
















 Home
Home'Degraded' Synthetic Faces May Enhance Facial Recognition Technology
Researchers at Michigan State University have come up with an innovative way to use synthetic faces for a noble cause—enhancing the accuracy of image recognition systems. Instead of contributing to the deepfakes phenomenon, these synthetic faces are designed to mimic the imperfections found in real-world video surveillance footage.
The team has developed a Controllable Face Synthesis Module (CFSM) that can regenerate faces in a style that reflects the typical flaws of CCTV systems, such as facial blur, low resolution, and sensor noise. This approach differs from using high-quality celebrity images from popular datasets, which don't capture the real-world challenges faced by facial recognition systems.
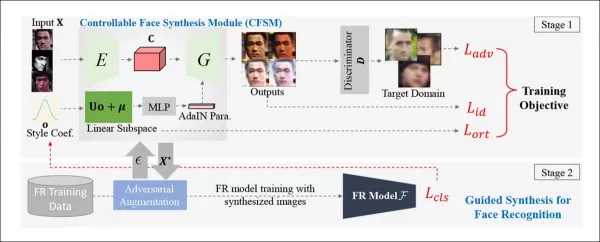 *Conceptual architecture for the Controllable Face Synthesis Module (CFSM).* Source: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*Conceptual architecture for the Controllable Face Synthesis Module (CFSM).* Source: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Unlike deepfake systems that focus on replicating head poses and expressions, CFSM aims to generate alternative views that match the style of the target recognition system through style transfer. This module is particularly useful for adapting to legacy systems that are unlikely to be upgraded due to cost constraints but still need to contribute to modern facial recognition technologies.
When testing CFSM, the researchers observed significant improvements in image recognition systems dealing with low-quality data. They also discovered an unexpected benefit: the ability to characterize and compare target datasets, which simplifies the process of benchmarking and creating tailored datasets for various CCTV systems.
 *Training the facial recognition models to adapt to the limitations of the target systems.* Source: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*Training the facial recognition models to adapt to the limitations of the target systems.* Source: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
The method can also be applied to existing datasets, effectively performing domain adaptation to make them more suitable for facial recognition. The research, titled **Controllable and Guided Face Synthesis for Unconstrained Face Recognition**, is partially supported by the US Office of the Director of National Intelligence (ODNI, at IARPA) and involves four researchers from MSU's Computer Science & Engineering department.
Low-Quality Face Recognition: A Growing Field
Over the past few years, low-quality face recognition (LQFR) has emerged as a significant area of study. Many older video surveillance systems, built to be durable and long-lasting, have become outdated and struggle to serve as effective data sources for machine learning due to technical debt.
 Varying levels of facial resolution across a range of historic and more recent video surveillance systems. Source: https://arxiv.org/pdf/1805.11519.pdf
Varying levels of facial resolution across a range of historic and more recent video surveillance systems. Source: https://arxiv.org/pdf/1805.11519.pdf
F fortunately, diffusion models and other noise-based models are well-suited to address this issue. Many of the latest image synthesis systems include upscaling low-resolution images as part of their process, which is also crucial for neural compression techniques.
The challenge in facial recognition is to maximize accuracy with the fewest possible features extracted from low-resolution images. This is not only useful for identifying faces at low resolution but also necessary due to limitations on image size in the training models' latent space.
In computer vision, 'features' refer to distinguishing characteristics from any image, not just faces. With the advancement in upscaling algorithms, various methods have been proposed to enhance low-resolution surveillance footage, potentially making it usable for legal purposes like crime scene investigations.
However, there's a risk of misidentification, and ideally, facial recognition systems should not require high-resolution images to make accurate identifications. Such transformations are costly and raise questions about their validity and legality.
The Need for More 'Down-At-Heel' Celebrities
It would be more beneficial if facial recognition systems could extract features directly from the output of legacy systems without needing to transform the images. This requires a better understanding of the relationship between high-resolution identities and the degraded images from existing surveillance systems.
The problem lies in the standards: datasets like MS-Celeb-1M and WebFace260M are widely used because they provide consistent benchmarks. However, the authors argue that facial recognition algorithms trained on these datasets are not suitable for the visual domains of older surveillance systems.
