新聞文章摘要和分類:深入研究

 2025年04月27日
2025年04月27日

 LucasNelson
LucasNelson

 0
0
在當今快節奏的世界中,從各個方向向我們傳達信息,快速總結和分類新聞文章的能力比以往任何時候都更為重要。本文深入了解新聞文章的迷人世界摘要和分類,探索其背後的業務原因,用於準備數據的技術以及用於實現準確有效的結果的模型。
關鍵點
- 了解新聞文章摘要和分類背後的業務問題。
- 收集和預處理新聞文章數據的技術。
- 使用機器學習模型進行情感分析和文本摘要。
- 將模型部署在簡化應用程序中以進行實時使用。
- 用BLEU和Rouge分數等指標評估模型性能。
- 利用圖書館,例如美麗的湯,報紙3K和NLTK。
- 實施CRIRP-ML(Q)方法來簡化項目工作流程。
了解新聞文章的摘要和分類
業務問題
處理和分類新聞文章所需的手動努力可能是壓倒性的。想像以下圖片:您坐在桌子上,篩選無盡的文章,試圖編寫獨特的摘要並將其歸類為正面,負面或中立。這是耗時的和資源密集的。
這是自動化派上用場的地方。通過使流程自動化,我們不僅節省了時間,還減少了我們對手動勞動的依賴,從而釋放了其他任務的資源。機器學習步驟通過文本摘要和情感分析技術提供解決方案。
業務目標和約束
主要目標是最大程度地減少撰寫新文章的時間並減少手動干預。這對於需要快速獲取信息的新聞機構至關重要。
一個主要的限制是確保摘要和分類的準確性和質量。自動化系統必須捕獲原始文章的本質,同時準確地分類情感。目的是創建一個最小化手動努力的系統,同時保持高質量和可靠性的高標準。
通過了解業務問題,目標和約束,我們可以明確地關注提供有影響力的解決方案。新聞文章的摘要和分類可以顯著提高效率和資源分配。
項目體系結構和概述
項目流
該項目遵循一種結構化方法,並結合了幾個關鍵步驟。
- 業務理解:了解業務需求和目標是基礎。
- 數據收集:數據直接來自URL,主要關注馬來郵件文章和其他新聞來源。
- 數據準備:數據預處理對於清潔和準備文本數據至關重要,以進行有效的模型培訓。
- 探索性數據分析(EDA): EDA有助於了解數據,識別模式並完善方法。
- 模型評估:嚴格的評估確保模型符合所需的性能標準。
- 模型部署:最後一步涉及部署模型,使其可用於實時使用。
高級建築
該項目體系結構旨在穩健有效,結合了幾個階段,以確保運行平穩。
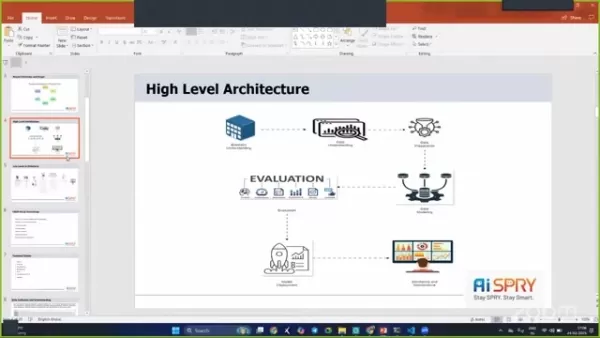
階段包括業務理解,數據理解,數據準備,數據建模,評估和部署。
技術堆棧和工具
為了成功實施該項目,使用了幾種技術堆棧和工具:
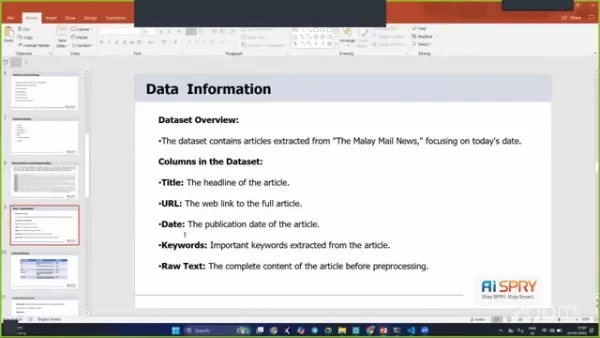
- Python:用於腳本和模型構建。
- 簡化:用於創建Web應用程序。
- 美麗的湯:用於網絡刮擦以從HTML中提取數據。
- 報紙3K:提取和解析新聞文章的高級圖書館。
- NLTK(自然語言工具包):用於英語的符號和統計自然語言處理(NLP)的庫和程序套件。
- 變形金剛(GPT-2):用於文本摘要任務。
- Distilbert:由於其效率和準確性而用於情感分析。
如何使用已部署的簡化應用
刮擦和加載數據
部署的簡化應用程序允許直接互動和分析新聞文章。
