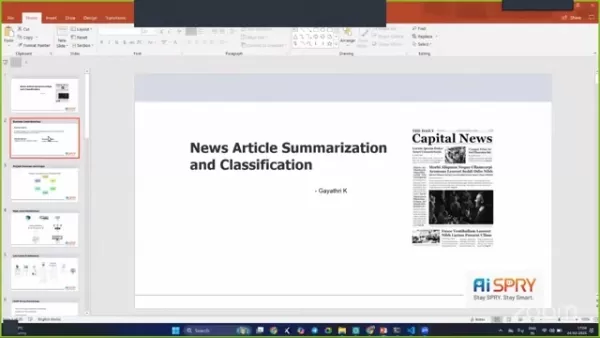
Summarisierung und Klassifizierung von Nachrichtenartikeln: Ein tiefer Tauchgang

 27. April 2025
27. April 2025

 LucasNelson
LucasNelson

 0
0
In der heutigen schnelllebigen Welt, in der Informationen aus allen Richtungen auf uns kommen, ist die Fähigkeit, Nachrichtenartikel schnell zusammenzufassen und zu kategorisieren, wichtiger denn je. Dieser Artikel taucht in die faszinierende Welt der Nachrichtenartikel zusammen, die die geschäftlichen Gründe, die für die Vorbereitung von Daten verwendeten Techniken und die Modelle zur Erzielung genauer und effizienter Ergebnisse untersuchen.
Schlüsselpunkte
- Verständnis des Geschäftsproblems hinter dem Zusammenfassung und Klassifizierung von Nachrichtenartikeln.
- Techniken zum Sammeln und Vorverarbeitung von Nachrichtenartikeln.
- Verwenden von Modellen für maschinelles Lernen für die Analyse der Stimmung und die Zusammenfassung des Textes.
- Bereitstellung des Modells in einer Stromnutzungsanwendung zur Echtzeitverwendung.
- Bewertung der Modellleistung mit Metriken wie Bleu- und Rouge -Scores.
- Verwendung von Bibliotheken wie wunderschöner Suppe, Zeitung3k und NLTK.
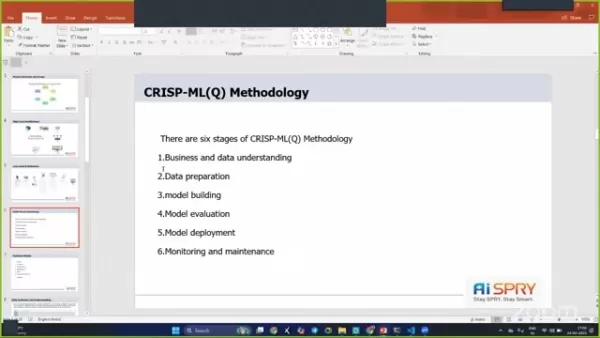
- Implementierung der CRISP-ML (Q) -Methodik, um den Projektworkflow zu optimieren.
Verständnis der Nachrichtenartikel Zusammenfassung und Klassifizierung
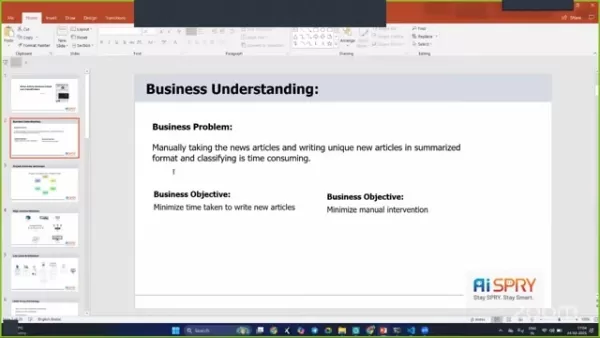
Das Geschäftsproblem
Der manuelle Aufwand für die Verarbeitung und Klassifizierung von Nachrichtenartikeln kann überwältigend sein. Stellen Sie sich Folgendes vor: Sie sitzen an Ihrem Schreibtisch, sitzen endlose Artikel durch, versuchen einzigartige Zusammenfassungen zu schreiben und sie als positiv, negativ oder neutral zu kategorisieren. Es ist zeitaufwändig und ressourcenintensiv.
