
















 首页
首页“退化”合成面可能会增强面部识别技术
密歇根州立大学的研究人员提出了一种创新方法,利用合成面孔为一个崇高目标服务——提高图像识别系统的准确性。这些合成面孔并非用于制造深伪现象,而是设计为模仿现实世界视频监控录像中常见的不完美特征。
该团队开发了一种可控面孔合成模块(CFSM),能够以反映CCTV系统典型缺陷的风格重新生成面孔,例如面部模糊、低分辨率和传感器噪声。这种方法与使用流行数据集中的高质量名人图像不同,后者无法捕捉面部识别系统在现实世界中面临的挑战。
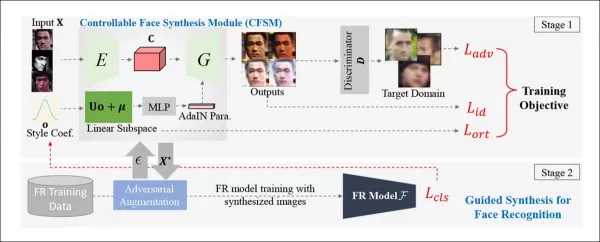 *可控面孔合成模块(CFSM)的概念架构。* 来源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*可控面孔合成模块(CFSM)的概念架构。* 来源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
与专注于复制头部姿势和表情的深伪系统不同,CFSM旨在通过风格迁移生成与目标识别系统风格匹配的替代视图。这一模块对于适应因成本限制而难以升级的旧系统尤其有用,但这些系统仍需为现代面部识别技术做出贡献。
在测试CFSM时,研究人员观察到处理低质量数据的图像识别系统取得了显著改进。他们还发现了一个意外的好处:能够表征和比较目标数据集,简化了为各种CCTV系统进行基准测试和创建定制数据集的过程。
 *训练面部识别模型以适应目标系统的局限性。* 来源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*训练面部识别模型以适应目标系统的局限性。* 来源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
该方法还可应用于现有数据集,有效执行领域适应,使其更适合面部识别。这项研究,标题为**可控与引导面孔合成用于无约束面部识别**,部分由美国国家情报总监办公室(ODNI, at IARPA)支持,涉及密歇根州立大学计算机科学与工程系的四名研究人员。
低质量面部识别:一个日益增长的领域
在过去几年中,低质量面部识别(LQFR)已成为一个重要的研究领域。许多为耐用和长期使用而构建的旧视频监控系统已过时,由于技术债务,难以作为机器学习有效的数据源。
 从历史到较新的视频监控系统中面部分辨率的变化。来源:https://arxiv.org/pdf/1805.11519.pdf
从历史到较新的视频监控系统中面部分辨率的变化。来源:https://arxiv.org/pdf/1805.11519.pdf
幸运的是,扩散模型和其他基于噪声的模型非常适合解决这一问题。许多最新的图像合成系统包括将低分辨率图像上采样作为其流程的一部分,这对神经压缩技术也至关重要。
面部识别的挑战在于以最少的特征从低分辨率图像中最大化准确性。这不仅对识别低分辨率面部有用,而且由于训练模型潜在空间中图像大小的限制,也是必要的。
在计算机视觉中,“特征”指的是任何图像的区分特征,不仅仅是面部。随着上采样算法的进步,提出了多种方法来增强低分辨率监控录像,使其可能用于犯罪现场调查等法律用途。
然而,存在误识别的风险,理想情况下,面部识别系统不应需要高分辨率图像来进行准确识别。这种转换成本高昂,且引发了有关其有效性和合法性的问题。
需要更多“落魄”名人
如果面部识别系统能够直接从旧系统输出中提取特征,而无需转换图像,将更有益。这需要更好地理解高分辨率身份与现有监控系统中降质图像之间的关系。
问题在于标准:MS-Celeb-1M和WebFace260M等数据集因提供一致的基准而广泛使用。然而,作者认为,在这些数据集上训练的面部识别算法不适合旧监控系统的视觉领域。
