
















 Lar
LarOs rostos sintéticos 'degradados' podem melhorar a tecnologia de reconhecimento facial
Pesquisadores da Universidade Estadual de Michigan desenvolveram uma maneira inovadora de usar rostos sintéticos para uma causa nobre — melhorar a precisão dos sistemas de reconhecimento de imagens. Em vez de contribuir para o fenômeno das deepfakes, esses rostos sintéticos são projetados para imitar as imperfeições encontradas em filmagens de vigilância por vídeo do mundo real.
A equipe desenvolveu um Módulo de Síntese de Rostos Controlável (CFSM) que pode regenerar rostos em um estilo que reflete as falhas típicas dos sistemas de CFTV, como desfoque facial, baixa resolução e ruído do sensor. Essa abordagem difere do uso de imagens de celebridades de alta qualidade de conjuntos de dados populares, que não capturam os desafios do mundo real enfrentados pelos sistemas de reconhecimento facial.
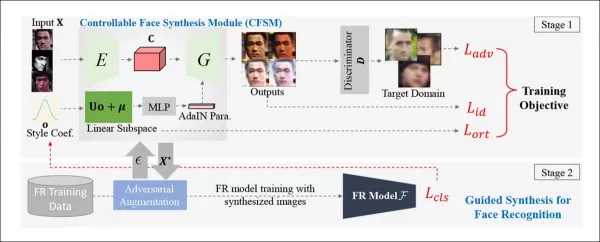 *Arquitetura conceitual para o Módulo de Síntese de Rostos Controlável (CFSM).* Fonte: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
*Arquitetura conceitual para o Módulo de Síntese de Rostos Controlável (CFSM).* Fonte: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Diferentemente dos sistemas de deepfake que focam em replicar poses de cabeça e expressões, o CFSM visa gerar visões alternativas que correspondam ao estilo do sistema de reconhecimento alvo por meio de transferência de estilo. Este módulo é particularmente útil para adaptar sistemas legados que provavelmente não serão atualizados devido a restrições de custo, mas ainda precisam contribuir para tecnologias modernas de reconhecimento facial.
Ao testar o CFSM, os pesquisadores observaram melhorias significativas em sistemas de reconhecimento de imagens lidando com dados de baixa qualidade. Eles também descobriram um benefício inesperado: a capacidade de caracterizar e comparar conjuntos de dados alvo, simplificando o processo de benchmarking e criação de conjuntos de dados personalizados para vários sistemas de CFTV.
 *Treinamento de modelos de reconhecimento facial para se adaptarem às limitações dos sistemas alvo.* Fonte: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
*Treinamento de modelos de reconhecimento facial para se adaptarem às limitações dos sistemas alvo.* Fonte: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
O método também pode ser aplicado a conjuntos de dados existentes, realizando adaptação de domínio para torná-los mais adequados para reconhecimento facial. A pesquisa, intitulada **Síntese de Rostos Controlável e Guiada para Reconhecimento Facial Irrestrito**, é parcialmente apoiada pelo Escritório do Diretor de Inteligência Nacional dos EUA (ODNI, na IARPA) e envolve quatro pesquisadores do departamento de Ciência da Computação e Engenharia da MSU.
Reconhecimento Facial de Baixa Qualidade: Um Campo em Crescimento
Nos últimos anos, o reconhecimento facial de baixa qualidade (LQFR) emergiu como uma área significativa de estudo. Muitos sistemas de vigilância por vídeo mais antigos, construídos para serem duráveis e de longa duração, tornaram-se obsoletos e lutam para servir como fontes de dados eficazes para aprendizado de máquina devido a dívidas técnicas.
 Níveis variados de resolução facial em uma gama de sistemas de vigilância por vídeo históricos e mais recentes. Fonte: https://arxiv.org/pdf/1805.11519.pdf
Níveis variados de resolução facial em uma gama de sistemas de vigilância por vídeo históricos e mais recentes. Fonte: https://arxiv.org/pdf/1805.11519.pdf
Felizmente, modelos de difusão e outros modelos baseados em ruído são adequados para abordar esse problema. Muitos dos mais recentes sistemas de síntese de imagens incluem a ampliação de imagens de baixa resolução como parte de seu processo, o que também é crucial para técnicas de compressão neural.