- 網絡刮擦:您可以直接從馬來郵件或其他來源刮擦數據來啟動該過程。此功能使用美麗的湯和報紙3K從指定的URL中提取相關文本。
- 數據加載:刮擦後,將數據加載到應用程序中以進行進一步處理。
執行文本摘要和情感分析
加載數據後,您可以執行文本摘要和其他任務以獲取最佳模型:
- 選擇一個NLP任務:根據您的需求,可以選擇各種任務。選項包括文本摘要,主題建模和文本分類。文本摘要使用GPT-2進行,提供簡潔而連貫的摘要。
- 情感分析:文章是根據情感(陽性,負或中性)進行分類的,使Distilbert檢查並確定最佳解決方案以獲得最佳結果。
利弊
優點
- 減少了處理新聞文章的手動努力和時間。
- 提供準確的情感分析和文本摘要。
- 提高新聞機構的效率。
- 使用強大的體系結構和高級機器學習模型。
缺點
- 需要用於網絡刮擦,數據處理和模型培訓的計算資源。
- 情感分析的準確性可能會根據文本的複雜性而有所不同。
- 需要維護。
常問問題
新聞文章摘要和分類的主要目標是什麼?
主要目標是減少總結和分類新聞文章所涉及的手動努力和時間。
該項目中使用了哪些主要技術工具?
使用Python,簡化,美麗的湯,報紙3K,NLTK,Transformers(GPT-2)和Distilbert。
Distilbert在項目中使用了什麼?
Distilbert由於其效率和準確性將文章分類為正,陰性或中性,因此被用於情感分析。
如何部署用於實時使用的模型?
該模型被部署在簡化應用程序中,使用戶可以實時與摘要和分類工具進行交互。
該項目中數據預處理的目的是什麼?
數據預處理涉及通過刪除不必要的字符,空間和停止字樣來清潔和準備文本數據,以提高機器學習模型的準確性。
相關問題
Crisp-Ml(Q)方法論如何改善項目成果?
CRIRP-ML(Q)方法可確保一種結構化方法挖掘和機器學習項目。它有助於更好的業務和數據理解,有效的數據準備以及徹底的模型評估,從而導致更成功的項目成果。通過遵循六個階段,該項目組織良好,並與業務目標保持一致。
相關文章
 indesign:將糊劑用於精簡圖形設計的功能
Adobe Indesign是用於圖形設計師的強大力量,其功能可以將您的佈局轉變為藝術品。 “粘貼到”功能中通常不被低估但功能強大的一個功能。該工具允許您將圖像,文本或其他對象直接放入前E
拜登的la腳鴨總統職位:破壞還是政治家?
隨著喬·拜登(Joe Biden)總統在任期的結束時,政治景觀引起了人們對他在最後幾周可能會做什麼的猜測。拜登被標記為“ la腳的鴨子”總統,對國內和國際事務仍然有重大影響。這篇文章探討了關鍵
AI電子書生成器:亞馬遜KDP成功的前5個工具
您是否渴望通過創建和銷售電子書來深入研究在線收入的世界?隨著AI技術的出現,該過程不僅變得有效,而且變得難以置信。本文深入研究了前五名AI電子書生成器,可以幫助您利用被動收入OP
評論 (0)
0/200
indesign:將糊劑用於精簡圖形設計的功能
Adobe Indesign是用於圖形設計師的強大力量,其功能可以將您的佈局轉變為藝術品。 “粘貼到”功能中通常不被低估但功能強大的一個功能。該工具允許您將圖像,文本或其他對象直接放入前E
拜登的la腳鴨總統職位:破壞還是政治家?
