ニュース記事の要約と分類:深いダイビング

 2025年4月27日
2025年4月27日

 LucasNelson
LucasNelson

 0
0
情報があらゆる方向から私たちに届く今日のペースの速い世界では、ニュース記事を迅速に要約して分類する能力がこれまで以上に重要です。この記事では、ニュース記事の要約と分類の魅力的な世界に分かれ、その背後にあるビジネス上の理由、データの準備に使用される技術、および正確で効率的な結果を達成するために使用されるモデルを探ります。
キーポイント
- ニュース記事の要約と分類の背後にあるビジネス上の問題を理解する。
- ニュース記事データを収集および前処理するための手法。
- センチメント分析とテキストの要約に機械学習モデルを使用します。
- リアルタイムで使用するために、モデルを流線アプリケーションに展開します。
- ブルーやルージュのスコアなどのメトリックを使用したモデルパフォーマンスの評価。
- 美しいスープ、新聞3K、NLTKなどのライブラリを利用しています。
- プロジェクトワークフローを合理化するためのCRISP-ML(Q)方法論の実装。
ニュース記事の要約と分類を理解する
ビジネス上の問題
ニュース記事を処理して分類するために必要な手動の努力は圧倒的です。これを想像してください:あなたはあなたの机に座って、無限の記事をふるいにかけ、ユニークな要約を書き、それらをポジティブ、ネガティブ、またはニュートラルとして分類しようとしています。時間がかかり、リソースが集中しています。
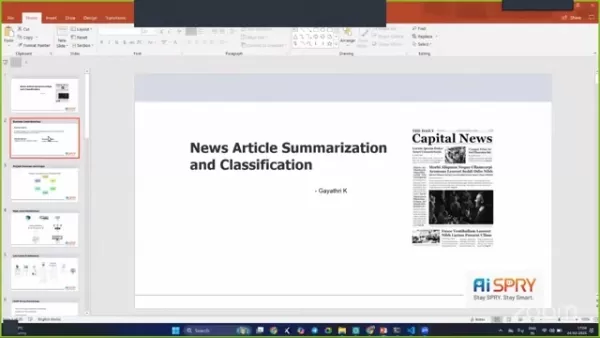
これは、自動化が役立つ場所です。プロセスを自動化することにより、時間を節約するだけでなく、肉体労働への依存を減らし、他のタスクのリソースを解放します。機械学習は、テキストの要約とセンチメント分析技術を通じてソリューションを提供するための措置を講じます。
ビジネス目標と制約
主な目標は、新しい記事を書くのに費やされた時間を最小限に抑え、手動介入を減らすことです。これは、情報を迅速に出す必要があるニュース組織にとって非常に重要です。
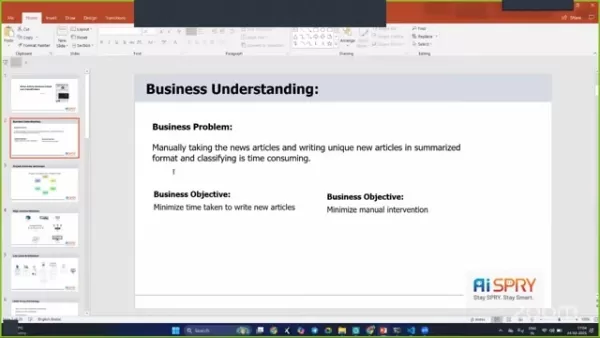
大きな制約の1つは、要約と分類の正確性と品質を確保することです。自動化されたシステムは、感情を正確に分類しながら、元の記事の本質をキャプチャする必要があります。目的は、品質と信頼性の高い基準を維持しながら、手動の努力を最小限に抑えるシステムを作成することです。
ビジネス上の問題、目標、制約を理解することにより、インパクトのあるソリューションの提供に明確に焦点を当ててプロジェクトにアプローチすることができます。ニュース記事の要約と分類は、効率とリソースの割り当てを大幅に改善できます。
プロジェクトアーキテクチャと概要
プロジェクトフロー
このプロジェクトは、いくつかの重要なステップを組み込んだ構造化されたアプローチに従います。
- ビジネスの理解:ビジネスのニーズと目的を理解することが基盤です。
- データ収集:データは、主にマレーメールの記事やその他のニュースソースに焦点を当てたURLから直接供給されます。
- データの準備:データの前処理は、効果的なモデルトレーニングのためにテキストデータをクリーニングして準備するために不可欠です。
- 探索的データ分析(EDA): EDAは、データの洞察を得るのを助け、パターンを特定し、アプローチを改善します。
