समाचार लेख सारांश और वर्गीकरण: एक गहरी गोता

 27 अप्रैल 2025
27 अप्रैल 2025

 LucasNelson
LucasNelson

 0
0
आज की तेज-तर्रार दुनिया में, जहां सभी दिशाओं से जानकारी हमारे पास आती है, समाचार लेखों को जल्दी से संक्षेप और वर्गीकृत करने की क्षमता पहले से कहीं अधिक महत्वपूर्ण है। यह लेख समाचार लेख सारांश और वर्गीकरण की आकर्षक दुनिया में गोता लगाता है, इसके पीछे के व्यावसायिक कारणों की खोज करता है, डेटा तैयार करने के लिए उपयोग की जाने वाली तकनीकें, और सटीक और कुशल परिणाम प्राप्त करने के लिए उपयोग किए जाने वाले मॉडल।
प्रमुख बिंदु
- समाचार लेख सारांश और वर्गीकरण के पीछे व्यावसायिक समस्या को समझना।
- समाचार लेख डेटा एकत्र करने और प्रीप्रोसेसिंग के लिए तकनीक।
- भावना विश्लेषण और पाठ सारांश के लिए मशीन लर्निंग मॉडल का उपयोग करना।
- वास्तविक समय के उपयोग के लिए एक स्ट्रीमलाइट एप्लिकेशन में मॉडल को तैनात करना।
- BLEU और ROUGE स्कोर जैसे मेट्रिक्स के साथ मॉडल प्रदर्शन का मूल्यांकन।
- सुंदर सूप, समाचार पत्र 3 के और एनएलटीके जैसे पुस्तकालयों का उपयोग करना।
- प्रोजेक्ट वर्कफ़्लो को सुव्यवस्थित करने के लिए क्रिस्प-एमएल (क्यू) पद्धति को लागू करना।
समाचार लेख सारांश और वर्गीकरण को समझना
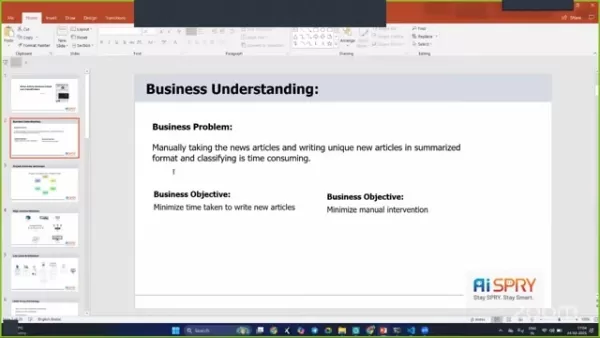
व्यापार की समस्या
समाचार लेखों को संसाधित करने और वर्गीकृत करने के लिए आवश्यक मैनुअल प्रयास भारी हो सकता है। यह चित्र: आप अपने डेस्क पर बैठे हैं, अंतहीन लेखों के माध्यम से बदल रहे हैं, अद्वितीय सारांश लिखने और उन्हें सकारात्मक, नकारात्मक या तटस्थ के रूप में वर्गीकृत करने की कोशिश कर रहे हैं। यह समय लेने वाली और संसाधन-गहन है।
यह वह जगह है जहाँ स्वचालन काम में आता है। प्रक्रिया को स्वचालित करके, हम न केवल समय बचाते हैं, बल्कि मैनुअल श्रम पर अपनी निर्भरता को कम करते हैं, अन्य कार्यों के लिए संसाधनों को मुक्त करते हैं। पाठ सारांश और भावना विश्लेषण तकनीकों के माध्यम से समाधान की पेशकश करने के लिए मशीन सीखने के कदम।
व्यावसायिक उद्देश्य और बाधाएँ
प्राथमिक लक्ष्य नए लेख लिखने और मैनुअल हस्तक्षेप को कम करने में बिताए समय को कम करना है। यह समाचार संगठनों के लिए महत्वपूर्ण है जिन्हें जल्दी से जानकारी प्राप्त करने की आवश्यकता है।
एक प्रमुख बाधा सारांश और वर्गीकरण की सटीकता और गुणवत्ता सुनिश्चित कर रही है। स्वचालित प्रणाली को मूल लेख के सार पर कब्जा करना चाहिए, जबकि भावनाओं को सटीक रूप से वर्गीकृत करना चाहिए। उद्देश्य एक ऐसी प्रणाली बनाना है जो गुणवत्ता और विश्वसनीयता के उच्च मानकों को बनाए रखते हुए मैनुअल प्रयास को कम करता है।
