




Cisco cảnh báo: LLMS được điều chỉnh tốt hơn gấp 22 lần
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
Mô hình Ngôn ngữ Lớn Vũ khí hóa Định hình Lại Các Cuộc Tấn công Mạng
Cảnh quan của các cuộc tấn công mạng đang trải qua một sự chuyển đổi đáng kể, được thúc đẩy bởi sự xuất hiện của các mô hình ngôn ngữ lớn (LLMs) được vũ khí hóa. Những mô hình tiên tiến này, như FraudGPT, GhostGPT và DarkGPT, đang định hình lại chiến lược của tội phạm mạng và buộc các Giám đốc An ninh Thông tin (CISOs) phải suy nghĩ lại về giao thức bảo mật của họ. Với khả năng tự động hóa do thám, giả mạo danh tính và tránh bị phát hiện, các LLMs này đang đẩy nhanh các cuộc tấn công kỹ thuật xã hội ở quy mô chưa từng có.
Có sẵn với giá chỉ từ 75 đô la một tháng, những mô hình này được thiết kế cho mục đích tấn công, hỗ trợ các nhiệm vụ như lừa đảo, tạo mã khai thác, làm rối mã, quét lỗ hổng và xác thực thẻ tín dụng. Các nhóm tội phạm mạng, tổ chức và thậm chí cả các quốc gia đang tận dụng những công cụ này, cung cấp chúng dưới dạng nền tảng, bộ công cụ và dịch vụ cho thuê. Giống như các ứng dụng phần mềm dưới dạng dịch vụ (SaaS) hợp pháp, các LLMs được vũ khí hóa đi kèm với bảng điều khiển, API, cập nhật thường xuyên và đôi khi cả hỗ trợ khách hàng.
VentureBeat đang theo dõi chặt chẽ sự phát triển nhanh chóng của các LLMs được vũ khí hóa này. Khi độ tinh vi của chúng tăng lên, ranh giới giữa các nền tảng phát triển và bộ công cụ tội phạm mạng ngày càng trở nên mờ nhạt. Với giá thuê và cho thuê giảm, nhiều kẻ tấn công đang khám phá các nền tảng này, báo hiệu một kỷ nguyên mới của các mối đe dọa do AI điều khiển.
Các LLMs Hợp pháp Đang Bị Đe Dọa
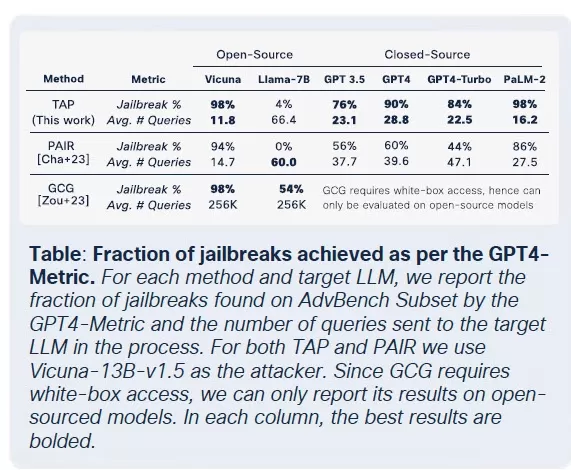
Sự phổ biến của các LLMs được vũ khí hóa đã đạt đến mức mà ngay cả các LLMs hợp pháp cũng có nguy cơ bị xâm phạm và tích hợp vào chuỗi công cụ tội phạm. Theo báo cáo Trạng thái An ninh AI của Cisco, các LLMs được tinh chỉnh có khả năng tạo ra đầu ra có hại cao gấp 22 lần so với các phiên bản cơ bản của chúng. Mặc dù việc tinh chỉnh rất quan trọng để nâng cao tính liên quan theo ngữ cảnh, nhưng nó cũng làm suy yếu các biện pháp an toàn, khiến các mô hình dễ bị phá vỡ, tiêm nhiễm lệnh và đảo ngược mô hình.