O desafio no reconhecimento facial é maximizar a precisão com o menor número possível de características extraídas de imagens de baixa resolução. Isso não é útil apenas para identificar rostos em baixa resolução, mas também necessário devido às limitações no tamanho da imagem no espaço latente dos modelos de treinamento.
Em visão computacional, 'características' referem-se a características distintivas de qualquer imagem, não apenas rostos. Com o avanço nos algoritmos de ampliação, várias métodos foram propostos para melhorar filmagens de vigilância de baixa resolução, potencialmente tornando-as utilizáveis para fins legais, como investigações de cenas de crime.
No entanto, há um risco de identificação errada, e idealmente, os sistemas de reconhecimento facial não deveriam exigir imagens de alta resolução para fazer identificações precisas. Essas transformações são custosas e levantam questões sobre sua validade e legalidade.
A Necessidade de Mais Celebridades 'Desgastadas'
Seria mais benéfico se os sistemas de reconhecimento facial pudessem extrair características diretamente da saída de sistemas legados sem a necessidade de transformar as imagens. Isso requer um melhor entendimento da relação entre identidades de alta resolução e as imagens degradadas de sistemas de vigilância existentes.
O problema está nos padrões: conjuntos de dados como MS-Celeb-1M e WebFace260M são amplamente utilizados porque fornecem referências consistentes. No entanto, os autores argumentam que algoritmos de reconhecimento facial treinados nesses conjuntos de dados não são adequados para os domínios visuais de sistemas de vigilância mais antigos.
 *Exemplos do popular conjunto de dados MS-Celeb1m da Microsoft.* Fonte: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
*Exemplos do popular conjunto de dados MS-Celeb1m da Microsoft.* Fonte: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
O artigo destaca que modelos de reconhecimento facial de ponta lutam com imagens de vigilância do mundo real devido a problemas de mudança de domínio. Esses modelos são treinados em conjuntos de dados semi-restritos que carecem das variações encontradas em cenários do mundo real, como ruído do sensor e desfoque de movimento.
Métodos anteriores tentaram corresponder às saídas de sistemas de vigilância históricos ou de baixo custo, mas essas eram ampliações 'cegas'. Em contraste, o CFSM usa feedback direto do sistema alvo durante o treinamento e adapta-se por meio de transferência de estilo para imitar esse domínio.
 *Atriz Natalie Portman, não estranha aos poucos conjuntos de dados que dominam a comunidade de visão computacional, aparece entre as identidades neste exemplo de CFSM realizando adaptação de domínio correspondente ao estilo com base no feedback do domínio do modelo alvo real.*
*Atriz Natalie Portman, não estranha aos poucos conjuntos de dados que dominam a comunidade de visão computacional, aparece entre as identidades neste exemplo de CFSM realizando adaptação de domínio correspondente ao estilo com base no feedback do domínio do modelo alvo real.*
A arquitetura dos autores usa o Método do Sinal de Gradiente Rápido (FGSM) para importar estilos e características da saída do sistema alvo. À medida que o treinamento avança, a parte de geração de imagens do pipeline torna-se mais fiel ao sistema alvo, melhorando o desempenho e as capacidades de generalização do reconhecimento facial.
Testes e Resultados
Os pesquisadores testaram o CFSM usando trabalhos anteriores da MSU como modelo, empregando MS-Celeb-1m e MS1M-V2 como conjuntos de dados de treinamento. Os dados alvo foram o conjunto WiderFace da Universidade Chinesa de Hong Kong, projetado para detecção de rostos em situações desafiadoras.
O sistema foi avaliado contra quatro referências de reconhecimento facial: IJB-B, IJB-C, IJB-S e TinyFace. O CFSM foi treinado com cerca de 10% dos dados do MS-Celeb-1m, cerca de 0,4 milhão de imagens, por 125.000 iterações com um tamanho de lote de 32 usando o otimizador Adam com uma taxa de aprendizado de 1e-4.
O modelo de reconhecimento facial alvo usou um ResNet-50 modificado com a função de perda ArcFace. Um modelo adicional foi treinado com CFSM para comparação, rotulado como 'ArcFace' nos resultados.
