Résumé de l'article et classification: une plongée profonde

 27 avril 2025
27 avril 2025

 LucasNelson
LucasNelson

 0
0
Dans le monde au rythme rapide d'aujourd'hui, où les informations nous proviennent de toutes les directions, la capacité de résumer et de classer rapidement les articles de presse est plus importante que jamais. Cet article plonge dans le monde fascinant du résumé et de la classification des articles de presse, explorant les raisons commerciales derrière elle, les techniques utilisées pour préparer des données et les modèles utilisés pour obtenir des résultats précis et efficaces.
Points clés
- Comprendre le problème commercial derrière le résumé des articles et la classification.
- Techniques de collecte et de prétraitement des données de l'article d'information.
- Utilisation de modèles d'apprentissage automatique pour l'analyse des sentiments et le résumé de texte.
- Déploiement du modèle dans une application rationalisée pour une utilisation en temps réel.
- Évaluation des performances du modèle avec des mesures comme Bleu et Rouge Scores.
- Utiliser des bibliothèques telles que Beautiful Soup, Newspaper3K et NLTK.
- Implémentation de la méthodologie CRISP-ML (Q) pour rationaliser le flux de travail du projet.
Comprendre le résumé de l'article et la classification
Le problème commercial
L'effort manuel requis pour traiter et classer les articles de presse peut être écrasant. Imaginez ceci: vous êtes assis à votre bureau, en passant par les articles sans fin, en essayant d'écrire des résumés uniques et de les classer positifs, négatifs ou neutres. Il prend du temps et à forte intensité de ressources.
C'est là que l'automatisation est utile. En automatisant le processus, nous faisons non seulement gagner du temps, mais réduisons également notre dépendance à l'égard de la main-d'œuvre manuelle, libérant des ressources pour d'autres tâches. L'apprentissage automatique intervient pour offrir des solutions grâce à des techniques de résumé de texte et d'analyse des sentiments.
Objectifs et contraintes de l'entreprise
L'objectif principal est de minimiser le temps consacré à la rédaction de nouveaux articles et à réduire l'intervention manuelle. Ceci est crucial pour les organisations de presse qui ont besoin de réaliser des informations rapidement.
Une contrainte majeure consiste à garantir l'exactitude et la qualité des résumés et des classifications. Le système automatisé doit capturer l'essence de l'article d'origine tout en classant avec précision les sentiments. L'objectif est de créer un système qui minimise l'effort manuel tout en maintenant des normes élevées de qualité et de fiabilité.
En comprenant le problème commercial, les objectifs et les contraintes, nous pouvons aborder le projet en mettant clairement l'accent sur la fourniture de solutions percutantes. Le résumé des articles et la classification peut améliorer considérablement l'efficacité et l'allocation des ressources.
Architecture du projet et aperçu
Flux de projets
Le projet suit une approche structurée, incorporant plusieurs étapes clés.
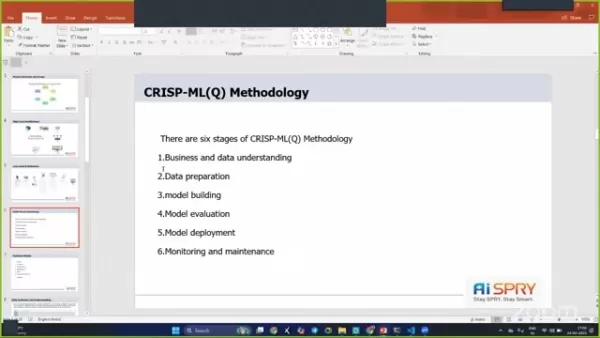
- Compréhension de l'entreprise: Comprendre les besoins et les objectifs de l'entreprise est le fondement.
- Collecte de données: les données proviennent directement des URL, se concentrant principalement sur les articles de messagerie malaise et d'autres sources d'information.
- Préparation des données: le prétraitement des données est essentiel pour nettoyer et préparer les données texte pour une formation de modèle efficace.
- Analyse des données exploratoires (EDA): EDA aide à obtenir un aperçu des données, à identifier les modèles et à affiner l'approche.
- Évaluation du modèle: une évaluation rigoureuse garantit que les modèles répondent aux normes de performance requises.
- Déploiement du modèle: l'étape finale consiste à déployer le modèle, ce qui le rend accessible pour une utilisation en temps réel.
Architecture de haut niveau
L'architecture du projet est conçue pour être robuste et efficace, incorporant plusieurs étapes pour assurer un fonctionnement en douceur.