व्यावसायिक समस्या, उद्देश्यों और बाधाओं को समझने से, हम प्रभावशाली समाधान देने पर स्पष्ट ध्यान देने के साथ परियोजना को संपर्क कर सकते हैं। समाचार लेख सारांश और वर्गीकरण दक्षता और संसाधन आवंटन में काफी सुधार कर सकता है।
परियोजना वास्तुकला और अवलोकन
परियोजना प्रवाह
परियोजना एक संरचित दृष्टिकोण का अनुसरण करती है, जिसमें कई प्रमुख चरण शामिल हैं।
- व्यावसायिक समझ: व्यावसायिक आवश्यकताओं और उद्देश्यों को समझना नींव है।
- डेटा संग्रह: डेटा को सीधे URL से प्राप्त किया जाता है, मुख्य रूप से मलय मेल लेखों और अन्य समाचार स्रोतों पर ध्यान केंद्रित किया जाता है।
- डेटा तैयारी: प्रभावी मॉडल प्रशिक्षण के लिए पाठ डेटा को साफ करने और तैयार करने के लिए डेटा प्रीप्रोसेसिंग आवश्यक है।
- खोजपूर्ण डेटा विश्लेषण (EDA): EDA डेटा में अंतर्दृष्टि प्राप्त करने, पैटर्न की पहचान करने और दृष्टिकोण को परिष्कृत करने में मदद करता है।
- मॉडल मूल्यांकन: कठोर मूल्यांकन सुनिश्चित करता है कि मॉडल आवश्यक प्रदर्शन मानकों को पूरा करते हैं।
- मॉडल परिनियोजन: अंतिम चरण में मॉडल को तैनात करना शामिल है, जिससे यह वास्तविक समय के उपयोग के लिए सुलभ है।
उच्च-स्तरीय वास्तुकला
प्रोजेक्ट आर्किटेक्चर को मजबूत और कुशल बनाने के लिए डिज़ाइन किया गया है, जिसमें सुचारू संचालन सुनिश्चित करने के लिए कई चरण शामिल हैं।
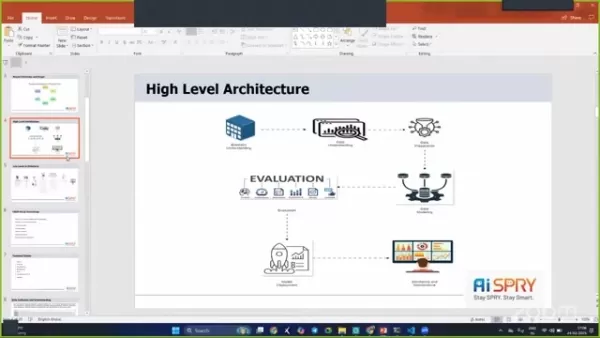
चरणों में व्यावसायिक समझ, डेटा समझ, डेटा तैयारी, डेटा मॉडलिंग, मूल्यांकन और परिनियोजन शामिल हैं।
तकनीकी ढेर और उपयोग किए गए उपकरण
परियोजना को सफलतापूर्वक लागू करने के लिए, कई तकनीकी ढेर और उपकरणों का उपयोग किया गया था:
- पायथन: स्क्रिप्टिंग और मॉडल बिल्डिंग के लिए उपयोग किया जाता है।
- स्ट्रीमलाइट: वेब एप्लिकेशन बनाने के लिए उपयोग किया जाता है।
- सुंदर सूप: HTML से डेटा निकालने के लिए वेब स्क्रैपिंग के लिए उपयोग किया जाता है।
- समाचार पत्र 3k: समाचार लेखों को निकालने और पार्सिंग करने के लिए एक उन्नत पुस्तकालय।
- एनएलटीके (प्राकृतिक भाषा टूलकिट): अंग्रेजी के लिए प्रतीकात्मक और सांख्यिकीय प्राकृतिक भाषा प्रसंस्करण (एनएलपी) के लिए पुस्तकालयों और कार्यक्रमों का एक सूट।
- ट्रांसफॉर्मर (GPT-2): पाठ सारांश कार्यों के लिए उपयोग किया जाता है।
- डिस्टिलबर्ट: इसकी दक्षता और सटीकता के कारण भावना विश्लेषण के लिए उपयोग किया जाता है।
तैनात स्ट्रीमलाइट ऐप का उपयोग कैसे करें
स्क्रैपिंग और लोडिंग डेटा
तैनात स्ट्रीमलाइट ऐप समाचार लेखों के प्रत्यक्ष बातचीत और विश्लेषण के लिए अनुमति देता है।