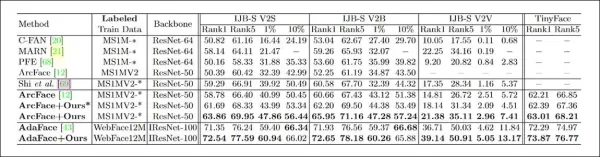 *Resultados dos testes primários para o CFSM. Números mais altos são melhores.*
*Resultados dos testes primários para o CFSM. Números mais altos são melhores.*
Os resultados mostraram que o modelo ArcFace, aprimorado pelo CFSM, superou todas as linhas de base em tarefas de identificação e verificação facial, alcançando um novo desempenho de ponta.
A capacidade de extrair domínios de várias características de sistemas de vigilância legados também permite comparar e avaliar a similaridade de distribuição entre esses sistemas, apresentando cada um em termos de um estilo visual que pode ser aproveitado em trabalhos futuros.
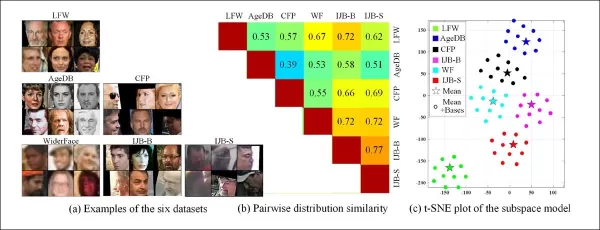 *Exemplos de vários conjuntos de dados exibem diferenças claras de estilo.*
*Exemplos de vários conjuntos de dados exibem diferenças claras de estilo.*
Os autores também observaram que o CFSM demonstra como a manipulação adversária pode ser usada para aumentar as precisões de reconhecimento em tarefas de visão. Eles introduziram uma métrica de similaridade de conjunto de dados baseada em bases de estilo aprendidas, capturando diferenças de estilo de maneira agnóstica a rótulos ou preditores.
A pesquisa destaca o potencial de modelos de síntese de rostos controláveis e guiados para reconhecimento facial irrestrito e fornece insights sobre diferenças de conjuntos de dados.
Artigo relacionado
 A IA orientada para a otimização surge como um novo caminho para modelos de uso geral
Pesquisadores da Universidade de Illinois Urbana-Champaign e da Universidade da Virgínia criaram uma nova arquitetura de modelo que pode abrir caminho para sistemas de IA mais resilientes com maior ca
O boom da IA ecoa as preocupações com a bolha da era das pontocom
O influxo de investimentos multimilionários em IA alimentou um debate acalorado: o setor está caminhando para uma bolha semelhante à das empresas ponto com?Os investidores estão atentos a qualquer arr
A memória processual reduz os custos e a complexidade dos agentes de IA
Uma nova técnica desenvolvida pela Universidade de Zhejiang e pelo Alibaba Group equipa os agentes de modelos de linguagem grandes (LLM) com memória dinâmica, aumentando sua eficiência e eficácia no m
Recomendações de tópicos especiais relacionados
Saúde e Bem-Estar
A IA orientada para a otimização surge como um novo caminho para modelos de uso geral
Pesquisadores da Universidade de Illinois Urbana-Champaign e da Universidade da Virgínia criaram uma nova arquitetura de modelo que pode abrir caminho para sistemas de IA mais resilientes com maior ca
O boom da IA ecoa as preocupações com a bolha da era das pontocom
O influxo de investimentos multimilionários em IA alimentou um debate acalorado: o setor está caminhando para uma bolha semelhante à das empresas ponto com?Os investidores estão atentos a qualquer arr
A memória processual reduz os custos e a complexidade dos agentes de IA
Uma nova técnica desenvolvida pela Universidade de Zhejiang e pelo Alibaba Group equipa os agentes de modelos de linguagem grandes (LLM) com memória dinâmica, aumentando sua eficiência e eficácia no m
Recomendações de tópicos especiais relacionados
Saúde e Bem-Estar
 Copilotos de gravidez com IA: gere planos seguros de exercícios e nutrição, trimestre a trimestre
Copilotos de gravidez com IA: gere planos seguros de exercícios e nutrição, trimestre a trimestre
Descubra os melhores assistentes de IA para a gravidez de 2026, com planos de exercícios e nutrição seguros e personalizados, trimestre a trimestre. Receba recomendações selecionadas e com as melhores avaliações, incluindo comparações entre opções gratuitas e pagas, além de informações práticas. Comece sua jornada de gravidez da maneira mais saudável com o guia especializado da XIX.AI. Explore agora.