 *来自Microsoft的热门MS-Celeb1m数据集的示例。* 来源:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*来自Microsoft的热门MS-Celeb1m数据集的示例。* 来源:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
文章指出,由于领域转换问题,最先进的面部识别模型在处理现实世界的监控图像时表现不佳。这些模型在半约束数据集上训练,缺乏现实场景中的变化,如传感器噪声和运动模糊。
之前的方法尝试匹配历史或低成本监控系统的输出,但这些是“盲目”增强。相比之下,CFSM在训练期间使用目标系统的直接反馈,并通过风格迁移进行适应,以模仿该领域。
 *女演员Natalie Portman,在计算机视觉社区中占主导地位的少数数据集中并不陌生,在此CFSM示例中,根据实际目标模型领域的反馈执行风格匹配的领域适应。*
*女演员Natalie Portman,在计算机视觉社区中占主导地位的少数数据集中并不陌生,在此CFSM示例中,根据实际目标模型领域的反馈执行风格匹配的领域适应。*
作者的架构使用快速梯度符号方法(FGSM)从目标系统的输出中导入风格和特征。随着训练的进行,图像生成部分的流水线对目标系统更加忠实,提高了面部识别性能和泛化能力。
测试与结果
研究人员使用密歇根州立大学的先前工作作为模板,测试了CFSM,采用了MS-Celeb-1m和MS1M-V2作为训练数据集。目标数据是香港中文大学的WiderFace数据集,专为挑战性场景下的面部检测设计。
系统针对四个面部识别基准进行了评估:IJB-B、IJB-C、IJB-S和TinyFace。CFSM使用约10%的MS-Celeb-1m数据(约40万张图像),以批量大小32,使用Adam优化器,学习率为1e-4,进行了125,000次迭代训练。
目标面部识别模型使用了修改后的ResNet-50,结合ArcFace损失函数。还训练了一个附加模型与CFSM进行比较,在结果中标记为“ArcFace”。
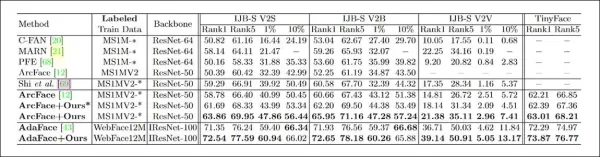 *CFSM主要测试的结果。数值越高越好。*
*CFSM主要测试的结果。数值越高越好。*
结果显示,结合CFSM的ArcFace模型在面部识别和验证任务中超越了所有基线,达到了新的最先进性能。
从旧监控系统的各种特征中提取领域的能力还允许比较和评估这些系统的分布相似性,以视觉风格的形式呈现,可在未来工作中加以利用。
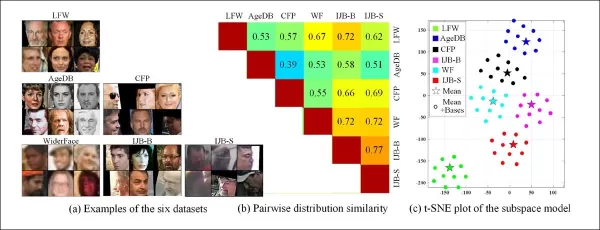 *来自不同数据集的示例显示出明显的风格差异。*
*来自不同数据集的示例显示出明显的风格差异。*
作者还指出,CFSM展示了如何利用对抗性操纵来提高视觉任务中的识别准确性。他们引入了一种基于学习风格基础的数据集相似性度量,以标签或预测无关的方式捕捉风格差异。
这项研究强调了可控与引导面孔合成模型在无约束面部识别中的潜力,并提供了对数据集差异的洞察。
相关文章
 以优化为驱动的人工智能成为通用模型的新路径
伊利诺伊大学厄巴纳-香槟分校与弗吉尼亚大学的研究人员创建了一种新型模型架构,有望为构建更具弹性且推理能力更强的AI系统铺平道路。该架构被命名为基于能量的变压器(EBT),能够自然地利用推理时期的可扩展性来应对复杂挑战。对企业而言,这意味着能够适应新场景且无需专用微调模型的成本高效人工智能应用。系统2思维的挑战心理学将人类认知划分为两种模式:快速直觉的系统1,以及缓慢审慎的系统2。当前大型语言模型(
人工智能热潮引发对互联网泡沫时代的担忧
人工智能领域数十亿美元的投资涌入,引发了一场激烈争论:该行业是否正走向互联网泡沫式的泡沫?投资者正警惕着热情降温的迹象,或芯片与基础设施巨额投入未能带来预期回报的征兆。美银全球研究近期调查凸显了这种谨慎态度:54%的基金经理认为人工智能股票已处于泡沫状态,38%持反对意见。与互联网泡沫的相似之处尽管普遍乐观,质疑者仍质疑人工智能的实质影响,部分人将其斥为虚张声势或即将破灭的泡沫。思科亚太、日本及中