- モデル評価:厳密な評価により、モデルは必要なパフォーマンス基準を満たします。
- モデルの展開:最後のステップでは、モデルを展開し、リアルタイムで使用できるようにすることが含まれます。
高レベルのアーキテクチャ
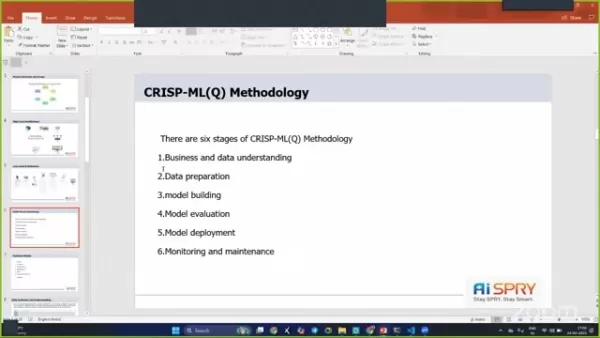
プロジェクトアーキテクチャは、堅牢で効率的であるように設計されており、いくつかの段階を組み込んでスムーズな動作を確保しています。
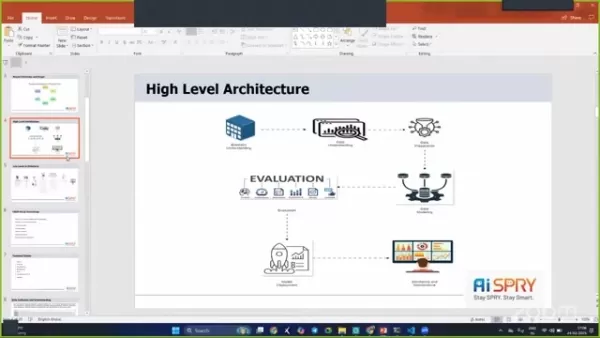
段階には、ビジネスの理解、データの理解、データの準備、データモデリング、評価、展開が含まれます。
使用される技術スタックとツール
プロジェクトを正常に実装するために、いくつかの技術的なスタックとツールが使用されました。
- Python:スクリプトとモデルの構築に使用されます。
- Restream -Lit: Webアプリケーションの作成に使用されます。
- 美しいスープ: HTMLからデータを抽出するためにWebスクレイピングに使用されます。
- Newspaper3K:ニュース記事を抽出して解析するための高度なライブラリ。
- NLTK(Natural Language Toolkit):英語向けのシンボリックおよび統計的自然言語処理(NLP)のライブラリとプログラムのスイート。
- トランス(GPT-2):テキスト要約タスクに使用されます。
- Distilbert:その効率と精度のため、感情分析に使用されます。
展開されたretrylitアプリの使用方法
データの削減と読み込み
展開されたretrylidアプリにより、ニュース記事の直接的な相互作用と分析が可能になります。
- Webスクレイピング: Malay Mailまたは他のソースから直接データを削減することで、プロセスを開始できます。この機能では、美しいスープと新聞3Kを使用して、指定されたURLから関連するテキストを抽出します。
- データの読み込み:スクレイピング後、データはアプリケーションにロードされ、さらに処理されます。
テキストの要約と感情分析を実行します
データがロードされたら、テキストの要約やその他のタスクを実行して、最適なモデルを取得できます。
- NLPタスクを選択します。ニーズに応じて、さまざまなタスクを選択できます。オプションには、テキストの要約、トピックモデリング、およびテキスト分類が含まれます。テキストの要約は、GPT-2を使用して実行され、簡潔で一貫した要約を提供します。
- センチメント分析:記事は感情に基づいて分類されます - 陽性、否定、または中立 - Distilbertを使用して、最良の結果を達成するための最良のソリューションをチェックおよび決定します。
長所と短所
長所
- ニュース記事の処理における手動の努力と時間を短縮します。
- 正確な感情分析とテキストの要約を提供します。
- ニュース組織の効率を高めます。
- 堅牢なアーキテクチャと高度な機械学習モデルを使用します。
短所
- Webスクレイピング、データ処理、モデルトレーニングのための計算リソースが必要です。
- 感情分析の精度は、テキストの複雑さによって異なる場合があります。
- メンテナンスが必要です。
よくある質問
ニュース記事の要約と分類の主な目標は何ですか?
主な目標は、ニュース記事の要約と分類に関与する手動の努力と時間を短縮することです。
このプロジェクトで使用されている主要な技術ツールは何ですか?