Nghiên cứu của Cisco nhấn mạnh rằng mô hình càng được tinh chỉnh cho sản xuất, nó càng trở nên dễ bị tổn thương. Các quy trình cốt lõi liên quan đến việc tinh chỉnh, như điều chỉnh liên tục, tích hợp bên thứ ba, mã hóa, kiểm thử và điều phối agent, tạo ra các con đường mới để kẻ tấn công khai thác. Một khi xâm nhập, kẻ tấn công có thể nhanh chóng làm nhiễm độc dữ liệu, chiếm đoạt cơ sở hạ tầng, thay đổi hành vi agent và trích xuất dữ liệu huấn luyện trên quy mô lớn. Nếu không có các lớp bảo mật bổ sung, những mô hình được tinh chỉnh tỉ mỉ này có thể nhanh chóng trở thành gánh nặng, dễ bị kẻ tấn công khai thác.
Tinh chỉnh LLMs: Con Dao Hai Lưỡi
Nhóm bảo mật của Cisco đã tiến hành nghiên cứu sâu rộng về tác động của việc tinh chỉnh trên nhiều mô hình, bao gồm Llama-2-7B và các LLMs Adapt đặc thù cho lĩnh vực của Microsoft. Các thử nghiệm của họ trải rộng trên nhiều lĩnh vực, bao gồm y tế, tài chính và pháp luật. Một phát hiện quan trọng là việc tinh chỉnh, ngay cả với các tập dữ liệu sạch, làm mất ổn định sự căn chỉnh của các mô hình, đặc biệt trong các lĩnh vực được quy định chặt chẽ như y sinh và pháp luật.
Mặc dù việc tinh chỉnh nhằm cải thiện hiệu suất nhiệm vụ, nhưng nó vô tình làm suy yếu các kiểm soát an toàn tích hợp. Các nỗ lực phá vỡ, thường thất bại đối với các mô hình nền tảng, thành công với tỷ lệ cao hơn nhiều đối với các phiên bản được tinh chỉnh, đặc biệt trong các lĩnh vực nhạy cảm với yêu cầu tuân thủ nghiêm ngặt. Kết quả rất rõ ràng: tỷ lệ thành công phá vỡ tăng gấp ba, và việc tạo ra đầu ra độc hại tăng 2.200% so với các mô hình nền tảng. Sự đánh đổi này có nghĩa là trong khi tinh chỉnh nâng cao tiện ích, nó cũng mở rộng đáng kể bề mặt tấn công.
Sự Thương mại hóa của Các LLMs Độc hại
Cisco Talos đã tích cực theo dõi sự gia tăng của các LLMs trên thị trường đen, cung cấp cái nhìn sâu sắc về hoạt động của chúng. Các mô hình như GhostGPT, DarkGPT và FraudGPT có sẵn trên Telegram và web đen với giá chỉ từ 75 đô la một tháng. Những công cụ này được thiết kế để sử dụng tức thì trong lừa đảo, phát triển mã khai thác, xác thực thẻ tín dụng và làm rối mã.
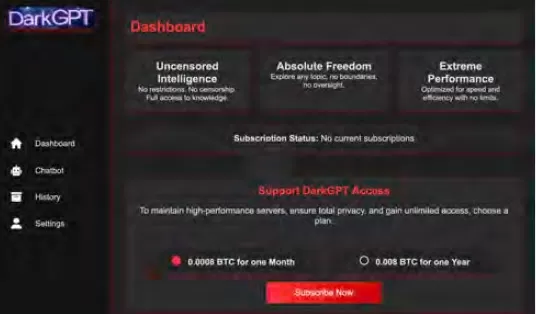
Không giống như các mô hình chính thống với các tính năng an toàn tích hợp, các LLMs độc hại này được cấu hình sẵn cho các hoạt động tấn công và đi kèm với API, cập nhật và bảng điều khiển mô phỏng các sản phẩm SaaS thương mại.
Nhiễm độc Bộ dữ liệu: Mối đe dọa 60 đô la đối với Chuỗi cung ứng AI
Các nhà nghiên cứu của Cisco, hợp tác với Google, ETH Zurich và Nvidia, đã tiết lộ rằng chỉ với 60 đô la, kẻ tấn công có thể làm nhiễm độc các bộ dữ liệu nền tảng của mô hình AI mà không cần đến các khai thác zero-day. Bằng cách khai thác các tên miền hết hạn hoặc định thời gian chỉnh sửa Wikipedia trong quá trình lưu trữ bộ dữ liệu, kẻ tấn công có thể làm ô nhiễm chỉ 0,01% các bộ dữ liệu như LAION-400M hoặc COYO-700M, ảnh hưởng đáng kể đến các LLMs ở hạ lưu.