Hier ist die Automatisierung nützlich. Durch die Automatisierung des Prozesses sparen wir nicht nur Zeit, sondern reduzieren auch unser Vertrauen in die manuelle Arbeit, wodurch die Ressourcen für andere Aufgaben freigegeben werden. Maschinelles Lernen tritt ein, um Lösungen durch Textübersichts- und Stimmungsanalysetechniken anzubieten.
Geschäftsziele und Einschränkungen
Das Hauptziel ist es, die Zeit für das Schreiben neuer Artikel zu minimieren und die manuelle Intervention zu verringern. Dies ist für Nachrichtenorganisationen von entscheidender Bedeutung, die Informationen schnell herausholen müssen.
Eine große Einschränkung besteht darin, die Genauigkeit und Qualität der Zusammenfassungen und Klassifizierungen zu gewährleisten. Das automatisierte System muss die Essenz des ursprünglichen Artikels erfassen und gleichzeitig die Gefühle klassifizieren. Ziel ist es, ein System zu erstellen, das den manuellen Aufwand minimiert und gleichzeitig hohe Qualität und Zuverlässigkeitsstandards aufrechterhält.
Durch das Verständnis des Geschäftsproblems, der Ziele und der Einschränkungen können wir uns mit einem klaren Fokus auf die Bereitstellung wirksamer Lösungen an das Projekt wenden. Die Zusammenfassung und Klassifizierung von Nachrichtenartikeln kann die Effizienz und Ressourcenallokation erheblich verbessern.
Projektarchitektur und Übersicht
Projektfluss
Das Projekt folgt einem strukturierten Ansatz mit mehreren wichtigen Schritten.
- Geschäftsverständnis: Das Verständnis der Geschäftsbedürfnisse und Ziele ist die Grundlage.
- Datenerfassung: Die Daten stammen direkt aus URLs und konzentrieren sich hauptsächlich auf malaiische Mail -Artikel und andere Nachrichtenquellen.
- Datenvorbereitung: Datenvorverarbeitung ist für die Reinigung und Erstellung der Textdaten für ein effektives Modelltraining unerlässlich.
- Explorationsdatenanalyse (EDA): EDA hilft, Einblicke in die Daten zu erhalten, Muster zu identifizieren und den Ansatz zu verfeinern.
- Modellbewertung: Die strenge Bewertung stellt sicher, dass die Modelle den erforderlichen Leistungsstandards erfüllen.
- Modellbereitstellung: Der letzte Schritt umfasst die Bereitstellung des Modells, wodurch es für die Echtzeitverwendung zugänglich ist.
Hochrangige Architektur
Die Projektarchitektur ist so ausgelegt und effizient und enthält mehrere Phasen, um einen reibungslosen Betrieb zu gewährleisten.
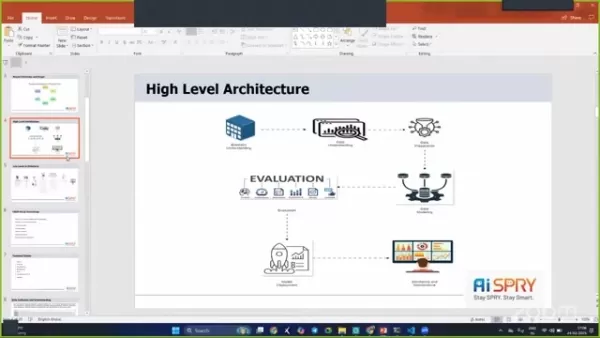
Die Phasen umfassen das Verständnis des Geschäfts, das Verständnis der Daten, die Datenvorbereitung, die Datenmodellierung, die Bewertung und die Bereitstellung.
Technische Stapel und Tools verwendet
Um das Projekt erfolgreich zu implementieren, wurden mehrere technische Stapel und Tools verwendet:
- Python: Wird zum Skript- und Modellgebäude verwendet.
- Streamlit: Wird zum Erstellen der Webanwendung verwendet.
