
















 집
집ByteDance, Seed-Thinking-v1.5 AI 모델 공개로 추론 능력 강화
고급 추론 AI를 위한 경쟁은 2024년 9월 OpenAI의 o1 모델로 시작되었으며, 2025년 1월 DeepSeek의 R1 출시로 더욱 가속화되었습니다.
주요 AI 개발자들은 이제 체인 오브 쏘트 프로세스를 통해 정확하고 신중한 응답을 제공하는 더 빠르고 비용 효율적인 추론 AI 모델을 만들기 위해 경쟁하고 있습니다.
TikTok의 모회사인 ByteDance는 기술 논문에서 소개된 새로운 대형 언어 모델(LLM)인 Seed-Thinking-v1.5를 공개하며 이 경쟁에 뛰어들었습니다. 이 모델은 STEM 및 일반 도메인에서 추론 능력을 강화하는 데 목표를 두고 있습니다.
이 모델은 아직 사용 가능하지 않으며, 라이선스가 독점, 오픈소스, 또는 하이브리드인지 여부는 공개되지 않았습니다. 하지만 논문은 출시 전에 탐구할 만한 주요 통찰을 제공합니다.
전문가 혼합(MoE) 프레임워크 활용
Meta의 Llama 4와 Mistral의 Mixtral을 따라, Seed-Thinking-v1.5는 전문가 혼합(MoE) 아키텍처를 채택했습니다.
이 접근법은 여러 전문화된 모델을 하나로 통합하여 각기 다른 도메인에 초점을 맞춤으로써 효율성을 높입니다.
Seed-Thinking-v1.5는 2000억 개 파라미터 중 단 200억 개만을 사용하여 성능을 최적화합니다.
ByteDance의 GitHub에 공개된 논문은 모델이 구조화된 추론과 의도적인 응답 생성에 중점을 둔 점을 강조합니다.
이 모델은 DeepSeek R1을 능가하며, Google의 Gemini 2.5 Pro와 OpenAI의 o3-mini-high를 타사 벤치마크에서 경쟁하며, ARC-AGI 벤치마크에서 인간의 성능을 초월하는 경제적으로 가치 있는 작업에서 OpenAI 기준을 넘어섭니다.
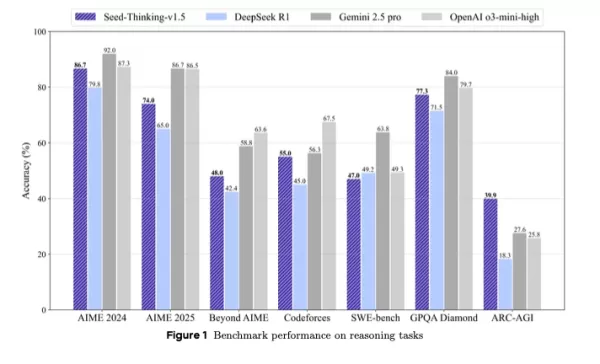
더 큰 모델에 대한 컴팩트하면서 강력한 대안으로 자리 잡은 Seed-Thinking-v1.5는 혁신적인 강화 학습, 엄선된 훈련 데이터, 고급 AI 인프라를 통해 강력한 벤치마크 결과를 제공합니다.
벤치마크 성능 및 핵심 강점
Seed-Thinking-v1.5는 어려운 작업에서 탁월하며, AIME 2024에서 86.7%, Codeforces에서 pass@8로 55.0%, GPQA 과학 벤치마크에서 77.3%를 기록하며 OpenAI의 o3-mini-high 및 Google의 Gemini 2.5 Pro와 비슷하거나 이를 초월하는 추론 메트릭을 보여줍니다.
비추론 작업에서는 DeepSeek R1보다 8.0% 높은 인간 선호도 승률을 달성하여 논리와 수학을 넘어선 다재다능함을 보여줍니다.
벤치마크 포화를 방지하기 위해 ByteDance는 암기를 방지하고 모델 성능을 더 잘 평가하기 위해 더 어려운 수학 벤치마크인 BeyondAIME을 만들었습니다. 이와 함께 Codeforces 세트는 향후 연구를 돕기 위해 공개될 예정입니다.