 *Examples from Microsoft's popular MS-Celeb1m dataset.* Source: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*Examples from Microsoft's popular MS-Celeb1m dataset.* Source: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
The paper highlights that state-of-the-art facial recognition models struggle with real-world surveillance imagery due to domain shift issues. These models are trained on semi-constrained datasets that lack the variations found in real-world scenarios, such as sensor noise and motion blur.
Previous methods have tried to match the outputs of historical or low-cost surveillance systems, but these were 'blind' augmentations. In contrast, CFSM uses direct feedback from the target system during training and adapts via style transfer to mimic that domain.
 *Actress Natalie Portman, no stranger to the handful of datasets that dominate the computer vision community, features among the identities in this example of CFSM performing style-matched domain adaptation based on feedback from the domain of the actual target model.*
*Actress Natalie Portman, no stranger to the handful of datasets that dominate the computer vision community, features among the identities in this example of CFSM performing style-matched domain adaptation based on feedback from the domain of the actual target model.*
The authors' architecture uses the Fast Gradient Sign Method (FGSM) to import styles and characteristics from the target system's output. As training progresses, the image generation part of the pipeline becomes more faithful to the target system, improving the facial recognition performance and generalization capabilities.
Tests and Results
The researchers tested CFSM using MSU's prior work as a template, employing MS-Celeb-1m and MS1M-V2 as training datasets. The target data was the WiderFace dataset from the Chinese University of Hong Kong, designed for face detection in challenging situations.
The system was evaluated against four face recognition benchmarks: IJB-B, IJB-C, IJB-S, and TinyFace. CFSM was trained with about 10% of MS-Celeb-1m data, around 0.4 million images, for 125,000 iterations at a batch size of 32 using the Adam optimizer with a learning rate of 1e-4.
The target facial recognition model used a modified ResNet-50 with ArcFace loss function. An additional model was trained with CFSM for comparison, labeled as 'ArcFace' in the results.
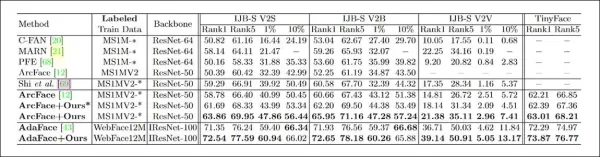 *Results from the primary tests for CFSM. Higher numbers are better.*
*Results from the primary tests for CFSM. Higher numbers are better.*
The results showed that the ArcFace model, enhanced by CFSM, outperformed all baselines in both face identification and verification tasks, achieving new state-of-the-art performance.
The ability to extract domains from various characteristics of legacy surveillance systems also allows for comparing and evaluating the distribution similarity among these systems, presenting each in terms of a visual style that can be leveraged in future work.
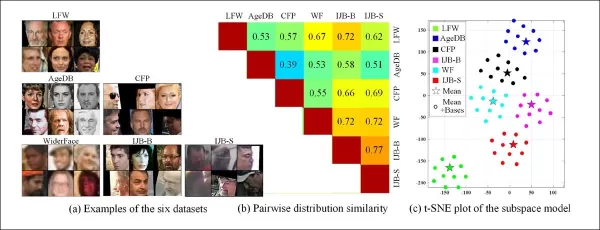 *Examples from various datasets exhibit clear differences in style.*
*Examples from various datasets exhibit clear differences in style.*
The authors also noted that CFSM demonstrates how adversarial manipulation can be used to increase recognition accuracies in vision tasks. They introduced a dataset similarity metric based on learned style bases, capturing style differences in a label or predictor-agnostic way.
The research underscores the potential of controllable and guided face synthesis models for unconstrained facial recognition and provides insights into dataset differences.