Python、Streamlit、Beautiful Soup、Newspaper3K、NLTK、Transformers(GPT-2)、およびDistilbertが使用されます。
プロジェクトでDistilbertが使用しているものは何ですか?
Distilbertは、記事を肯定的、否定的、または中性として分類する効率と精度のため、感情分析に使用されます。
モデルはリアルタイムで使用するためにどのように展開されますか?
このモデルは、retrylidアプリケーションに展開されているため、ユーザーは要約および分類ツールをリアルタイムでやり取りできます。
このプロジェクトでのデータ前処理の目的は何ですか?
データの前処理には、不要な文字、スペース、ストップワードを削除して、機械学習モデルの精度を向上させることにより、テキストデータのクリーニングと準備が含まれます。
関連する質問
Crisp-ML(Q)方法論はどのようにプロジェクトの成果を改善しますか?
CRISP-ML(Q)方法論は、データマイニングおよび機械学習プロジェクトへの構造化されたアプローチを保証します。より良いビジネスとデータの理解、効果的なデータの準備、徹底的なモデル評価に役立ち、より成功したプロジェクトの成果につながります。 6つのフェーズに従うことにより、このプロジェクトは十分に組織化されており、ビジネス目標と整合しています。
関連記事
 マスターindesign:合理化されたグラフィックデザインのために貼り付けを機能に使用します
Adobe Indesignは、レイアウトを芸術作品に変えることができる機能を備えたグラフィックデザイナー向けの大国です。しばしば過小評価されているが信じられないほど強力な機能の1つは、「貼り付け」機能です。このツールを使用すると、画像、テキスト、またはその他のオブジェクトをpre-eに落とすことができます
バイデンのラムダック大統領:妨害行為または政治家?
ジョー・バイデン大統領が彼の任期の終わりに近づくと、政治的景観は彼が最後の数週間で何をするかもしれないという憶測で賑わっています。 「ラムダック」大統領とラベル付けされたバイデンは、依然として国内および国際問題の両方に大きな揺れを抱いています。この作品は批判的なことを探ります
AI電子ブックジェネレーター:Amazon KDP成功のためのトップ5ツール
電子書籍を作成して販売することで、オンライン収入の世界に飛び込むことに熱心ですか? AIテクノロジーの出現により、このプロセスは効率的であるだけでなく、非常にアクセスしやすくなっています。この記事は、パッシブ収入opを活用するのに役立つ上位5つのAI電子ブックジェネレーターを掘り下げています
コメント (0)
0/200
マスターindesign:合理化されたグラフィックデザインのために貼り付けを機能に使用します
Adobe Indesignは、レイアウトを芸術作品に変えることができる機能を備えたグラフィックデザイナー向けの大国です。しばしば過小評価されているが信じられないほど強力な機能の1つは、「貼り付け」機能です。このツールを使用すると、画像、テキスト、またはその他のオブジェクトをpre-eに落とすことができます
バイデンのラムダック大統領:妨害行為または政治家?
ジョー・バイデン大統領が彼の任期の終わりに近づくと、政治的景観は彼が最後の数週間で何をするかもしれないという憶測で賑わっています。 「ラムダック」大統領とラベル付けされたバイデンは、依然として国内および国際問題の両方に大きな揺れを抱いています。この作品は批判的なことを探ります
AI電子ブックジェネレーター:Amazon KDP成功のためのトップ5ツール
電子書籍を作成して販売することで、オンライン収入の世界に飛び込むことに熱心ですか? AIテクノロジーの出現により、このプロセスは効率的であるだけでなく、非常にアクセスしやすくなっています。この記事は、パッシブ収入opを活用するのに役立つ上位5つのAI電子ブックジェネレーターを掘り下げています
コメント (0)
0/200
2025年4月27日
LucasNelson
0
情報があらゆる方向から私たちに届く今日のペースの速い世界では、ニュース記事を迅速に要約して分類する能力がこれまで以上に重要です。この記事では、ニュース記事の要約と分類の魅力的な世界に分かれ、その背後にあるビジネス上の理由、データの準備に使用される技術、および正確で効率的な結果を達成するために使用されるモデルを探ります。
キーポイント
- ニュース記事の要約と分類の背後にあるビジネス上の問題を理解する。
- ニュース記事データを収集および前処理するための手法。
- センチメント分析とテキストの要約に機械学習モデルを使用します。
- リアルタイムで使用するために、モデルを流線アプリケーションに展開します。
- ブルーやルージュのスコアなどのメトリックを使用したモデルパフォーマンスの評価。
- 美しいスープ、新聞3K、NLTKなどのライブラリを利用しています。
- プロジェクトワークフローを合理化するためのCRISP-ML(Q)方法論の実装。
ニュース記事の要約と分類を理解する
ビジネス上の問題
