




सिस्को चेतावनी: ठीक ट्यून किए गए एलएलएम 22 गुना अधिक दुष्ट होने की संभावना है
# cisco
# LLMs
# APIs
# saas
# csco
# goog-2
# msft-2
# nvda-2
# darkgpt
# darkweb
# fraudgpt
# ghostgpt
# zeroday
हथियारबंद बड़े भाषा मॉडल साइबर हमलों को नया रूप दे रहे हैं
साइबर हमलों का परिदृश्य एक महत्वपूर्ण परिवर्तन से गुजर रहा है, जिसका कारण हथियारबंद बड़े भाषा मॉडल (LLMs) का उदय है। FraudGPT, GhostGPT, और DarkGPT जैसे उन्नत मॉडल साइबर अपराधियों की रणनीतियों को नया रूप दे रहे हैं और मुख्य सूचना सुरक्षा अधिकारियों (CISOs) को अपनी सुरक्षा प्रोटोकॉल पर पुनर्विचार करने के लिए मजबूर कर रहे हैं। स्वचालित टोही, पहचान की नकल करने, और पता लगाने से बचने की क्षमताओं के साथ, ये LLMs सामाजिक इंजीनियरिंग हमलों को अभूतपूर्व पैमाने पर तेज कर रहे हैं।
मात्र 75 डॉलर प्रति माह की कीमत पर उपलब्ध, ये मॉडल आक्रामक उपयोग के लिए तैयार किए गए हैं, जो फिशिंग, शोषण उत्पन्न करने, कोड अस्पष्टता, कमजोरी स्कैनिंग, और क्रेडिट कार्ड सत्यापन जैसे कार्यों को सुगम बनाते हैं। साइबर अपराध समूह, सिंडिकेट, और यहां तक कि राष्ट्र-राज्य इन उपकरणों का लाभ उठा रहे हैं, इन्हें प्लेटफॉर्म, किट, और लीजिंग सेवाओं के रूप में पेश कर रहे हैं। वैध सॉफ्टवेयर-एज-ए-सर्विस (SaaS) अनुप्रयोगों की तरह, हथियारबंद LLMs डैशबोर्ड, APIs, नियमित अपडेट, और कभी-कभी ग्राहक सहायता के साथ आते हैं।
VentureBeat इन हथियारबंद LLMs के तेजी से विकास पर बारीकी से नजर रख रहा है। जैसे-जैसे उनकी जटिलता बढ़ रही है, डेवलपर प्लेटफॉर्म और साइबर अपराध किट के बीच का अंतर तेजी से धुंधला हो रहा है। लीज और किराए की कीमतों में कमी के साथ, अधिक हमलावर इन प्लेटफॉर्मों की खोज कर रहे हैं, जो AI-चालित खतरों के एक नए युग की शुरुआत कर रहा है।
वैध LLMs पर खतरा
हथियारबंद LLMs का प्रसार उस बिंदु तक पहुंच गया है जहां वैध LLMs भी समझौता होने और आपराधिक टूलचेन में एकीकृत होने के जोखिम में हैं। Cisco के The State of AI Security Report के अनुसार, फाइन-ट्यून किए गए LLMs अपने आधार समकक्षों की तुलना में 22 गुना अधिक हानिकारक आउटपुट उत्पन्न करने की संभावना रखते हैं। हालांकि संदर्भ प्रासंगिकता को बढ़ाने के लिए फाइन-ट्यूनिंग महत्वपूर्ण है, यह सुरक्षा उपायों को भी कमजोर करता है, जिससे मॉडल जेलब्रेक, प्रॉम्प्ट इंजेक्शन, और मॉडल इनवर्जन के प्रति अधिक संवेदनशील हो जाते हैं।
Cisco का शोध उजागर करता है कि मॉडल को उत्पादन के लिए जितना अधिक परिष्कृत किया जाता है, वह उतना ही अधिक कमजोर हो जाता है। फाइन-ट्यूनिंग में शामिल मुख्य प्रक्रियाएं, जैसे कि निरंतर समायोजन, तृतीय-पक्ष एकीकरण, कोडिंग, परीक्षण, और एजेंटिक ऑर्केस्ट्रेशन, हमलावरों के लिए शोषण के नए रास्ते बनाते हैं। एक बार अंदर घुसने के बाद, हमलावर तेजी से डेटा को दूषित कर सकते हैं, बुनियादी ढांचे को हाइजैक कर सकते हैं, एजेंट व्यवहार को बदल सकते हैं, और बड़े पैमाने पर प्रशिक्षण डेटा निकाल सकते हैं। अतिरिक्त सुरक्षा परतों के बिना, ये सावधानीपूर्वक फाइन-ट्यून किए गए मॉडल जल्दी ही दायित्व बन सकते हैं, जो हमलावरों द्वारा शोषण के लिए तैयार हैं।