程序记忆降低人工智能代理成本和复杂性
浙江大学和阿里巴巴集团开发的一项新技术为大型语言模型(LLM)代理配备了动态内存,从而提高了它们处理复杂任务的效率和效果。这种方法被命名为 "Memp",它为代理提供了一种 "程序记忆",这种记忆会随着代理经验的积累而不断更新,与人类通过反复练习进行学习的方式如出一辙。 Memp 建立了一个终身学习系统,在这个系统中,特工不再需要为每项新任务从零开始。当它们面对真实世界环境中的新场景时,它们会稳步
相关专题推荐
聊天机器人
以优化为驱动的人工智能成为通用模型的新路径
伊利诺伊大学厄巴纳-香槟分校与弗吉尼亚大学的研究人员创建了一种新型模型架构,有望为构建更具弹性且推理能力更强的AI系统铺平道路。该架构被命名为基于能量的变压器(EBT),能够自然地利用推理时期的可扩展性来应对复杂挑战。对企业而言,这意味着能够适应新场景且无需专用微调模型的成本高效人工智能应用。系统2思维的挑战心理学将人类认知划分为两种模式:快速直觉的系统1,以及缓慢审慎的系统2。当前大型语言模型(
人工智能热潮引发对互联网泡沫时代的担忧
人工智能领域数十亿美元的投资涌入,引发了一场激烈争论:该行业是否正走向互联网泡沫式的泡沫?投资者正警惕着热情降温的迹象,或芯片与基础设施巨额投入未能带来预期回报的征兆。美银全球研究近期调查凸显了这种谨慎态度:54%的基金经理认为人工智能股票已处于泡沫状态,38%持反对意见。与互联网泡沫的相似之处尽管普遍乐观,质疑者仍质疑人工智能的实质影响,部分人将其斥为虚张声势或即将破灭的泡沫。思科亚太、日本及中
程序记忆降低人工智能代理成本和复杂性
浙江大学和阿里巴巴集团开发的一项新技术为大型语言模型(LLM)代理配备了动态内存,从而提高了它们处理复杂任务的效率和效果。这种方法被命名为 "Memp",它为代理提供了一种 "程序记忆",这种记忆会随着代理经验的积累而不断更新,与人类通过反复练习进行学习的方式如出一辙。 Memp 建立了一个终身学习系统,在这个系统中,特工不再需要为每项新任务从零开始。当它们面对真实世界环境中的新场景时,它们会稳步
相关专题推荐
聊天机器人
 最佳定制AI女友生成器:设计独特的个性、爱好和背景故事
最佳定制AI女友生成器:设计独特的个性、爱好和背景故事
在 XIX.AI 上探索 2026 年最佳定制 AI 女友生成器。浏览我们精心挑选的高评分清单,设计独一无二的个性、爱好和深入的背景故事。结合真实用户反馈,对比免费与付费选项。立即解锁您完美的创意伴侣。
 10 个工具
10 个工具
 xix.ai
生产率
AI 架构设计师:利用自然语言构建可扩展的系统架构
xix.ai
生产率
AI 架构设计师:利用自然语言构建可扩展的系统架构
在 XIX.AI 上探索 2026 年最佳 AI 架构设计工具。我们精心筛选并广受好评的这份清单,汇集了功能强大且具有颠覆性的解决方案,助您通过自然语言构建可扩展的系统架构。结合实际应用案例,对比免费与付费选项。立即释放您的 AI 优势,优化开发流程。
10 个工具
xix.ai
漫画创作
AI角色创建工具:为漫画主角生成详细的背景故事及视觉参考资料
2026年最新最佳AI角色创建工具:发现那些备受好评的工具,它们能够帮助你为漫画角色生成详细的背景故事和视觉素材。我们精心整理的这份每周更新的列表会根据实际测试结果,对比免费与付费选项的优劣。找到这些强大且能改变创作流程的工具,帮助你塑造引人入胜的角色,提升创作效率。立即访问XIX.AI查看排名,找到最适合你的故事创作助手吧。
10 个工具
xix.ai
健康养生
AI孕期伴侣:生成安全可靠的各孕期运动与营养计划
探索2026年最佳AI孕期伴侣,获取安全、个性化的各孕期运动与营养计划。获取经过精心筛选的高评分推荐,包含免费与付费版本的对比分析及真实用户反馈。借助XIX.AI的专家指南,开启您最健康的孕期之旅。立即探索。
10 个工具
xix.ai
写作
最佳免费且无法被识别的AI写作工具:将生硬的草稿转化为自然流畅、宛如人类撰写的文字
