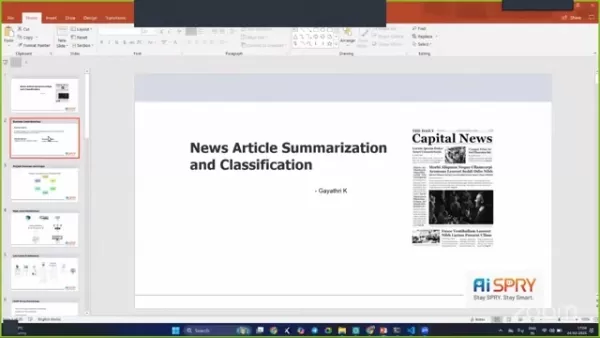
新闻文章摘要和分类:深入研究

 2025年04月27日
2025年04月27日

 LucasNelson
LucasNelson

 0
0
在当今快节奏的世界中,从各个方向向我们传达信息,快速总结和分类新闻文章的能力比以往任何时候都更为重要。本文深入了解新闻文章的迷人世界摘要和分类,探索其背后的业务原因,用于准备数据的技术以及用于实现准确有效的结果的模型。
关键点
- 了解新闻文章摘要和分类背后的业务问题。
- 收集和预处理新闻文章数据的技术。
- 使用机器学习模型进行情感分析和文本摘要。
- 将模型部署在简化应用程序中以进行实时使用。
- 用BLEU和Rouge分数等指标评估模型性能。
- 利用图书馆,例如美丽的汤,报纸3K和NLTK。
- 实施CRIRP-ML(Q)方法来简化项目工作流程。
了解新闻文章的摘要和分类
业务问题
处理和分类新闻文章所需的手动努力可能是压倒性的。想象以下图片:您坐在桌子上,筛选无尽的文章,试图编写独特的摘要并将其归类为正面,负面或中立。这是耗时的和资源密集的。
这是自动化派上用场的地方。通过使流程自动化,我们不仅节省了时间,还减少了我们对手动劳动的依赖,从而释放了其他任务的资源。机器学习步骤通过文本摘要和情感分析技术提供解决方案。
业务目标和约束
主要目标是最大程度地减少撰写新文章的时间并减少手动干预。这对于需要快速获取信息的新闻机构至关重要。
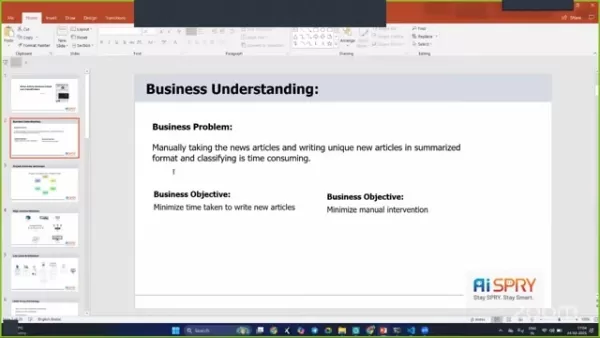
一个主要的限制是确保摘要和分类的准确性和质量。自动化系统必须捕获原始文章的本质,同时准确地分类情感。目的是创建一个最小化手动努力的系统,同时保持高质量和可靠性的高标准。
通过了解业务问题,目标和约束,我们可以明确地关注提供有影响力的解决方案。新闻文章的摘要和分类可以显着提高效率和资源分配。
项目体系结构和概述
项目流
该项目遵循一种结构化方法,并结合了几个关键步骤。
- 业务理解:了解业务需求和目标是基础。
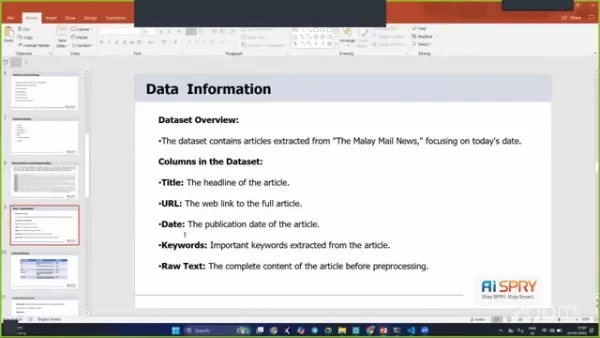
- 数据收集:数据直接来自URL,主要关注马来邮件文章和其他新闻来源。
- 数据准备:数据预处理对于清洁和准备文本数据至关重要,以进行有效的模型培训。
- 探索性数据分析(EDA): EDA有助于了解数据,识别模式并完善方法。
- 模型评估:严格的评估确保模型符合所需的性能标准。
- 模型部署:最后一步涉及部署模型,使其可用于实时使用。
高级建筑
该项目体系结构旨在稳健有效,结合了几个阶段,以确保运行平稳。