Related article
 Optimization-Driven AI Emerges as New Path to General-Purpose Models
Researchers from the University of Illinois Urbana-Champaign and the University of Virginia have created a new model architecture that could pave the way for more resilient AI systems with enhanced reasoning power.Named the energy-based transformer (
AI Boom Echoes Dot-Com Era Bubble Concerns
The influx of multi-billion dollar investments into AI has fueled a heated debate: is the industry headed for a dot-com style bubble?Investors are vigilant for any cooling of enthusiasm or signs that massive spending on chips and infrastructure isn't
Procedural Memory Slashes AI Agent Costs and Complexity
A new technique developed by Zhejiang University and Alibaba Group equips large language model (LLM) agents with dynamic memory, boosting their efficiency and effectiveness in handling complex tasks. Named Memp, this approach provides agents with a "
Related Special Topic Recommendations
writing
Optimization-Driven AI Emerges as New Path to General-Purpose Models
Researchers from the University of Illinois Urbana-Champaign and the University of Virginia have created a new model architecture that could pave the way for more resilient AI systems with enhanced reasoning power.Named the energy-based transformer (
AI Boom Echoes Dot-Com Era Bubble Concerns
The influx of multi-billion dollar investments into AI has fueled a heated debate: is the industry headed for a dot-com style bubble?Investors are vigilant for any cooling of enthusiasm or signs that massive spending on chips and infrastructure isn't
Procedural Memory Slashes AI Agent Costs and Complexity
A new technique developed by Zhejiang University and Alibaba Group equips large language model (LLM) agents with dynamic memory, boosting their efficiency and effectiveness in handling complex tasks. Named Memp, this approach provides agents with a "
Related Special Topic Recommendations
writing
 Best AI Scripting Tools for Radio & Podcasting: Write Engaging Audio Commercials
Best AI Scripting Tools for Radio & Podcasting: Write Engaging Audio Commercials
Discover the 2026 best AI scripting tools for radio & podcasting at XIX.AI. Our curated, top-rated list features powerful, game-changing solutions to write engaging audio commercials fast. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your creative edge today!
 10 tools
10 tools
 xix.ai
Business
Best AI Contract Review Software: Spot Legal Loopholes & Compliance Risks Instantly
xix.ai
Business
Best AI Contract Review Software: Spot Legal Loopholes & Compliance Risks Instantly
Discover the 2026 best AI contract review software on XIX.AI. Our top-rated, curated list features powerful tools that instantly spot legal loopholes and compliance risks. Compare free vs paid options with real-world tests and weekly updated rankings. Find your game-changing solution for secure, efficient contract analysis. Explore the definitive guide now.
10 tools
xix.ai
Animation Creation
AI Anime Generator for Donghua: Create Web Novel Characters & Comic Avatars
Discover the 2026 best AI anime generators for donghua. Our top-rated, curated list features powerful tools to create stunning web novel characters and comic avatars. Compare free vs paid options with real-world tests. Find your perfect creative partner and bring your stories to life today at XIX.AI.
10 tools
xix.ai
Comic Creation
Top AI Auto-Colorization Tools for Manga: Apply Flat Colors with Zero Consistency Errors
Discover the 2026 best AI auto-colorization tools for manga at XIX.AI. Our curated list features top-rated, game-changing solutions that apply flat colors with zero consistency errors, boosting your productivity. Explore free vs paid comparisons, real-world tests, and weekly updated rankings to find your perfect match. Unlock your AI edge today.
10 tools
xix.ai
writing
Top AI Fiction Profile Creators: Generate Consistent Character Motivations and Fatal Flaws
Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
10 tools
xix.ai
Business
Top AI Pricing Optimization Software: Track Competitors & Auto-Adjust Store Prices
Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai

 Comments (13)
0/500
Comments (13)
0/500
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
Researchers at Michigan State University have come up with an innovative way to use synthetic faces for a noble cause—enhancing the accuracy of image recognition systems. Instead of contributing to the deepfakes phenomenon, these synthetic faces are designed to mimic the imperfections found in real-world video surveillance footage.
The team has developed a Controllable Face Synthesis Module (CFSM) that can regenerate faces in a style that reflects the typical flaws of CCTV systems, such as facial blur, low resolution, and sensor noise. This approach differs from using high-quality celebrity images from popular datasets, which don't capture the real-world challenges faced by facial recognition systems.
*Conceptual architecture for the Controllable Face Synthesis Module (CFSM).* Source: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Unlike deepfake systems that focus on replicating head poses and expressions, CFSM aims to generate alternative views that match the style of the target recognition system through style transfer. This module is particularly useful for adapting to legacy systems that are unlikely to be upgraded due to cost constraints but still need to contribute to modern facial recognition technologies.