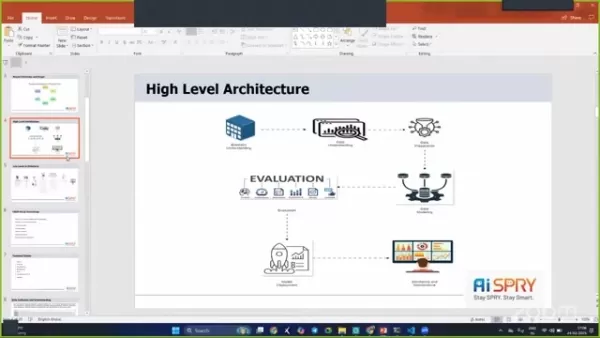
Les étapes incluent la compréhension des entreprises, la compréhension des données, la préparation des données, la modélisation des données, l'évaluation et le déploiement.
Piles et outils techniques utilisés
Pour mettre en œuvre le projet avec succès, plusieurs piles et outils techniques ont été utilisés:
- Python: Utilisé pour les scripts et la construction de modèles.
- Streamlit: utilisé pour créer l'application Web.
- Belle soupe: utilisée pour le grattage Web pour extraire les données de HTML.
- Journal3K: Une bibliothèque avancée pour extraire et analyser les articles de presse.
- NLTK (Natural Language Toolkit): une suite de bibliothèques et de programmes pour le traitement symbolique et statistique du langage naturel (PNL) pour l'anglais.
- Transformers (GPT-2): utilisé pour les tâches de résumé de texte.
- Distilbert: Utilisé pour l'analyse des sentiments en raison de son efficacité et de sa précision.
Comment utiliser l'application Streamlit déployée
Gratter et charger des données
L'application Streamlit déployée permet une interaction directe et une analyse des articles de presse.
- Stracage sur le Web: vous pouvez lancer le processus en grattant les données directement à partir du courrier malais ou d'autres sources. Cette fonctionnalité utilise une belle soupe et un journal3K pour extraire le texte pertinent des URL spécifiées.
- Chargement des données: Après le grattage, les données sont chargées dans l'application pour un traitement ultérieur.
Effectuer un résumé de texte et une analyse des sentiments
Une fois les données chargées, vous pouvez effectuer un résumé de texte et d'autres tâches pour obtenir le meilleur modèle:
- Choisissez une tâche PNL: Selon vos besoins, diverses tâches peuvent être choisies. Les options incluent le résumé de texte, la modélisation des sujets et la classification du texte. Le résumé de texte est effectué à l'aide de GPT-2, fournissant des résumés concis et cohérents.
- Analyse des sentiments: Les articles sont classés en fonction du sentiment - positif, négatif ou neutre - à l'aide de Distilbert pour vérifier et déterminer la meilleure solution pour obtenir le meilleur résultat.
Pour les avantages et les inconvénients
Pros
- Réduit l'effort manuel et le temps dans le traitement des articles de presse.
- Fournit une analyse précise des sentiments et un résumé de texte.
- Améliore l'efficacité des organisations de presse.
- Utilise une architecture robuste et des modèles avancés d'apprentissage automatique.
Inconvénients
- Nécessite des ressources informatiques pour le grattage Web, le traitement des données et la formation des modèles.
- La précision de l'analyse des sentiments peut varier en fonction de la complexité du texte.
- Une maintenance est nécessaire.
FAQ
Quel est l'objectif principal du résumé et de la classification des articles de presse?
L'objectif principal est de réduire les efforts manuels et le temps impliqués dans le résumé et la catégorisation des articles de presse.
Quels sont les principaux outils techniques utilisés dans ce projet?
Python, rationalisation, belle soupe, journal3K, NLTK, Transformers (GPT-2) et Distilbert sont utilisés.
À quoi est utilisé Distilbert dans le projet?
Distilbert est utilisé pour l'analyse des sentiments en raison de son efficacité et de sa précision dans la classification des articles comme positifs, négatifs ou neutres.
Comment le modèle est-il déployé pour une utilisation en temps réel?
Le modèle est déployé dans une application rationalisée, permettant aux utilisateurs d'interagir avec les outils de résumé et de classification en temps réel.
Quel est le but du prétraitement des données dans ce projet?
Le prétraitement des données implique le nettoyage et la préparation des données texte en supprimant les caractères, les espaces et les mots d'arrêt inutiles pour améliorer la précision des modèles d'apprentissage automatique.