隨著喬·拜登(Joe Biden)總統在任期的結束時,政治景觀引起了人們對他在最後幾周可能會做什麼的猜測。拜登被標記為“ la腳的鴨子”總統,對國內和國際事務仍然有重大影響。這篇文章探討了關鍵
AI電子書生成器:亞馬遜KDP成功的前5個工具
您是否渴望通過創建和銷售電子書來深入研究在線收入的世界?隨著AI技術的出現,該過程不僅變得有效,而且變得難以置信。本文深入研究了前五名AI電子書生成器,可以幫助您利用被動收入OP
評論 (0)
0/200
2025年04月27日
LucasNelson
0
在當今快節奏的世界中,從各個方向向我們傳達信息,快速總結和分類新聞文章的能力比以往任何時候都更為重要。本文深入了解新聞文章的迷人世界摘要和分類,探索其背後的業務原因,用於準備數據的技術以及用於實現準確有效的結果的模型。
關鍵點
- 了解新聞文章摘要和分類背後的業務問題。
- 收集和預處理新聞文章數據的技術。
- 使用機器學習模型進行情感分析和文本摘要。
- 將模型部署在簡化應用程序中以進行實時使用。
- 用BLEU和Rouge分數等指標評估模型性能。
- 利用圖書館,例如美麗的湯,報紙3K和NLTK。
- 實施CRIRP-ML(Q)方法來簡化項目工作流程。
了解新聞文章的摘要和分類
業務問題
處理和分類新聞文章所需的手動努力可能是壓倒性的。想像以下圖片:您坐在桌子上,篩選無盡的文章,試圖編寫獨特的摘要並將其歸類為正面,負面或中立。這是耗時的和資源密集的。
這是自動化派上用場的地方。通過使流程自動化,我們不僅節省了時間,還減少了我們對手動勞動的依賴,從而釋放了其他任務的資源。機器學習步驟通過文本摘要和情感分析技術提供解決方案。
業務目標和約束
主要目標是最大程度地減少撰寫新文章的時間並減少手動干預。這對於需要快速獲取信息的新聞機構至關重要。
一個主要的限制是確保摘要和分類的準確性和質量。自動化系統必須捕獲原始文章的本質,同時準確地分類情感。目的是創建一個最小化手動努力的系統,同時保持高質量和可靠性的高標準。
通過了解業務問題,目標和約束,我們可以明確地關注提供有影響力的解決方案。新聞文章的摘要和分類可以顯著提高效率和資源分配。
項目體系結構和概述
項目流
該項目遵循一種結構化方法,並結合了幾個關鍵步驟。
- 業務理解:了解業務需求和目標是基礎。
- 數據收集:數據直接來自URL,主要關注馬來郵件文章和其他新聞來源。
- 數據準備:數據預處理對於清潔和準備文本數據至關重要,以進行有效的模型培訓。
- 探索性數據分析(EDA): EDA有助於了解數據,識別模式並完善方法。
- 模型評估:嚴格的評估確保模型符合所需的性能標準。
- 模型部署:最後一步涉及部署模型,使其可用於實時使用。
高級建築
該項目體系結構旨在穩健有效,結合了幾個階段,以確保運行平穩。
階段包括業務理解,數據理解,數據準備,數據建模,評估和部署。
技術堆棧和工具
為了成功實施該項目,使用了幾種技術堆棧和工具:
- Python:用於腳本和模型構建。
- 簡化:用於創建Web應用程序。
- 美麗的湯:用於網絡刮擦以從HTML中提取數據。
- 報紙3K:提取和解析新聞文章的高級圖書館。
- NLTK(自然語言工具包):用於英語的符號和統計自然語言處理(NLP)的庫和程序套件。
- 變形金剛(GPT-2):用於文本摘要任務。
- Distilbert:由於其效率和準確性而用於情感分析。
如何使用已部署的簡化應用
刮擦和加載數據
部署的簡化應用程序允許直接互動和分析新聞文章。
- 網絡刮擦:您可以直接從馬來郵件或其他來源刮擦數據來啟動該過程。此功能使用美麗的湯和報紙3K從指定的URL中提取相關文本。
- 數據加載:刮擦後,將數據加載到應用程序中以進行進一步處理。
執行文本摘要和情感分析
加載數據後,您可以執行文本摘要和其他任務以獲取最佳模型:
- 選擇一個NLP任務:根據您的需求,可以選擇各種任務。選項包括文本摘要,主題建模和文本分類。文本摘要使用GPT-2進行,提供簡潔而連貫的摘要。
- 情感分析:文章是根據情感(陽性,負或中性)進行分類的,使Distilbert檢查並確定最佳解決方案以獲得最佳結果。
利弊
優點
- 減少了處理新聞文章的手動努力和時間。
- 提供準確的情感分析和文本摘要。
- 提高新聞機構的效率。
- 使用強大的體系結構和高級機器學習模型。
缺點
- 需要用於網絡刮擦,數據處理和模型培訓的計算資源。
- 情感分析的準確性可能會根據文本的複雜性而有所不同。
- 需要維護。
常問問題
新聞文章摘要和分類的主要目標是什麼?