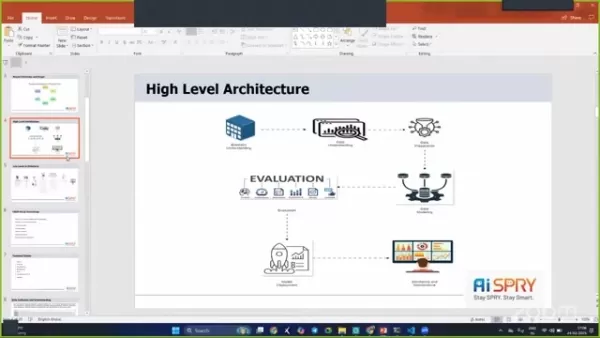
阶段包括业务理解,数据理解,数据准备,数据建模,评估和部署。
技术堆栈和工具
为了成功实施该项目,使用了几种技术堆栈和工具:
- Python:用于脚本和模型构建。
- 简化:用于创建Web应用程序。
- 美丽的汤:用于网络刮擦以从HTML中提取数据。
- 报纸3K:提取和解析新闻文章的高级图书馆。
- NLTK(自然语言工具包):用于英语的符号和统计自然语言处理(NLP)的库和程序套件。
- 变形金刚(GPT-2):用于文本摘要任务。
- Distilbert:由于其效率和准确性而用于情感分析。
如何使用已部署的简化应用
刮擦和加载数据
部署的简化应用程序允许直接互动和分析新闻文章。
- 网络刮擦:您可以直接从马来邮件或其他来源刮擦数据来启动该过程。此功能使用美丽的汤和报纸3K从指定的URL中提取相关文本。
- 数据加载:刮擦后,将数据加载到应用程序中以进行进一步处理。
执行文本摘要和情感分析
加载数据后,您可以执行文本摘要和其他任务以获取最佳模型:
- 选择一个NLP任务:根据您的需求,可以选择各种任务。选项包括文本摘要,主题建模和文本分类。文本摘要使用GPT-2进行,提供简洁而连贯的摘要。
- 情感分析:文章是根据情感(阳性,负或中性)进行分类的,使Distilbert检查并确定最佳解决方案以获得最佳结果。
利弊
优点
- 减少了处理新闻文章的手动努力和时间。
- 提供准确的情感分析和文本摘要。
- 提高新闻机构的效率。
- 使用强大的体系结构和高级机器学习模型。
缺点
- 需要用于网络刮擦,数据处理和模型培训的计算资源。
- 情感分析的准确性可能会根据文本的复杂性而有所不同。
- 需要维护。
常问问题
新闻文章摘要和分类的主要目标是什么?
主要目标是减少总结和分类新闻文章所涉及的手动努力和时间。
该项目中使用了哪些主要技术工具?
使用Python,简化,美丽的汤,报纸3K,NLTK,Transformers(GPT-2)和Distilbert。
Distilbert在项目中使用了什么?
Distilbert由于其效率和准确性将文章分类为正,阴性或中性,因此被用于情感分析。
如何部署用于实时使用的模型?
该模型被部署在简化应用程序中,使用户可以实时与摘要和分类工具进行交互。
该项目中数据预处理的目的是什么?
数据预处理涉及通过删除不必要的字符,空间和停止字样来清洁和准备文本数据,以提高机器学习模型的准确性。
相关问题
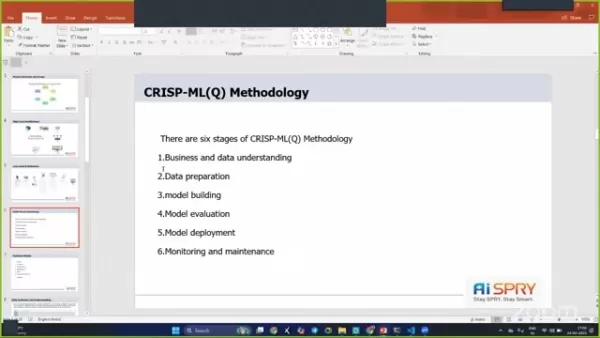
Crisp-Ml(Q)方法论如何改善项目成果?