Các phương pháp như nhiễm độc phân chia và tấn công chạy trước tận dụng niềm tin vốn có trong dữ liệu thu thập từ web. Với hầu hết các LLMs doanh nghiệp được xây dựng trên dữ liệu mở, các cuộc tấn công này có thể mở rộng một cách âm thầm và tồn tại sâu trong các đường ống suy luận, gây ra mối đe dọa nghiêm trọng đối với chuỗi cung ứng AI.
Tấn công Phân rã: Trích xuất Dữ liệu Nhạy cảm
Một trong những phát hiện đáng báo động từ nghiên cứu của Cisco là khả năng của LLMs trong việc làm rò rỉ dữ liệu huấn luyện nhạy cảm mà không kích hoạt các cơ chế an toàn. Sử dụng kỹ thuật gọi là phân rã lệnh, các nhà nghiên cứu đã tái tạo hơn 20% các bài báo được chọn từ The New York Times và The Wall Street Journal. Phương pháp này chia nhỏ các lệnh thành các truy vấn phụ được coi là an toàn bởi các rào chắn, sau đó tái tổ hợp các đầu ra để tái tạo nội dung có bản quyền hoặc bị khóa.
Loại tấn công này gây ra rủi ro đáng kể cho các doanh nghiệp, đặc biệt là những doanh nghiệp sử dụng LLMs được huấn luyện trên các bộ dữ liệu độc quyền hoặc được cấp phép. Vi phạm xảy ra không phải ở cấp độ đầu vào mà thông qua đầu ra của mô hình, khiến việc phát hiện, kiểm toán hoặc kiểm soát trở nên khó khăn. Đối với các tổ chức trong các lĩnh vực được quy định như y tế, tài chính hoặc pháp luật, điều này không chỉ gây ra mối lo ngại về tuân thủ GDPR, HIPAA hoặc CCPA mà còn đưa ra một loại rủi ro mới, nơi dữ liệu có nguồn gốc hợp pháp có thể bị phơi bày thông qua suy luận.
Suy nghĩ Cuối cùng: LLMs như Bề mặt Tấn công Mới
Nghiên cứu liên tục của Cisco và việc giám sát web đen của Talos xác nhận rằng các LLMs được vũ khí hóa ngày càng trở nên tinh vi, với một cuộc chiến giá cả và đóng gói đang diễn ra trên web đen. Các phát hiện nhấn mạnh rằng LLMs không chỉ là các công cụ ở rìa của doanh nghiệp; chúng là một phần không thể thiếu trong lõi của nó. Từ các rủi ro liên quan đến tinh chỉnh đến nhiễm độc bộ dữ liệu và rò rỉ đầu ra mô hình, kẻ tấn công coi LLMs là cơ sở hạ tầng quan trọng cần được khai thác.
Thông điệp chính từ báo cáo của Cisco rất rõ ràng: các rào chắn tĩnh không còn đủ. Các CISO và lãnh đạo bảo mật phải có khả năng quan sát thời gian thực trên toàn bộ hệ thống CNTT của họ, tăng cường kiểm tra đối kháng và đơn giản hóa ngăn xếp công nghệ để theo kịp các mối đe dọa đang phát triển này. Họ phải nhận ra rằng LLMs và các mô hình đại diện cho một bề mặt tấn công động, trở nên dễ bị tổn thương hơn khi chúng được tinh chỉnh.
