des nombres plus élevés sont préférables.*
*Résultats des tests principaux pour le CFSM. Des nombres plus élevés sont préférables.*
Les résultats ont montré que le modèle ArcFace, amélioré par le CFSM, a surpassé toutes les références dans les tâches d'identification et de vérification des visages, atteignant une performance de pointe.
La capacité à extraire des domaines à partir de diverses caractéristiques des systèmes de surveillance hérités permet également de comparer et d'évaluer la similarité de distribution parmi ces systèmes, en les présentant chacun en termes de style visuel qui peut être exploité dans les travaux futurs.
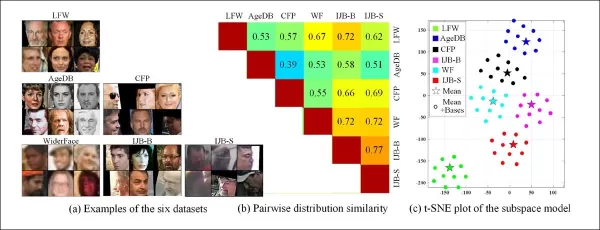 *Exemples de divers datasets montrent des différences claires de style.*
*Exemples de divers datasets montrent des différences claires de style.*
Les auteurs ont également noté que le CFSM démontre comment la manipulation adversariale peut être utilisée pour augmenter la précision de la reconnaissance dans les tâches de vision. Ils ont introduit une métrique de similarité de dataset basée sur des bases de style apprises, capturant les différences de style de manière agnostique par rapport aux étiquettes ou aux prédicteurs.
La recherche souligne le potentiel des modèles de synthèse de visages contrôlables et guidés pour la reconnaissance faciale non contrainte et fournit des insights sur les différences entre datasets.
Article connexe
 L'IA axée sur l'optimisation apparaît comme une nouvelle voie vers des modèles à usage général
Des chercheurs de l'université de l'Illinois à Urbana-Champaign et de l'université de Virginie ont créé une nouvelle architecture de modèle qui pourrait ouvrir la voie à des systèmes d'IA plus résilie
Le boom de l'IA fait écho aux inquiétudes liées à la bulle Internet
L'afflux d'investissements de plusieurs milliards de dollars dans l'IA a alimenté un débat houleux : le secteur se dirige-t-il vers une bulle spéculative similaire à celle des dot-com ?Les investisseu
La mémoire procédurale réduit les coûts et la complexité des agents d'IA
Une nouvelle technique mise au point par l'université de Zhejiang et le groupe Alibaba dote les agents de grands modèles de langage (LLM) d'une mémoire dynamique, ce qui accroît leur efficacité dans l
Recommandations de sujets spéciaux liés
Création de bande dessinée
L'IA axée sur l'optimisation apparaît comme une nouvelle voie vers des modèles à usage général
Des chercheurs de l'université de l'Illinois à Urbana-Champaign et de l'université de Virginie ont créé une nouvelle architecture de modèle qui pourrait ouvrir la voie à des systèmes d'IA plus résilie
Le boom de l'IA fait écho aux inquiétudes liées à la bulle Internet
L'afflux d'investissements de plusieurs milliards de dollars dans l'IA a alimenté un débat houleux : le secteur se dirige-t-il vers une bulle spéculative similaire à celle des dot-com ?Les investisseu
La mémoire procédurale réduit les coûts et la complexité des agents d'IA
Une nouvelle technique mise au point par l'université de Zhejiang et le groupe Alibaba dote les agents de grands modèles de langage (LLM) d'une mémoire dynamique, ce qui accroît leur efficacité dans l
Recommandations de sujets spéciaux liés
Création de bande dessinée
 Créateurs de profils de personnages AI : générer des histoires de fond détaillées et des références visuelles pour les personnages principaux des mangas
Créateurs de profils de personnages AI : générer des histoires de fond détaillées et des références visuelles pour les personnages principaux des mangas
2026 : Les meilleurs outils pour créer des profils de personnages AI : Découvrez des outils hautement réputés qui vous permettent de générer des histoires détaillées et des références visuelles pour vos personnages principaux dans les mangas. Notre liste, mise à jour chaque semaine, compare les options gratuites et payantes sur la base d’essais réels. Trouvez des solutions puissantes qui transformeront votre processus créatif et vous aideront à créer des personnages captivants. Explorez le classement sur XIX.AI et découvrez dès aujourd’hui l’allié idéal pour votre narration.