- वेब स्क्रैपिंग: आप सीधे मलय मेल या अन्य स्रोतों से डेटा को स्क्रैप करके प्रक्रिया शुरू कर सकते हैं। यह सुविधा निर्दिष्ट URL से प्रासंगिक पाठ निकालने के लिए सुंदर सूप और समाचार पत्र 3K का उपयोग करती है।
- डेटा लोडिंग: स्क्रैपिंग के बाद, डेटा को आगे की प्रक्रिया के लिए एप्लिकेशन में लोड किया जाता है।
पाठ सारांश और भावना विश्लेषण करना
एक बार डेटा लोड होने के बाद, आप सबसे अच्छा मॉडल प्राप्त करने के लिए पाठ सारांश और अन्य कार्य कर सकते हैं:
- एक एनएलपी कार्य चुनें: अपनी आवश्यकताओं के आधार पर, विभिन्न कार्यों को चुना जा सकता है। विकल्पों में पाठ सारांश, विषय मॉडलिंग और पाठ वर्गीकरण शामिल हैं। पाठ सारांश GPT-2 का उपयोग करके किया जाता है, जो संक्षिप्त और सुसंगत सारांश प्रदान करता है।
- भावना विश्लेषण: लेखों को भावना के आधार पर वर्गीकृत किया जाता है - पॉजिटिव, नकारात्मक, या तटस्थ - सबसे अच्छा परिणाम प्राप्त करने के लिए सबसे अच्छा समाधान की जांच करने और निर्धारित करने के लिए डिस्टिलबर्ट का उपयोग करना।
पक्ष - विपक्ष
पेशेवरों
- समाचार लेखों के प्रसंस्करण में मैनुअल प्रयास और समय को कम करता है।
- सटीक भावना विश्लेषण और पाठ सारांश प्रदान करता है।
- समाचार संगठनों की दक्षता को बढ़ाता है।
- एक मजबूत वास्तुकला और उन्नत मशीन सीखने के मॉडल का उपयोग करता है।
दोष
- वेब स्क्रैपिंग, डेटा प्रोसेसिंग और मॉडल प्रशिक्षण के लिए कम्प्यूटेशनल संसाधनों की आवश्यकता है।
- भावना विश्लेषण की सटीकता पाठ की जटिलता के आधार पर भिन्न हो सकती है।
- रखरखाव की जरूरत है।
उपवास
समाचार लेख सारांश और वर्गीकरण का मुख्य लक्ष्य क्या है?
मुख्य लक्ष्य समाचार लेखों को संक्षेप और वर्गीकृत करने में शामिल मैनुअल प्रयास और समय को कम करना है।
इस परियोजना में उपयोग किए जाने वाले प्राथमिक तकनीकी उपकरण क्या हैं?
पायथन, स्ट्रीमलिट, सुंदर सूप, अखबार 3 के, एनएलटीके, ट्रांसफार्मर (जीपीटी -2), और डिस्टिलबर्ट का उपयोग किया जाता है।
प्रोजेक्ट में डिस्टिलबर्ट का क्या उपयोग किया जाता है?
Distilbert का उपयोग अपनी दक्षता और सटीकता के कारण भावों को सकारात्मक, नकारात्मक या तटस्थ के रूप में वर्गीकृत करने में भावना विश्लेषण के लिए किया जाता है।
वास्तविक समय के उपयोग के लिए मॉडल कैसे तैनात किया जाता है?
मॉडल को एक स्ट्रीमलाइट एप्लिकेशन में तैनात किया गया है, जिससे उपयोगकर्ता वास्तविक समय में सारांश और वर्गीकरण उपकरण के साथ बातचीत करने की अनुमति देते हैं।
इस परियोजना में डेटा प्रीप्रोसेसिंग का उद्देश्य क्या है?