훈련 데이터 접근법
Seed-Thinking-v1.5 개발에서 데이터 품질은 핵심이었습니다. 지도 미세 조정을 위해 40만 개 샘플이 엄선되었습니다: 30만 개의 검증 가능한 STEM, 논리, 코딩 작업과 10만 개의 창의적 글쓰기와 같은 비검증 작업.
강화 학습을 위해 데이터는 다음과 같이 나뉘었습니다:
- 검증 가능한 문제: 엘리트 대회에서 전문가가 검증한 10만 개의 엄선된 STEM 질문과 논리 퍼즐.
- 비검증 작업: 쌍대 보상 모델을 통해 평가된 개방형 프롬프트에 대한 인간 선호도 데이터셋.
STEM 데이터의 80% 이상은 고급 수학에 초점을 맞췄으며, 스도쿠 및 24포인트 퍼즐과 같은 논리 작업은 모델 진행 상황에 맞춰 조정되었습니다.
강화 학습 혁신
Seed-Thinking-v1.5는 긴 체인 오브 쏘트 시나리오에서 문제를 해결하기 위해 사용자 정의 액터-크리틱(VAPO) 및 정책-그라디언트(DAPO) 프레임워크를 사용하여 강화 학습을 안정화합니다.
두 가지 보상 모델이 RL 감독을 강화합니다:
- Seed-Verifier: 생성된 답변과 참조 답변 간의 수학적 동등성을 보장하는 규칙 기반 LLM.
- Seed-Thinking-Verifier: 보상 조작에 강한 일관된 평가를 위한 추론 기반 판단자.
이 듀얼 시스템은 간단하고 복잡한 작업 전반에 걸쳐 정밀한 평가를 지원합니다.
확장 가능한 인프라 설계
ByteDance의 HybridFlow 프레임워크는 Ray 클러스터로 구동되며, GPU 유휴 시간을 최소화하기 위해 훈련과 추론을 공동 배치하여 효율적인 대규모 훈련을 지원합니다.
스트리밍 롤아웃 시스템(SRS)은 모델 진화와 런타임을 분리하여 부분 생성의 비동기 관리를 통해 반복 속도를 최대 3배까지 가속화합니다.
추가 기술에는 다음이 포함됩니다:
- 메모리 효율성을 위한 혼합 정밀도(FP8)
- MoE 최적화를 위한 전문가 병렬 처리 및 커널 자동 튜닝
- 견고한 체크포인팅을 위한 ByteCheckpoint
- 최적화된 병렬 처리 및 메모리 설정을 위한 AutoTuner
인간 중심 평가 및 응용
창의적 글쓰기, 인문학, 일반 대화에 걸친 인간 테스트에서 Seed-Thinking-v1.5는 DeepSeek R1을 능가하며 실세계 관련성을 입증했습니다.
팀은 검증 가능한 작업에 대한 훈련이 엄격한 수학적 워크플로우를 통해 창의적 도메인으로의 일반화를 강화했다고 밝혔습니다.
기술 팀 및 기업에 대한 시사점
LLM 수명 주기를 감독하는 기술 리더들에게 Seed-Thinking-v1.5는 고급 추론을 기업 AI 시스템에 통합하는 모델을 제공합니다.
검증 가능한 데이터셋과 다단계 강화 학습을 통한 모듈식 훈련은 정밀한 제어로 LLM 개발을 확장하는 팀에 적합합니다.
Seed-Verifier와 Seed-Thinking-Verifier는 고객 대면 또는 규제 환경에서 필수적인 신뢰할 수 있는 보상 모델링을 강화합니다.
촉박한 일정의 팀을 위해 VAPO와 동적 샘플링은 반복 주기를 줄여 작업별 미세 조정을 간소화합니다.
SRS 및 FP8 최적화를 포함한 하이브리드 인프라는 훈련 처리량과 하드웨어 효율성을 높여 클라우드 및 온프레미스 시스템에 이상적입니다.
모델의 적응형 보상 피드백은 다양한 데이터 파이프라인 관리의 문제를 해결하여 도메인 전반의 일관성을 보장합니다.
데이터 엔지니어들에게는 엄격한 데이터 필터링과 전문가 검증에 대한 초점이 고품질 데이터셋이 모델 성능을 높이는 데 중요한 가치를 강조합니다.
미래 전망
Yonghui Wu가 이끌고 Haibin Lin이 공개적으로 대표하는 ByteDance의 Seed LLM Systems 팀이 개발한 Seed-Thinking-v1.5는 Doubao 1.5 Pro와 같은 노력에 기반을 두며, 공유 RLHF 및 데이터 큐레이션 기술을 사용합니다.