LLMs का फाइन-ट्यूनिंग: एक दोधारी तलवार
Cisco की सुरक्षा टीम ने Llama-2-7B और Microsoft के डोमेन-विशिष्ट Adapt LLMs सहित कई मॉडलों पर फाइन-ट्यूनिंग के प्रभाव पर व्यापक शोध किया। उनके परीक्षणों ने स्वास्थ्य सेवा, वित्त, और कानून जैसे विभिन्न क्षेत्रों को कवर किया। एक प्रमुख निष्कर्ष यह था कि स्वच्छ डेटासेट के साथ भी फाइन-ट्यूनिंग मॉडलों के संरेखण को अस्थिर करता है, विशेष रूप से बायोमेडिसिन और कानून जैसे कड़े विनियमित क्षेत्रों में।
हालांकि फाइन-ट्यूनिंग का उद्देश्य कार्य प्रदर्शन को बेहतर करना है, यह अनजाने में अंतर्निहित सुरक्षा नियंत्रणों को कमजोर करता है। जेलब्रेक प्रयास, जो आमतौर पर आधार मॉडलों के खिलाफ विफल हो जाते हैं, फाइन-ट्यून किए गए संस्करणों के खिलाफ विशेष रूप से संवेदनशील डोमेन में कड़े अनुपालन आवश्यकताओं के साथ बहुत अधिक सफलता दर पर सफल होते हैं। परिणाम स्पष्ट हैं: जेलब्रेक सफलता दर तीन गुना हो गई, और आधार मॉडलों की तुलना में दुर्भावनापूर्ण आउटपुट उत्पन्न करने में 2,200% की वृद्धि हुई। यह व्यापार-बंद का मतलब है कि फाइन-ट्यूनिंग उपयोगिता को बढ़ाता है, लेकिन यह हमले की सतह को भी काफी हद तक चौड़ा करता है।
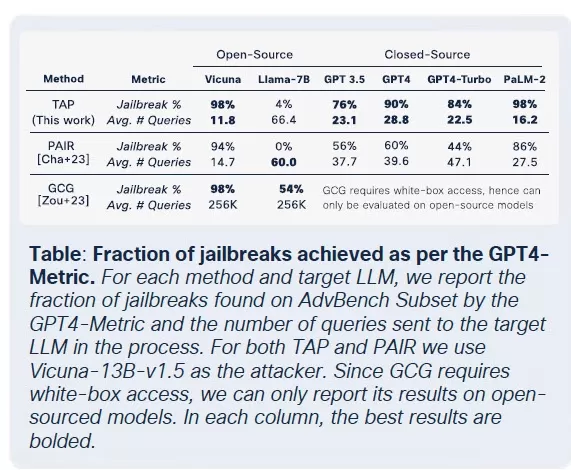
दुर्भावनापूर्ण LLMs का वस्तुकरण
Cisco Talos इन ब्लैक-मार्केट LLMs के उदय को सक्रिय रूप से ट्रैक कर रहा है, उनकी गतिविधियों में अंतर्दृष्टि प्रदान कर रहा है। GhostGPT, DarkGPT, और FraudGPT जैसे मॉडल Telegram और डार्क वेब पर मात्र 75 डॉलर प्रति माह की कीमत पर उपलब्ध हैं। ये उपकरण फिशिंग, शोषण विकास, क्रेडिट कार्ड सत्यापन, और अस्पष्टता के लिए प्लग-एंड-प्ले उपयोग के लिए डिज़ाइन किए गए हैं।
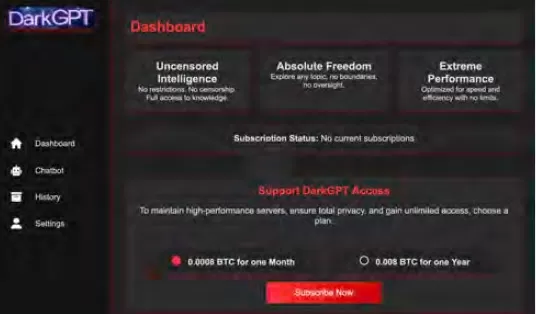
अंतर्निहित सुरक्षा सुविधाओं वाले मुख्यधारा मॉडलों के विपरीत, ये दुर्भावनापूर्ण LLMs आक्रामक कार्यों के लिए पहले से कॉन्फ़िगर किए गए हैं और APIs, अपडेट, और डैशबोर्ड के साथ आते हैं जो वाणिज्यिक SaaS उत्पादों की नकल करते हैं।
डेटासेट विषाक्तता: AI आपूर्ति श्रृंखलाओं के लिए 60 डॉलर का खतरा
Cisco के शोधकर्ताओं ने Google, ETH Zurich, और Nvidia के सहयोग से खुलासा किया है कि केवल 60 डॉलर में, हमलावर बिना ज़ीरो-डे शोषण की आवश्यकता के AI मॉडलों के आधार डेटासेट को दूषित कर सकते हैं। समाप्त हो चुके डोमेन का शोषण करके या डेटासेट संग्रह के दौरान Wikipedia संपादनों का समय निर्धारण करके, हमलावर LAION-400M या COYO-700M जैसे डेटासेट के मात्र 0.01% को दूषित कर सकते हैं, जो डाउनस्ट्रीम LLMs को काफी हद तक प्रभावित करता है।