CRIRP-ML(Q)方法可确保一种结构化方法挖掘和机器学习项目。它有助于更好的业务和数据理解,有效的数据准备以及彻底的模型评估,从而导致更成功的项目成果。通过遵循六个阶段,该项目组织良好,并与业务目标保持一致。
相关文章
 indesign:将糊剂用于精简图形设计的功能
Adobe Indesign是用于图形设计师的强大力量,其功能可以将您的布局转变为艺术品。 “粘贴到”功能中通常不被低估但功能强大的一个功能。该工具允许您将图像,文本或其他对象直接放入前E
拜登的la脚鸭总统职位:破坏还是政治家?
随着乔·拜登(Joe Biden)总统在任期的结束时,政治景观引起了人们对他在最后几周可能会做什么的猜测。拜登被标记为“ la脚的鸭子”总统,对国内和国际事务仍然有重大影响。这篇文章探讨了关键
AI电子书生成器:亚马逊KDP成功的前5个工具
您是否渴望通过创建和销售电子书来深入研究在线收入的世界?随着AI技术的出现,该过程不仅变得有效,而且变得难以置信。本文深入研究了前五名AI电子书生成器,可以帮助您利用被动收入OP
评论 (0)
0/200
indesign:将糊剂用于精简图形设计的功能
Adobe Indesign是用于图形设计师的强大力量,其功能可以将您的布局转变为艺术品。 “粘贴到”功能中通常不被低估但功能强大的一个功能。该工具允许您将图像,文本或其他对象直接放入前E
拜登的la脚鸭总统职位:破坏还是政治家?
随着乔·拜登(Joe Biden)总统在任期的结束时,政治景观引起了人们对他在最后几周可能会做什么的猜测。拜登被标记为“ la脚的鸭子”总统,对国内和国际事务仍然有重大影响。这篇文章探讨了关键
AI电子书生成器:亚马逊KDP成功的前5个工具
您是否渴望通过创建和销售电子书来深入研究在线收入的世界?随着AI技术的出现,该过程不仅变得有效,而且变得难以置信。本文深入研究了前五名AI电子书生成器,可以帮助您利用被动收入OP
评论 (0)
0/200
2025年04月27日
LucasNelson
0
在当今快节奏的世界中,从各个方向向我们传达信息,快速总结和分类新闻文章的能力比以往任何时候都更为重要。本文深入了解新闻文章的迷人世界摘要和分类,探索其背后的业务原因,用于准备数据的技术以及用于实现准确有效的结果的模型。
关键点
- 了解新闻文章摘要和分类背后的业务问题。
- 收集和预处理新闻文章数据的技术。
- 使用机器学习模型进行情感分析和文本摘要。
- 将模型部署在简化应用程序中以进行实时使用。
- 用BLEU和Rouge分数等指标评估模型性能。
- 利用图书馆,例如美丽的汤,报纸3K和NLTK。
- 实施CRIRP-ML(Q)方法来简化项目工作流程。
了解新闻文章的摘要和分类
业务问题
处理和分类新闻文章所需的手动努力可能是压倒性的。想象以下图片:您坐在桌子上,筛选无尽的文章,试图编写独特的摘要并将其归类为正面,负面或中立。这是耗时的和资源密集的。
这是自动化派上用场的地方。通过使流程自动化,我们不仅节省了时间,还减少了我们对手动劳动的依赖,从而释放了其他任务的资源。机器学习步骤通过文本摘要和情感分析技术提供解决方案。
业务目标和约束
主要目标是最大程度地减少撰写新文章的时间并减少手动干预。这对于需要快速获取信息的新闻机构至关重要。
一个主要的限制是确保摘要和分类的准确性和质量。自动化系统必须捕获原始文章的本质,同时准确地分类情感。目的是创建一个最小化手动努力的系统,同时保持高质量和可靠性的高标准。
通过了解业务问题,目标和约束,我们可以明确地关注提供有影响力的解决方案。新闻文章的摘要和分类可以显着提高效率和资源分配。
项目体系结构和概述
项目流
该项目遵循一种结构化方法,并结合了几个关键步骤。
- 业务理解:了解业务需求和目标是基础。
- 数据收集:数据直接来自URL,主要关注马来邮件文章和其他新闻来源。
- 数据准备:数据预处理对于清洁和准备文本数据至关重要,以进行有效的模型培训。
- 探索性数据分析(EDA): EDA有助于了解数据,识别模式并完善方法。
- 模型评估:严格的评估确保模型符合所需的性能标准。
- 模型部署:最后一步涉及部署模型,使其可用于实时使用。
高级建筑
该项目体系结构旨在稳健有效,结合了几个阶段,以确保运行平稳。
阶段包括业务理解,数据理解,数据准备,数据建模,评估和部署。
