
















 Дом
Дом«Униженные» синтетические лица могут улучшить технологию распознавания лиц
Исследователи Университета штата Мичиган разработали инновационный способ использования синтетических лиц для благородной цели — повышения точности систем распознавания изображений. Вместо способствования феномену дипфейков, эти синтетические лица созданы для имитации несовершенств, встречающихся в реальных видеозаписях с камер наблюдения.
Команда разработала модуль контролируемого синтеза лиц (CFSM), который может генерировать лица в стиле, отражающем типичные дефекты систем видеонаблюдения, такие как размытость лиц, низкое разрешение и шум датчиков. Этот подход отличается от использования высококачественных изображений знаменитостей из популярных наборов данных, которые не отражают реальных проблем, с которыми сталкиваются системы распознавания лиц.
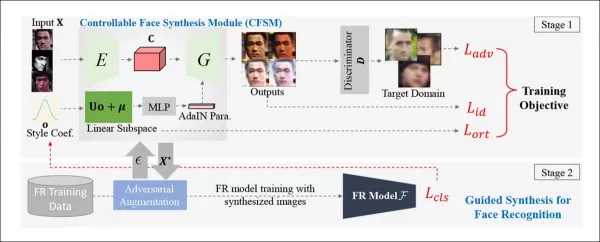 *Концептуальная архитектура модуля контролируемого синтеза лиц (CFSM).* Источник: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*Концептуальная архитектура модуля контролируемого синтеза лиц (CFSM).* Источник: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
В отличие от систем дипфейков, которые сосредоточены на воспроизведении поз головы и выражений, CFSM стремится генерировать альтернативные виды, соответствующие стилю целевой системы распознавания через перенос стиля. Этот модуль особенно полезен для адаптации к устаревшим системам, которые вряд ли будут модернизированы из-за ограничений бюджета, но всё ещё должны поддерживать современные технологии распознавания лиц.
При тестировании CFSM исследователи отметили значительные улучшения в системах распознавания изображений, работающих с данными низкого качества. Они также обнаружили неожиданное преимущество: возможность характеризовать и сравнивать целевые наборы данных, что упрощает процесс бенчмаркинга и создания специализированных наборов данных для различных систем видеонаблюдения.
 *Обучение моделей распознавания лиц для адаптации к ограничениям целевых систем.* Источник: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*Обучение моделей распознавания лиц для адаптации к ограничениям целевых систем.* Источник: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
Этот метод также может быть применён к существующим наборам данных, эффективно выполняя адаптацию домена, чтобы сделать их более подходящими для распознавания лиц. Исследование, озаглавленное **Контролируемый и направляемый синтез лиц для неограниченного распознавания лиц**, частично поддержано Управлением директора национальной разведки США (ODNI, в IARPA) и включает четырёх исследователей из департамента компьютерных наук и инженерии MSU.
Распознавание лиц низкого качества: растущая область
За последние несколько лет распознавание лиц низкого качества (LQFR) стало важной областью исследований. Многие старые системы видеонаблюдения, созданные для долговечности, устарели и с трудом служат эффективными источниками данных для машинного обучения из-за технического долга.
 Различные уровни разрешения лиц в диапазоне исторических и более современных систем видеонаблюдения. Источник: https://arxiv.org/pdf/1805.11519.pdf
Различные уровни разрешения лиц в диапазоне исторических и более современных систем видеонаблюдения. Источник: https://arxiv.org/pdf/1805.11519.pdf
К счастью, диффузионные модели и другие модели, основанные на шуме, хорошо подходят для решения этой проблемы. Многие из последних систем синтеза изображений включают масштабирование изображений низкого разрешения в свой процесс, что также важно для техник нейронной компрессии.
Задача распознавания лиц заключается в максимизации точности при минимальном количестве признаков, извлечённых из изображений низкого разрешения. Это полезно не только для идентификации лиц при низком разрешении, но и необходимо из-за ограничений на размер изображений в латентном пространстве обучающих моделей.