Questions connexes
Comment la méthodologie CRISP-ML (Q) améliore-t-elle les résultats du projet?
La méthodologie CRISP-ML (Q) assure une approche structurée des projets d'exploration de données et d'apprentissage automatique. Il aide à une meilleure compréhension des entreprises et des données, une préparation efficace des données et une évaluation complète des modèles, ce qui conduit à des résultats de projet plus réussis. En suivant les six phases, ce projet est bien organisé et aligné sur les objectifs commerciaux.
Article connexe
 La présidence de canard boiteuse de Biden: sabotage ou état-état?
Alors que le président Joe Biden s'approche de la fin de son mandat, le paysage politique bourdonne de spéculations sur ce qu'il pourrait faire dans ses dernières semaines. Étiqueté comme un président de «canard boiteux», Biden a toujours une signification importante sur les affaires nationales et internationales. Cette pièce explore la critique
Générateurs de livres électroniques AI: Top 5 des outils pour le succès du KDP Amazon
Êtes-vous impatient de plonger dans le monde du revenu en ligne en créant et en vendant des livres électroniques? Avec l'avènement de la technologie de l'IA, le processus est devenu non seulement efficace mais aussi incroyablement accessible. Cet article plonge dans les cinq premiers générateurs d'ebook d'IA qui peuvent vous aider à tirer parti du revenu passif OP
«Rebel Yell» de Billy Idol: un regard approfondi sur la performance en direct
«Rebel Yell» de Billy Idol transcende d'être juste une chanson; C'est un emblème de la culture rock des années 1980 qui continue de résonner avec les fans à travers les générations. Cette pièce vous emmène dans un voyage à travers l'énergie pulsante et les visuels emblématiques d'une performance en direct «rebelle», démêlant les éléments que CEM
Commentaires (0)
0/200
La présidence de canard boiteuse de Biden: sabotage ou état-état?
Alors que le président Joe Biden s'approche de la fin de son mandat, le paysage politique bourdonne de spéculations sur ce qu'il pourrait faire dans ses dernières semaines. Étiqueté comme un président de «canard boiteux», Biden a toujours une signification importante sur les affaires nationales et internationales. Cette pièce explore la critique
Générateurs de livres électroniques AI: Top 5 des outils pour le succès du KDP Amazon
Êtes-vous impatient de plonger dans le monde du revenu en ligne en créant et en vendant des livres électroniques? Avec l'avènement de la technologie de l'IA, le processus est devenu non seulement efficace mais aussi incroyablement accessible. Cet article plonge dans les cinq premiers générateurs d'ebook d'IA qui peuvent vous aider à tirer parti du revenu passif OP
«Rebel Yell» de Billy Idol: un regard approfondi sur la performance en direct
«Rebel Yell» de Billy Idol transcende d'être juste une chanson; C'est un emblème de la culture rock des années 1980 qui continue de résonner avec les fans à travers les générations. Cette pièce vous emmène dans un voyage à travers l'énergie pulsante et les visuels emblématiques d'une performance en direct «rebelle», démêlant les éléments que CEM
Commentaires (0)
0/200
27 avril 2025
LucasNelson
0
Dans le monde au rythme rapide d'aujourd'hui, où les informations nous proviennent de toutes les directions, la capacité de résumer et de classer rapidement les articles de presse est plus importante que jamais. Cet article plonge dans le monde fascinant du résumé et de la classification des articles de presse, explorant les raisons commerciales derrière elle, les techniques utilisées pour préparer des données et les modèles utilisés pour obtenir des résultats précis et efficaces.
Points clés
- Comprendre le problème commercial derrière le résumé des articles et la classification.
- Techniques de collecte et de prétraitement des données de l'article d'information.
- Utilisation de modèles d'apprentissage automatique pour l'analyse des sentiments et le résumé de texte.
- Déploiement du modèle dans une application rationalisée pour une utilisation en temps réel.
- Évaluation des performances du modèle avec des mesures comme Bleu et Rouge Scores.
- Utiliser des bibliothèques telles que Beautiful Soup, Newspaper3K et NLTK.
- Implémentation de la méthodologie CRISP-ML (Q) pour rationaliser le flux de travail du projet.
Comprendre le résumé de l'article et la classification
Le problème commercial
L'effort manuel requis pour traiter et classer les articles de presse peut être écrasant. Imaginez ceci: vous êtes assis à votre bureau, en passant par les articles sans fin, en essayant d'écrire des résumés uniques et de les classer positifs, négatifs ou neutres. Il prend du temps et à forte intensité de ressources.