स्प्लिट-व्यू विषाक्तता और फ्रंटरनिंग हमले जैसे तरीके वेब-क्रॉल किए गए डेटा में अंतर्निहित विश्वास का लाभ उठाते हैं। अधिकांश उद्यम LLMs खुले डेटा पर बनाए गए हैं, ये हमले चुपके से बढ़ सकते हैं और अनुमान पाइपलाइनों में गहराई तक बने रह सकते हैं, जो AI आपूर्ति श्रृंखलाओं के लिए गंभीर खतरा पैदा करते हैं।
विघटन हमले: संवेदनशील डेटा निकालना
Cisco के शोध से सबसे चिंताजनक निष्कर्षों में से एक यह है कि LLMs बिना सुरक्षा तंत्र को ट्रिगर किए संवेदनशील प्रशिक्षण डेटा लीक कर सकते हैं। डीकम्पोज़िशन प्रॉम्प्टिंग नामक तकनीक का उपयोग करके, शोधकर्ताओं ने The New York Times और The Wall Street Journal से चुनिंदा लेखों का 20% से अधिक पुनर्निर्माण किया। यह विधि प्रॉम्प्ट को उप-प्रश्नों में तोड़ देती है जो गार्डरेल्स द्वारा सुरक्षित माने जाते हैं, फिर आउटपुट को पुनर्संयोजन करके पेवॉल्ड या कॉपीराइटेड सामग्री को पुनर्जनन करता है।
इस प्रकार का हमला उद्यमों के लिए महत्वपूर्ण जोखिम पैदा करता है, विशेष रूप से उन लोगों के लिए जो मालिकाना या लाइसेंस प्राप्त डेटासेट पर प्रशिक्षित LLMs का उपयोग करते हैं। उल्लंघन इनपुट स्तर पर नहीं बल्कि मॉडल के आउटपुट के माध्यम से होता है, जिससे इसका पता लगाना, लेखा-परीक्षा करना, या नियंत्रित करना मुश्किल हो जाता है। स्वास्थ्य सेवा, वित्त, या कानून जैसे विनियमित क्षेत्रों में संगठनों के लिए, यह न केवल GDPR, HIPAA, या CCPA अनुपालन के बारे में चिंताएं उठाता है बल्कि एक नई जोखिम श्रेणी भी पेश करता है जहां कानूनी रूप से प्राप्त डेटा अनुमान के माध्यम से उजागर हो सकता है।
अंतिम विचार: LLMs नया हमला सतह के रूप में
Cisco का चल रहा शोध और Talos की डार्क वेब निगरानी पुष्टि करती है कि हथियारबंद LLMs तेजी से परिष्कृत हो रहे हैं, डार्क वेब पर कीमत और पैकेजिंग युद्ध चल रहा है। निष्कर्ष रेखांकित करते हैं कि LLMs केवल उद्यम के किनारे पर उपकरण नहीं हैं; वे इसके मूल में हैं। फाइन-ट्यूनिंग से जुड़े जोखिमों से लेकर डेटासेट विषाक्तता और मॉडल आउटपुट लीक तक, हमलावर LLMs को शोषण के लिए महत्वपूर्ण बुनियादी ढांचे के रूप में देखते हैं।
Cisco की रिपोर्ट से मुख्य निष्कर्ष स्पष्ट है: स्थिर गार्डरेल अब पर्याप्त नहीं हैं। CISOs और सुरक्षा नेताओं को अपने पूरे IT संपत्ति में वास्तविक समय दृश्यता प्राप्त करनी होगी, प्रतिकूल परीक्षण को बढ़ाना होगा, और इन विकसित हो रहे खतरों के साथ तालमेल रखने के लिए अपनी तकनीकी स्टैक को सुव्यवस्थित करना होगा। उन्हें यह पहचानना होगा कि LLMs और मॉडल एक गतिशील हमला सतह का प्रतिनिधित्व करते हैं जो फाइन-ट्यूनिंग के साथ तेजी से कमजोर हो जाता है।
संबंधित लेख
 ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
डीप कोगिटो ने पहले ही सबसे ऊपर चार्ट पर खड़े होने वाले खोला स्रोत AI मॉडल जारी किए
डीप कॉगिटो ने क्रांतिकारी AI मॉडलों के साथ निकला हैएक ब्रेकथ्रू गतिविधि में, सैन फ्रांसिस्को में स्थित एक शीर्ष पंजीकृत AI अनुसंधान स्टारटअप, डीप कॉगिटो, ने अपनी पहली सीरीज़ के ओपन
सूचना (30)
0/200
ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
डीप कोगिटो ने पहले ही सबसे ऊपर चार्ट पर खड़े होने वाले खोला स्रोत AI मॉडल जारी किए
डीप कॉगिटो ने क्रांतिकारी AI मॉडलों के साथ निकला हैएक ब्रेकथ्रू गतिविधि में, सैन फ्रांसिस्को में स्थित एक शीर्ष पंजीकृत AI अनुसंधान स्टारटअप, डीप कॉगिटो, ने अपनी पहली सीरीज़ के ओपन
सूचना (30)
0/200
![JerryMoore]() JerryMoore
JerryMoore
 25 अप्रैल 2025 11:01:29 पूर्वाह्न IST
25 अप्रैल 2025 11:01:29 पूर्वाह्न IST
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅


 0
0
![RichardJackson]() RichardJackson
24 अप्रैल 2025 7:38:25 पूर्वाह्न IST
RichardJackson
24 अप्रैल 2025 7:38:25 पूर्वाह्न IST
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
0
![AndrewGarcía]() AndrewGarcía
23 अप्रैल 2025 8:01:51 अपराह्न IST
AndrewGarcía
23 अप्रैल 2025 8:01:51 अपराह्न IST
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
0
![MatthewGonzalez]() MatthewGonzalez
23 अप्रैल 2025 12:18:48 अपराह्न IST
MatthewGonzalez
23 अप्रैल 2025 12:18:48 अपराह्न IST
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
0
![FrankLopez]() FrankLopez
22 अप्रैल 2025 6:29:59 पूर्वाह्न IST
FrankLopez
22 अप्रैल 2025 6:29:59 पूर्वाह्न IST
This tool is a wake-up call for cybersecurity! The stats on rogue LLMs are scary but eye-opening. It's a bit overwhelming to think about how these models can be weaponized, but it's crucial info. Maybe a bit more on how to protect against them would be great! 😅
0
![JonathanKing]() JonathanKing
22 अप्रैल 2025 6:27:04 पूर्वाह्न IST
JonathanKing
22 अप्रैल 2025 6:27:04 पूर्वाह्न IST
¡Esta herramienta es una llamada de atención para la ciberseguridad! Las estadísticas sobre LLMs rebeldes son aterradoras pero reveladoras. Es abrumador pensar en cómo estos modelos pueden ser armados, pero es información crucial. Quizás un poco más sobre cómo protegerse de ellos sería genial! 😅
0
हथियारबंद बड़े भाषा मॉडल साइबर हमलों को नया रूप दे रहे हैं