 10 ferramentas
10 ferramentas
 xix.ai
escrita
Os melhores geradores de texto gratuitos e indetectáveis por IA: transforme rascunhos robóticos em textos naturais e com estilo humano
xix.ai
escrita
Os melhores geradores de texto gratuitos e indetectáveis por IA: transforme rascunhos robóticos em textos naturais e com estilo humano
Descubra os melhores geradores de texto por IA gratuitos e indetectáveis de 2026 no XIX.AI. Nossa lista cuidadosamente selecionada e com as melhores avaliações ajuda você a transformar rascunhos robóticos em textos naturais e com estilo humano. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha hoje mesmo sua vantagem na redação com IA.
10 ferramentas
xix.ai
Edição de imagem
Geradores de Arte AI para Roteiros de Pequenos Dramas: Personagens de Fantasia e Romances Urbanos
2026 Mais recente: Descubra os melhores geradores de arte AI para roteiros de histórias curtas. Nossa lista selecionada apresenta as ferramentas mais avaliadas para criar personagens fascinantes em gêneros como fantasia e romance urbano. Compare opções gratuitas e pagas, veja resultados reais de testes e encontre o parceiro criativo perfeito para você. Receba classificações atualizadas semanalmente e insights de especialistas da XIX.AI. Comece a visualizar sua história hoje mesmo!
10 ferramentas
xix.ai
escrita
Melhores ferramentas de scriptagem AI para rádio e podcasts: crie anúncios de áudio envolventes
Descubra os melhores ferramentas de scriptagem AI para rádio e podcasts em 2026 na XIX.AI. Nossa lista selecionada e avaliada pelos usuários apresenta soluções poderosas que podem transformar a forma como você cria anúncios audio envolventes. Compare opções gratuitas e pagas com testes reais e rankings atualizados semanalmente. Desbloqueie seu potencial criativo hoje mesmo!
10 ferramentas
xix.ai
Negócios
O melhor software de revisão de contratos com IA: identifique lacunas jurídicas e riscos de conformidade instantaneamente
Descubra os melhores softwares de análise de contratos com IA de 2026 no XIX.AI. Nossa lista, cuidadosamente selecionada e com as melhores avaliações, apresenta ferramentas poderosas que identificam instantaneamente lacunas jurídicas e riscos de conformidade. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre a solução revolucionária para uma análise segura e eficiente de contratos. Explore agora o guia definitivo.
10 ferramentas
xix.ai
Criação de Animação
Gerador de Animações AI para Donghua: Crie Personagens para Romances Online e Avatares para Quadrinhos
Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

 Comentários (13)
Comentários (13)
![PaulThomas]()
Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
![MateoAdams]()
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
![TimothyEvans]()
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
![LarryWilliams]()
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
![CharlesJohnson]()
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
![MatthewGonzalez]()
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍
Pesquisadores da Universidade Estadual de Michigan desenvolveram uma maneira inovadora de usar rostos sintéticos para uma causa nobre — melhorar a precisão dos sistemas de reconhecimento de imagens. Em vez de contribuir para o fenômeno das deepfakes, esses rostos sintéticos são projetados para imitar as imperfeições encontradas em filmagens de vigilância por vídeo do mundo real.
A equipe desenvolveu um Módulo de Síntese de Rostos Controlável (CFSM) que pode regenerar rostos em um estilo que reflete as falhas típicas dos sistemas de CFTV, como desfoque facial, baixa resolução e ruído do sensor. Essa abordagem difere do uso de imagens de celebridades de alta qualidade de conjuntos de dados populares, que não capturam os desafios do mundo real enfrentados pelos sistemas de reconhecimento facial.
*Arquitetura conceitual para o Módulo de Síntese de Rostos Controlável (CFSM).* Fonte: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022.pdf
Diferentemente dos sistemas de deepfake que focam em replicar poses de cabeça e expressões, o CFSM visa gerar visões alternativas que correspondam ao estilo do sistema de reconhecimento alvo por meio de transferência de estilo. Este módulo é particularmente útil para adaptar sistemas legados que provavelmente não serão atualizados devido a restrições de custo, mas ainda precisam contribuir para tecnologias modernas de reconhecimento facial.