ニュース記事を処理して分類するために必要な手動の努力は圧倒的です。これを想像してください:あなたはあなたの机に座って、無限の記事をふるいにかけ、ユニークな要約を書き、それらをポジティブ、ネガティブ、またはニュートラルとして分類しようとしています。時間がかかり、リソースが集中しています。
これは、自動化が役立つ場所です。プロセスを自動化することにより、時間を節約するだけでなく、肉体労働への依存を減らし、他のタスクのリソースを解放します。機械学習は、テキストの要約とセンチメント分析技術を通じてソリューションを提供するための措置を講じます。
ビジネス目標と制約
主な目標は、新しい記事を書くのに費やされた時間を最小限に抑え、手動介入を減らすことです。これは、情報を迅速に出す必要があるニュース組織にとって非常に重要です。
大きな制約の1つは、要約と分類の正確性と品質を確保することです。自動化されたシステムは、感情を正確に分類しながら、元の記事の本質をキャプチャする必要があります。目的は、品質と信頼性の高い基準を維持しながら、手動の努力を最小限に抑えるシステムを作成することです。
ビジネス上の問題、目標、制約を理解することにより、インパクトのあるソリューションの提供に明確に焦点を当ててプロジェクトにアプローチすることができます。ニュース記事の要約と分類は、効率とリソースの割り当てを大幅に改善できます。
プロジェクトアーキテクチャと概要
プロジェクトフロー
このプロジェクトは、いくつかの重要なステップを組み込んだ構造化されたアプローチに従います。
- ビジネスの理解:ビジネスのニーズと目的を理解することが基盤です。
- データ収集:データは、主にマレーメールの記事やその他のニュースソースに焦点を当てたURLから直接供給されます。
- データの準備:データの前処理は、効果的なモデルトレーニングのためにテキストデータをクリーニングして準備するために不可欠です。
- 探索的データ分析(EDA): EDAは、データの洞察を得るのを助け、パターンを特定し、アプローチを改善します。
- モデル評価:厳密な評価により、モデルは必要なパフォーマンス基準を満たします。
- モデルの展開:最後のステップでは、モデルを展開し、リアルタイムで使用できるようにすることが含まれます。
高レベルのアーキテクチャ
プロジェクトアーキテクチャは、堅牢で効率的であるように設計されており、いくつかの段階を組み込んでスムーズな動作を確保しています。
段階には、ビジネスの理解、データの理解、データの準備、データモデリング、評価、展開が含まれます。
使用される技術スタックとツール
プロジェクトを正常に実装するために、いくつかの技術的なスタックとツールが使用されました。
- Python:スクリプトとモデルの構築に使用されます。
- Restream -Lit: Webアプリケーションの作成に使用されます。
- 美しいスープ: HTMLからデータを抽出するためにWebスクレイピングに使用されます。
- Newspaper3K:ニュース記事を抽出して解析するための高度なライブラリ。
- NLTK(Natural Language Toolkit):英語向けのシンボリックおよび統計的自然言語処理(NLP)のライブラリとプログラムのスイート。
- トランス(GPT-2):テキスト要約タスクに使用されます。
- Distilbert:その効率と精度のため、感情分析に使用されます。
展開されたretrylitアプリの使用方法
データの削減と読み込み
展開されたretrylidアプリにより、ニュース記事の直接的な相互作用と分析が可能になります。
- Webスクレイピング: Malay Mailまたは他のソースから直接データを削減することで、プロセスを開始できます。この機能では、美しいスープと新聞3Kを使用して、指定されたURLから関連するテキストを抽出します。
- データの読み込み:スクレイピング後、データはアプリケーションにロードされ、さらに処理されます。
テキストの要約と感情分析を実行します
データがロードされたら、テキストの要約やその他のタスクを実行して、最適なモデルを取得できます。
- NLPタスクを選択します。ニーズに応じて、さまざまなタスクを選択できます。オプションには、テキストの要約、トピックモデリング、およびテキスト分類が含まれます。テキストの要約は、GPT-2を使用して実行され、簡潔で一貫した要約を提供します。
- センチメント分析:記事は感情に基づいて分類されます - 陽性、否定、または中立 - Distilbertを使用して、最良の結果を達成するための最良のソリューションをチェックおよび決定します。
長所と短所
長所
- ニュース記事の処理における手動の努力と時間を短縮します。
- 正確な感情分析とテキストの要約を提供します。
- ニュース組織の効率を高めます。
- 堅牢なアーキテクチャと高度な機械学習モデルを使用します。
短所
- Webスクレイピング、データ処理、モデルトレーニングのための計算リソースが必要です。
- 感情分析の精度は、テキストの複雑さによって異なる場合があります。
- メンテナンスが必要です。
よくある質問
ニュース記事の要約と分類の主な目標は何ですか?