В компьютерном зрении «признаки» означают отличительные характеристики любого изображения, а не только лиц. С развитием алгоритмов масштабирования предложены различные методы для улучшения видеозаписей низкого разрешения, что потенциально делает их пригодными для юридических целей, таких как расследование мест преступлений.
Однако существует риск ошибочной идентификации, и в идеале системы распознавания лиц не должны требовать изображений высокого разрешения для точной идентификации. Такие преобразования дорогостоящи и вызывают вопросы о их достоверности и законности.
Потребность в более «потрёпанных» знаменитостях
Было бы полезнее, если бы системы распознавания лиц могли извлекать признаки непосредственно из выходных данных устаревших систем без необходимости преобразования изображений. Это требует лучшего понимания связи между идентичностями высокого разрешения и деградированными изображениями из существующих систем наблюдения.
Проблема заключается в стандартах: наборы данных, такие как MS-Celeb-1M и WebFace260M, широко используются, поскольку предоставляют согласованные эталоны. Однако авторы утверждают, что алгоритмы распознавания лиц, обученные на этих наборах данных, не подходят для визуальных доменов старых систем наблюдения.
 *Примеры из популярного набора данных MS-Celeb1m от Microsoft.* Источник: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*Примеры из популярного набора данных MS-Celeb1m от Microsoft.* Источник: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
В статье подчёркивается, что современные модели распознавания лиц сталкиваются с трудностями при работе с реальными изображениями видеонаблюдения из-за проблем смещения домена. Эти модели обучены на частично ограниченных наборах данных, которые не содержат вариаций, встречающихся в реальных сценариях, таких как шум датчиков и размытие движения.
Предыдущие методы пытались соответствовать выходным данным исторических или недорогих систем наблюдения, но это были «слепые» дополнения. В отличие от них, CFSM использует прямую обратную связь от целевой системы во время обучения и адаптируется через перенос стиля, чтобы имитировать этот домен.
 *Актриса Натали Портман, хорошо знакомая с несколькими наборами данных, доминирующими в сообществе компьютерного зрения, фигурирует среди идентичностей в этом примере CFSM, выполняющего адаптацию домена с учётом стиля на основе обратной связи от домена целевой модели.*
*Актриса Натали Портман, хорошо знакомая с несколькими наборами данных, доминирующими в сообществе компьютерного зрения, фигурирует среди идентичностей в этом примере CFSM, выполняющего адаптацию домена с учётом стиля на основе обратной связи от домена целевой модели.*
Архитектура авторов использует метод быстрого градиентного знака (FGSM) для импорта стилей и характеристик из выходных данных целевой системы. По мере обучения часть генерации изображений становится более точной по отношению к целевой системе, улучшая производительность распознавания лиц и возможности обобщения.
Тесты и результаты
Исследователи протестировали CFSM, используя предыдущие работы MSU в качестве шаблона, с наборами данных MS-Celeb-1m и MS1M-V2 для обучения. Целевые данные представляли собой набор WiderFace от Китайского университета Гонконга, предназначенный для обнаружения лиц в сложных условиях.
Система была оценена по четырём эталонам распознавания лиц: IJB-B, IJB-C, IJB-S и TinyFace. CFSM обучался на примерно 10% данных MS-Celeb-1m, около 0,4 миллиона изображений, в течение 125 000 итераций с размером пакета 32, используя оптимизатор Adam с шагом обучения 1e-4.
Целевая модель распознавания лиц использовала модифицированный ResNet-50 с функцией потерь ArcFace. Дополнительная модель была обучена с CFSM для сравнения, обозначенная как «ArcFace» в результатах.