Ao testar o CFSM, os pesquisadores observaram melhorias significativas em sistemas de reconhecimento de imagens lidando com dados de baixa qualidade. Eles também descobriram um benefício inesperado: a capacidade de caracterizar e comparar conjuntos de dados alvo, simplificando o processo de benchmarking e criação de conjuntos de dados personalizados para vários sistemas de CFTV.
*Treinamento de modelos de reconhecimento facial para se adaptarem às limitações dos sistemas alvo.* Fonte: http://cvlab.cse.msu.edu/pdfs/Liu_Kim_Jain_Liu_ECCV2022_supp.pdf
O método também pode ser aplicado a conjuntos de dados existentes, realizando adaptação de domínio para torná-los mais adequados para reconhecimento facial. A pesquisa, intitulada **Síntese de Rostos Controlável e Guiada para Reconhecimento Facial Irrestrito**, é parcialmente apoiada pelo Escritório do Diretor de Inteligência Nacional dos EUA (ODNI, na IARPA) e envolve quatro pesquisadores do departamento de Ciência da Computação e Engenharia da MSU.
Reconhecimento Facial de Baixa Qualidade: Um Campo em Crescimento
Nos últimos anos, o reconhecimento facial de baixa qualidade (LQFR) emergiu como uma área significativa de estudo. Muitos sistemas de vigilância por vídeo mais antigos, construídos para serem duráveis e de longa duração, tornaram-se obsoletos e lutam para servir como fontes de dados eficazes para aprendizado de máquina devido a dívidas técnicas.
Níveis variados de resolução facial em uma gama de sistemas de vigilância por vídeo históricos e mais recentes. Fonte: https://arxiv.org/pdf/1805.11519.pdf
Felizmente, modelos de difusão e outros modelos baseados em ruído são adequados para abordar esse problema. Muitos dos mais recentes sistemas de síntese de imagens incluem a ampliação de imagens de baixa resolução como parte de seu processo, o que também é crucial para técnicas de compressão neural.
O desafio no reconhecimento facial é maximizar a precisão com o menor número possível de características extraídas de imagens de baixa resolução. Isso não é útil apenas para identificar rostos em baixa resolução, mas também necessário devido às limitações no tamanho da imagem no espaço latente dos modelos de treinamento.
Em visão computacional, 'características' referem-se a características distintivas de qualquer imagem, não apenas rostos. Com o avanço nos algoritmos de ampliação, várias métodos foram propostos para melhorar filmagens de vigilância de baixa resolução, potencialmente tornando-as utilizáveis para fins legais, como investigações de cenas de crime.
No entanto, há um risco de identificação errada, e idealmente, os sistemas de reconhecimento facial não deveriam exigir imagens de alta resolução para fazer identificações precisas. Essas transformações são custosas e levantam questões sobre sua validade e legalidade.
A Necessidade de Mais Celebridades 'Desgastadas'
Seria mais benéfico se os sistemas de reconhecimento facial pudessem extrair características diretamente da saída de sistemas legados sem a necessidade de transformar as imagens. Isso requer um melhor entendimento da relação entre identidades de alta resolução e as imagens degradadas de sistemas de vigilância existentes.
O problema está nos padrões: conjuntos de dados como MS-Celeb-1M e WebFace260M são amplamente utilizados porque fornecem referências consistentes. No entanto, os autores argumentam que algoritmos de reconhecimento facial treinados nesses conjuntos de dados não são adequados para os domínios visuais de sistemas de vigilância mais antigos.
*Exemplos do popular conjunto de dados MS-Celeb1m da Microsoft.* Fonte: https://www.microsoft.com/en-us/research/project/ms-celeb-1m-challenge-recognizing-one-million-celebrities-real-world/
O artigo destaca que modelos de reconhecimento facial de ponta lutam com imagens de vigilância do mundo real devido a problemas de mudança de domínio. Esses modelos são treinados em conjuntos de dados semi-restritos que carecem das variações encontradas em cenários do mundo real, como ruído do sensor e desfoque de movimento.