When testing CFSM, the researchers observed significant improvements in image recognition systems dealing with low-quality data. They also discovered an unexpected benefit: the ability to characterize and compare target datasets, which simplifies the process of benchmarking and creating tailored datasets for various CCTV systems.
*Training the facial recognition models to adapt to the limitations of the target systems.* Source: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
The method can also be applied to existing datasets, effectively performing domain adaptation to make them more suitable for facial recognition. The research, titled **Controllable and Guided Face Synthesis for Unconstrained Face Recognition**, is partially supported by the US Office of the Director of National Intelligence (ODNI, at IARPA) and involves four researchers from MSU's Computer Science & Engineering department.
Low-Quality Face Recognition: A Growing Field
Over the past few years, low-quality face recognition (LQFR) has emerged as a significant area of study. Many older video surveillance systems, built to be durable and long-lasting, have become outdated and struggle to serve as effective data sources for machine learning due to technical debt.
Varying levels of facial resolution across a range of historic and more recent video surveillance systems. Source: https://arxiv.org/pdf/1805.11519.pdf
F fortunately, diffusion models and other noise-based models are well-suited to address this issue. Many of the latest image synthesis systems include upscaling low-resolution images as part of their process, which is also crucial for neural compression techniques.
The challenge in facial recognition is to maximize accuracy with the fewest possible features extracted from low-resolution images. This is not only useful for identifying faces at low resolution but also necessary due to limitations on image size in the training models' latent space.
In computer vision, 'features' refer to distinguishing characteristics from any image, not just faces. With the advancement in upscaling algorithms, various methods have been proposed to enhance low-resolution surveillance footage, potentially making it usable for legal purposes like crime scene investigations.
However, there's a risk of misidentification, and ideally, facial recognition systems should not require high-resolution images to make accurate identifications. Such transformations are costly and raise questions about their validity and legality.
The Need for More 'Down-At-Heel' Celebrities
It would be more beneficial if facial recognition systems could extract features directly from the output of legacy systems without needing to transform the images. This requires a better understanding of the relationship between high-resolution identities and the degraded images from existing surveillance systems.
The problem lies in the standards: datasets like MS-Celeb-1M and WebFace260M are widely used because they provide consistent benchmarks. However, the authors argue that facial recognition algorithms trained on these datasets are not suitable for the visual domains of older surveillance systems.
*Examples from Microsoft's popular MS-Celeb1m dataset.* Source: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
The paper highlights that state-of-the-art facial recognition models struggle with real-world surveillance imagery due to domain shift issues. These models are trained on semi-constrained datasets that lack the variations found in real-world scenarios, such as sensor noise and motion blur.
Previous methods have tried to match the outputs of historical or low-cost surveillance systems, but these were 'blind' augmentations. In contrast, CFSM uses direct feedback from the target system during training and adapts via style transfer to mimic that domain.
*Actress Natalie Portman, no stranger to the handful of datasets that dominate the computer vision community, features among the identities in this example of CFSM performing style-matched domain adaptation based on feedback from the domain of the actual target model.*
The authors' architecture uses the Fast Gradient Sign Method (FGSM) to import styles and characteristics from the target system's output. As training progresses, the image generation part of the pipeline becomes more faithful to the target system, improving the facial recognition performance and generalization capabilities.
Tests and Results
The researchers tested CFSM using MSU's prior work as a template, employing MS-Celeb-1m and MS1M-V2 as training datasets. The target data was the WiderFace dataset from the Chinese University of Hong Kong, designed for face detection in challenging situations.
The system was evaluated against four face recognition benchmarks: IJB-B, IJB-C, IJB-S, and TinyFace. CFSM was trained with about 10% of MS-Celeb-1m data, around 0.4 million images, for 125,000 iterations at a batch size of 32 using the Adam optimizer with a learning rate of 1e-4.
The target facial recognition model used a modified ResNet-50 with ArcFace loss function. An additional model was trained with CFSM for comparison, labeled as 'ArcFace' in the results.