- Schöne Suppe: Wird für das Web -Scraping verwendet, um Daten aus HTML zu extrahieren.
- Zeitung3K: Eine fortgeschrittene Bibliothek zum Extrahieren und Parsen von Nachrichtenartikeln.
- NLTK (Natural Language Toolkit): Eine Reihe von Bibliotheken und Programmen für die symbolische und statistische Verarbeitung natürlicher Sprache (NLP) für Englisch.
- Transformatoren (GPT-2): Wird für Textübersichtsaufgaben verwendet.
- DISTILBERT: Wird aufgrund seiner Effizienz und Genauigkeit zur Stimmungsanalyse verwendet.
So verwenden Sie die bereitgestellte Streamlit -App
Datenkratzen und Laden von Daten
Die bereitgestellte Streamlit -App ermöglicht eine direkte Interaktion und Analyse von Nachrichtenartikeln.
- Web -Scraping: Sie können den Prozess initiieren, indem Sie Daten direkt aus Malay -Mail oder anderen Quellen abkratzen. Diese Funktion verwendet wunderschöne Suppe und Zeitungen3K, um relevante Text aus den angegebenen URLs zu extrahieren.
- Datenbelastung: Nach dem Kratzen werden die Daten zur weiteren Verarbeitung in die Anwendung geladen.
Textübersicht und Stimmungsanalyse durchführen
Sobald die Daten geladen sind, können Sie die Textübersicht und andere Aufgaben ausführen, um das beste Modell zu erhalten:
- Wählen Sie eine NLP -Aufgabe: Abhängig von Ihren Anforderungen können verschiedene Aufgaben ausgewählt werden. Zu den Optionen gehören die Zusammenfassung der Text, Themenmodellierung und Textklassifizierung. Die Textübersicht wird mit GPT-2 durchgeführt, wobei präzise und kohärente Zusammenfassungen bereitgestellt werden.
- Stimmungsanalyse: Die Artikel werden basierend auf der Stimmung - positiv, negativ oder neutral - eingestuft, um die beste Lösung zu überprüfen und zu bestimmen, um das beste Ergebnis zu erzielen.
Für und Wider
Profis
- Reduziert die manuelle Anstrengung und Zeit in der Verarbeitung von Nachrichtenartikeln.
- Bietet eine genaue Stimmungsanalyse und Textübersicht.
- Verbessert die Effizienz von Nachrichtenorganisationen.
- Verwendet eine robuste Architektur und erweiterte Modelle für maschinelles Lernen.
Nachteile
- Benötigt Rechenressourcen für Web -Scraping, Datenverarbeitung und Modelltraining.
- Die Genauigkeit der Stimmungsanalyse kann je nach Komplexität des Textes variieren.
- Wartung ist erforderlich.
FAQ
Was ist das Hauptziel der Zusammenfassung und Klassifizierung von Nachrichtenartikeln?
Das Hauptziel ist es, den manuellen Aufwand und die Zeit zu verkürzen, die mit der Zusammenfassung und Kategorisierung von Nachrichtenartikeln verbunden sind.
Was werden die primären technischen Tools in diesem Projekt verwendet?
Python, Straffung, schöne Suppe, Zeitung3k, NLTK, Transformers (GPT-2) und Distilbert werden verwendet.
Wofür wird Distilbert im Projekt verwendet?
Distilbert wird aufgrund ihrer Effizienz und Genauigkeit bei der Klassifizierung von Artikeln als positiv, negativ oder neutral verwendet.
Wie wird das Modell für die Echtzeitverwendung bereitgestellt?
Das Modell wird in einer stromleuchten Anwendung bereitgestellt, sodass Benutzer in Echtzeit mit den Infizierungs- und Klassifizierungswerkzeugen interagieren können.
Was ist der Zweck der Datenvorverarbeitung in diesem Projekt?
Die Datenvorverarbeitung umfasst das Reinigen und Vorbereiten von Textdaten, indem unnötige Zeichen, Räume und Stoppwörter entfernt werden, um die Genauigkeit der Modelle für maschinelles Lernen zu verbessern.