技术堆栈和工具
为了成功实施该项目,使用了几种技术堆栈和工具:
- Python:用于脚本和模型构建。
- 简化:用于创建Web应用程序。
- 美丽的汤:用于网络刮擦以从HTML中提取数据。
- 报纸3K:提取和解析新闻文章的高级图书馆。
- NLTK(自然语言工具包):用于英语的符号和统计自然语言处理(NLP)的库和程序套件。
- 变形金刚(GPT-2):用于文本摘要任务。
- Distilbert:由于其效率和准确性而用于情感分析。
如何使用已部署的简化应用
刮擦和加载数据
部署的简化应用程序允许直接互动和分析新闻文章。
- 网络刮擦:您可以直接从马来邮件或其他来源刮擦数据来启动该过程。此功能使用美丽的汤和报纸3K从指定的URL中提取相关文本。
- 数据加载:刮擦后,将数据加载到应用程序中以进行进一步处理。
执行文本摘要和情感分析
加载数据后,您可以执行文本摘要和其他任务以获取最佳模型:
- 选择一个NLP任务:根据您的需求,可以选择各种任务。选项包括文本摘要,主题建模和文本分类。文本摘要使用GPT-2进行,提供简洁而连贯的摘要。
- 情感分析:文章是根据情感(阳性,负或中性)进行分类的,使Distilbert检查并确定最佳解决方案以获得最佳结果。
利弊
优点
- 减少了处理新闻文章的手动努力和时间。
- 提供准确的情感分析和文本摘要。
- 提高新闻机构的效率。
- 使用强大的体系结构和高级机器学习模型。
缺点
- 需要用于网络刮擦,数据处理和模型培训的计算资源。
- 情感分析的准确性可能会根据文本的复杂性而有所不同。
- 需要维护。
常问问题
新闻文章摘要和分类的主要目标是什么?
主要目标是减少总结和分类新闻文章所涉及的手动努力和时间。
该项目中使用了哪些主要技术工具?
使用Python,简化,美丽的汤,报纸3K,NLTK,Transformers(GPT-2)和Distilbert。
Distilbert在项目中使用了什么?
Distilbert由于其效率和准确性将文章分类为正,阴性或中性,因此被用于情感分析。
如何部署用于实时使用的模型?
该模型被部署在简化应用程序中,使用户可以实时与摘要和分类工具进行交互。
该项目中数据预处理的目的是什么?
数据预处理涉及通过删除不必要的字符,空间和停止字样来清洁和准备文本数据,以提高机器学习模型的准确性。
相关问题
Crisp-Ml(Q)方法论如何改善项目成果?
CRIRP-ML(Q)方法可确保一种结构化方法挖掘和机器学习项目。它有助于更好的业务和数据理解,有效的数据准备以及彻底的模型评估,从而导致更成功的项目成果。通过遵循六个阶段,该项目组织良好,并与业务目标保持一致。










 indesign:将糊剂用于精简图形设计的功能
Adobe Indesign是用于图形设计师的强大力量,其功能可以将您的布局转变为艺术品。 “粘贴到”功能中通常不被低估但功能强大的一个功能。该工具允许您将图像,文本或其他对象直接放入前E
indesign:将糊剂用于精简图形设计的功能
Adobe Indesign是用于图形设计师的强大力量,其功能可以将您的布局转变为艺术品。 “粘贴到”功能中通常不被低估但功能强大的一个功能。该工具允许您将图像,文本或其他对象直接放入前E
 拜登的la脚鸭总统职位:破坏还是政治家?
随着乔·拜登(Joe Biden)总统在任期的结束时,政治景观引起了人们对他在最后几周可能会做什么的猜测。拜登被标记为“ la脚的鸭子”总统,对国内和国际事务仍然有重大影响。这篇文章探讨了关键
拜登的la脚鸭总统职位:破坏还是政治家?
随着乔·拜登(Joe Biden)总统在任期的结束时,政治景观引起了人们对他在最后几周可能会做什么的猜测。拜登被标记为“ la脚的鸭子”总统,对国内和国际事务仍然有重大影响。这篇文章探讨了关键
 AI电子书生成器:亚马逊KDP成功的前5个工具
您是否渴望通过创建和销售电子书来深入研究在线收入的世界?随着AI技术的出现,该过程不仅变得有效,而且变得难以置信。本文深入研究了前五名AI电子书生成器,可以帮助您利用被动收入OP
AI电子书生成器:亚马逊KDP成功的前5个工具
您是否渴望通过创建和销售电子书来深入研究在线收入的世界?随着AI技术的出现,该过程不仅变得有效,而且变得难以置信。本文深入研究了前五名AI电子书生成器,可以帮助您利用被动收入OP