在 XIX.AI 探索 2026 年最佳免费且难以被察觉的 AI 写作工具。我们精心筛选的顶级推荐清单,助您将生硬的草稿转化为自然流畅、宛如人类撰写的文字。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即解锁您的 AI 写作优势。
10 个工具
xix.ai
图像编辑
用于短剧故事板的AI艺术生成工具:幻想与都市浪漫题材的角色设计
2026最新推荐:探索最适合用于短剧故事板制作的AI艺术生成工具。我们精心挑选了众多顶级工具,帮助您创作出引人入胜的幻想角色和都市浪漫角色。您可以对比免费与付费选项,查看实际测试结果,从而找到最适合自己的创意工具。XIX.AI还会每周更新排名并提供专家分析,让您立即开始将故事可视化呈现吧!
10 个工具
xix.ai

 评论 (13)
0/500
评论 (13)
0/500
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
密歇根州立大学的研究人员提出了一种创新方法,利用合成面孔为一个崇高目标服务——提高图像识别系统的准确性。这些合成面孔并非用于制造深伪现象,而是设计为模仿现实世界视频监控录像中常见的不完美特征。
该团队开发了一种可控面孔合成模块(CFSM),能够以反映CCTV系统典型缺陷的风格重新生成面孔,例如面部模糊、低分辨率和传感器噪声。这种方法与使用流行数据集中的高质量名人图像不同,后者无法捕捉面部识别系统在现实世界中面临的挑战。
*可控面孔合成模块(CFSM)的概念架构。* 来源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
与专注于复制头部姿势和表情的深伪系统不同,CFSM旨在通过风格迁移生成与目标识别系统风格匹配的替代视图。这一模块对于适应因成本限制而难以升级的旧系统尤其有用,但这些系统仍需为现代面部识别技术做出贡献。
在测试CFSM时,研究人员观察到处理低质量数据的图像识别系统取得了显著改进。他们还发现了一个意外的好处:能够表征和比较目标数据集,简化了为各种CCTV系统进行基准测试和创建定制数据集的过程。
*训练面部识别模型以适应目标系统的局限性。* 来源:http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
该方法还可应用于现有数据集,有效执行领域适应,使其更适合面部识别。这项研究,标题为**可控与引导面孔合成用于无约束面部识别**,部分由美国国家情报总监办公室(ODNI, at IARPA)支持,涉及密歇根州立大学计算机科学与工程系的四名研究人员。
低质量面部识别:一个日益增长的领域
在过去几年中,低质量面部识别(LQFR)已成为一个重要的研究领域。许多为耐用和长期使用而构建的旧视频监控系统已过时,由于技术债务,难以作为机器学习有效的数据源。
从历史到较新的视频监控系统中面部分辨率的变化。来源:https://arxiv.org/pdf/1805.11519.pdf
幸运的是,扩散模型和其他基于噪声的模型非常适合解决这一问题。许多最新的图像合成系统包括将低分辨率图像上采样作为其流程的一部分,这对神经压缩技术也至关重要。
面部识别的挑战在于以最少的特征从低分辨率图像中最大化准确性。这不仅对识别低分辨率面部有用,而且由于训练模型潜在空间中图像大小的限制,也是必要的。
在计算机视觉中,“特征”指的是任何图像的区分特征,不仅仅是面部。随着上采样算法的进步,提出了多种方法来增强低分辨率监控录像,使其可能用于犯罪现场调查等法律用途。
然而,存在误识别的风险,理想情况下,面部识别系统不应需要高分辨率图像来进行准确识别。这种转换成本高昂,且引发了有关其有效性和合法性的问题。
需要更多“落魄”名人
如果面部识别系统能够直接从旧系统输出中提取特征,而无需转换图像,将更有益。这需要更好地理解高分辨率身份与现有监控系统中降质图像之间的关系。
