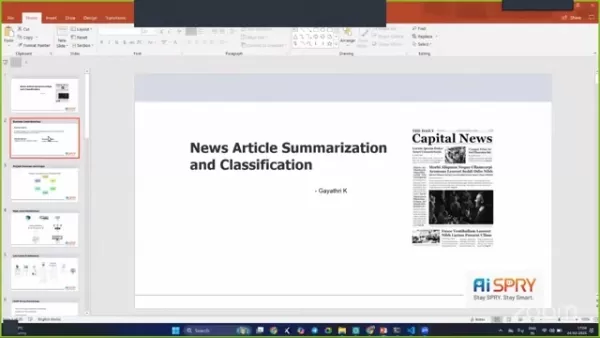
News Article Summarization and Classification: A Deep Dive

 April 27, 2025
April 27, 2025

 LucasNelson
LucasNelson

 0
0
In today's fast-paced world, where information comes at us from all directions, the ability to quickly summarize and categorize news articles is more important than ever. This article dives into the fascinating world of news article summarization and classification, exploring the business reasons behind it, the techniques used for preparing data, and the models used to achieve accurate and efficient results.
Key Points
- Understanding the business problem behind news article summarization and classification.
- Techniques for collecting and preprocessing news article data.
- Using machine learning models for sentiment analysis and text summarization.
- Deploying the model in a Streamlit application for real-time use.
- Evaluating model performance with metrics like BLEU and Rouge scores.
- Utilizing libraries such as Beautiful Soup, Newspaper3k, and NLTK.
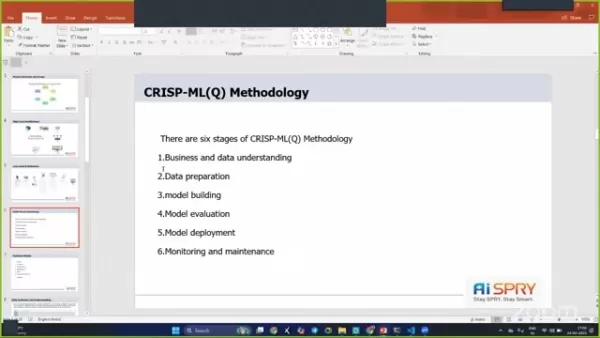
- Implementing the CRISP-ML(Q) methodology to streamline the project workflow.
Understanding News Article Summarization and Classification
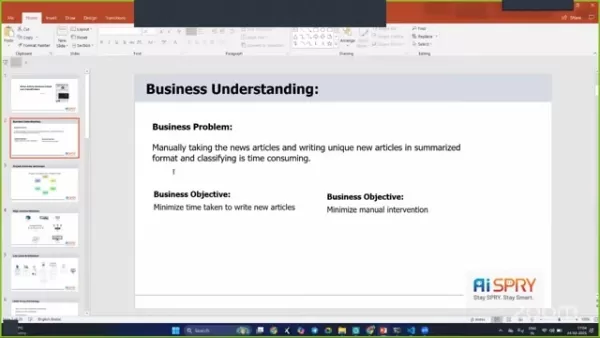
The Business Problem
The manual effort required to process and classify news articles can be overwhelming. Picture this: you're sitting at your desk, sifting through endless articles, trying to write unique summaries and categorize them as positive, negative, or neutral. It's time-consuming and resource-intensive.
This is where automation comes in handy. By automating the process, we not only save time but also reduce our reliance on manual labor, freeing up resources for other tasks. Machine learning steps in to offer solutions through text summarization and sentiment analysis techniques.
Business Objectives and Constraints
The primary goal is to minimize the time spent on writing new articles and reduce manual intervention. This is crucial for news organizations that need to get information out quickly.
One major constraint is ensuring the accuracy and quality of the summaries and classifications. The automated system must capture the essence of the original article while accurately classifying sentiments. The aim is to create a system that minimizes manual effort while maintaining high standards of quality and reliability.
By understanding the business problem, objectives, and constraints, we can approach the project with a clear focus on delivering impactful solutions. News article summarization and classification can significantly improve efficiency and resource allocation.
Project Architecture and Overview
Project Flow
The project follows a structured approach, incorporating several key steps.
- Business Understanding: Understanding the business needs and objectives is the foundation.
- Data Collection: Data is sourced directly from URLs, primarily focusing on Malay Mail articles and other news sources.
- Data Preparation: Data preprocessing is essential to clean and prepare the text data for effective model training.