 10 outils
10 outils
 xix.ai
Santé et bien-être
Assistants IA pour la grossesse : créez des programmes d'entraînement et de nutrition sûrs, adaptés à chaque trimestre
xix.ai
Santé et bien-être
Assistants IA pour la grossesse : créez des programmes d'entraînement et de nutrition sûrs, adaptés à chaque trimestre
Découvrez les meilleurs assistants de grossesse basés sur l'IA pour 2026, qui vous proposent des programmes d'entraînement et des plans nutritionnels personnalisés et sans risque, trimestre par trimestre. Bénéficiez de recommandations triées sur le volet et très bien notées, accompagnées de comparaisons entre les options gratuites et payantes ainsi que d'avis concrets. Vivez une grossesse en pleine forme grâce au guide d'experts de XIX.AI. Découvrez-le dès maintenant.
10 outils
xix.ai
en écrivant
Les meilleurs outils gratuits d'écriture IA indétectables : transformez des brouillons robotiques en textes naturels, dignes d'un humain
Découvrez les meilleurs générateurs de texte IA gratuits et indétectables de 2026 sur XIX.AI. Notre sélection rigoureuse des meilleurs outils vous aide à transformer des brouillons robotiques en textes naturels, dignes d'un humain. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance en matière de rédaction IA.
10 outils
xix.ai
Édition d'images
Generateurs d'art par intelligence artificielle pour storyboards de courts drames : personnages de fantasy et de romance urbaine
2026 : Découvrez les meilleurs générateurs d’art artificiel pour les storyboards de courts métrages. Notre liste sélectionnée présente des outils hautement réputés pour créer des personnages captivants dans les genres fantasy et romance urbaine. Comparez les options gratuites et payantes, consultez les résultats de tests réels et trouvez le partenaire créatif idéal pour vous. Recevez chaque semaine des classements mis à jour et des conseils d’experts de XIX.AI. Commencez dès aujourd’hui à visualiser votre histoire !
10 outils
xix.ai
en écrivant
Meilleurs outils d’scriptage AI pour la radio et la production de podcasts : rédiger des publicités audio captivantes
Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
10 outils
xix.ai
Entreprise
Le meilleur logiciel d'analyse de contrats basé sur l'IA : identifiez instantanément les failles juridiques et les risques de non-conformité
Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai

 commentaires (13)
commentaires (13)
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
Des chercheurs de l'Université d'État du Michigan ont mis au point une méthode innovante pour utiliser des visages synthétiques dans une noble cause : améliorer la précision des systèmes de reconnaissance d'images. Au lieu de contribuer au phénomène des deepfakes, ces visages synthétiques sont conçus pour imiter les imperfections présentes dans les séquences de surveillance vidéo du monde réel.
L'équipe a développé un Module de Synthèse de Visages Contrôlable (CFSM) capable de régénérer des visages dans un style reflétant les défauts typiques des systèmes de vidéosurveillance, tels que le flou facial, la basse résolution et le bruit des capteurs. Cette approche diffère de l'utilisation d'images de célébrités de haute qualité provenant de datasets populaires, qui ne capturent pas les défis du monde réel rencontrés par les systèmes de reconnaissance faciale.
*Architecture conceptuelle du Module de Synthèse de Visages Contrôlable (CFSM).* Source : http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Contrairement aux systèmes de deepfake qui se concentrent sur la réplication des poses de tête et des expressions, le CFSM vise à générer des vues alternatives correspondant au style du système de reconnaissance cible grâce au transfert de style. Ce module est particulièrement utile pour s'adapter aux systèmes hérités qui ne seront probablement pas mis à niveau en raison de contraintes budgétaires, mais qui doivent néanmoins contribuer aux technologies modernes de reconnaissance faciale.