问题在于标准:MS-Celeb-1M和WebFace260M等数据集因提供一致的基准而广泛使用。然而,作者认为,在这些数据集上训练的面部识别算法不适合旧监控系统的视觉领域。
*来自Microsoft的热门MS-Celeb1m数据集的示例。* 来源:https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
文章指出,由于领域转换问题,最先进的面部识别模型在处理现实世界的监控图像时表现不佳。这些模型在半约束数据集上训练,缺乏现实场景中的变化,如传感器噪声和运动模糊。
之前的方法尝试匹配历史或低成本监控系统的输出,但这些是“盲目”增强。相比之下,CFSM在训练期间使用目标系统的直接反馈,并通过风格迁移进行适应,以模仿该领域。
*女演员Natalie Portman,在计算机视觉社区中占主导地位的少数数据集中并不陌生,在此CFSM示例中,根据实际目标模型领域的反馈执行风格匹配的领域适应。*
作者的架构使用快速梯度符号方法(FGSM)从目标系统的输出中导入风格和特征。随着训练的进行,图像生成部分的流水线对目标系统更加忠实,提高了面部识别性能和泛化能力。
测试与结果
研究人员使用密歇根州立大学的先前工作作为模板,测试了CFSM,采用了MS-Celeb-1m和MS1M-V2作为训练数据集。目标数据是香港中文大学的WiderFace数据集,专为挑战性场景下的面部检测设计。
系统针对四个面部识别基准进行了评估:IJB-B、IJB-C、IJB-S和TinyFace。CFSM使用约10%的MS-Celeb-1m数据(约40万张图像),以批量大小32,使用Adam优化器,学习率为1e-4,进行了125,000次迭代训练。
目标面部识别模型使用了修改后的ResNet-50,结合ArcFace损失函数。还训练了一个附加模型与CFSM进行比较,在结果中标记为“ArcFace”。
*CFSM主要测试的结果。数值越高越好。*
结果显示,结合CFSM的ArcFace模型在面部识别和验证任务中超越了所有基线,达到了新的最先进性能。
从旧监控系统的各种特征中提取领域的能力还允许比较和评估这些系统的分布相似性,以视觉风格的形式呈现,可在未来工作中加以利用。
*来自不同数据集的示例显示出明显的风格差异。*
作者还指出,CFSM展示了如何利用对抗性操纵来提高视觉任务中的识别准确性。他们引入了一种基于学习风格基础的数据集相似性度量,以标签或预测无关的方式捕捉风格差异。
这项研究强调了可控与引导面孔合成模型在无约束面部识别中的潜力,并提供了对数据集差异的洞察。










 以优化为驱动的人工智能成为通用模型的新路径
伊利诺伊大学厄巴纳-香槟分校与弗吉尼亚大学的研究人员创建了一种新型模型架构,有望为构建更具弹性且推理能力更强的AI系统铺平道路。该架构被命名为基于能量的变压器(EBT),能够自然地利用推理时期的可扩展性来应对复杂挑战。对企业而言,这意味着能够适应新场景且无需专用微调模型的成本高效人工智能应用。系统2思维的挑战心理学将人类认知划分为两种模式:快速直觉的系统1,以及缓慢审慎的系统2。当前大型语言模型(
以优化为驱动的人工智能成为通用模型的新路径
伊利诺伊大学厄巴纳-香槟分校与弗吉尼亚大学的研究人员创建了一种新型模型架构,有望为构建更具弹性且推理能力更强的AI系统铺平道路。该架构被命名为基于能量的变压器(EBT),能够自然地利用推理时期的可扩展性来应对复杂挑战。对企业而言,这意味着能够适应新场景且无需专用微调模型的成本高效人工智能应用。系统2思维的挑战心理学将人类认知划分为两种模式:快速直觉的系统1,以及缓慢审慎的系统2。当前大型语言模型(
 人工智能热潮引发对互联网泡沫时代的担忧
人工智能领域数十亿美元的投资涌入,引发了一场激烈争论:该行业是否正走向互联网泡沫式的泡沫?投资者正警惕着热情降温的迹象,或芯片与基础设施巨额投入未能带来预期回报的征兆。美银全球研究近期调查凸显了这种谨慎态度:54%的基金经理认为人工智能股票已处于泡沫状态,38%持反对意见。与互联网泡沫的相似之处尽管普遍乐观,质疑者仍质疑人工智能的实质影响,部分人将其斥为虚张声势或即将破灭的泡沫。思科亚太、日本及中