- Exploratory Data Analysis (EDA): EDA helps gain insights into the data, identify patterns, and refine the approach.
- Model Evaluation: Rigorous evaluation ensures the models meet the required performance standards.
- Model Deployment: The final step involves deploying the model, making it accessible for real-time use.
High-Level Architecture
The project architecture is designed to be robust and efficient, incorporating several stages to ensure smooth operation.
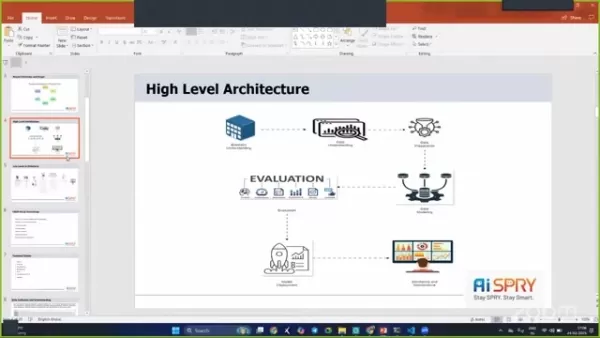
The stages include business understanding, data understanding, data preparation, data modeling, evaluation, and deployment.
Technical Stacks and Tools Used
To implement the project successfully, several technical stacks and tools were used:
- Python: Used for scripting and model building.
- Streamlit: Used for creating the web application.
- Beautiful Soup: Used for web scraping to extract data from HTML.
- Newspaper3k: An advanced library for extracting and parsing news articles.
- NLTK (Natural Language Toolkit): A suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English.
- Transformers (GPT-2): Used for text summarization tasks.
- DistilBERT: Used for sentiment analysis due to its efficiency and accuracy.
How to Use the Deployed Streamlit App
Scraping and Loading Data
The deployed Streamlit app allows for direct interaction and analysis of news articles.
- Web Scraping: You can initiate the process by scraping data directly from Malay Mail or other sources. This feature uses Beautiful Soup and Newspaper3k to extract relevant text from the specified URLs.
- Data Loading: After scraping, the data is loaded into the application for further processing.
Performing Text Summarization and Sentiment Analysis
Once the data is loaded, you can perform text summarization and other tasks to get the best model:
- Choose an NLP Task: Depending on your needs, various tasks can be chosen. Options include text summarization, topic modeling, and text classification. Text summarization is performed using GPT-2, providing concise and coherent summaries.
- Sentiment Analysis: The articles are classified based on sentiment—positive, negative, or neutral—using DistilBERT to check and determine the best solution to achieve the best result.
Pros and Cons
Pros
- Reduces manual effort and time in processing news articles.
- Provides accurate sentiment analysis and text summarization.
- Enhances the efficiency of news organizations.
- Uses a robust architecture and advanced machine learning models.
Cons
- Requires computational resources for web scraping, data processing, and model training.
- Accuracy of sentiment analysis may vary based on the complexity of the text.
- Maintenance is needed.
FAQ
What is the main goal of news article summarization and classification?
The main goal is to reduce the manual effort and time involved in summarizing and categorizing news articles.
What are the primary technical tools used in this project?
Python, Streamlit, Beautiful Soup, Newspaper3k, NLTK, Transformers (GPT-2), and DistilBERT are used.
What is DistilBERT used for in the project?
DistilBERT is used for sentiment analysis due to its efficiency and accuracy in classifying articles as positive, negative, or neutral.
How is the model deployed for real-time use?
The model is deployed in a Streamlit application, allowing users to interact with the summarization and classification tools in real-time.
What is the purpose of data preprocessing in this project?
Data preprocessing involves cleaning and preparing text data by removing unnecessary characters, spaces, and stopwords to improve the accuracy of the machine learning models.
Related Questions
How does the CRISP-ML(Q) methodology improve project outcomes?
The CRISP-ML(Q) methodology ensures a structured approach to data mining and machine learning projects. It helps in better business and data understanding, effective data preparation, and thorough model evaluation, leading to more successful project outcomes. By following the six phases, this project is well-organized and aligned with business objectives.
Related article
 Master InDesign: Use Paste Into Feature for Streamlined Graphic Design
Adobe InDesign is a powerhouse for graphic designers, packed with features that can transform your layouts into works of art. One feature that's often underappreciated but incredibly powerful is the 'Paste Into' function. This tool allows you to drop images, text, or other objects right into a pre-e
Biden's Lame Duck Presidency: Sabotage or Statesmanship?