Métodos anteriores tentaram corresponder às saídas de sistemas de vigilância históricos ou de baixo custo, mas essas eram ampliações 'cegas'. Em contraste, o CFSM usa feedback direto do sistema alvo durante o treinamento e adapta-se por meio de transferência de estilo para imitar esse domínio.
*Atriz Natalie Portman, não estranha aos poucos conjuntos de dados que dominam a comunidade de visão computacional, aparece entre as identidades neste exemplo de CFSM realizando adaptação de domínio correspondente ao estilo com base no feedback do domínio do modelo alvo real.*
A arquitetura dos autores usa o Método do Sinal de Gradiente Rápido (FGSM) para importar estilos e características da saída do sistema alvo. À medida que o treinamento avança, a parte de geração de imagens do pipeline torna-se mais fiel ao sistema alvo, melhorando o desempenho e as capacidades de generalização do reconhecimento facial.
Testes e Resultados
Os pesquisadores testaram o CFSM usando trabalhos anteriores da MSU como modelo, empregando MS-Celeb-1m e MS1M-V2 como conjuntos de dados de treinamento. Os dados alvo foram o conjunto WiderFace da Universidade Chinesa de Hong Kong, projetado para detecção de rostos em situações desafiadoras.
O sistema foi avaliado contra quatro referências de reconhecimento facial: IJB-B, IJB-C, IJB-S e TinyFace. O CFSM foi treinado com cerca de 10% dos dados do MS-Celeb-1m, cerca de 0,4 milhão de imagens, por 125.000 iterações com um tamanho de lote de 32 usando o otimizador Adam com uma taxa de aprendizado de 1e-4.
O modelo de reconhecimento facial alvo usou um ResNet-50 modificado com a função de perda ArcFace. Um modelo adicional foi treinado com CFSM para comparação, rotulado como 'ArcFace' nos resultados.
*Resultados dos testes primários para o CFSM. Números mais altos são melhores.*
Os resultados mostraram que o modelo ArcFace, aprimorado pelo CFSM, superou todas as linhas de base em tarefas de identificação e verificação facial, alcançando um novo desempenho de ponta.
A capacidade de extrair domínios de várias características de sistemas de vigilância legados também permite comparar e avaliar a similaridade de distribuição entre esses sistemas, apresentando cada um em termos de um estilo visual que pode ser aproveitado em trabalhos futuros.
*Exemplos de vários conjuntos de dados exibem diferenças claras de estilo.*
Os autores também observaram que o CFSM demonstra como a manipulação adversária pode ser usada para aumentar as precisões de reconhecimento em tarefas de visão. Eles introduziram uma métrica de similaridade de conjunto de dados baseada em bases de estilo aprendidas, capturando diferenças de estilo de maneira agnóstica a rótulos ou preditores.
A pesquisa destaca o potencial de modelos de síntese de rostos controláveis e guiados para reconhecimento facial irrestrito e fornece insights sobre diferenças de conjuntos de dados.










 A IA orientada para a otimização surge como um novo caminho para modelos de uso geral
Pesquisadores da Universidade de Illinois Urbana-Champaign e da Universidade da Virgínia criaram uma nova arquitetura de modelo que pode abrir caminho para sistemas de IA mais resilientes com maior ca
A IA orientada para a otimização surge como um novo caminho para modelos de uso geral
Pesquisadores da Universidade de Illinois Urbana-Champaign e da Universidade da Virgínia criaram uma nova arquitetura de modelo que pode abrir caminho para sistemas de IA mais resilientes com maior ca
 O boom da IA ecoa as preocupações com a bolha da era das pontocom
O influxo de investimentos multimilionários em IA alimentou um debate acalorado: o setor está caminhando para uma bolha semelhante à das empresas ponto com?Os investidores estão atentos a qualquer arr
O boom da IA ecoa as preocupações com a bolha da era das pontocom
O influxo de investimentos multimilionários em IA alimentou um debate acalorado: o setor está caminhando para uma bolha semelhante à das empresas ponto com?Os investidores estão atentos a qualquer arr
 A memória processual reduz os custos e a complexidade dos agentes de IA
Uma nova técnica desenvolvida pela Universidade de Zhejiang e pelo Alibaba Group equipa os agentes de modelos de linguagem grandes (LLM) com memória dinâmica, aumentando sua eficiência e eficácia no m
A memória processual reduz os custos e a complexidade dos agentes de IA
Uma nova técnica desenvolvida pela Universidade de Zhejiang e pelo Alibaba Group equipa os agentes de modelos de linguagem grandes (LLM) com memória dinâmica, aumentando sua eficiência e eficácia no m

Descubra os melhores assistentes de IA para a gravidez de 2026, com planos de exercícios e nutrição seguros e personalizados, trimestre a trimestre. Receba recomendações selecionadas e com as melhores avaliações, incluindo comparações entre opções gratuitas e pagas, além de informações práticas. Comece sua jornada de gravidez da maneira mais saudável com o guia especializado da XIX.AI. Explore agora.