Verwandte Fragen
Wie verbessert die CRISP-ML (Q) -Methodik die Projektergebnisse?
Die CRISP-ML (Q) -Methodik sorgt für einen strukturierten Ansatz für Data Mining und maschinelles Lernen. Es hilft beim besseren Geschäfts- und Datenverständnis, der effektiven Datenvorbereitung und der gründlichen Modellbewertung, was zu erfolgreicheren Projektergebnissen führt. Durch die Befolgung der sechs Phasen ist dieses Projekt gut organisiert und mit den Geschäftszielen ausgerichtet.
Verwandter Artikel
 Bidens lahme Entenpräsidentschaft: Sabotage oder Staatskunst?
Als Präsident Joe Biden das Ende seiner Amtszeit nähert, summt die politische Landschaft mit Spekulationen darüber, was er in seinen letzten Wochen tun könnte. Biden ist als "lahmer Duck" -Präsident bezeichnet und hat immer noch einen erheblichen Einfluss auf inländische und internationale Angelegenheiten. Dieses Stück untersucht das Kritische
AI E -Book -Generatoren: Top 5 Tools für den Erfolg von Amazon KDP
Möchten Sie unbedingt in die Welt des Online -Einkommens eintauchen, indem Sie E -Books erstellen und verkaufen? Mit dem Aufkommen der AI -Technologie ist der Prozess nicht nur effizient, sondern auch unglaublich zugänglich geworden. Dieser Artikel befasst sich mit den fünf wichtigsten AI -E -Book -Generatoren, die Ihnen helfen können, das passive Einkommen OP zu nutzen
Billy Idols 'Rebel Yell': Ein ausführlicher Blick auf die Live-Performance
Billy Idols 'Rebel Yell' überschreitet nur ein Lied; Es ist ein Emblem der Rockkultur der 1980er Jahre, das weiterhin bei Fans über Generationen hinweg ankommt. Dieses Stück führt Sie auf eine Reise durch die pulsierende Energie und die ikonische Grafik eines Live -Rebellen -Yell -Auftritts und löst die Elemente auf
Kommentare (0)
0/200
Bidens lahme Entenpräsidentschaft: Sabotage oder Staatskunst?
Als Präsident Joe Biden das Ende seiner Amtszeit nähert, summt die politische Landschaft mit Spekulationen darüber, was er in seinen letzten Wochen tun könnte. Biden ist als "lahmer Duck" -Präsident bezeichnet und hat immer noch einen erheblichen Einfluss auf inländische und internationale Angelegenheiten. Dieses Stück untersucht das Kritische
AI E -Book -Generatoren: Top 5 Tools für den Erfolg von Amazon KDP
Möchten Sie unbedingt in die Welt des Online -Einkommens eintauchen, indem Sie E -Books erstellen und verkaufen? Mit dem Aufkommen der AI -Technologie ist der Prozess nicht nur effizient, sondern auch unglaublich zugänglich geworden. Dieser Artikel befasst sich mit den fünf wichtigsten AI -E -Book -Generatoren, die Ihnen helfen können, das passive Einkommen OP zu nutzen
Billy Idols 'Rebel Yell': Ein ausführlicher Blick auf die Live-Performance
Billy Idols 'Rebel Yell' überschreitet nur ein Lied; Es ist ein Emblem der Rockkultur der 1980er Jahre, das weiterhin bei Fans über Generationen hinweg ankommt. Dieses Stück führt Sie auf eine Reise durch die pulsierende Energie und die ikonische Grafik eines Live -Rebellen -Yell -Auftritts und löst die Elemente auf
Kommentare (0)
0/200
27. April 2025
LucasNelson
0
In der heutigen schnelllebigen Welt, in der Informationen aus allen Richtungen auf uns kommen, ist die Fähigkeit, Nachrichtenartikel schnell zusammenzufassen und zu kategorisieren, wichtiger denn je. Dieser Artikel taucht in die faszinierende Welt der Nachrichtenartikel zusammen, die die geschäftlichen Gründe, die für die Vorbereitung von Daten verwendeten Techniken und die Modelle zur Erzielung genauer und effizienter Ergebnisse untersuchen.