डेटा प्रीप्रोसेसिंग में मशीन लर्निंग मॉडल की सटीकता में सुधार करने के लिए अनावश्यक वर्णों, रिक्त स्थान और स्टॉपवर्ड को हटाकर टेक्स्ट डेटा की सफाई और तैयार करना शामिल है।
संबंधित प्रश्न
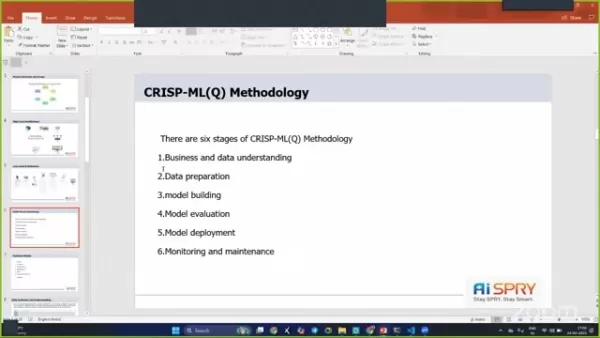
CRISP-ML (Q) कार्यप्रणाली परियोजना के परिणामों में कैसे सुधार करती है?
CRISP-ML (Q) कार्यप्रणाली डेटा खनन और मशीन लर्निंग प्रोजेक्ट्स के लिए एक संरचित दृष्टिकोण सुनिश्चित करती है। यह बेहतर व्यवसाय और डेटा समझ, प्रभावी डेटा तैयारी और पूरी तरह से मॉडल मूल्यांकन में मदद करता है, जिससे अधिक सफल परियोजना परिणामों के लिए अग्रणी होता है। छह चरणों का पालन करके, यह परियोजना अच्छी तरह से संगठित है और व्यावसायिक उद्देश्यों के साथ संरेखित है।
संबंधित लेख
 मास्टर Indesign: सुव्यवस्थित ग्राफिक डिजाइन के लिए फीचर में पेस्ट का उपयोग करें
Adobe Indesign ग्राफिक डिजाइनरों के लिए एक पावरहाउस है, जो उन सुविधाओं के साथ पैक किया जाता है जो आपके लेआउट को कला के कार्यों में बदल सकते हैं। एक विशेषता जिसे अक्सर कम कर दिया जाता है लेकिन अविश्वसनीय रूप से शक्तिशाली 'पेस्ट इन' फ़ंक्शन है। यह टूल आपको छवियों, पाठ, या अन्य ऑब्जेक्ट्स को प्री-ई में छोड़ने की अनुमति देता है
बिडेन की लंगड़ा बतख प्रेसीडेंसी: सबोटेज या स्टेट्समैनशिप?
जैसा कि राष्ट्रपति जो बिडेन ने अपने कार्यकाल के अंत में पहुंचते हैं, राजनीतिक परिदृश्य अपने अंतिम हफ्तों में क्या कर सकता है, इस बारे में अटकलों के साथ गुलजार है। एक 'लंगड़ा डक' के अध्यक्ष के रूप में लेबल, बिडेन अभी भी घरेलू और अंतर्राष्ट्रीय दोनों मामलों पर महत्वपूर्ण बोलबाला है। यह टुकड़ा महत्वपूर्ण की खोज करता है
एआई ईबुक जनरेटर: अमेज़ॅन केडीपी सफलता के लिए शीर्ष 5 उपकरण
क्या आप ई -बुक्स बनाकर ऑनलाइन आय की दुनिया में गोता लगाने के लिए उत्सुक हैं? एआई तकनीक के आगमन के साथ, प्रक्रिया न केवल कुशल हो गई है, बल्कि अविश्वसनीय रूप से सुलभ भी है। यह लेख शीर्ष पांच एआई ईबुक जनरेटर में देरी करता है जो आपको निष्क्रिय आय ओपी का लाभ उठाने में मदद कर सकता है
सूचना (0)
0/200
मास्टर Indesign: सुव्यवस्थित ग्राफिक डिजाइन के लिए फीचर में पेस्ट का उपयोग करें
Adobe Indesign ग्राफिक डिजाइनरों के लिए एक पावरहाउस है, जो उन सुविधाओं के साथ पैक किया जाता है जो आपके लेआउट को कला के कार्यों में बदल सकते हैं। एक विशेषता जिसे अक्सर कम कर दिया जाता है लेकिन अविश्वसनीय रूप से शक्तिशाली 'पेस्ट इन' फ़ंक्शन है। यह टूल आपको छवियों, पाठ, या अन्य ऑब्जेक्ट्स को प्री-ई में छोड़ने की अनुमति देता है
बिडेन की लंगड़ा बतख प्रेसीडेंसी: सबोटेज या स्टेट्समैनशिप?