As President Joe Biden approaches the end of his term, the political landscape is buzzing with speculation about what he might do in his final weeks. Labeled as a 'lame duck' president, Biden still holds significant sway over both domestic and international affairs. This piece explores the critical
AI eBook Generators: Top 5 Tools for Amazon KDP Success
Are you eager to dive into the world of online income by creating and selling eBooks? With the advent of AI technology, the process has become not only efficient but also incredibly accessible. This article delves into the top five AI eBook generators that can help you leverage the passive income op
Comments (0)
0/200
Master InDesign: Use Paste Into Feature for Streamlined Graphic Design
Adobe InDesign is a powerhouse for graphic designers, packed with features that can transform your layouts into works of art. One feature that's often underappreciated but incredibly powerful is the 'Paste Into' function. This tool allows you to drop images, text, or other objects right into a pre-e
Biden's Lame Duck Presidency: Sabotage or Statesmanship?
As President Joe Biden approaches the end of his term, the political landscape is buzzing with speculation about what he might do in his final weeks. Labeled as a 'lame duck' president, Biden still holds significant sway over both domestic and international affairs. This piece explores the critical
AI eBook Generators: Top 5 Tools for Amazon KDP Success
Are you eager to dive into the world of online income by creating and selling eBooks? With the advent of AI technology, the process has become not only efficient but also incredibly accessible. This article delves into the top five AI eBook generators that can help you leverage the passive income op
Comments (0)
0/200
April 27, 2025
LucasNelson
0
In today's fast-paced world, where information comes at us from all directions, the ability to quickly summarize and categorize news articles is more important than ever. This article dives into the fascinating world of news article summarization and classification, exploring the business reasons behind it, the techniques used for preparing data, and the models used to achieve accurate and efficient results.
Key Points
- Understanding the business problem behind news article summarization and classification.
- Techniques for collecting and preprocessing news article data.
- Using machine learning models for sentiment analysis and text summarization.
- Deploying the model in a Streamlit application for real-time use.
- Evaluating model performance with metrics like BLEU and Rouge scores.
- Utilizing libraries such as Beautiful Soup, Newspaper3k, and NLTK.
- Implementing the CRISP-ML(Q) methodology to streamline the project workflow.
Understanding News Article Summarization and Classification
The Business Problem
The manual effort required to process and classify news articles can be overwhelming. Picture this: you're sitting at your desk, sifting through endless articles, trying to write unique summaries and categorize them as positive, negative, or neutral. It's time-consuming and resource-intensive.
This is where automation comes in handy. By automating the process, we not only save time but also reduce our reliance on manual labor, freeing up resources for other tasks. Machine learning steps in to offer solutions through text summarization and sentiment analysis techniques.
Business Objectives and Constraints
The primary goal is to minimize the time spent on writing new articles and reduce manual intervention. This is crucial for news organizations that need to get information out quickly.
One major constraint is ensuring the accuracy and quality of the summaries and classifications. The automated system must capture the essence of the original article while accurately classifying sentiments. The aim is to create a system that minimizes manual effort while maintaining high standards of quality and reliability.
By understanding the business problem, objectives, and constraints, we can approach the project with a clear focus on delivering impactful solutions. News article summarization and classification can significantly improve efficiency and resource allocation.
Project Architecture and Overview
Project Flow
The project follows a structured approach, incorporating several key steps.
- Business Understanding: Understanding the business needs and objectives is the foundation.
- Data Collection: Data is sourced directly from URLs, primarily focusing on Malay Mail articles and other news sources.
- Data Preparation: Data preprocessing is essential to clean and prepare the text data for effective model training.
- Exploratory Data Analysis (EDA): EDA helps gain insights into the data, identify patterns, and refine the approach.
- Model Evaluation: Rigorous evaluation ensures the models meet the required performance standards.
- Model Deployment: The final step involves deploying the model, making it accessible for real-time use.
High-Level Architecture
The project architecture is designed to be robust and efficient, incorporating several stages to ensure smooth operation.
The stages include business understanding, data understanding, data preparation, data modeling, evaluation, and deployment.
Technical Stacks and Tools Used
To implement the project successfully, several technical stacks and tools were used:
- Python: Used for scripting and model building.
- Streamlit: Used for creating the web application.
- Beautiful Soup: Used for web scraping to extract data from HTML.