Schlüsselpunkte
- Verständnis des Geschäftsproblems hinter dem Zusammenfassung und Klassifizierung von Nachrichtenartikeln.
- Techniken zum Sammeln und Vorverarbeitung von Nachrichtenartikeln.
- Verwenden von Modellen für maschinelles Lernen für die Analyse der Stimmung und die Zusammenfassung des Textes.
- Bereitstellung des Modells in einer Stromnutzungsanwendung zur Echtzeitverwendung.
- Bewertung der Modellleistung mit Metriken wie Bleu- und Rouge -Scores.
- Verwendung von Bibliotheken wie wunderschöner Suppe, Zeitung3k und NLTK.
- Implementierung der CRISP-ML (Q) -Methodik, um den Projektworkflow zu optimieren.
Verständnis der Nachrichtenartikel Zusammenfassung und Klassifizierung
Das Geschäftsproblem
Der manuelle Aufwand für die Verarbeitung und Klassifizierung von Nachrichtenartikeln kann überwältigend sein. Stellen Sie sich Folgendes vor: Sie sitzen an Ihrem Schreibtisch, sitzen endlose Artikel durch, versuchen einzigartige Zusammenfassungen zu schreiben und sie als positiv, negativ oder neutral zu kategorisieren. Es ist zeitaufwändig und ressourcenintensiv.
Hier ist die Automatisierung nützlich. Durch die Automatisierung des Prozesses sparen wir nicht nur Zeit, sondern reduzieren auch unser Vertrauen in die manuelle Arbeit, wodurch die Ressourcen für andere Aufgaben freigegeben werden. Maschinelles Lernen tritt ein, um Lösungen durch Textübersichts- und Stimmungsanalysetechniken anzubieten.
Geschäftsziele und Einschränkungen
Das Hauptziel ist es, die Zeit für das Schreiben neuer Artikel zu minimieren und die manuelle Intervention zu verringern. Dies ist für Nachrichtenorganisationen von entscheidender Bedeutung, die Informationen schnell herausholen müssen.
Eine große Einschränkung besteht darin, die Genauigkeit und Qualität der Zusammenfassungen und Klassifizierungen zu gewährleisten. Das automatisierte System muss die Essenz des ursprünglichen Artikels erfassen und gleichzeitig die Gefühle klassifizieren. Ziel ist es, ein System zu erstellen, das den manuellen Aufwand minimiert und gleichzeitig hohe Qualität und Zuverlässigkeitsstandards aufrechterhält.
Durch das Verständnis des Geschäftsproblems, der Ziele und der Einschränkungen können wir uns mit einem klaren Fokus auf die Bereitstellung wirksamer Lösungen an das Projekt wenden. Die Zusammenfassung und Klassifizierung von Nachrichtenartikeln kann die Effizienz und Ressourcenallokation erheblich verbessern.
Projektarchitektur und Übersicht
Projektfluss
Das Projekt folgt einem strukturierten Ansatz mit mehreren wichtigen Schritten.
- Geschäftsverständnis: Das Verständnis der Geschäftsbedürfnisse und Ziele ist die Grundlage.
- Datenerfassung: Die Daten stammen direkt aus URLs und konzentrieren sich hauptsächlich auf malaiische Mail -Artikel und andere Nachrichtenquellen.
- Datenvorbereitung: Datenvorverarbeitung ist für die Reinigung und Erstellung der Textdaten für ein effektives Modelltraining unerlässlich.
- Explorationsdatenanalyse (EDA): EDA hilft, Einblicke in die Daten zu erhalten, Muster zu identifizieren und den Ansatz zu verfeinern.
- Modellbewertung: Die strenge Bewertung stellt sicher, dass die Modelle den erforderlichen Leistungsstandards erfüllen.
- Modellbereitstellung: Der letzte Schritt umfasst die Bereitstellung des Modells, wodurch es für die Echtzeitverwendung zugänglich ist.
Hochrangige Architektur
Die Projektarchitektur ist so ausgelegt und effizient und enthält mehrere Phasen, um einen reibungslosen Betrieb zu gewährleisten.