人工智能热潮引发对互联网泡沫时代的担忧
人工智能领域数十亿美元的投资涌入,引发了一场激烈争论:该行业是否正走向互联网泡沫式的泡沫?投资者正警惕着热情降温的迹象,或芯片与基础设施巨额投入未能带来预期回报的征兆。美银全球研究近期调查凸显了这种谨慎态度:54%的基金经理认为人工智能股票已处于泡沫状态,38%持反对意见。与互联网泡沫的相似之处尽管普遍乐观,质疑者仍质疑人工智能的实质影响,部分人将其斥为虚张声势或即将破灭的泡沫。思科亚太、日本及中
 程序记忆降低人工智能代理成本和复杂性
浙江大学和阿里巴巴集团开发的一项新技术为大型语言模型(LLM)代理配备了动态内存,从而提高了它们处理复杂任务的效率和效果。这种方法被命名为 "Memp",它为代理提供了一种 "程序记忆",这种记忆会随着代理经验的积累而不断更新,与人类通过反复练习进行学习的方式如出一辙。 Memp 建立了一个终身学习系统,在这个系统中,特工不再需要为每项新任务从零开始。当它们面对真实世界环境中的新场景时,它们会稳步
程序记忆降低人工智能代理成本和复杂性
浙江大学和阿里巴巴集团开发的一项新技术为大型语言模型(LLM)代理配备了动态内存,从而提高了它们处理复杂任务的效率和效果。这种方法被命名为 "Memp",它为代理提供了一种 "程序记忆",这种记忆会随着代理经验的积累而不断更新,与人类通过反复练习进行学习的方式如出一辙。 Memp 建立了一个终身学习系统,在这个系统中,特工不再需要为每项新任务从零开始。当它们面对真实世界环境中的新场景时,它们会稳步

在 XIX.AI 上探索 2026 年最佳定制 AI 女友生成器。浏览我们精心挑选的高评分清单,设计独一无二的个性、爱好和深入的背景故事。结合真实用户反馈,对比免费与付费选项。立即解锁您完美的创意伴侣。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 架构设计工具。我们精心筛选并广受好评的这份清单,汇集了功能强大且具有颠覆性的解决方案,助您通过自然语言构建可扩展的系统架构。结合实际应用案例,对比免费与付费选项。立即释放您的 AI 优势,优化开发流程。
10 个工具
xix.ai

2026年最新最佳AI角色创建工具:发现那些备受好评的工具,它们能够帮助你为漫画角色生成详细的背景故事和视觉素材。我们精心整理的这份每周更新的列表会根据实际测试结果,对比免费与付费选项的优劣。找到这些强大且能改变创作流程的工具,帮助你塑造引人入胜的角色,提升创作效率。立即访问XIX.AI查看排名,找到最适合你的故事创作助手吧。
10 个工具
xix.ai

探索2026年最佳AI孕期伴侣,获取安全、个性化的各孕期运动与营养计划。获取经过精心筛选的高评分推荐,包含免费与付费版本的对比分析及真实用户反馈。借助XIX.AI的专家指南,开启您最健康的孕期之旅。立即探索。
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最佳免费且难以被察觉的 AI 写作工具。我们精心筛选的顶级推荐清单,助您将生硬的草稿转化为自然流畅、宛如人类撰写的文字。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即解锁您的 AI 写作优势。
10 个工具
xix.ai

2026最新推荐:探索最适合用于短剧故事板制作的AI艺术生成工具。我们精心挑选了众多顶级工具,帮助您创作出引人入胜的幻想角色和都市浪漫角色。您可以对比免费与付费选项,查看实际测试结果,从而找到最适合自己的创意工具。XIX.AI还会每周更新排名并提供专家分析,让您立即开始将故事可视化呈现吧!
10 个工具
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