जैसा कि राष्ट्रपति जो बिडेन ने अपने कार्यकाल के अंत में पहुंचते हैं, राजनीतिक परिदृश्य अपने अंतिम हफ्तों में क्या कर सकता है, इस बारे में अटकलों के साथ गुलजार है। एक 'लंगड़ा डक' के अध्यक्ष के रूप में लेबल, बिडेन अभी भी घरेलू और अंतर्राष्ट्रीय दोनों मामलों पर महत्वपूर्ण बोलबाला है। यह टुकड़ा महत्वपूर्ण की खोज करता है
एआई ईबुक जनरेटर: अमेज़ॅन केडीपी सफलता के लिए शीर्ष 5 उपकरण
क्या आप ई -बुक्स बनाकर ऑनलाइन आय की दुनिया में गोता लगाने के लिए उत्सुक हैं? एआई तकनीक के आगमन के साथ, प्रक्रिया न केवल कुशल हो गई है, बल्कि अविश्वसनीय रूप से सुलभ भी है। यह लेख शीर्ष पांच एआई ईबुक जनरेटर में देरी करता है जो आपको निष्क्रिय आय ओपी का लाभ उठाने में मदद कर सकता है
सूचना (0)
0/200
27 अप्रैल 2025
LucasNelson
0
आज की तेज-तर्रार दुनिया में, जहां सभी दिशाओं से जानकारी हमारे पास आती है, समाचार लेखों को जल्दी से संक्षेप और वर्गीकृत करने की क्षमता पहले से कहीं अधिक महत्वपूर्ण है। यह लेख समाचार लेख सारांश और वर्गीकरण की आकर्षक दुनिया में गोता लगाता है, इसके पीछे के व्यावसायिक कारणों की खोज करता है, डेटा तैयार करने के लिए उपयोग की जाने वाली तकनीकें, और सटीक और कुशल परिणाम प्राप्त करने के लिए उपयोग किए जाने वाले मॉडल।
प्रमुख बिंदु
- समाचार लेख सारांश और वर्गीकरण के पीछे व्यावसायिक समस्या को समझना।
- समाचार लेख डेटा एकत्र करने और प्रीप्रोसेसिंग के लिए तकनीक।
- भावना विश्लेषण और पाठ सारांश के लिए मशीन लर्निंग मॉडल का उपयोग करना।
- वास्तविक समय के उपयोग के लिए एक स्ट्रीमलाइट एप्लिकेशन में मॉडल को तैनात करना।
- BLEU और ROUGE स्कोर जैसे मेट्रिक्स के साथ मॉडल प्रदर्शन का मूल्यांकन।
- सुंदर सूप, समाचार पत्र 3 के और एनएलटीके जैसे पुस्तकालयों का उपयोग करना।
- प्रोजेक्ट वर्कफ़्लो को सुव्यवस्थित करने के लिए क्रिस्प-एमएल (क्यू) पद्धति को लागू करना।
समाचार लेख सारांश और वर्गीकरण को समझना
व्यापार की समस्या
समाचार लेखों को संसाधित करने और वर्गीकृत करने के लिए आवश्यक मैनुअल प्रयास भारी हो सकता है। यह चित्र: आप अपने डेस्क पर बैठे हैं, अंतहीन लेखों के माध्यम से बदल रहे हैं, अद्वितीय सारांश लिखने और उन्हें सकारात्मक, नकारात्मक या तटस्थ के रूप में वर्गीकृत करने की कोशिश कर रहे हैं। यह समय लेने वाली और संसाधन-गहन है।
यह वह जगह है जहाँ स्वचालन काम में आता है। प्रक्रिया को स्वचालित करके, हम न केवल समय बचाते हैं, बल्कि मैनुअल श्रम पर अपनी निर्भरता को कम करते हैं, अन्य कार्यों के लिए संसाधनों को मुक्त करते हैं। पाठ सारांश और भावना विश्लेषण तकनीकों के माध्यम से समाधान की पेशकश करने के लिए मशीन सीखने के कदम।
व्यावसायिक उद्देश्य और बाधाएँ
प्राथमिक लक्ष्य नए लेख लिखने और मैनुअल हस्तक्षेप को कम करने में बिताए समय को कम करना है। यह समाचार संगठनों के लिए महत्वपूर्ण है जिन्हें जल्दी से जानकारी प्राप्त करने की आवश्यकता है।