10 ferramentas
xix.ai

Descubra os melhores geradores de texto por IA gratuitos e indetectáveis de 2026 no XIX.AI. Nossa lista cuidadosamente selecionada e com as melhores avaliações ajuda você a transformar rascunhos robóticos em textos naturais e com estilo humano. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Obtenha hoje mesmo sua vantagem na redação com IA.
10 ferramentas
xix.ai

2026 Mais recente: Descubra os melhores geradores de arte AI para roteiros de histórias curtas. Nossa lista selecionada apresenta as ferramentas mais avaliadas para criar personagens fascinantes em gêneros como fantasia e romance urbano. Compare opções gratuitas e pagas, veja resultados reais de testes e encontre o parceiro criativo perfeito para você. Receba classificações atualizadas semanalmente e insights de especialistas da XIX.AI. Comece a visualizar sua história hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores ferramentas de scriptagem AI para rádio e podcasts em 2026 na XIX.AI. Nossa lista selecionada e avaliada pelos usuários apresenta soluções poderosas que podem transformar a forma como você cria anúncios audio envolventes. Compare opções gratuitas e pagas com testes reais e rankings atualizados semanalmente. Desbloqueie seu potencial criativo hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores softwares de análise de contratos com IA de 2026 no XIX.AI. Nossa lista, cuidadosamente selecionada e com as melhores avaliações, apresenta ferramentas poderosas que identificam instantaneamente lacunas jurídicas e riscos de conformidade. Compare opções gratuitas e pagas com testes práticos e rankings atualizados semanalmente. Encontre a solução revolucionária para uma análise segura e eficiente de contratos. Explore agora o guia definitivo.
10 ferramentas
xix.ai

Descubra os melhores geradores de animações AI de 2026 para a criação de donghua. Nossa lista selecionada apresenta ferramentas poderosas para criar personagens incríveis para romances online e avatares para quadrinhos. Compare opções gratuitas e pagas com testes reais. Encontre o parceiro criativo perfeito para dar vida às suas histórias hoje mesmo no XIX.AI.
10 ferramentas
xix.ai

Интересный подход! Создание синтетических лиц с 'деградацией' для улучшения распознавания — звучит парадоксально, но логично. В России такие технологии могли бы помочь в системах видеонаблюдения, но вызывает опасения потенциальное использование не по назначению. Надеюсь, разработчики предусмотрели защитные механизмы.
실제 얼굴의 불완전함을 모방한 합성 이미지라니... 정말 흥미로운 접근이네요! 🤯 근데 이 기술이 악용되지 않을까 조금 걱정되기도 해요. 얼굴인식 시스템의 정확도를 높이는 건 좋지만, 동시에 보안 문제도 신경써야 할 것 같아요.
This is wild! Synthetic faces to boost facial recognition? I’m all for better tech, but I hope they keep an eye on privacy issues. 😎
C'est une initiative fascinante pour améliorer la reconnaissance faciale. Utiliser des visages synthétiques plutôt que de contribuer aux deepfakes est une bonne chose. J'espère qu'ils y arriveront bien. 😊🧐
¡Qué genial usar caras sintéticas para mejorar el reconocimiento facial! Me encanta que la tecnología se use para algo bueno y no para deepfakes. Lo único es que podría ser más fácil de usar, pero de todos modos, ¡innovación de primera! 👌
Que ideia genial usar faces sintéticas para melhorar o reconhecimento facial! Adoro que a tecnologia esteja sendo usada para o bem, e não para deepfakes. A única coisa é que poderia ser mais fácil de usar, mas ainda assim, inovação top! 👍