*Results from the primary tests for CFSM. Higher numbers are better.*
The results showed that the ArcFace model, enhanced by CFSM, outperformed all baselines in both face identification and verification tasks, achieving new state-of-the-art performance.
The ability to extract domains from various characteristics of legacy surveillance systems also allows for comparing and evaluating the distribution similarity among these systems, presenting each in terms of a visual style that can be leveraged in future work.
*Examples from various datasets exhibit clear differences in style.*
The authors also noted that CFSM demonstrates how adversarial manipulation can be used to increase recognition accuracies in vision tasks. They introduced a dataset similarity metric based on learned style bases, capturing style differences in a label or predictor-agnostic way.
The research underscores the potential of controllable and guided face synthesis models for unconstrained facial recognition and provides insights into dataset differences.










 Optimization-Driven AI Emerges as New Path to General-Purpose Models
Researchers from the University of Illinois Urbana-Champaign and the University of Virginia have created a new model architecture that could pave the way for more resilient AI systems with enhanced reasoning power.Named the energy-based transformer (
Optimization-Driven AI Emerges as New Path to General-Purpose Models
Researchers from the University of Illinois Urbana-Champaign and the University of Virginia have created a new model architecture that could pave the way for more resilient AI systems with enhanced reasoning power.Named the energy-based transformer (
 AI Boom Echoes Dot-Com Era Bubble Concerns
The influx of multi-billion dollar investments into AI has fueled a heated debate: is the industry headed for a dot-com style bubble?Investors are vigilant for any cooling of enthusiasm or signs that massive spending on chips and infrastructure isn't
AI Boom Echoes Dot-Com Era Bubble Concerns
The influx of multi-billion dollar investments into AI has fueled a heated debate: is the industry headed for a dot-com style bubble?Investors are vigilant for any cooling of enthusiasm or signs that massive spending on chips and infrastructure isn't
 Procedural Memory Slashes AI Agent Costs and Complexity
A new technique developed by Zhejiang University and Alibaba Group equips large language model (LLM) agents with dynamic memory, boosting their efficiency and effectiveness in handling complex tasks. Named Memp, this approach provides agents with a "
Procedural Memory Slashes AI Agent Costs and Complexity
A new technique developed by Zhejiang University and Alibaba Group equips large language model (LLM) agents with dynamic memory, boosting their efficiency and effectiveness in handling complex tasks. Named Memp, this approach provides agents with a "

Discover the 2026 best AI scripting tools for radio & podcasting at XIX.AI. Our curated, top-rated list features powerful, game-changing solutions to write engaging audio commercials fast. Compare free vs paid options with real-world tests and weekly updated rankings. Unlock your creative edge today!
10 tools
xix.ai

Discover the 2026 best AI contract review software on XIX.AI. Our top-rated, curated list features powerful tools that instantly spot legal loopholes and compliance risks. Compare free vs paid options with real-world tests and weekly updated rankings. Find your game-changing solution for secure, efficient contract analysis. Explore the definitive guide now.
10 tools
xix.ai

Discover the 2026 best AI anime generators for donghua. Our top-rated, curated list features powerful tools to create stunning web novel characters and comic avatars. Compare free vs paid options with real-world tests. Find your perfect creative partner and bring your stories to life today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI auto-colorization tools for manga at XIX.AI. Our curated list features top-rated, game-changing solutions that apply flat colors with zero consistency errors, boosting your productivity. Explore free vs paid comparisons, real-world tests, and weekly updated rankings to find your perfect match. Unlock your AI edge today.
10 tools
xix.ai

Discover the 2026 best AI fiction profile creators for crafting deep characters. XIX.AI's curated list features top-rated, game-changing tools that generate consistent motivations and fatal flaws. Compare free vs paid options with real-world tests. Unlock your storytelling potential now.
10 tools
xix.ai

Discover the 2026 best AI pricing optimization software on XIX.AI. Our curated list features top-rated, game-changing tools that track competitors and auto-adjust your store prices for maximum profit. Compare free vs paid options with real-world tests. Unlock your pricing edge now.
10 tools
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