Die Phasen umfassen das Verständnis des Geschäfts, das Verständnis der Daten, die Datenvorbereitung, die Datenmodellierung, die Bewertung und die Bereitstellung.
Technische Stapel und Tools verwendet
Um das Projekt erfolgreich zu implementieren, wurden mehrere technische Stapel und Tools verwendet:
- Python: Wird zum Skript- und Modellgebäude verwendet.
- Streamlit: Wird zum Erstellen der Webanwendung verwendet.
- Schöne Suppe: Wird für das Web -Scraping verwendet, um Daten aus HTML zu extrahieren.
- Zeitung3K: Eine fortgeschrittene Bibliothek zum Extrahieren und Parsen von Nachrichtenartikeln.
- NLTK (Natural Language Toolkit): Eine Reihe von Bibliotheken und Programmen für die symbolische und statistische Verarbeitung natürlicher Sprache (NLP) für Englisch.
- Transformatoren (GPT-2): Wird für Textübersichtsaufgaben verwendet.
- DISTILBERT: Wird aufgrund seiner Effizienz und Genauigkeit zur Stimmungsanalyse verwendet.
So verwenden Sie die bereitgestellte Streamlit -App
Datenkratzen und Laden von Daten
Die bereitgestellte Streamlit -App ermöglicht eine direkte Interaktion und Analyse von Nachrichtenartikeln.
- Web -Scraping: Sie können den Prozess initiieren, indem Sie Daten direkt aus Malay -Mail oder anderen Quellen abkratzen. Diese Funktion verwendet wunderschöne Suppe und Zeitungen3K, um relevante Text aus den angegebenen URLs zu extrahieren.
- Datenbelastung: Nach dem Kratzen werden die Daten zur weiteren Verarbeitung in die Anwendung geladen.
Textübersicht und Stimmungsanalyse durchführen
Sobald die Daten geladen sind, können Sie die Textübersicht und andere Aufgaben ausführen, um das beste Modell zu erhalten:
- Wählen Sie eine NLP -Aufgabe: Abhängig von Ihren Anforderungen können verschiedene Aufgaben ausgewählt werden. Zu den Optionen gehören die Zusammenfassung der Text, Themenmodellierung und Textklassifizierung. Die Textübersicht wird mit GPT-2 durchgeführt, wobei präzise und kohärente Zusammenfassungen bereitgestellt werden.
- Stimmungsanalyse: Die Artikel werden basierend auf der Stimmung - positiv, negativ oder neutral - eingestuft, um die beste Lösung zu überprüfen und zu bestimmen, um das beste Ergebnis zu erzielen.
Für und Wider
Profis
- Reduziert die manuelle Anstrengung und Zeit in der Verarbeitung von Nachrichtenartikeln.
- Bietet eine genaue Stimmungsanalyse und Textübersicht.
- Verbessert die Effizienz von Nachrichtenorganisationen.
- Verwendet eine robuste Architektur und erweiterte Modelle für maschinelles Lernen.
Nachteile
- Benötigt Rechenressourcen für Web -Scraping, Datenverarbeitung und Modelltraining.
- Die Genauigkeit der Stimmungsanalyse kann je nach Komplexität des Textes variieren.
- Wartung ist erforderlich.
FAQ
Was ist das Hauptziel der Zusammenfassung und Klassifizierung von Nachrichtenartikeln?
Das Hauptziel ist es, den manuellen Aufwand und die Zeit zu verkürzen, die mit der Zusammenfassung und Kategorisierung von Nachrichtenartikeln verbunden sind.
Was werden die primären technischen Tools in diesem Projekt verwendet?
Python, Straffung, schöne Suppe, Zeitung3k, NLTK, Transformers (GPT-2) und Distilbert werden verwendet.
Wofür wird Distilbert im Projekt verwendet?
Distilbert wird aufgrund ihrer Effizienz und Genauigkeit bei der Klassifizierung von Artikeln als positiv, negativ oder neutral verwendet.
Wie wird das Modell für die Echtzeitverwendung bereitgestellt?