एक प्रमुख बाधा सारांश और वर्गीकरण की सटीकता और गुणवत्ता सुनिश्चित कर रही है। स्वचालित प्रणाली को मूल लेख के सार पर कब्जा करना चाहिए, जबकि भावनाओं को सटीक रूप से वर्गीकृत करना चाहिए। उद्देश्य एक ऐसी प्रणाली बनाना है जो गुणवत्ता और विश्वसनीयता के उच्च मानकों को बनाए रखते हुए मैनुअल प्रयास को कम करता है।
व्यावसायिक समस्या, उद्देश्यों और बाधाओं को समझने से, हम प्रभावशाली समाधान देने पर स्पष्ट ध्यान देने के साथ परियोजना को संपर्क कर सकते हैं। समाचार लेख सारांश और वर्गीकरण दक्षता और संसाधन आवंटन में काफी सुधार कर सकता है।
परियोजना वास्तुकला और अवलोकन
परियोजना प्रवाह
परियोजना एक संरचित दृष्टिकोण का अनुसरण करती है, जिसमें कई प्रमुख चरण शामिल हैं।
- व्यावसायिक समझ: व्यावसायिक आवश्यकताओं और उद्देश्यों को समझना नींव है।
- डेटा संग्रह: डेटा को सीधे URL से प्राप्त किया जाता है, मुख्य रूप से मलय मेल लेखों और अन्य समाचार स्रोतों पर ध्यान केंद्रित किया जाता है।
- डेटा तैयारी: प्रभावी मॉडल प्रशिक्षण के लिए पाठ डेटा को साफ करने और तैयार करने के लिए डेटा प्रीप्रोसेसिंग आवश्यक है।
- खोजपूर्ण डेटा विश्लेषण (EDA): EDA डेटा में अंतर्दृष्टि प्राप्त करने, पैटर्न की पहचान करने और दृष्टिकोण को परिष्कृत करने में मदद करता है।
- मॉडल मूल्यांकन: कठोर मूल्यांकन सुनिश्चित करता है कि मॉडल आवश्यक प्रदर्शन मानकों को पूरा करते हैं।
- मॉडल परिनियोजन: अंतिम चरण में मॉडल को तैनात करना शामिल है, जिससे यह वास्तविक समय के उपयोग के लिए सुलभ है।
उच्च-स्तरीय वास्तुकला
प्रोजेक्ट आर्किटेक्चर को मजबूत और कुशल बनाने के लिए डिज़ाइन किया गया है, जिसमें सुचारू संचालन सुनिश्चित करने के लिए कई चरण शामिल हैं।
चरणों में व्यावसायिक समझ, डेटा समझ, डेटा तैयारी, डेटा मॉडलिंग, मूल्यांकन और परिनियोजन शामिल हैं।
तकनीकी ढेर और उपयोग किए गए उपकरण
परियोजना को सफलतापूर्वक लागू करने के लिए, कई तकनीकी ढेर और उपकरणों का उपयोग किया गया था:
- पायथन: स्क्रिप्टिंग और मॉडल बिल्डिंग के लिए उपयोग किया जाता है।
- स्ट्रीमलाइट: वेब एप्लिकेशन बनाने के लिए उपयोग किया जाता है।
- सुंदर सूप: HTML से डेटा निकालने के लिए वेब स्क्रैपिंग के लिए उपयोग किया जाता है।
- समाचार पत्र 3k: समाचार लेखों को निकालने और पार्सिंग करने के लिए एक उन्नत पुस्तकालय।
- एनएलटीके (प्राकृतिक भाषा टूलकिट): अंग्रेजी के लिए प्रतीकात्मक और सांख्यिकीय प्राकृतिक भाषा प्रसंस्करण (एनएलपी) के लिए पुस्तकालयों और कार्यक्रमों का एक सूट।
- ट्रांसफॉर्मर (GPT-2): पाठ सारांश कार्यों के लिए उपयोग किया जाता है।
- डिस्टिलबर्ट: इसकी दक्षता और सटीकता के कारण भावना विश्लेषण के लिए उपयोग किया जाता है।
तैनात स्ट्रीमलाइट ऐप का उपयोग कैसे करें
स्क्रैपिंग और लोडिंग डेटा
तैनात स्ट्रीमलाइट ऐप समाचार लेखों के प्रत्यक्ष बातचीत और विश्लेषण के लिए अनुमति देता है।