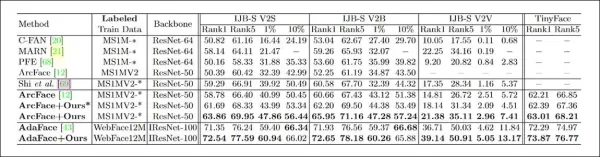 *Результаты основных тестов для CFSM. Более высокие значения лучше.*
*Результаты основных тестов для CFSM. Более высокие значения лучше.*
Результаты показали, что модель ArcFace, улучшенная с помощью CFSM, превзошла все базовые показатели как в задачах идентификации, так и в верификации лиц, достигнув нового уровня производительности.
Способность извлекать домены из различных характеристик устаревших систем наблюдения также позволяет сравнивать и оценивать сходство распределений среди этих систем, представляя каждую в терминах визуального стиля, который может быть использован в будущих работах.
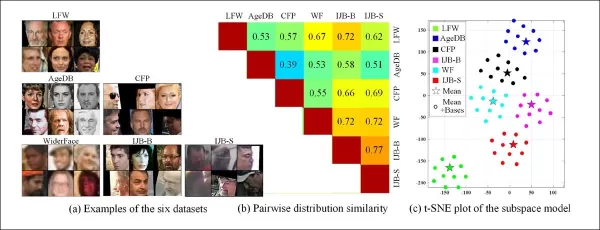 *Примеры из различных наборов данных демонстрируют явные различия в стиле.*
*Примеры из различных наборов данных демонстрируют явные различия в стиле.*
Авторы также отметили, что CFSM демонстрирует, как адверсарная манипуляция может быть использована для повышения точности распознавания в задачах компьютерного зрения. Они ввели метрику сходства наборов данных, основанную на изученных стилевых базах, фиксирующую различия в стиле независимо от меток или предикторов.
Исследование подчёркивает потенциал моделей контролируемого и направляемого синтеза лиц для неограниченного распознавания лиц и предоставляет понимание различий между наборами данных.
Связанная статья
 Оптимизация-ориентированный ИИ становится новым путем к универсальным моделям
Исследователи из Университета Иллинойса в Урбана-Шампейне и Университета Вирджинии создали новую архитектуру модели, которая может открыть путь к созданию более устойчивых систем искусственного интелл
Бум искусственного интеллекта вызывает опасения, напоминающие пузырь эпохи доткомов
Приток многомиллиардных инвестиций в искусственный интеллект вызвал бурную дискуссию: не грозит ли отрасли пузырь, подобный тому, что был в сфере интернет-компаний?Инвесторы внимательно следят за любы
Процедурная память снижает затраты и сложность агентов ИИ
Новая методика, разработанная Чжэцзянским университетом и Alibaba Group, наделяет агентов с большой языковой моделью (LLM) динамической памятью, что повышает их эффективность и результативность при ре
Рекомендации по связанным специальным темам
Создание комиксов
Оптимизация-ориентированный ИИ становится новым путем к универсальным моделям
Исследователи из Университета Иллинойса в Урбана-Шампейне и Университета Вирджинии создали новую архитектуру модели, которая может открыть путь к созданию более устойчивых систем искусственного интелл
Бум искусственного интеллекта вызывает опасения, напоминающие пузырь эпохи доткомов
Приток многомиллиардных инвестиций в искусственный интеллект вызвал бурную дискуссию: не грозит ли отрасли пузырь, подобный тому, что был в сфере интернет-компаний?Инвесторы внимательно следят за любы
Процедурная память снижает затраты и сложность агентов ИИ
Новая методика, разработанная Чжэцзянским университетом и Alibaba Group, наделяет агентов с большой языковой моделью (LLM) динамической памятью, что повышает их эффективность и результативность при ре
Рекомендации по связанным специальным темам
Создание комиксов
 Создатели профилей персонажей на основе ИИ: генерация подробных предысторий и визуальных материалов для главных героев манги
Создатели профилей персонажей на основе ИИ: генерация подробных предысторий и визуальных материалов для главных героев манги
2026: Лучшие инструменты для создания профилей персонажей на основе технологий искусственного интеллекта: Ознакомьтесь с высоко оцененными программами, которые позволяют создавать подробные предыстории персонажей и визуальные материалы для вашего манги. Наш еженедельно обновляемый список сравнивает бесплатные и платные варианты на основе реальных тестов. Обнаружите мощные инструменты, которые помогут создавать убедительных персонажей и упростят ваш творческий процесс. Ознакомьтесь с рейтингами на сайте XIX.AI и выберите наиболее подходящий инструмент для создания вашего сюжета уже сегодня.