Das Modell wird in einer stromleuchten Anwendung bereitgestellt, sodass Benutzer in Echtzeit mit den Infizierungs- und Klassifizierungswerkzeugen interagieren können.
Was ist der Zweck der Datenvorverarbeitung in diesem Projekt?
Die Datenvorverarbeitung umfasst das Reinigen und Vorbereiten von Textdaten, indem unnötige Zeichen, Räume und Stoppwörter entfernt werden, um die Genauigkeit der Modelle für maschinelles Lernen zu verbessern.
Verwandte Fragen
Wie verbessert die CRISP-ML (Q) -Methodik die Projektergebnisse?
Die CRISP-ML (Q) -Methodik sorgt für einen strukturierten Ansatz für Data Mining und maschinelles Lernen. Es hilft beim besseren Geschäfts- und Datenverständnis, der effektiven Datenvorbereitung und der gründlichen Modellbewertung, was zu erfolgreicheren Projektergebnissen führt. Durch die Befolgung der sechs Phasen ist dieses Projekt gut organisiert und mit den Geschäftszielen ausgerichtet.










 Bidens lahme Entenpräsidentschaft: Sabotage oder Staatskunst?
Als Präsident Joe Biden das Ende seiner Amtszeit nähert, summt die politische Landschaft mit Spekulationen darüber, was er in seinen letzten Wochen tun könnte. Biden ist als "lahmer Duck" -Präsident bezeichnet und hat immer noch einen erheblichen Einfluss auf inländische und internationale Angelegenheiten. Dieses Stück untersucht das Kritische
Bidens lahme Entenpräsidentschaft: Sabotage oder Staatskunst?
Als Präsident Joe Biden das Ende seiner Amtszeit nähert, summt die politische Landschaft mit Spekulationen darüber, was er in seinen letzten Wochen tun könnte. Biden ist als "lahmer Duck" -Präsident bezeichnet und hat immer noch einen erheblichen Einfluss auf inländische und internationale Angelegenheiten. Dieses Stück untersucht das Kritische
 AI E -Book -Generatoren: Top 5 Tools für den Erfolg von Amazon KDP
Möchten Sie unbedingt in die Welt des Online -Einkommens eintauchen, indem Sie E -Books erstellen und verkaufen? Mit dem Aufkommen der AI -Technologie ist der Prozess nicht nur effizient, sondern auch unglaublich zugänglich geworden. Dieser Artikel befasst sich mit den fünf wichtigsten AI -E -Book -Generatoren, die Ihnen helfen können, das passive Einkommen OP zu nutzen
AI E -Book -Generatoren: Top 5 Tools für den Erfolg von Amazon KDP
Möchten Sie unbedingt in die Welt des Online -Einkommens eintauchen, indem Sie E -Books erstellen und verkaufen? Mit dem Aufkommen der AI -Technologie ist der Prozess nicht nur effizient, sondern auch unglaublich zugänglich geworden. Dieser Artikel befasst sich mit den fünf wichtigsten AI -E -Book -Generatoren, die Ihnen helfen können, das passive Einkommen OP zu nutzen
 Billy Idols 'Rebel Yell': Ein ausführlicher Blick auf die Live-Performance
Billy Idols 'Rebel Yell' überschreitet nur ein Lied; Es ist ein Emblem der Rockkultur der 1980er Jahre, das weiterhin bei Fans über Generationen hinweg ankommt. Dieses Stück führt Sie auf eine Reise durch die pulsierende Energie und die ikonische Grafik eines Live -Rebellen -Yell -Auftritts und löst die Elemente auf
Billy Idols 'Rebel Yell': Ein ausführlicher Blick auf die Live-Performance
Billy Idols 'Rebel Yell' überschreitet nur ein Lied; Es ist ein Emblem der Rockkultur der 1980er Jahre, das weiterhin bei Fans über Generationen hinweg ankommt. Dieses Stück führt Sie auf eine Reise durch die pulsierende Energie und die ikonische Grafik eines Live -Rebellen -Yell -Auftritts und löst die Elemente auf