- वेब स्क्रैपिंग: आप सीधे मलय मेल या अन्य स्रोतों से डेटा को स्क्रैप करके प्रक्रिया शुरू कर सकते हैं। यह सुविधा निर्दिष्ट URL से प्रासंगिक पाठ निकालने के लिए सुंदर सूप और समाचार पत्र 3K का उपयोग करती है।
- डेटा लोडिंग: स्क्रैपिंग के बाद, डेटा को आगे की प्रक्रिया के लिए एप्लिकेशन में लोड किया जाता है।
पाठ सारांश और भावना विश्लेषण करना
एक बार डेटा लोड होने के बाद, आप सबसे अच्छा मॉडल प्राप्त करने के लिए पाठ सारांश और अन्य कार्य कर सकते हैं:
- एक एनएलपी कार्य चुनें: अपनी आवश्यकताओं के आधार पर, विभिन्न कार्यों को चुना जा सकता है। विकल्पों में पाठ सारांश, विषय मॉडलिंग और पाठ वर्गीकरण शामिल हैं। पाठ सारांश GPT-2 का उपयोग करके किया जाता है, जो संक्षिप्त और सुसंगत सारांश प्रदान करता है।
- भावना विश्लेषण: लेखों को भावना के आधार पर वर्गीकृत किया जाता है - पॉजिटिव, नकारात्मक, या तटस्थ - सबसे अच्छा परिणाम प्राप्त करने के लिए सबसे अच्छा समाधान की जांच करने और निर्धारित करने के लिए डिस्टिलबर्ट का उपयोग करना।
पक्ष - विपक्ष
पेशेवरों
- समाचार लेखों के प्रसंस्करण में मैनुअल प्रयास और समय को कम करता है।
- सटीक भावना विश्लेषण और पाठ सारांश प्रदान करता है।
- समाचार संगठनों की दक्षता को बढ़ाता है।
- एक मजबूत वास्तुकला और उन्नत मशीन सीखने के मॉडल का उपयोग करता है।
दोष
- वेब स्क्रैपिंग, डेटा प्रोसेसिंग और मॉडल प्रशिक्षण के लिए कम्प्यूटेशनल संसाधनों की आवश्यकता है।
- भावना विश्लेषण की सटीकता पाठ की जटिलता के आधार पर भिन्न हो सकती है।
- रखरखाव की जरूरत है।
उपवास
समाचार लेख सारांश और वर्गीकरण का मुख्य लक्ष्य क्या है?
मुख्य लक्ष्य समाचार लेखों को संक्षेप और वर्गीकृत करने में शामिल मैनुअल प्रयास और समय को कम करना है।
इस परियोजना में उपयोग किए जाने वाले प्राथमिक तकनीकी उपकरण क्या हैं?
पायथन, स्ट्रीमलिट, सुंदर सूप, अखबार 3 के, एनएलटीके, ट्रांसफार्मर (जीपीटी -2), और डिस्टिलबर्ट का उपयोग किया जाता है।
प्रोजेक्ट में डिस्टिलबर्ट का क्या उपयोग किया जाता है?
Distilbert का उपयोग अपनी दक्षता और सटीकता के कारण भावों को सकारात्मक, नकारात्मक या तटस्थ के रूप में वर्गीकृत करने में भावना विश्लेषण के लिए किया जाता है।
वास्तविक समय के उपयोग के लिए मॉडल कैसे तैनात किया जाता है?
मॉडल को एक स्ट्रीमलाइट एप्लिकेशन में तैनात किया गया है, जिससे उपयोगकर्ता वास्तविक समय में सारांश और वर्गीकरण उपकरण के साथ बातचीत करने की अनुमति देते हैं।
इस परियोजना में डेटा प्रीप्रोसेसिंग का उद्देश्य क्या है?
डेटा प्रीप्रोसेसिंग में मशीन लर्निंग मॉडल की सटीकता में सुधार करने के लिए अनावश्यक वर्णों, रिक्त स्थान और स्टॉपवर्ड को हटाकर टेक्स्ट डेटा की सफाई और तैयार करना शामिल है।
संबंधित प्रश्न
CRISP-ML (Q) कार्यप्रणाली परियोजना के परिणामों में कैसे सुधार करती है?