- Newspaper3k: An advanced library for extracting and parsing news articles.
- NLTK (Natural Language Toolkit): A suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English.
- Transformers (GPT-2): Used for text summarization tasks.
- DistilBERT: Used for sentiment analysis due to its efficiency and accuracy.
How to Use the Deployed Streamlit App
Scraping and Loading Data
The deployed Streamlit app allows for direct interaction and analysis of news articles.
- Web Scraping: You can initiate the process by scraping data directly from Malay Mail or other sources. This feature uses Beautiful Soup and Newspaper3k to extract relevant text from the specified URLs.
- Data Loading: After scraping, the data is loaded into the application for further processing.
Performing Text Summarization and Sentiment Analysis
Once the data is loaded, you can perform text summarization and other tasks to get the best model:
- Choose an NLP Task: Depending on your needs, various tasks can be chosen. Options include text summarization, topic modeling, and text classification. Text summarization is performed using GPT-2, providing concise and coherent summaries.
- Sentiment Analysis: The articles are classified based on sentiment—positive, negative, or neutral—using DistilBERT to check and determine the best solution to achieve the best result.
Pros and Cons
Pros
- Reduces manual effort and time in processing news articles.
- Provides accurate sentiment analysis and text summarization.
- Enhances the efficiency of news organizations.
- Uses a robust architecture and advanced machine learning models.
Cons
- Requires computational resources for web scraping, data processing, and model training.
- Accuracy of sentiment analysis may vary based on the complexity of the text.
- Maintenance is needed.
FAQ
What is the main goal of news article summarization and classification?
The main goal is to reduce the manual effort and time involved in summarizing and categorizing news articles.
What are the primary technical tools used in this project?
Python, Streamlit, Beautiful Soup, Newspaper3k, NLTK, Transformers (GPT-2), and DistilBERT are used.
What is DistilBERT used for in the project?
DistilBERT is used for sentiment analysis due to its efficiency and accuracy in classifying articles as positive, negative, or neutral.
How is the model deployed for real-time use?
The model is deployed in a Streamlit application, allowing users to interact with the summarization and classification tools in real-time.
What is the purpose of data preprocessing in this project?
Data preprocessing involves cleaning and preparing text data by removing unnecessary characters, spaces, and stopwords to improve the accuracy of the machine learning models.
Related Questions
How does the CRISP-ML(Q) methodology improve project outcomes?
The CRISP-ML(Q) methodology ensures a structured approach to data mining and machine learning projects. It helps in better business and data understanding, effective data preparation, and thorough model evaluation, leading to more successful project outcomes. By following the six phases, this project is well-organized and aligned with business objectives.










 Master InDesign: Use Paste Into Feature for Streamlined Graphic Design
Adobe InDesign is a powerhouse for graphic designers, packed with features that can transform your layouts into works of art. One feature that's often underappreciated but incredibly powerful is the 'Paste Into' function. This tool allows you to drop images, text, or other objects right into a pre-e
Master InDesign: Use Paste Into Feature for Streamlined Graphic Design
Adobe InDesign is a powerhouse for graphic designers, packed with features that can transform your layouts into works of art. One feature that's often underappreciated but incredibly powerful is the 'Paste Into' function. This tool allows you to drop images, text, or other objects right into a pre-e
 Biden's Lame Duck Presidency: Sabotage or Statesmanship?
As President Joe Biden approaches the end of his term, the political landscape is buzzing with speculation about what he might do in his final weeks. Labeled as a 'lame duck' president, Biden still holds significant sway over both domestic and international affairs. This piece explores the critical
Biden's Lame Duck Presidency: Sabotage or Statesmanship?
As President Joe Biden approaches the end of his term, the political landscape is buzzing with speculation about what he might do in his final weeks. Labeled as a 'lame duck' president, Biden still holds significant sway over both domestic and international affairs. This piece explores the critical
 AI eBook Generators: Top 5 Tools for Amazon KDP Success
Are you eager to dive into the world of online income by creating and selling eBooks? With the advent of AI technology, the process has become not only efficient but also incredibly accessible. This article delves into the top five AI eBook generators that can help you leverage the passive income op
AI eBook Generators: Top 5 Tools for Amazon KDP Success
Are you eager to dive into the world of online income by creating and selling eBooks? With the advent of AI technology, the process has become not only efficient but also incredibly accessible. This article delves into the top five AI eBook generators that can help you leverage the passive income op