팀은 훈련 효율성과 비검증 작업에 대한 보상 모델링에 초점을 맞춰 강화 학습을 개선하는 것을 목표로 합니다. BeyondAIME과 같은 벤치마크 공개는 추론 중심 AI 연구의 추가 발전을 촉진할 것입니다.
관련 기사
 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
관련 특별 주제 추천
텍스트 음성 변환
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
관련 특별 주제 추천
텍스트 음성 변환
 난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 환자를 위한 최고의 AI 음성 합성 앱: 학생들의 학습 및 독서 효율성 향상
난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
 10 도구
10 도구
 xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
xix.ai
만화 창작
소년 만화를 위한 최고의 AI 생성기: 박진감 넘치는 액션 장면과 에너지 효과 만들기
XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai
사업
최고의 AI 경비 관리 앱: 영수증을 스캔하고 기업 경비를 자동으로 분류하세요
2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai
사업
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

 의견 (1)
0/500
의견 (1)
0/500
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
고급 추론 AI를 위한 경쟁은 2024년 9월 OpenAI의 o1 모델로 시작되었으며, 2025년 1월 DeepSeek의 R1 출시로 더욱 가속화되었습니다.
주요 AI 개발자들은 이제 체인 오브 쏘트 프로세스를 통해 정확하고 신중한 응답을 제공하는 더 빠르고 비용 효율적인 추론 AI 모델을 만들기 위해 경쟁하고 있습니다.
TikTok의 모회사인 ByteDance는 기술 논문에서 소개된 새로운 대형 언어 모델(LLM)인 Seed-Thinking-v1.5를 공개하며 이 경쟁에 뛰어들었습니다. 이 모델은 STEM 및 일반 도메인에서 추론 능력을 강화하는 데 목표를 두고 있습니다.
이 모델은 아직 사용 가능하지 않으며, 라이선스가 독점, 오픈소스, 또는 하이브리드인지 여부는 공개되지 않았습니다. 하지만 논문은 출시 전에 탐구할 만한 주요 통찰을 제공합니다.
전문가 혼합(MoE) 프레임워크 활용
Meta의 Llama 4와 Mistral의 Mixtral을 따라, Seed-Thinking-v1.5는 전문가 혼합(MoE) 아키텍처를 채택했습니다.
이 접근법은 여러 전문화된 모델을 하나로 통합하여 각기 다른 도메인에 초점을 맞춤으로써 효율성을 높입니다.
Seed-Thinking-v1.5는 2000억 개 파라미터 중 단 200억 개만을 사용하여 성능을 최적화합니다.
ByteDance의 GitHub에 공개된 논문은 모델이 구조화된 추론과 의도적인 응답 생성에 중점을 둔 점을 강조합니다.
이 모델은 DeepSeek R1을 능가하며, Google의 Gemini 2.5 Pro와 OpenAI의 o3-mini-high를 타사 벤치마크에서 경쟁하며, ARC-AGI 벤치마크에서 인간의 성능을 초월하는 경제적으로 가치 있는 작업에서 OpenAI 기준을 넘어섭니다.
더 큰 모델에 대한 컴팩트하면서 강력한 대안으로 자리 잡은 Seed-Thinking-v1.5는 혁신적인 강화 학습, 엄선된 훈련 데이터, 고급 AI 인프라를 통해 강력한 벤치마크 결과를 제공합니다.
벤치마크 성능 및 핵심 강점
Seed-Thinking-v1.5는 어려운 작업에서 탁월하며, AIME 2024에서 86.7%, Codeforces에서 pass@8로 55.0%, GPQA 과학 벤치마크에서 77.3%를 기록하며 OpenAI의 o3-mini-high 및 Google의 Gemini 2.5 Pro와 비슷하거나 이를 초월하는 추론 메트릭을 보여줍니다.
비추론 작업에서는 DeepSeek R1보다 8.0% 높은 인간 선호도 승률을 달성하여 논리와 수학을 넘어선 다재다능함을 보여줍니다.
벤치마크 포화를 방지하기 위해 ByteDance는 암기를 방지하고 모델 성능을 더 잘 평가하기 위해 더 어려운 수학 벤치마크인 BeyondAIME을 만들었습니다. 이와 함께 Codeforces 세트는 향후 연구를 돕기 위해 공개될 예정입니다.