Lors des tests du CFSM, les chercheurs ont observé des améliorations significatives dans les systèmes de reconnaissance d'images traitant des données de basse qualité. Ils ont également découvert un avantage inattendu : la capacité à caractériser et comparer les datasets cibles, ce qui simplifie le processus d'évaluation comparative et de création de datasets adaptés à divers systèmes de vidéosurveillance.
*Entraînement des modèles de reconnaissance faciale pour s'adapter aux limitations des systèmes cibles.* Source : http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
La méthode peut également être appliquée aux datasets existants, effectuant une adaptation de domaine pour les rendre plus adaptés à la reconnaissance faciale. La recherche, intitulée **Synthèse de Visages Contrôlable et Guidée pour la Reconnaissance Faciale Non Contrôlée**, est partiellement soutenue par le Bureau du Directeur du Renseignement National des États-Unis (ODNI, à IARPA) et implique quatre chercheurs du département d'informatique et d'ingénierie de MSU.
Reconnaissance Faciale de Basse Qualité : Un Domaine en Croissance
Au cours des dernières années, la reconnaissance faciale de basse qualité (LQFR) est devenue un domaine d'étude important. De nombreux systèmes de vidéosurveillance plus anciens, conçus pour être durables et à longue durée de vie, sont devenus obsolètes et peinent à servir de sources de données efficaces pour l'apprentissage automatique en raison de la dette technique.
Niveaux variables de résolution faciale à travers une gamme de systèmes de vidéosurveillance historiques et plus récents. Source : https://arxiv.org/pdf/1805.11519.pdf
Heureusement, les modèles de diffusion et autres modèles basés sur le bruit sont bien adaptés pour résoudre ce problème. De nombreux systèmes de synthèse d'images les plus récents incluent l'agrandissement d'images à basse résolution dans leur processus, ce qui est également crucial pour les techniques de compression neurale.
Le défi de la reconnaissance faciale est de maximiser la précision avec le moins de caractéristiques possibles extraites des images à basse résolution. Cela est non seulement utile pour identifier les visages à basse résolution, mais aussi nécessaire en raison des limitations de taille d'image dans l'espace latent des modèles d'entraînement.
En vision par ordinateur, les « caractéristiques » font référence aux traits distinctifs de n'importe quelle image, pas seulement des visages. Avec l'avancement des algorithmes d'agrandissement, diverses méthodes ont été proposées pour améliorer les séquences de surveillance à basse résolution, les rendant potentiellement utilisables à des fins légales comme les enquêtes sur les scènes de crime.
Cependant, il existe un risque d'erreur d'identification, et idéalement, les systèmes de reconnaissance faciale ne devraient pas nécessiter d'images à haute résolution pour effectuer des identifications précises. De telles transformations sont coûteuses et soulèvent des questions sur leur validité et leur légalité.
Le Besoin de Célébrités Plus « Usées »
Il serait plus bénéfique que les systèmes de reconnaissance faciale puissent extraire des caractéristiques directement à partir de la sortie des systèmes hérités sans avoir besoin de transformer les images. Cela nécessite une meilleure compréhension de la relation entre les identités à haute résolution et les images dégradées des systèmes de surveillance existants.
Le problème réside dans les normes : des datasets comme MS-Celeb-1M et WebFace260M sont largement utilisés car ils offrent des références cohérentes. Cependant, les auteurs soutiennent que les algorithmes de reconnaissance faciale entraînés sur ces datasets ne sont pas adaptés aux domaines visuels des systèmes de surveillance plus anciens.
*Exemples du dataset populaire MS-Celeb1m de Microsoft.* Source : https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
Le document souligne que les modèles de reconnaissance faciale de pointe ont du mal avec les images de surveillance du monde réel en raison de problèmes de décalage de domaine. Ces modèles sont entraînés sur des datasets semi-contraints qui manquent des variations trouvées dans les scénarios réels, comme le bruit des capteurs et le flou de mouvement.