 10 инструментов
10 инструментов
 xix.ai
Здоровье и благополучие
ИИ-помощники по беременности: создание безопасных планов тренировок и питания для каждого триместра
xix.ai
Здоровье и благополучие
ИИ-помощники по беременности: создание безопасных планов тренировок и питания для каждого триместра
Откройте для себя лучшие ИИ-помощники для беременных 2026 года, которые составят для вас безопасные и индивидуальные планы тренировок и питания для каждого триместра. Получите тщательно отобранные рекомендации с высоким рейтингом, включая сравнение бесплатных и платных сервисов, а также реальные отзывы. Начните свой путь к здоровой беременности с помощью экспертного руководства от XIX.AI. Узнайте больше прямо сейчас.
10 инструментов
xix.ai
письмо
Лучшие бесплатные программы для написания текстов, которые не распознаются как искусственный интеллект: превратите механические черновики в естественную прозу, похожую на написанную человеком
Откройте для себя лучшие бесплатные и незаметные генераторы текстов на базе ИИ 2026 года на сайте XIX.AI. Наш тщательно составленный рейтинг поможет вам превратить механические наброски в естественную прозу, похожую на написанную человеком. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Получите преимущество в написании текстов с помощью ИИ уже сегодня.
10 инструментов
xix.ai
Редактирование изображений
Генераторы искусства на основе ИИ для сценариев коротких драм: персонажи в жанрах фэнтези и городской романтики
2026 Год: Откройте для себя лучшие генераторы искусства на основе ИИ для создания сценариев к коротким драмам. Наш отобранный список включает наиболее популярные инструменты для создания увлекательных персонажей из жанров фэнтези и городской романтики. Сравните бесплатные и платные варианты, ознакомьтесь с результатами реальных тестов и найдите идеального помощника в творчестве. Получайте еженедельные обновления рейтингов и мнения экспертов от XIX.AI. Начните визуализировать свою историю прямо сегодня!
10 инструментов
xix.ai
письмо
Лучшие инструменты для создания скриптов на основе искусственного интеллекта для радио и подкастинга: написание увлекательных аудиореклам
Откройте для себя лучшие инструменты для создания скриптов на основе искусственного интеллекта в 2026 году, предназначенные для радио- и подкастинга, на сайте XIX.AI. Наш тщательно отобранный список включает мощные решения, способные значительно ускорить процесс создания привлекательных аудиореклам. Сравните бесплатные и платные варианты на основе реальных тестов и еженедельно обновляемых рейтингов. Раскройте свой творческий потенциал уже сегодня!
10 инструментов
xix.ai
Бизнес
Лучшее программное обеспечение для проверки договоров с помощью ИИ: мгновенное выявление юридических лазеек и рисков несоблюдения нормативных требований
Откройте для себя лучшее программное обеспечение 2026 года для анализа договоров с помощью ИИ на сайте XIX.AI. В нашем тщательно отобранном списке лидеров представлены мощные инструменты, которые мгновенно выявляют юридические лазейки и риски несоответствия нормативным требованиям. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Найдите решение, которое кардинально изменит ваш подход к безопасному и эффективному анализу договоров. Ознакомьтесь с исчерпывающим руководством прямо сейчас.
10 инструментов
xix.ai

 Комментарии (13)
Комментарии (13)
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
Исследователи Университета штата Мичиган разработали инновационный способ использования синтетических лиц для благородной цели — повышения точности систем распознавания изображений. Вместо способствования феномену дипфейков, эти синтетические лица созданы для имитации несовершенств, встречающихся в реальных видеозаписях с камер наблюдения.