훈련 데이터 접근법
Seed-Thinking-v1.5 개발에서 데이터 품질은 핵심이었습니다. 지도 미세 조정을 위해 40만 개 샘플이 엄선되었습니다: 30만 개의 검증 가능한 STEM, 논리, 코딩 작업과 10만 개의 창의적 글쓰기와 같은 비검증 작업.
강화 학습을 위해 데이터는 다음과 같이 나뉘었습니다:
- 검증 가능한 문제: 엘리트 대회에서 전문가가 검증한 10만 개의 엄선된 STEM 질문과 논리 퍼즐.
- 비검증 작업: 쌍대 보상 모델을 통해 평가된 개방형 프롬프트에 대한 인간 선호도 데이터셋.
STEM 데이터의 80% 이상은 고급 수학에 초점을 맞췄으며, 스도쿠 및 24포인트 퍼즐과 같은 논리 작업은 모델 진행 상황에 맞춰 조정되었습니다.
강화 학습 혁신
Seed-Thinking-v1.5는 긴 체인 오브 쏘트 시나리오에서 문제를 해결하기 위해 사용자 정의 액터-크리틱(VAPO) 및 정책-그라디언트(DAPO) 프레임워크를 사용하여 강화 학습을 안정화합니다.
두 가지 보상 모델이 RL 감독을 강화합니다:
- Seed-Verifier: 생성된 답변과 참조 답변 간의 수학적 동등성을 보장하는 규칙 기반 LLM.
- Seed-Thinking-Verifier: 보상 조작에 강한 일관된 평가를 위한 추론 기반 판단자.
이 듀얼 시스템은 간단하고 복잡한 작업 전반에 걸쳐 정밀한 평가를 지원합니다.
확장 가능한 인프라 설계
ByteDance의 HybridFlow 프레임워크는 Ray 클러스터로 구동되며, GPU 유휴 시간을 최소화하기 위해 훈련과 추론을 공동 배치하여 효율적인 대규모 훈련을 지원합니다.
스트리밍 롤아웃 시스템(SRS)은 모델 진화와 런타임을 분리하여 부분 생성의 비동기 관리를 통해 반복 속도를 최대 3배까지 가속화합니다.
추가 기술에는 다음이 포함됩니다:
- 메모리 효율성을 위한 혼합 정밀도(FP8)
- MoE 최적화를 위한 전문가 병렬 처리 및 커널 자동 튜닝
- 견고한 체크포인팅을 위한 ByteCheckpoint
- 최적화된 병렬 처리 및 메모리 설정을 위한 AutoTuner
인간 중심 평가 및 응용
창의적 글쓰기, 인문학, 일반 대화에 걸친 인간 테스트에서 Seed-Thinking-v1.5는 DeepSeek R1을 능가하며 실세계 관련성을 입증했습니다.
팀은 검증 가능한 작업에 대한 훈련이 엄격한 수학적 워크플로우를 통해 창의적 도메인으로의 일반화를 강화했다고 밝혔습니다.
기술 팀 및 기업에 대한 시사점
LLM 수명 주기를 감독하는 기술 리더들에게 Seed-Thinking-v1.5는 고급 추론을 기업 AI 시스템에 통합하는 모델을 제공합니다.
검증 가능한 데이터셋과 다단계 강화 학습을 통한 모듈식 훈련은 정밀한 제어로 LLM 개발을 확장하는 팀에 적합합니다.
Seed-Verifier와 Seed-Thinking-Verifier는 고객 대면 또는 규제 환경에서 필수적인 신뢰할 수 있는 보상 모델링을 강화합니다.
촉박한 일정의 팀을 위해 VAPO와 동적 샘플링은 반복 주기를 줄여 작업별 미세 조정을 간소화합니다.
SRS 및 FP8 최적화를 포함한 하이브리드 인프라는 훈련 처리량과 하드웨어 효율성을 높여 클라우드 및 온프레미스 시스템에 이상적입니다.
모델의 적응형 보상 피드백은 다양한 데이터 파이프라인 관리의 문제를 해결하여 도메인 전반의 일관성을 보장합니다.
데이터 엔지니어들에게는 엄격한 데이터 필터링과 전문가 검증에 대한 초점이 고품질 데이터셋이 모델 성능을 높이는 데 중요한 가치를 강조합니다.