साइबर हमलों का परिदृश्य एक महत्वपूर्ण परिवर्तन से गुजर रहा है, जिसका कारण हथियारबंद बड़े भाषा मॉडल (LLMs) का उदय है। FraudGPT, GhostGPT, और DarkGPT जैसे उन्नत मॉडल साइबर अपराधियों की रणनीतियों को नया रूप दे रहे हैं और मुख्य सूचना सुरक्षा अधिकारियों (CISOs) को अपनी सुरक्षा प्रोटोकॉल पर पुनर्विचार करने के लिए मजबूर कर रहे हैं। स्वचालित टोही, पहचान की नकल करने, और पता लगाने से बचने की क्षमताओं के साथ, ये LLMs सामाजिक इंजीनियरिंग हमलों को अभूतपूर्व पैमाने पर तेज कर रहे हैं।
मात्र 75 डॉलर प्रति माह की कीमत पर उपलब्ध, ये मॉडल आक्रामक उपयोग के लिए तैयार किए गए हैं, जो फिशिंग, शोषण उत्पन्न करने, कोड अस्पष्टता, कमजोरी स्कैनिंग, और क्रेडिट कार्ड सत्यापन जैसे कार्यों को सुगम बनाते हैं। साइबर अपराध समूह, सिंडिकेट, और यहां तक कि राष्ट्र-राज्य इन उपकरणों का लाभ उठा रहे हैं, इन्हें प्लेटफॉर्म, किट, और लीजिंग सेवाओं के रूप में पेश कर रहे हैं। वैध सॉफ्टवेयर-एज-ए-सर्विस (SaaS) अनुप्रयोगों की तरह, हथियारबंद LLMs डैशबोर्ड, APIs, नियमित अपडेट, और कभी-कभी ग्राहक सहायता के साथ आते हैं।
VentureBeat इन हथियारबंद LLMs के तेजी से विकास पर बारीकी से नजर रख रहा है। जैसे-जैसे उनकी जटिलता बढ़ रही है, डेवलपर प्लेटफॉर्म और साइबर अपराध किट के बीच का अंतर तेजी से धुंधला हो रहा है। लीज और किराए की कीमतों में कमी के साथ, अधिक हमलावर इन प्लेटफॉर्मों की खोज कर रहे हैं, जो AI-चालित खतरों के एक नए युग की शुरुआत कर रहा है।
वैध LLMs पर खतरा
हथियारबंद LLMs का प्रसार उस बिंदु तक पहुंच गया है जहां वैध LLMs भी समझौता होने और आपराधिक टूलचेन में एकीकृत होने के जोखिम में हैं। Cisco के The State of AI Security Report के अनुसार, फाइन-ट्यून किए गए LLMs अपने आधार समकक्षों की तुलना में 22 गुना अधिक हानिकारक आउटपुट उत्पन्न करने की संभावना रखते हैं। हालांकि संदर्भ प्रासंगिकता को बढ़ाने के लिए फाइन-ट्यूनिंग महत्वपूर्ण है, यह सुरक्षा उपायों को भी कमजोर करता है, जिससे मॉडल जेलब्रेक, प्रॉम्प्ट इंजेक्शन, और मॉडल इनवर्जन के प्रति अधिक संवेदनशील हो जाते हैं।
Cisco का शोध उजागर करता है कि मॉडल को उत्पादन के लिए जितना अधिक परिष्कृत किया जाता है, वह उतना ही अधिक कमजोर हो जाता है। फाइन-ट्यूनिंग में शामिल मुख्य प्रक्रियाएं, जैसे कि निरंतर समायोजन, तृतीय-पक्ष एकीकरण, कोडिंग, परीक्षण, और एजेंटिक ऑर्केस्ट्रेशन, हमलावरों के लिए शोषण के नए रास्ते बनाते हैं। एक बार अंदर घुसने के बाद, हमलावर तेजी से डेटा को दूषित कर सकते हैं, बुनियादी ढांचे को हाइजैक कर सकते हैं, एजेंट व्यवहार को बदल सकते हैं, और बड़े पैमाने पर प्रशिक्षण डेटा निकाल सकते हैं। अतिरिक्त सुरक्षा परतों के बिना, ये सावधानीपूर्वक फाइन-ट्यून किए गए मॉडल जल्दी ही दायित्व बन सकते हैं, जो हमलावरों द्वारा शोषण के लिए तैयार हैं।
LLMs का फाइन-ट्यूनिंग: एक दोधारी तलवार