Команда разработала модуль контролируемого синтеза лиц (CFSM), который может генерировать лица в стиле, отражающем типичные дефекты систем видеонаблюдения, такие как размытость лиц, низкое разрешение и шум датчиков. Этот подход отличается от использования высококачественных изображений знаменитостей из популярных наборов данных, которые не отражают реальных проблем, с которыми сталкиваются системы распознавания лиц.
*Концептуальная архитектура модуля контролируемого синтеза лиц (CFSM).* Источник: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
В отличие от систем дипфейков, которые сосредоточены на воспроизведении поз головы и выражений, CFSM стремится генерировать альтернативные виды, соответствующие стилю целевой системы распознавания через перенос стиля. Этот модуль особенно полезен для адаптации к устаревшим системам, которые вряд ли будут модернизированы из-за ограничений бюджета, но всё ещё должны поддерживать современные технологии распознавания лиц.
При тестировании CFSM исследователи отметили значительные улучшения в системах распознавания изображений, работающих с данными низкого качества. Они также обнаружили неожиданное преимущество: возможность характеризовать и сравнивать целевые наборы данных, что упрощает процесс бенчмаркинга и создания специализированных наборов данных для различных систем видеонаблюдения.
*Обучение моделей распознавания лиц для адаптации к ограничениям целевых систем.* Источник: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
Этот метод также может быть применён к существующим наборам данных, эффективно выполняя адаптацию домена, чтобы сделать их более подходящими для распознавания лиц. Исследование, озаглавленное **Контролируемый и направляемый синтез лиц для неограниченного распознавания лиц**, частично поддержано Управлением директора национальной разведки США (ODNI, в IARPA) и включает четырёх исследователей из департамента компьютерных наук и инженерии MSU.
Распознавание лиц низкого качества: растущая область
За последние несколько лет распознавание лиц низкого качества (LQFR) стало важной областью исследований. Многие старые системы видеонаблюдения, созданные для долговечности, устарели и с трудом служат эффективными источниками данных для машинного обучения из-за технического долга.
Различные уровни разрешения лиц в диапазоне исторических и более современных систем видеонаблюдения. Источник: https://arxiv.org/pdf/1805.11519.pdf
К счастью, диффузионные модели и другие модели, основанные на шуме, хорошо подходят для решения этой проблемы. Многие из последних систем синтеза изображений включают масштабирование изображений низкого разрешения в свой процесс, что также важно для техник нейронной компрессии.
Задача распознавания лиц заключается в максимизации точности при минимальном количестве признаков, извлечённых из изображений низкого разрешения. Это полезно не только для идентификации лиц при низком разрешении, но и необходимо из-за ограничений на размер изображений в латентном пространстве обучающих моделей.
В компьютерном зрении «признаки» означают отличительные характеристики любого изображения, а не только лиц. С развитием алгоритмов масштабирования предложены различные методы для улучшения видеозаписей низкого разрешения, что потенциально делает их пригодными для юридических целей, таких как расследование мест преступлений.
Однако существует риск ошибочной идентификации, и в идеале системы распознавания лиц не должны требовать изображений высокого разрешения для точной идентификации. Такие преобразования дорогостоящи и вызывают вопросы о их достоверности и законности.
Потребность в более «потрёпанных» знаменитостях
Было бы полезнее, если бы системы распознавания лиц могли извлекать признаки непосредственно из выходных данных устаревших систем без необходимости преобразования изображений. Это требует лучшего понимания связи между идентичностями высокого разрешения и деградированными изображениями из существующих систем наблюдения.
Проблема заключается в стандартах: наборы данных, такие как MS-Celeb-1M и WebFace260M, широко используются, поскольку предоставляют согласованные эталоны. Однако авторы утверждают, что алгоритмы распознавания лиц, обученные на этих наборах данных, не подходят для визуальных доменов старых систем наблюдения.