C'est là que l'automatisation est utile. En automatisant le processus, nous faisons non seulement gagner du temps, mais réduisons également notre dépendance à l'égard de la main-d'œuvre manuelle, libérant des ressources pour d'autres tâches. L'apprentissage automatique intervient pour offrir des solutions grâce à des techniques de résumé de texte et d'analyse des sentiments.
Objectifs et contraintes de l'entreprise
L'objectif principal est de minimiser le temps consacré à la rédaction de nouveaux articles et à réduire l'intervention manuelle. Ceci est crucial pour les organisations de presse qui ont besoin de réaliser des informations rapidement.
Une contrainte majeure consiste à garantir l'exactitude et la qualité des résumés et des classifications. Le système automatisé doit capturer l'essence de l'article d'origine tout en classant avec précision les sentiments. L'objectif est de créer un système qui minimise l'effort manuel tout en maintenant des normes élevées de qualité et de fiabilité.
En comprenant le problème commercial, les objectifs et les contraintes, nous pouvons aborder le projet en mettant clairement l'accent sur la fourniture de solutions percutantes. Le résumé des articles et la classification peut améliorer considérablement l'efficacité et l'allocation des ressources.
Architecture du projet et aperçu
Flux de projets
Le projet suit une approche structurée, incorporant plusieurs étapes clés.
- Compréhension de l'entreprise: Comprendre les besoins et les objectifs de l'entreprise est le fondement.
- Collecte de données: les données proviennent directement des URL, se concentrant principalement sur les articles de messagerie malaise et d'autres sources d'information.
- Préparation des données: le prétraitement des données est essentiel pour nettoyer et préparer les données texte pour une formation de modèle efficace.
- Analyse des données exploratoires (EDA): EDA aide à obtenir un aperçu des données, à identifier les modèles et à affiner l'approche.
- Évaluation du modèle: une évaluation rigoureuse garantit que les modèles répondent aux normes de performance requises.
- Déploiement du modèle: l'étape finale consiste à déployer le modèle, ce qui le rend accessible pour une utilisation en temps réel.
Architecture de haut niveau
L'architecture du projet est conçue pour être robuste et efficace, incorporant plusieurs étapes pour assurer un fonctionnement en douceur.
Les étapes incluent la compréhension des entreprises, la compréhension des données, la préparation des données, la modélisation des données, l'évaluation et le déploiement.
Piles et outils techniques utilisés
Pour mettre en œuvre le projet avec succès, plusieurs piles et outils techniques ont été utilisés:
- Python: Utilisé pour les scripts et la construction de modèles.
- Streamlit: utilisé pour créer l'application Web.
- Belle soupe: utilisée pour le grattage Web pour extraire les données de HTML.
- Journal3K: Une bibliothèque avancée pour extraire et analyser les articles de presse.
- NLTK (Natural Language Toolkit): une suite de bibliothèques et de programmes pour le traitement symbolique et statistique du langage naturel (PNL) pour l'anglais.
- Transformers (GPT-2): utilisé pour les tâches de résumé de texte.
- Distilbert: Utilisé pour l'analyse des sentiments en raison de son efficacité et de sa précision.
Comment utiliser l'application Streamlit déployée
Gratter et charger des données
L'application Streamlit déployée permet une interaction directe et une analyse des articles de presse.
- Stracage sur le Web: vous pouvez lancer le processus en grattant les données directement à partir du courrier malais ou d'autres sources. Cette fonctionnalité utilise une belle soupe et un journal3K pour extraire le texte pertinent des URL spécifiées.
- Chargement des données: Après le grattage, les données sont chargées dans l'application pour un traitement ultérieur.
Effectuer un résumé de texte et une analyse des sentiments
Une fois les données chargées, vous pouvez effectuer un résumé de texte et d'autres tâches pour obtenir le meilleur modèle:
- Choisissez une tâche PNL: Selon vos besoins, diverses tâches peuvent être choisies. Les options incluent le résumé de texte, la modélisation des sujets et la classification du texte. Le résumé de texte est effectué à l'aide de GPT-2, fournissant des résumés concis et cohérents.
- Analyse des sentiments: Les articles sont classés en fonction du sentiment - positif, négatif ou neutre - à l'aide de Distilbert pour vérifier et déterminer la meilleure solution pour obtenir le meilleur résultat.
Pour les avantages et les inconvénients
Pros
- Réduit l'effort manuel et le temps dans le traitement des articles de presse.
- Fournit une analyse précise des sentiments et un résumé de texte.