CRISP-ML (Q) कार्यप्रणाली डेटा खनन और मशीन लर्निंग प्रोजेक्ट्स के लिए एक संरचित दृष्टिकोण सुनिश्चित करती है। यह बेहतर व्यवसाय और डेटा समझ, प्रभावी डेटा तैयारी और पूरी तरह से मॉडल मूल्यांकन में मदद करता है, जिससे अधिक सफल परियोजना परिणामों के लिए अग्रणी होता है। छह चरणों का पालन करके, यह परियोजना अच्छी तरह से संगठित है और व्यावसायिक उद्देश्यों के साथ संरेखित है।










 मास्टर Indesign: सुव्यवस्थित ग्राफिक डिजाइन के लिए फीचर में पेस्ट का उपयोग करें
Adobe Indesign ग्राफिक डिजाइनरों के लिए एक पावरहाउस है, जो उन सुविधाओं के साथ पैक किया जाता है जो आपके लेआउट को कला के कार्यों में बदल सकते हैं। एक विशेषता जिसे अक्सर कम कर दिया जाता है लेकिन अविश्वसनीय रूप से शक्तिशाली 'पेस्ट इन' फ़ंक्शन है। यह टूल आपको छवियों, पाठ, या अन्य ऑब्जेक्ट्स को प्री-ई में छोड़ने की अनुमति देता है
मास्टर Indesign: सुव्यवस्थित ग्राफिक डिजाइन के लिए फीचर में पेस्ट का उपयोग करें
Adobe Indesign ग्राफिक डिजाइनरों के लिए एक पावरहाउस है, जो उन सुविधाओं के साथ पैक किया जाता है जो आपके लेआउट को कला के कार्यों में बदल सकते हैं। एक विशेषता जिसे अक्सर कम कर दिया जाता है लेकिन अविश्वसनीय रूप से शक्तिशाली 'पेस्ट इन' फ़ंक्शन है। यह टूल आपको छवियों, पाठ, या अन्य ऑब्जेक्ट्स को प्री-ई में छोड़ने की अनुमति देता है
 बिडेन की लंगड़ा बतख प्रेसीडेंसी: सबोटेज या स्टेट्समैनशिप?
जैसा कि राष्ट्रपति जो बिडेन ने अपने कार्यकाल के अंत में पहुंचते हैं, राजनीतिक परिदृश्य अपने अंतिम हफ्तों में क्या कर सकता है, इस बारे में अटकलों के साथ गुलजार है। एक 'लंगड़ा डक' के अध्यक्ष के रूप में लेबल, बिडेन अभी भी घरेलू और अंतर्राष्ट्रीय दोनों मामलों पर महत्वपूर्ण बोलबाला है। यह टुकड़ा महत्वपूर्ण की खोज करता है
बिडेन की लंगड़ा बतख प्रेसीडेंसी: सबोटेज या स्टेट्समैनशिप?
जैसा कि राष्ट्रपति जो बिडेन ने अपने कार्यकाल के अंत में पहुंचते हैं, राजनीतिक परिदृश्य अपने अंतिम हफ्तों में क्या कर सकता है, इस बारे में अटकलों के साथ गुलजार है। एक 'लंगड़ा डक' के अध्यक्ष के रूप में लेबल, बिडेन अभी भी घरेलू और अंतर्राष्ट्रीय दोनों मामलों पर महत्वपूर्ण बोलबाला है। यह टुकड़ा महत्वपूर्ण की खोज करता है
 एआई ईबुक जनरेटर: अमेज़ॅन केडीपी सफलता के लिए शीर्ष 5 उपकरण
क्या आप ई -बुक्स बनाकर ऑनलाइन आय की दुनिया में गोता लगाने के लिए उत्सुक हैं? एआई तकनीक के आगमन के साथ, प्रक्रिया न केवल कुशल हो गई है, बल्कि अविश्वसनीय रूप से सुलभ भी है। यह लेख शीर्ष पांच एआई ईबुक जनरेटर में देरी करता है जो आपको निष्क्रिय आय ओपी का लाभ उठाने में मदद कर सकता है
एआई ईबुक जनरेटर: अमेज़ॅन केडीपी सफलता के लिए शीर्ष 5 उपकरण
क्या आप ई -बुक्स बनाकर ऑनलाइन आय की दुनिया में गोता लगाने के लिए उत्सुक हैं? एआई तकनीक के आगमन के साथ, प्रक्रिया न केवल कुशल हो गई है, बल्कि अविश्वसनीय रूप से सुलभ भी है। यह लेख शीर्ष पांच एआई ईबुक जनरेटर में देरी करता है जो आपको निष्क्रिय आय ओपी का लाभ उठाने में मदद कर सकता है