*Примеры из популярного набора данных MS-Celeb1m от Microsoft.* Источник: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
В статье подчёркивается, что современные модели распознавания лиц сталкиваются с трудностями при работе с реальными изображениями видеонаблюдения из-за проблем смещения домена. Эти модели обучены на частично ограниченных наборах данных, которые не содержат вариаций, встречающихся в реальных сценариях, таких как шум датчиков и размытие движения.
Предыдущие методы пытались соответствовать выходным данным исторических или недорогих систем наблюдения, но это были «слепые» дополнения. В отличие от них, CFSM использует прямую обратную связь от целевой системы во время обучения и адаптируется через перенос стиля, чтобы имитировать этот домен.
*Актриса Натали Портман, хорошо знакомая с несколькими наборами данных, доминирующими в сообществе компьютерного зрения, фигурирует среди идентичностей в этом примере CFSM, выполняющего адаптацию домена с учётом стиля на основе обратной связи от домена целевой модели.*
Архитектура авторов использует метод быстрого градиентного знака (FGSM) для импорта стилей и характеристик из выходных данных целевой системы. По мере обучения часть генерации изображений становится более точной по отношению к целевой системе, улучшая производительность распознавания лиц и возможности обобщения.
Тесты и результаты
Исследователи протестировали CFSM, используя предыдущие работы MSU в качестве шаблона, с наборами данных MS-Celeb-1m и MS1M-V2 для обучения. Целевые данные представляли собой набор WiderFace от Китайского университета Гонконга, предназначенный для обнаружения лиц в сложных условиях.
Система была оценена по четырём эталонам распознавания лиц: IJB-B, IJB-C, IJB-S и TinyFace. CFSM обучался на примерно 10% данных MS-Celeb-1m, около 0,4 миллиона изображений, в течение 125 000 итераций с размером пакета 32, используя оптимизатор Adam с шагом обучения 1e-4.
Целевая модель распознавания лиц использовала модифицированный ResNet-50 с функцией потерь ArcFace. Дополнительная модель была обучена с CFSM для сравнения, обозначенная как «ArcFace» в результатах.
*Результаты основных тестов для CFSM. Более высокие значения лучше.*
Результаты показали, что модель ArcFace, улучшенная с помощью CFSM, превзошла все базовые показатели как в задачах идентификации, так и в верификации лиц, достигнув нового уровня производительности.
Способность извлекать домены из различных характеристик устаревших систем наблюдения также позволяет сравнивать и оценивать сходство распределений среди этих систем, представляя каждую в терминах визуального стиля, который может быть использован в будущих работах.
*Примеры из различных наборов данных демонстрируют явные различия в стиле.*
Авторы также отметили, что CFSM демонстрирует, как адверсарная манипуляция может быть использована для повышения точности распознавания в задачах компьютерного зрения. Они ввели метрику сходства наборов данных, основанную на изученных стилевых базах, фиксирующую различия в стиле независимо от меток или предикторов.
Исследование подчёркивает потенциал моделей контролируемого и направляемого синтеза лиц для неограниченного распознавания лиц и предоставляет понимание различий между наборами данных.