미래 전망
Yonghui Wu가 이끌고 Haibin Lin이 공개적으로 대표하는 ByteDance의 Seed LLM Systems 팀이 개발한 Seed-Thinking-v1.5는 Doubao 1.5 Pro와 같은 노력에 기반을 두며, 공유 RLHF 및 데이터 큐레이션 기술을 사용합니다.
팀은 훈련 효율성과 비검증 작업에 대한 보상 모델링에 초점을 맞춰 강화 학습을 개선하는 것을 목표로 합니다. BeyondAIME과 같은 벤치마크 공개는 추론 중심 AI 연구의 추가 발전을 촉진할 것입니다.










 사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
사티야 나델라, 새로운 오픈AI 협력을 활용할 준비가 되었다
수요일에 월스트리트의 한 애널리스트가 마이크로소프트의 사티야 나델라 CEO에게 개정된 오픈AI와의 파트너십이 회사의 재무 상황에 어떤 영향을 미칠지 직접 물었습니다.나델라는 이 새로운 협약이 모든 당사자에게 이익이 된다고 설명했습니다. “오픈AI와의 파트너십에 대해 우리는 만족하고 있습니다. 저는 언제나 모든 파트너십에서 상호 이익이 되도록 하는 데 집중합니다. 그렇게 해야만 좋은 파트너로 남을 수 있기 때문입니다.”그는 마이크로소프트가 여
 오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
오픈AI, 공공 부유 기금, 로봇세, 주 4일 근무제를 통해 AI 경제 구상 제시
각국 정부가 초지능 기계가 초래할 경제적 영향을 관리하기 위해 고심하는 가운데, 오픈AI는 ‘지능 시대’에 부와 일자리가 어떻게 재편될 수 있을지 제시하는 일련의 정책 제안을 발표했다. 이 제안들은 공공 부유 기금이나 사회 안전망 확충과 같은 전통적인 진보적 방안들을 근본적으로 자본주의적이고 시장 주도적인 경제 체계와 결합하고 있다.오픈AI의 제안은 본질적
 메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.
메타, 아마존 AI용 CPU 수백만 대 공급 계약 체결
아마존은 자체 설계 칩을 다시 한번 앞세워 메타(Meta)와 중요한 파트너십을 체결했다. 아마존은 금요일, 메타가 확대되는 AI 수요를 충족하기 위해 수백만 개의 AWS 그래비톤(Graviton) 칩을 도입하기로 합의했다고 밝혔다.참고로 AWS 그래비톤은 GPU(그래픽 처리 장치)가 아닌 ARM 기반 CPU(일반 컴퓨팅용으로 설계된 중앙 처리 장치)입니다.

난독증 지원을 위해 엄선된 2026년 최신 최고 평점 AI TTS 앱을 만나보세요. 전문가들이 선정한 이 순위는 무료 및 유료 도구를 비교 분석하여, 읽기 효율과 학습 효과를 높여주는 강력한 기능들을 소개합니다. 학생들의 잠재력을 최대한 발휘할 수 있도록 도와줄, 꼭 사용해봐야 할 혁신적인 솔루션을 확인해 보세요. XIX.AI에서 여정을 시작해 보세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 소년 만화 AI 생성기를 만나보세요. 엄선된 최고 평점 목록에는 박진감 넘치는 액션 장면과 역동적인 에너지 효과를 연출할 수 있는 강력한 도구들이 포함되어 있습니다. 실제 테스트를 통해 무료 버전과 유료 버전을 비교해 보세요. 여러분의 창의력을 마음껏 발휘하여 오늘 바로 장대한 만화를 만들어 보세요!
15 도구
xix.ai

2026년 최신 최고의 AI 경비 관리 도구: 영수증을 스캔하고 기업 경비를 자동으로 분류해 주는 최고 평점의 도구들. 손쉬운 경비 관리, 정확한 재무 추적, 효율적인 규정 준수를 위한 강력하고 혁신적인 솔루션을 만나보세요. 무료 및 유료 옵션을 엄선하여 매주 업데이트되는 비교 자료를 통해 귀사에 딱 맞는 도구를 찾으실 수 있습니다. XIX.AI의 전문가 추천 목록으로 AI의 장점을 최대한 활용하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