Les méthodes précédentes ont tenté de correspondre aux sorties des systèmes de surveillance historiques ou à faible coût, mais il s'agissait d'augmentations « aveugles ». En revanche, le CFSM utilise un retour direct du système cible pendant l'entraînement et s'adapte via un transfert de style pour imiter ce domaine.
*L'actrice Natalie Portman, bien connue des quelques datasets qui dominent la communauté de la vision par ordinateur, figure parmi les identités dans cet exemple de CFSM effectuant une adaptation de domaine basée sur le style, en fonction du retour du domaine du modèle cible réel.*
L'architecture des auteurs utilise la Méthode du Signe de Gradient Rapide (FGSM) pour importer les styles et les caractéristiques de la sortie du système cible. À mesure que l'entraînement progresse, la partie de génération d'images du pipeline devient plus fidèle au système cible, améliorant les performances de reconnaissance faciale et les capacités de généralisation.
Tests et Résultats
Les chercheurs ont testé le CFSM en utilisant les travaux antérieurs de MSU comme modèle, en employant MS-Celeb-1m et MS1M-V2 comme datasets d'entraînement. Les données cibles étaient le dataset WiderFace de l'Université chinoise de Hong Kong, conçu pour la détection de visages dans des situations difficiles.
Le système a été évalué par rapport à quatre benchmarks de reconnaissance faciale : IJB-B, IJB-C, IJB-S et TinyFace. Le CFSM a été entraîné avec environ 10 % des données de MS-Celeb-1m, soit environ 0,4 million d'images, pendant 125 000 itérations avec une taille de lot de 32, en utilisant l'optimiseur Adam avec un taux d'apprentissage de 1e-4.
Le modèle de reconnaissance faciale cible utilisait un ResNet-50 modifié avec une fonction de perte ArcFace. Un modèle supplémentaire a été entraîné avec le CFSM pour comparaison, étiqueté comme « ArcFace » dans les résultats.
*Résultats des tests principaux pour le CFSM. Des nombres plus élevés sont préférables.*
Les résultats ont montré que le modèle ArcFace, amélioré par le CFSM, a surpassé toutes les références dans les tâches d'identification et de vérification des visages, atteignant une performance de pointe.
La capacité à extraire des domaines à partir de diverses caractéristiques des systèmes de surveillance hérités permet également de comparer et d'évaluer la similarité de distribution parmi ces systèmes, en les présentant chacun en termes de style visuel qui peut être exploité dans les travaux futurs.
*Exemples de divers datasets montrent des différences claires de style.*
Les auteurs ont également noté que le CFSM démontre comment la manipulation adversariale peut être utilisée pour augmenter la précision de la reconnaissance dans les tâches de vision. Ils ont introduit une métrique de similarité de dataset basée sur des bases de style apprises, capturant les différences de style de manière agnostique par rapport aux étiquettes ou aux prédicteurs.
La recherche souligne le potentiel des modèles de synthèse de visages contrôlables et guidés pour la reconnaissance faciale non contrainte et fournit des insights sur les différences entre datasets.