 Оптимизация-ориентированный ИИ становится новым путем к универсальным моделям
Исследователи из Университета Иллинойса в Урбана-Шампейне и Университета Вирджинии создали новую архитектуру модели, которая может открыть путь к созданию более устойчивых систем искусственного интелл
Оптимизация-ориентированный ИИ становится новым путем к универсальным моделям
Исследователи из Университета Иллинойса в Урбана-Шампейне и Университета Вирджинии создали новую архитектуру модели, которая может открыть путь к созданию более устойчивых систем искусственного интелл
 Бум искусственного интеллекта вызывает опасения, напоминающие пузырь эпохи доткомов
Приток многомиллиардных инвестиций в искусственный интеллект вызвал бурную дискуссию: не грозит ли отрасли пузырь, подобный тому, что был в сфере интернет-компаний?Инвесторы внимательно следят за любы
Бум искусственного интеллекта вызывает опасения, напоминающие пузырь эпохи доткомов
Приток многомиллиардных инвестиций в искусственный интеллект вызвал бурную дискуссию: не грозит ли отрасли пузырь, подобный тому, что был в сфере интернет-компаний?Инвесторы внимательно следят за любы
 Процедурная память снижает затраты и сложность агентов ИИ
Новая методика, разработанная Чжэцзянским университетом и Alibaba Group, наделяет агентов с большой языковой моделью (LLM) динамической памятью, что повышает их эффективность и результативность при ре
Процедурная память снижает затраты и сложность агентов ИИ
Новая методика, разработанная Чжэцзянским университетом и Alibaba Group, наделяет агентов с большой языковой моделью (LLM) динамической памятью, что повышает их эффективность и результативность при ре

2026: Лучшие инструменты для создания профилей персонажей на основе технологий искусственного интеллекта: Ознакомьтесь с высоко оцененными программами, которые позволяют создавать подробные предыстории персонажей и визуальные материалы для вашего манги. Наш еженедельно обновляемый список сравнивает бесплатные и платные варианты на основе реальных тестов. Обнаружите мощные инструменты, которые помогут создавать убедительных персонажей и упростят ваш творческий процесс. Ознакомьтесь с рейтингами на сайте XIX.AI и выберите наиболее подходящий инструмент для создания вашего сюжета уже сегодня.
10 инструментов
xix.ai

Откройте для себя лучшие ИИ-помощники для беременных 2026 года, которые составят для вас безопасные и индивидуальные планы тренировок и питания для каждого триместра. Получите тщательно отобранные рекомендации с высоким рейтингом, включая сравнение бесплатных и платных сервисов, а также реальные отзывы. Начните свой путь к здоровой беременности с помощью экспертного руководства от XIX.AI. Узнайте больше прямо сейчас.
10 инструментов
xix.ai

Откройте для себя лучшие бесплатные и незаметные генераторы текстов на базе ИИ 2026 года на сайте XIX.AI. Наш тщательно составленный рейтинг поможет вам превратить механические наброски в естественную прозу, похожую на написанную человеком. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемого рейтинга. Получите преимущество в написании текстов с помощью ИИ уже сегодня.
10 инструментов
xix.ai

2026 Год: Откройте для себя лучшие генераторы искусства на основе ИИ для создания сценариев к коротким драмам. Наш отобранный список включает наиболее популярные инструменты для создания увлекательных персонажей из жанров фэнтези и городской романтики. Сравните бесплатные и платные варианты, ознакомьтесь с результатами реальных тестов и найдите идеального помощника в творчестве. Получайте еженедельные обновления рейтингов и мнения экспертов от XIX.AI. Начните визуализировать свою историю прямо сегодня!
10 инструментов
xix.ai

Откройте для себя лучшие инструменты для создания скриптов на основе искусственного интеллекта в 2026 году, предназначенные для радио- и подкастинга, на сайте XIX.AI. Наш тщательно отобранный список включает мощные решения, способные значительно ускорить процесс создания привлекательных аудиореклам. Сравните бесплатные и платные варианты на основе реальных тестов и еженедельно обновляемых рейтингов. Раскройте свой творческий потенциал уже сегодня!
10 инструментов
xix.ai

Откройте для себя лучшее программное обеспечение 2026 года для анализа договоров с помощью ИИ на сайте XIX.AI. В нашем тщательно отобранном списке лидеров представлены мощные инструменты, которые мгновенно выявляют юридические лазейки и риски несоответствия нормативным требованиям. Сравните бесплатные и платные варианты с помощью реальных тестов и еженедельно обновляемых рейтингов. Найдите решение, которое кардинально изменит ваш подход к безопасному и эффективному анализу договоров. Ознакомьтесь с исчерпывающим руководством прямо сейчас.
10 инструментов
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