- Améliore l'efficacité des organisations de presse.
- Utilise une architecture robuste et des modèles avancés d'apprentissage automatique.
Inconvénients
- Nécessite des ressources informatiques pour le grattage Web, le traitement des données et la formation des modèles.
- La précision de l'analyse des sentiments peut varier en fonction de la complexité du texte.
- Une maintenance est nécessaire.
FAQ
Quel est l'objectif principal du résumé et de la classification des articles de presse?
L'objectif principal est de réduire les efforts manuels et le temps impliqués dans le résumé et la catégorisation des articles de presse.
Quels sont les principaux outils techniques utilisés dans ce projet?
Python, rationalisation, belle soupe, journal3K, NLTK, Transformers (GPT-2) et Distilbert sont utilisés.
À quoi est utilisé Distilbert dans le projet?
Distilbert est utilisé pour l'analyse des sentiments en raison de son efficacité et de sa précision dans la classification des articles comme positifs, négatifs ou neutres.
Comment le modèle est-il déployé pour une utilisation en temps réel?
Le modèle est déployé dans une application rationalisée, permettant aux utilisateurs d'interagir avec les outils de résumé et de classification en temps réel.
Quel est le but du prétraitement des données dans ce projet?
Le prétraitement des données implique le nettoyage et la préparation des données texte en supprimant les caractères, les espaces et les mots d'arrêt inutiles pour améliorer la précision des modèles d'apprentissage automatique.
Questions connexes
Comment la méthodologie CRISP-ML (Q) améliore-t-elle les résultats du projet?
La méthodologie CRISP-ML (Q) assure une approche structurée des projets d'exploration de données et d'apprentissage automatique. Il aide à une meilleure compréhension des entreprises et des données, une préparation efficace des données et une évaluation complète des modèles, ce qui conduit à des résultats de projet plus réussis. En suivant les six phases, ce projet est bien organisé et aligné sur les objectifs commerciaux.










 La présidence de canard boiteuse de Biden: sabotage ou état-état?
Alors que le président Joe Biden s'approche de la fin de son mandat, le paysage politique bourdonne de spéculations sur ce qu'il pourrait faire dans ses dernières semaines. Étiqueté comme un président de «canard boiteux», Biden a toujours une signification importante sur les affaires nationales et internationales. Cette pièce explore la critique
La présidence de canard boiteuse de Biden: sabotage ou état-état?
Alors que le président Joe Biden s'approche de la fin de son mandat, le paysage politique bourdonne de spéculations sur ce qu'il pourrait faire dans ses dernières semaines. Étiqueté comme un président de «canard boiteux», Biden a toujours une signification importante sur les affaires nationales et internationales. Cette pièce explore la critique
 Générateurs de livres électroniques AI: Top 5 des outils pour le succès du KDP Amazon
Êtes-vous impatient de plonger dans le monde du revenu en ligne en créant et en vendant des livres électroniques? Avec l'avènement de la technologie de l'IA, le processus est devenu non seulement efficace mais aussi incroyablement accessible. Cet article plonge dans les cinq premiers générateurs d'ebook d'IA qui peuvent vous aider à tirer parti du revenu passif OP
Générateurs de livres électroniques AI: Top 5 des outils pour le succès du KDP Amazon
Êtes-vous impatient de plonger dans le monde du revenu en ligne en créant et en vendant des livres électroniques? Avec l'avènement de la technologie de l'IA, le processus est devenu non seulement efficace mais aussi incroyablement accessible. Cet article plonge dans les cinq premiers générateurs d'ebook d'IA qui peuvent vous aider à tirer parti du revenu passif OP
 «Rebel Yell» de Billy Idol: un regard approfondi sur la performance en direct
«Rebel Yell» de Billy Idol transcende d'être juste une chanson; C'est un emblème de la culture rock des années 1980 qui continue de résonner avec les fans à travers les générations. Cette pièce vous emmène dans un voyage à travers l'énergie pulsante et les visuels emblématiques d'une performance en direct «rebelle», démêlant les éléments que CEM
«Rebel Yell» de Billy Idol: un regard approfondi sur la performance en direct
«Rebel Yell» de Billy Idol transcende d'être juste une chanson; C'est un emblème de la culture rock des années 1980 qui continue de résonner avec les fans à travers les générations. Cette pièce vous emmène dans un voyage à travers l'énergie pulsante et les visuels emblématiques d'une performance en direct «rebelle», démêlant les éléments que CEM