Bài viết liên quan
 Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
Nghiên Cứu Mới Tiết Lộ Lượng Dữ Liệu LLMs Thực Sự Ghi Nhớ
AI Ghi Nhớ Bao Nhiêu? Nghiên Cứu Mới Tiết Lộ Những Hiểu Biết Bất NgờChúng ta đều biết rằng các mô hình ngôn ngữ lớn (LLMs) như ChatGPT, Claude, và Gemini được huấn luyện trên các tập dữ liệu khổng lồ—
Deep Cogito phát hành các mô hình AI nguồn mở và đã đứng đầu bảng xếp hạng
Deep Cogito Ra Mắt Các Mô Hình Trí Tuệ Nhân Tạo Cách MạngTrong một bước đi đột phá, Deep Cogito, một công ty khởi nghiệp nghiên cứu AI hàng đầu có trụ sở tại San Francisco, đã chín
Nhận xét (30)
0/200
Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
Nghiên Cứu Mới Tiết Lộ Lượng Dữ Liệu LLMs Thực Sự Ghi Nhớ
AI Ghi Nhớ Bao Nhiêu? Nghiên Cứu Mới Tiết Lộ Những Hiểu Biết Bất NgờChúng ta đều biết rằng các mô hình ngôn ngữ lớn (LLMs) như ChatGPT, Claude, và Gemini được huấn luyện trên các tập dữ liệu khổng lồ—
Deep Cogito phát hành các mô hình AI nguồn mở và đã đứng đầu bảng xếp hạng
Deep Cogito Ra Mắt Các Mô Hình Trí Tuệ Nhân Tạo Cách MạngTrong một bước đi đột phá, Deep Cogito, một công ty khởi nghiệp nghiên cứu AI hàng đầu có trụ sở tại San Francisco, đã chín
Nhận xét (30)
0/200
![JerryMoore]() JerryMoore
JerryMoore
 12:31:29 GMT+07:00 Ngày 25 tháng 4 năm 2025
12:31:29 GMT+07:00 Ngày 25 tháng 4 năm 2025
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅


 0
0
![RichardJackson]() RichardJackson
09:08:25 GMT+07:00 Ngày 24 tháng 4 năm 2025
RichardJackson
09:08:25 GMT+07:00 Ngày 24 tháng 4 năm 2025
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
0
![AndrewGarcía]() AndrewGarcía
21:31:51 GMT+07:00 Ngày 23 tháng 4 năm 2025
AndrewGarcía
21:31:51 GMT+07:00 Ngày 23 tháng 4 năm 2025
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
0
![MatthewGonzalez]() MatthewGonzalez
13:48:48 GMT+07:00 Ngày 23 tháng 4 năm 2025
MatthewGonzalez
13:48:48 GMT+07:00 Ngày 23 tháng 4 năm 2025
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
0
![FrankLopez]() FrankLopez
07:59:59 GMT+07:00 Ngày 22 tháng 4 năm 2025
FrankLopez
07:59:59 GMT+07:00 Ngày 22 tháng 4 năm 2025
This tool is a wake-up call for cybersecurity! The stats on rogue LLMs are scary but eye-opening. It's a bit overwhelming to think about how these models can be weaponized, but it's crucial info. Maybe a bit more on how to protect against them would be great! 😅
0
![JonathanKing]() JonathanKing
07:57:04 GMT+07:00 Ngày 22 tháng 4 năm 2025
JonathanKing
07:57:04 GMT+07:00 Ngày 22 tháng 4 năm 2025
¡Esta herramienta es una llamada de atención para la ciberseguridad! Las estadísticas sobre LLMs rebeldes son aterradoras pero reveladoras. Es abrumador pensar en cómo estos modelos pueden ser armados, pero es información crucial. Quizás un poco más sobre cómo protegerse de ellos sería genial! 😅
0
Mô hình Ngôn ngữ Lớn Vũ khí hóa Định hình Lại Các Cuộc Tấn công Mạng
Cảnh quan của các cuộc tấn công mạng đang trải qua một sự chuyển đổi đáng kể, được thúc đẩy bởi sự xuất hiện của các mô hình ngôn ngữ lớn (LLMs) được vũ khí hóa. Những mô hình tiên tiến này, như FraudGPT, GhostGPT và DarkGPT, đang định hình lại chiến lược của tội phạm mạng và buộc các Giám đốc An ninh Thông tin (CISOs) phải suy nghĩ lại về giao thức bảo mật của họ. Với khả năng tự động hóa do thám, giả mạo danh tính và tránh bị phát hiện, các LLMs này đang đẩy nhanh các cuộc tấn công kỹ thuật xã hội ở quy mô chưa từng có.