主な目標は、ニュース記事の要約と分類に関与する手動の努力と時間を短縮することです。
このプロジェクトで使用されている主要な技術ツールは何ですか?
Python、Streamlit、Beautiful Soup、Newspaper3K、NLTK、Transformers(GPT-2)、およびDistilbertが使用されます。
プロジェクトでDistilbertが使用しているものは何ですか?
Distilbertは、記事を肯定的、否定的、または中性として分類する効率と精度のため、感情分析に使用されます。
モデルはリアルタイムで使用するためにどのように展開されますか?
このモデルは、retrylidアプリケーションに展開されているため、ユーザーは要約および分類ツールをリアルタイムでやり取りできます。
このプロジェクトでのデータ前処理の目的は何ですか?
データの前処理には、不要な文字、スペース、ストップワードを削除して、機械学習モデルの精度を向上させることにより、テキストデータのクリーニングと準備が含まれます。
関連する質問
Crisp-ML(Q)方法論はどのようにプロジェクトの成果を改善しますか?
CRISP-ML(Q)方法論は、データマイニングおよび機械学習プロジェクトへの構造化されたアプローチを保証します。より良いビジネスとデータの理解、効果的なデータの準備、徹底的なモデル評価に役立ち、より成功したプロジェクトの成果につながります。 6つのフェーズに従うことにより、このプロジェクトは十分に組織化されており、ビジネス目標と整合しています。










 マスターindesign:合理化されたグラフィックデザインのために貼り付けを機能に使用します
Adobe Indesignは、レイアウトを芸術作品に変えることができる機能を備えたグラフィックデザイナー向けの大国です。しばしば過小評価されているが信じられないほど強力な機能の1つは、「貼り付け」機能です。このツールを使用すると、画像、テキスト、またはその他のオブジェクトをpre-eに落とすことができます
マスターindesign:合理化されたグラフィックデザインのために貼り付けを機能に使用します
Adobe Indesignは、レイアウトを芸術作品に変えることができる機能を備えたグラフィックデザイナー向けの大国です。しばしば過小評価されているが信じられないほど強力な機能の1つは、「貼り付け」機能です。このツールを使用すると、画像、テキスト、またはその他のオブジェクトをpre-eに落とすことができます
 バイデンのラムダック大統領:妨害行為または政治家?
ジョー・バイデン大統領が彼の任期の終わりに近づくと、政治的景観は彼が最後の数週間で何をするかもしれないという憶測で賑わっています。 「ラムダック」大統領とラベル付けされたバイデンは、依然として国内および国際問題の両方に大きな揺れを抱いています。この作品は批判的なことを探ります
バイデンのラムダック大統領:妨害行為または政治家?
ジョー・バイデン大統領が彼の任期の終わりに近づくと、政治的景観は彼が最後の数週間で何をするかもしれないという憶測で賑わっています。 「ラムダック」大統領とラベル付けされたバイデンは、依然として国内および国際問題の両方に大きな揺れを抱いています。この作品は批判的なことを探ります
 AI電子ブックジェネレーター:Amazon KDP成功のためのトップ5ツール
電子書籍を作成して販売することで、オンライン収入の世界に飛び込むことに熱心ですか? AIテクノロジーの出現により、このプロセスは効率的であるだけでなく、非常にアクセスしやすくなっています。この記事は、パッシブ収入opを活用するのに役立つ上位5つのAI電子ブックジェネレーターを掘り下げています
AI電子ブックジェネレーター:Amazon KDP成功のためのトップ5ツール
電子書籍を作成して販売することで、オンライン収入の世界に飛び込むことに熱心ですか? AIテクノロジーの出現により、このプロセスは効率的であるだけでなく、非常にアクセスしやすくなっています。この記事は、パッシブ収入opを活用するのに役立つ上位5つのAI電子ブックジェネレーターを掘り下げています