 L'IA axée sur l'optimisation apparaît comme une nouvelle voie vers des modèles à usage général
Des chercheurs de l'université de l'Illinois à Urbana-Champaign et de l'université de Virginie ont créé une nouvelle architecture de modèle qui pourrait ouvrir la voie à des systèmes d'IA plus résilie
L'IA axée sur l'optimisation apparaît comme une nouvelle voie vers des modèles à usage général
Des chercheurs de l'université de l'Illinois à Urbana-Champaign et de l'université de Virginie ont créé une nouvelle architecture de modèle qui pourrait ouvrir la voie à des systèmes d'IA plus résilie
 Le boom de l'IA fait écho aux inquiétudes liées à la bulle Internet
L'afflux d'investissements de plusieurs milliards de dollars dans l'IA a alimenté un débat houleux : le secteur se dirige-t-il vers une bulle spéculative similaire à celle des dot-com ?Les investisseu
Le boom de l'IA fait écho aux inquiétudes liées à la bulle Internet
L'afflux d'investissements de plusieurs milliards de dollars dans l'IA a alimenté un débat houleux : le secteur se dirige-t-il vers une bulle spéculative similaire à celle des dot-com ?Les investisseu
 La mémoire procédurale réduit les coûts et la complexité des agents d'IA
Une nouvelle technique mise au point par l'université de Zhejiang et le groupe Alibaba dote les agents de grands modèles de langage (LLM) d'une mémoire dynamique, ce qui accroît leur efficacité dans l
La mémoire procédurale réduit les coûts et la complexité des agents d'IA
Une nouvelle technique mise au point par l'université de Zhejiang et le groupe Alibaba dote les agents de grands modèles de langage (LLM) d'une mémoire dynamique, ce qui accroît leur efficacité dans l

2026 : Les meilleurs outils pour créer des profils de personnages AI : Découvrez des outils hautement réputés qui vous permettent de générer des histoires détaillées et des références visuelles pour vos personnages principaux dans les mangas. Notre liste, mise à jour chaque semaine, compare les options gratuites et payantes sur la base d’essais réels. Trouvez des solutions puissantes qui transformeront votre processus créatif et vous aideront à créer des personnages captivants. Explorez le classement sur XIX.AI et découvrez dès aujourd’hui l’allié idéal pour votre narration.
10 outils
xix.ai

Découvrez les meilleurs assistants de grossesse basés sur l'IA pour 2026, qui vous proposent des programmes d'entraînement et des plans nutritionnels personnalisés et sans risque, trimestre par trimestre. Bénéficiez de recommandations triées sur le volet et très bien notées, accompagnées de comparaisons entre les options gratuites et payantes ainsi que d'avis concrets. Vivez une grossesse en pleine forme grâce au guide d'experts de XIX.AI. Découvrez-le dès maintenant.
10 outils
xix.ai

Découvrez les meilleurs générateurs de texte IA gratuits et indétectables de 2026 sur XIX.AI. Notre sélection rigoureuse des meilleurs outils vous aide à transformer des brouillons robotiques en textes naturels, dignes d'un humain. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Prenez dès aujourd'hui une longueur d'avance en matière de rédaction IA.
10 outils
xix.ai

2026 : Découvrez les meilleurs générateurs d’art artificiel pour les storyboards de courts métrages. Notre liste sélectionnée présente des outils hautement réputés pour créer des personnages captivants dans les genres fantasy et romance urbaine. Comparez les options gratuites et payantes, consultez les résultats de tests réels et trouvez le partenaire créatif idéal pour vous. Recevez chaque semaine des classements mis à jour et des conseils d’experts de XIX.AI. Commencez dès aujourd’hui à visualiser votre histoire !
10 outils
xix.ai

Découvrez les 20 meilleurs outils de scriptage AI pour la radio et la production de podcasts en 2026 sur XIX.AI. Notre liste, soigneusement sélectionnée et hautement réputée, propose des solutions puissantes et révolutionnaires pour créer rapidement des publicités audio captivantes. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mises à jour chaque semaine. Développez votre potentiel créatif dès aujourd’hui !
10 outils
xix.ai

Découvrez les meilleurs logiciels d'analyse de contrats basés sur l'IA pour 2026 sur XIX.AI. Notre sélection triée sur le volet et très bien notée regroupe des outils performants qui détectent instantanément les failles juridiques et les risques de non-conformité. Comparez les options gratuites et payantes grâce à des tests concrets et à des classements mis à jour chaque semaine. Trouvez la solution qui changera la donne pour une analyse de contrats sécurisée et efficace. Découvrez dès maintenant le guide complet.
10 outils
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