主要目標是減少總結和分類新聞文章所涉及的手動努力和時間。
該項目中使用了哪些主要技術工具?
使用Python,簡化,美麗的湯,報紙3K,NLTK,Transformers(GPT-2)和Distilbert。
Distilbert在項目中使用了什麼?
Distilbert由於其效率和準確性將文章分類為正,陰性或中性,因此被用於情感分析。
如何部署用於實時使用的模型?
該模型被部署在簡化應用程序中,使用戶可以實時與摘要和分類工具進行交互。
該項目中數據預處理的目的是什麼?
數據預處理涉及通過刪除不必要的字符,空間和停止字樣來清潔和準備文本數據,以提高機器學習模型的準確性。
相關問題
Crisp-Ml(Q)方法論如何改善項目成果?
CRIRP-ML(Q)方法可確保一種結構化方法挖掘和機器學習項目。它有助於更好的業務和數據理解,有效的數據準備以及徹底的模型評估,從而導致更成功的項目成果。通過遵循六個階段,該項目組織良好,並與業務目標保持一致。










 indesign:將糊劑用於精簡圖形設計的功能
Adobe Indesign是用於圖形設計師的強大力量,其功能可以將您的佈局轉變為藝術品。 “粘貼到”功能中通常不被低估但功能強大的一個功能。該工具允許您將圖像,文本或其他對象直接放入前E
indesign:將糊劑用於精簡圖形設計的功能
Adobe Indesign是用於圖形設計師的強大力量,其功能可以將您的佈局轉變為藝術品。 “粘貼到”功能中通常不被低估但功能強大的一個功能。該工具允許您將圖像,文本或其他對象直接放入前E
 拜登的la腳鴨總統職位:破壞還是政治家?
隨著喬·拜登(Joe Biden)總統在任期的結束時,政治景觀引起了人們對他在最後幾周可能會做什麼的猜測。拜登被標記為“ la腳的鴨子”總統,對國內和國際事務仍然有重大影響。這篇文章探討了關鍵
拜登的la腳鴨總統職位:破壞還是政治家?
隨著喬·拜登(Joe Biden)總統在任期的結束時,政治景觀引起了人們對他在最後幾周可能會做什麼的猜測。拜登被標記為“ la腳的鴨子”總統,對國內和國際事務仍然有重大影響。這篇文章探討了關鍵
 AI電子書生成器:亞馬遜KDP成功的前5個工具
您是否渴望通過創建和銷售電子書來深入研究在線收入的世界?隨著AI技術的出現,該過程不僅變得有效,而且變得難以置信。本文深入研究了前五名AI電子書生成器,可以幫助您利用被動收入OP
AI電子書生成器:亞馬遜KDP成功的前5個工具
您是否渴望通過創建和銷售電子書來深入研究在線收入的世界?隨著AI技術的出現,該過程不僅變得有效,而且變得難以置信。本文深入研究了前五名AI電子書生成器,可以幫助您利用被動收入OP