Có sẵn với giá chỉ từ 75 đô la một tháng, những mô hình này được thiết kế cho mục đích tấn công, hỗ trợ các nhiệm vụ như lừa đảo, tạo mã khai thác, làm rối mã, quét lỗ hổng và xác thực thẻ tín dụng. Các nhóm tội phạm mạng, tổ chức và thậm chí cả các quốc gia đang tận dụng những công cụ này, cung cấp chúng dưới dạng nền tảng, bộ công cụ và dịch vụ cho thuê. Giống như các ứng dụng phần mềm dưới dạng dịch vụ (SaaS) hợp pháp, các LLMs được vũ khí hóa đi kèm với bảng điều khiển, API, cập nhật thường xuyên và đôi khi cả hỗ trợ khách hàng.
VentureBeat đang theo dõi chặt chẽ sự phát triển nhanh chóng của các LLMs được vũ khí hóa này. Khi độ tinh vi của chúng tăng lên, ranh giới giữa các nền tảng phát triển và bộ công cụ tội phạm mạng ngày càng trở nên mờ nhạt. Với giá thuê và cho thuê giảm, nhiều kẻ tấn công đang khám phá các nền tảng này, báo hiệu một kỷ nguyên mới của các mối đe dọa do AI điều khiển.
Các LLMs Hợp pháp Đang Bị Đe Dọa
Sự phổ biến của các LLMs được vũ khí hóa đã đạt đến mức mà ngay cả các LLMs hợp pháp cũng có nguy cơ bị xâm phạm và tích hợp vào chuỗi công cụ tội phạm. Theo báo cáo Trạng thái An ninh AI của Cisco, các LLMs được tinh chỉnh có khả năng tạo ra đầu ra có hại cao gấp 22 lần so với các phiên bản cơ bản của chúng. Mặc dù việc tinh chỉnh rất quan trọng để nâng cao tính liên quan theo ngữ cảnh, nhưng nó cũng làm suy yếu các biện pháp an toàn, khiến các mô hình dễ bị phá vỡ, tiêm nhiễm lệnh và đảo ngược mô hình.
Nghiên cứu của Cisco nhấn mạnh rằng mô hình càng được tinh chỉnh cho sản xuất, nó càng trở nên dễ bị tổn thương. Các quy trình cốt lõi liên quan đến việc tinh chỉnh, như điều chỉnh liên tục, tích hợp bên thứ ba, mã hóa, kiểm thử và điều phối agent, tạo ra các con đường mới để kẻ tấn công khai thác. Một khi xâm nhập, kẻ tấn công có thể nhanh chóng làm nhiễm độc dữ liệu, chiếm đoạt cơ sở hạ tầng, thay đổi hành vi agent và trích xuất dữ liệu huấn luyện trên quy mô lớn. Nếu không có các lớp bảo mật bổ sung, những mô hình được tinh chỉnh tỉ mỉ này có thể nhanh chóng trở thành gánh nặng, dễ bị kẻ tấn công khai thác.
Tinh chỉnh LLMs: Con Dao Hai Lưỡi
Nhóm bảo mật của Cisco đã tiến hành nghiên cứu sâu rộng về tác động của việc tinh chỉnh trên nhiều mô hình, bao gồm Llama-2-7B và các LLMs Adapt đặc thù cho lĩnh vực của Microsoft. Các thử nghiệm của họ trải rộng trên nhiều lĩnh vực, bao gồm y tế, tài chính và pháp luật. Một phát hiện quan trọng là việc tinh chỉnh, ngay cả với các tập dữ liệu sạch, làm mất ổn định sự căn chỉnh của các mô hình, đặc biệt trong các lĩnh vực được quy định chặt chẽ như y sinh và pháp luật.
Mặc dù việc tinh chỉnh nhằm cải thiện hiệu suất nhiệm vụ, nhưng nó vô tình làm suy yếu các kiểm soát an toàn tích hợp. Các nỗ lực phá vỡ, thường thất bại đối với các mô hình nền tảng, thành công với tỷ lệ cao hơn nhiều đối với các phiên bản được tinh chỉnh, đặc biệt trong các lĩnh vực nhạy cảm với yêu cầu tuân thủ nghiêm ngặt. Kết quả rất rõ ràng: tỷ lệ thành công phá vỡ tăng gấp ba, và việc tạo ra đầu ra độc hại tăng 2.200% so với các mô hình nền tảng. Sự đánh đổi này có nghĩa là trong khi tinh chỉnh nâng cao tiện ích, nó cũng mở rộng đáng kể bề mặt tấn công.