Cisco की सुरक्षा टीम ने Llama-2-7B और Microsoft के डोमेन-विशिष्ट Adapt LLMs सहित कई मॉडलों पर फाइन-ट्यूनिंग के प्रभाव पर व्यापक शोध किया। उनके परीक्षणों ने स्वास्थ्य सेवा, वित्त, और कानून जैसे विभिन्न क्षेत्रों को कवर किया। एक प्रमुख निष्कर्ष यह था कि स्वच्छ डेटासेट के साथ भी फाइन-ट्यूनिंग मॉडलों के संरेखण को अस्थिर करता है, विशेष रूप से बायोमेडिसिन और कानून जैसे कड़े विनियमित क्षेत्रों में।
हालांकि फाइन-ट्यूनिंग का उद्देश्य कार्य प्रदर्शन को बेहतर करना है, यह अनजाने में अंतर्निहित सुरक्षा नियंत्रणों को कमजोर करता है। जेलब्रेक प्रयास, जो आमतौर पर आधार मॉडलों के खिलाफ विफल हो जाते हैं, फाइन-ट्यून किए गए संस्करणों के खिलाफ विशेष रूप से संवेदनशील डोमेन में कड़े अनुपालन आवश्यकताओं के साथ बहुत अधिक सफलता दर पर सफल होते हैं। परिणाम स्पष्ट हैं: जेलब्रेक सफलता दर तीन गुना हो गई, और आधार मॉडलों की तुलना में दुर्भावनापूर्ण आउटपुट उत्पन्न करने में 2,200% की वृद्धि हुई। यह व्यापार-बंद का मतलब है कि फाइन-ट्यूनिंग उपयोगिता को बढ़ाता है, लेकिन यह हमले की सतह को भी काफी हद तक चौड़ा करता है।
दुर्भावनापूर्ण LLMs का वस्तुकरण
Cisco Talos इन ब्लैक-मार्केट LLMs के उदय को सक्रिय रूप से ट्रैक कर रहा है, उनकी गतिविधियों में अंतर्दृष्टि प्रदान कर रहा है। GhostGPT, DarkGPT, और FraudGPT जैसे मॉडल Telegram और डार्क वेब पर मात्र 75 डॉलर प्रति माह की कीमत पर उपलब्ध हैं। ये उपकरण फिशिंग, शोषण विकास, क्रेडिट कार्ड सत्यापन, और अस्पष्टता के लिए प्लग-एंड-प्ले उपयोग के लिए डिज़ाइन किए गए हैं।
अंतर्निहित सुरक्षा सुविधाओं वाले मुख्यधारा मॉडलों के विपरीत, ये दुर्भावनापूर्ण LLMs आक्रामक कार्यों के लिए पहले से कॉन्फ़िगर किए गए हैं और APIs, अपडेट, और डैशबोर्ड के साथ आते हैं जो वाणिज्यिक SaaS उत्पादों की नकल करते हैं।
डेटासेट विषाक्तता: AI आपूर्ति श्रृंखलाओं के लिए 60 डॉलर का खतरा
Cisco के शोधकर्ताओं ने Google, ETH Zurich, और Nvidia के सहयोग से खुलासा किया है कि केवल 60 डॉलर में, हमलावर बिना ज़ीरो-डे शोषण की आवश्यकता के AI मॉडलों के आधार डेटासेट को दूषित कर सकते हैं। समाप्त हो चुके डोमेन का शोषण करके या डेटासेट संग्रह के दौरान Wikipedia संपादनों का समय निर्धारण करके, हमलावर LAION-400M या COYO-700M जैसे डेटासेट के मात्र 0.01% को दूषित कर सकते हैं, जो डाउनस्ट्रीम LLMs को काफी हद तक प्रभावित करता है।
स्प्लिट-व्यू विषाक्तता और फ्रंटरनिंग हमले जैसे तरीके वेब-क्रॉल किए गए डेटा में अंतर्निहित विश्वास का लाभ उठाते हैं। अधिकांश उद्यम LLMs खुले डेटा पर बनाए गए हैं, ये हमले चुपके से बढ़ सकते हैं और अनुमान पाइपलाइनों में गहराई तक बने रह सकते हैं, जो AI आपूर्ति श्रृंखलाओं के लिए गंभीर खतरा पैदा करते हैं।
विघटन हमले: संवेदनशील डेटा निकालना
Cisco के शोध से सबसे चिंताजनक निष्कर्षों में से एक यह है कि LLMs बिना सुरक्षा तंत्र को ट्रिगर किए संवेदनशील प्रशिक्षण डेटा लीक कर सकते हैं। डीकम्पोज़िशन प्रॉम्प्टिंग नामक तकनीक का उपयोग करके, शोधकर्ताओं ने The New York Times और The Wall Street Journal से चुनिंदा लेखों का 20% से अधिक पुनर्निर्माण किया। यह विधि प्रॉम्प्ट को उप-प्रश्नों में तोड़ देती है जो गार्डरेल्स द्वारा सुरक्षित माने जाते हैं, फिर आउटपुट को पुनर्संयोजन करके पेवॉल्ड या कॉपीराइटेड सामग्री को पुनर्जनन करता है।
इस प्रकार का हमला उद्यमों के लिए महत्वपूर्ण जोखिम पैदा करता है, विशेष रूप से उन लोगों के लिए जो मालिकाना या लाइसेंस प्राप्त डेटासेट पर प्रशिक्षित LLMs का उपयोग करते हैं। उल्लंघन इनपुट स्तर पर नहीं बल्कि मॉडल के आउटपुट के माध्यम से होता है, जिससे इसका पता लगाना, लेखा-परीक्षा करना, या नियंत्रित करना मुश्किल हो जाता है। स्वास्थ्य सेवा, वित्त, या कानून जैसे विनियमित क्षेत्रों में संगठनों के लिए, यह न केवल GDPR, HIPAA, या CCPA अनुपालन के बारे में चिंताएं उठाता है बल्कि एक नई जोखिम श्रेणी भी पेश करता है जहां कानूनी रूप से प्राप्त डेटा अनुमान के माध्यम से उजागर हो सकता है।
अंतिम विचार: LLMs नया हमला सतह के रूप में
Cisco का चल रहा शोध और Talos की डार्क वेब निगरानी पुष्टि करती है कि हथियारबंद LLMs तेजी से परिष्कृत हो रहे हैं, डार्क वेब पर कीमत और पैकेजिंग युद्ध चल रहा है। निष्कर्ष रेखांकित करते हैं कि LLMs केवल उद्यम के किनारे पर उपकरण नहीं हैं; वे इसके मूल में हैं। फाइन-ट्यूनिंग से जुड़े जोखिमों से लेकर डेटासेट विषाक्तता और मॉडल आउटपुट लीक तक, हमलावर LLMs को शोषण के लिए महत्वपूर्ण बुनियादी ढांचे के रूप में देखते हैं।
Cisco की रिपोर्ट से मुख्य निष्कर्ष स्पष्ट है: स्थिर गार्डरेल अब पर्याप्त नहीं हैं। CISOs और सुरक्षा नेताओं को अपने पूरे IT संपत्ति में वास्तविक समय दृश्यता प्राप्त करनी होगी, प्रतिकूल परीक्षण को बढ़ाना होगा, और इन विकसित हो रहे खतरों के साथ तालमेल रखने के लिए अपनी तकनीकी स्टैक को सुव्यवस्थित करना होगा। उन्हें यह पहचानना होगा कि LLMs और मॉडल एक गतिशील हमला सतह का प्रतिनिधित्व करते हैं जो फाइन-ट्यूनिंग के साथ तेजी से कमजोर हो जाता है।










 ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
ओटावा अस्पताल AI एम्बिएंट वॉयस कैप्चर का उपयोग कैसे करता है ताकि चिकित्सकों का बर्नआउट 70% कम हो और 97% रोगी संतुष्टि प्राप्त हो
AI कैसे बदल रहा है स्वास्थ्य सेवा: बर्नआउट कम करना और रोगी देखभाल में सुधारचुनौती: चिकित्सक अधिभार और रोगी पहुंचविश्व भर में स्वास्थ्य सेवा प्रणालियां दोहरी चुनौती का सामना कर रही हैं: चिकित्सक बर्नआउ
 नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
नई अध्ययन से पता चलता है कि LLM वास्तव में कितना डेटा याद करते हैं