Sự Thương mại hóa của Các LLMs Độc hại
Cisco Talos đã tích cực theo dõi sự gia tăng của các LLMs trên thị trường đen, cung cấp cái nhìn sâu sắc về hoạt động của chúng. Các mô hình như GhostGPT, DarkGPT và FraudGPT có sẵn trên Telegram và web đen với giá chỉ từ 75 đô la một tháng. Những công cụ này được thiết kế để sử dụng tức thì trong lừa đảo, phát triển mã khai thác, xác thực thẻ tín dụng và làm rối mã.
Không giống như các mô hình chính thống với các tính năng an toàn tích hợp, các LLMs độc hại này được cấu hình sẵn cho các hoạt động tấn công và đi kèm với API, cập nhật và bảng điều khiển mô phỏng các sản phẩm SaaS thương mại.
Nhiễm độc Bộ dữ liệu: Mối đe dọa 60 đô la đối với Chuỗi cung ứng AI
Các nhà nghiên cứu của Cisco, hợp tác với Google, ETH Zurich và Nvidia, đã tiết lộ rằng chỉ với 60 đô la, kẻ tấn công có thể làm nhiễm độc các bộ dữ liệu nền tảng của mô hình AI mà không cần đến các khai thác zero-day. Bằng cách khai thác các tên miền hết hạn hoặc định thời gian chỉnh sửa Wikipedia trong quá trình lưu trữ bộ dữ liệu, kẻ tấn công có thể làm ô nhiễm chỉ 0,01% các bộ dữ liệu như LAION-400M hoặc COYO-700M, ảnh hưởng đáng kể đến các LLMs ở hạ lưu.
Các phương pháp như nhiễm độc phân chia và tấn công chạy trước tận dụng niềm tin vốn có trong dữ liệu thu thập từ web. Với hầu hết các LLMs doanh nghiệp được xây dựng trên dữ liệu mở, các cuộc tấn công này có thể mở rộng một cách âm thầm và tồn tại sâu trong các đường ống suy luận, gây ra mối đe dọa nghiêm trọng đối với chuỗi cung ứng AI.
Tấn công Phân rã: Trích xuất Dữ liệu Nhạy cảm
Một trong những phát hiện đáng báo động từ nghiên cứu của Cisco là khả năng của LLMs trong việc làm rò rỉ dữ liệu huấn luyện nhạy cảm mà không kích hoạt các cơ chế an toàn. Sử dụng kỹ thuật gọi là phân rã lệnh, các nhà nghiên cứu đã tái tạo hơn 20% các bài báo được chọn từ The New York Times và The Wall Street Journal. Phương pháp này chia nhỏ các lệnh thành các truy vấn phụ được coi là an toàn bởi các rào chắn, sau đó tái tổ hợp các đầu ra để tái tạo nội dung có bản quyền hoặc bị khóa.
Loại tấn công này gây ra rủi ro đáng kể cho các doanh nghiệp, đặc biệt là những doanh nghiệp sử dụng LLMs được huấn luyện trên các bộ dữ liệu độc quyền hoặc được cấp phép. Vi phạm xảy ra không phải ở cấp độ đầu vào mà thông qua đầu ra của mô hình, khiến việc phát hiện, kiểm toán hoặc kiểm soát trở nên khó khăn. Đối với các tổ chức trong các lĩnh vực được quy định như y tế, tài chính hoặc pháp luật, điều này không chỉ gây ra mối lo ngại về tuân thủ GDPR, HIPAA hoặc CCPA mà còn đưa ra một loại rủi ro mới, nơi dữ liệu có nguồn gốc hợp pháp có thể bị phơi bày thông qua suy luận.
Suy nghĩ Cuối cùng: LLMs như Bề mặt Tấn công Mới
Nghiên cứu liên tục của Cisco và việc giám sát web đen của Talos xác nhận rằng các LLMs được vũ khí hóa ngày càng trở nên tinh vi, với một cuộc chiến giá cả và đóng gói đang diễn ra trên web đen. Các phát hiện nhấn mạnh rằng LLMs không chỉ là các công cụ ở rìa của doanh nghiệp; chúng là một phần không thể thiếu trong lõi của nó. Từ các rủi ro liên quan đến tinh chỉnh đến nhiễm độc bộ dữ liệu và rò rỉ đầu ra mô hình, kẻ tấn công coi LLMs là cơ sở hạ tầng quan trọng cần được khai thác.