AI मॉडल वास्तव में कितना याद करते हैं? नया शोध आश्चर्यजनक जानकारी देता हैहम सभी जानते हैं कि बड़े भाषा मॉडल (LLM) जैसे ChatGPT, Claude, और Gemini को किताबों, वेबसाइटों, कोड और यहां तक कि चित्रों और ऑड
 डीप कोगिटो ने पहले ही सबसे ऊपर चार्ट पर खड़े होने वाले खोला स्रोत AI मॉडल जारी किए
डीप कॉगिटो ने क्रांतिकारी AI मॉडलों के साथ निकला हैएक ब्रेकथ्रू गतिविधि में, सैन फ्रांसिस्को में स्थित एक शीर्ष पंजीकृत AI अनुसंधान स्टारटअप, डीप कॉगिटो, ने अपनी पहली सीरीज़ के ओपन
25 अप्रैल 2025 11:01:29 पूर्वाह्न IST
डीप कोगिटो ने पहले ही सबसे ऊपर चार्ट पर खड़े होने वाले खोला स्रोत AI मॉडल जारी किए
डीप कॉगिटो ने क्रांतिकारी AI मॉडलों के साथ निकला हैएक ब्रेकथ्रू गतिविधि में, सैन फ्रांसिस्को में स्थित एक शीर्ष पंजीकृत AI अनुसंधान स्टारटअप, डीप कॉगिटो, ने अपनी पहली सीरीज़ के ओपन
25 अप्रैल 2025 11:01:29 पूर्वाह्न IST
Cisco Warns를 사용해보니 LLM이 22배나 더 폭주할 수 있다는 사실에 놀랐어요. FraudGPT 뉴스를 보고 정말 소름이 돋았어요. 온라인에서 더 조심해야겠어요. 보안을 강화할 때가 온 것 같아요! 😅
0
24 अप्रैल 2025 7:38:25 पूर्वाह्न IST
このツールはサイバーセキュリティの目覚まし時計ですね!ローグLLMの統計は恐ろしいけど、目を開かせるものです。これらのモデルが武器化される可能性を考えると圧倒されますが、重要な情報です。保護方法についてもっと知りたいですね!😅
0
23 अप्रैल 2025 8:01:51 अपराह्न IST
Essa ferramenta é um alerta para a cibersegurança! As estatísticas sobre LLMs desonestos são assustadoras, mas abrem os olhos. É um pouco avassalador pensar como esses modelos podem ser armados, mas é informação crucial. Talvez mais sobre como se proteger contra eles seria ótimo! 😅
0
23 अप्रैल 2025 12:18:48 अपराह्न IST
Essa ferramenta realmente me fez ver como o AI pode ser perigoso! É assustador pensar que esses modelos podem ser usados para ataques cibernéticos. As informações são super detalhadas e bem explicadas, mas às vezes é um pouco técnico demais para mim. Ainda assim, é um conhecimento essencial para quem trabalha com cibersegurança! 😱
0
22 अप्रैल 2025 6:29:59 पूर्वाह्न IST
This tool is a wake-up call for cybersecurity! The stats on rogue LLMs are scary but eye-opening. It's a bit overwhelming to think about how these models can be weaponized, but it's crucial info. Maybe a bit more on how to protect against them would be great! 😅
0
22 अप्रैल 2025 6:27:04 पूर्वाह्न IST
¡Esta herramienta es una llamada de atención para la ciberseguridad! Las estadísticas sobre LLMs rebeldes son aterradoras pero reveladoras. Es abrumador pensar en cómo estos modelos pueden ser armados, pero es información crucial. Quizás un poco más sobre cómo protegerse de ellos sería genial! 😅
0