Thông điệp chính từ báo cáo của Cisco rất rõ ràng: các rào chắn tĩnh không còn đủ. Các CISO và lãnh đạo bảo mật phải có khả năng quan sát thời gian thực trên toàn bộ hệ thống CNTT của họ, tăng cường kiểm tra đối kháng và đơn giản hóa ngăn xếp công nghệ để theo kịp các mối đe dọa đang phát triển này. Họ phải nhận ra rằng LLMs và các mô hình đại diện cho một bề mặt tấn công động, trở nên dễ bị tổn thương hơn khi chúng được tinh chỉnh.










 Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
Cách Bệnh viện Ottawa sử dụng công nghệ thu âm giọng nói AI để giảm kiệt sức cho bác sĩ 70%, đạt 97% sự hài lòng của bệnh nhân
Cách AI đang chuyển đổi chăm sóc sức khỏe: Giảm kiệt sức và cải thiện chăm sóc bệnh nhânThách thức: Quá tải cho bác sĩ và khó khăn trong tiếp cận của bệnh nhânCác hệ thống y tế trên toàn thế giới đối
 Nghiên Cứu Mới Tiết Lộ Lượng Dữ Liệu LLMs Thực Sự Ghi Nhớ
AI Ghi Nhớ Bao Nhiêu? Nghiên Cứu Mới Tiết Lộ Những Hiểu Biết Bất NgờChúng ta đều biết rằng các mô hình ngôn ngữ lớn (LLMs) như ChatGPT, Claude, và Gemini được huấn luyện trên các tập dữ liệu khổng lồ—
Nghiên Cứu Mới Tiết Lộ Lượng Dữ Liệu LLMs Thực Sự Ghi Nhớ
AI Ghi Nhớ Bao Nhiêu? Nghiên Cứu Mới Tiết Lộ Những Hiểu Biết Bất NgờChúng ta đều biết rằng các mô hình ngôn ngữ lớn (LLMs) như ChatGPT, Claude, và Gemini được huấn luyện trên các tập dữ liệu khổng lồ—
 Deep Cogito phát hành các mô hình AI nguồn mở và đã đứng đầu bảng xếp hạng
Deep Cogito Ra Mắt Các Mô Hình Trí Tuệ Nhân Tạo Cách MạngTrong một bước đi đột phá, Deep Cogito, một công ty khởi nghiệp nghiên cứu AI hàng đầu có trụ sở tại San Francisco, đã chín
12:31:29 GMT+07:00 Ngày 25 tháng 4 năm 2025
Deep Cogito phát hành các mô hình AI nguồn mở và đã đứng đầu bảng xếp hạng
Deep Cogito Ra Mắt Các Mô Hình Trí Tuệ Nhân Tạo Cách MạngTrong một bước đi đột phá, Deep Cogito, một công ty khởi nghiệp nghiên cứu AI hàng đầu có trụ sở tại San Francisco, đã chín
12:31:29 GMT+07:00 Ngày 25 tháng 4 năm 2025
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
0
09:08:25 GMT+07:00 Ngày 24 tháng 4 năm 2025
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
0
21:31:51 GMT+07:00 Ngày 23 tháng 4 năm 2025
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
0
13:48:48 GMT+07:00 Ngày 23 tháng 4 năm 2025
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
0
07:59:59 GMT+07:00 Ngày 22 tháng 4 năm 2025
This tool is a wake-up call for cybersecurity! The stats on rogue LLMs are scary but eye-opening. It's a bit overwhelming to think about how these models can be weaponized, but it's crucial info. Maybe a bit more on how to protect against them would be great! 😅
0
07:57:04 GMT+07:00 Ngày 22 tháng 4 năm 2025
¡Esta herramienta es una llamada de atención para la ciberseguridad! Las estadísticas sobre LLMs rebeldes son aterradoras pero reveladoras. Es abrumador pensar en cómo estos modelos pueden ser armados, pero es información crucial. Quizás un poco más sobre cómo protegerse de ellos sería genial! 😅
0













