
















 首页
首页字节跳动发布Seed-Thinking-v1.5 AI模型以增强推理能力
高级推理AI的竞赛始于2024年9月OpenAI的o1模型,随着2025年1月DeepSeek的R1发布而加速。
主要AI开发者现正竞相打造更快、更具成本效益的推理AI模型,通过链式思考过程提供精确、深思熟虑的回答,确保回答前的准确性。
字节跳动,TikTok的母公司,推出了Seed-Thinking-v1.5,这是一个在技术论文中概述的新大型语言模型(LLM),旨在提升STEM和通用领域的推理能力。
该模型尚未发布,其许可模式——无论是专有、开源还是混合——仍未披露。然而,该论文提供了值得在发布前探索的关键见解。
利用专家混合(MoE)框架
继Meta的Llama 4和Mistral的Mixtral之后,Seed-Thinking-v1.5采用了专家混合(MoE)架构。
这种方法通过整合多个专注于不同领域的专业模型来提升效率。
Seed-Thinking-v1.5一次仅使用其2000亿参数中的200亿,优化了性能。
字节跳动在GitHub上发布的论文强调了该模型专注于结构化推理和深思熟虑的回答生成。
它超越了DeepSeek R1,并在第三方基准测试中与Google的Gemini 2.5 Pro和OpenAI的o3-mini-high匹敌,甚至在ARC-AGI基准测试中表现出色,该基准是衡量向通用人工智能进展的关键指标,超越了OpenAI标准下人类在经济价值任务中的表现。
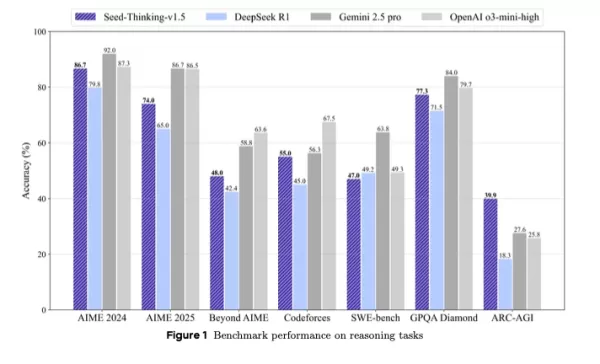
作为紧凑而强大的替代大型模型,Seed-Thinking-v1.5通过创新的强化学习、精选训练数据和先进的AI基础设施实现了强劲的基准测试结果。
基准测试表现与核心优势
Seed-Thinking-v1.5在困难任务中表现出色,在AIME 2024上得分86.7%,在Codeforces上pass@8得分55.0%,在GPQA科学基准测试中得分77.3%,在推理指标上接近或超越OpenAI的o3-mini-high和Google的Gemini 2.5 Pro等模型。
在非推理任务中,它比DeepSeek R1高出8.0%的人类偏好胜率,展示了逻辑和数学之外的多样性。
为应对基准测试饱和,字节跳动创建了BeyondAIME,一个更难的数学基准测试,以抵制记忆并更好地评估模型性能。这与Codeforces数据集一起,将公开发布以助力未来研究。
训练数据策略
数据质量在开发Seed-Thinking-v1.5中至关重要。用于监督微调的40万个样本经过精心挑选:30万个可验证的STEM、逻辑和编码任务,以及10万个不可验证的任务,如创意写作。
用于强化学习的数据分为:
- 可验证问题:从精英竞赛中精心挑选的10万个STEM问题和逻辑谜题,由专家验证。
- 不可验证任务:用于开放式提示的人类偏好数据集,通过成对奖励模型评估。
超过80%的STEM数据专注于高级数学,逻辑任务如数独和24点谜题按模型进展进行扩展。
强化学习创新
Seed-Thinking-v1.5使用定制的actor-critic(VAPO)和策略梯度(DAPO)框架来稳定强化学习,解决长链式思考场景中的问题。
两个奖励模型增强了强化学习监督:
- Seed-Verifier:基于规则的LLM,确保生成答案与参考答案的数学等价性。
- Seed-Thinking-Verifier:基于推理的评判模型,保持一致性评估,抵御奖励操控。
这一双重系统支持简单和复杂任务的精确评估。
可扩展的基础设施设计
字节跳动的HybridFlow框架,由Ray集群提供支持,支持高效的大规模训练,通过协同定位训练和推理以最小化GPU空闲时间。
流式推出系统(SRS)将模型演化与运行时分离,通过异步管理部分生成,将迭代速度提高至三倍。
其他技术包括:
- 混合精度(FP8)以提高内存效率
- 专家并行和内核自动调优以优化MoE
- ByteCheckpoint用于稳健的检查点
- AutoTuner用于优化的并行和内存设置
以人为本的评估与实际应用
在创意写作、人文学科和一般对话的人类测试中,Seed-Thinking-v1.5超越了DeepSeek R1,证明了其现实世界的相关性。
团队指出,在可验证任务上的训练增强了对创意领域的泛化能力,这是由严格的数学工作流程驱动的。
对技术团队和企业的意义
对于管理LLM生命周期的技术领导者,Seed-Thinking-v1.5提供了一个将高级推理整合到企业AI系统中的模型。
其模块化训练,结合可验证数据集和多阶段强化学习,适合需要精确控制的LLM开发团队。
Seed-Verifier和Seed-Thinking-Verifier增强了可信的奖励建模,对于面向客户或受监管的环境至关重要。
对于时间紧迫的团队,VAPO和动态采样减少了迭代周期,简化了特定任务的微调。
混合基础设施,包括SRS和FP8优化,提升了训练吞吐量和硬件效率,适用于云和本地系统。
模型的自适应奖励反馈解决了管理多样化数据管道的挑战,确保跨领域的一致性。
对于数据工程师,严格的数据过滤和专家验证的重点强调了高质量数据集在提升模型性能中的价值。
未来展望
由吴永辉领导、林海滨公开代表的字节跳动Seed LLM系统团队开发的Seed-Thinking-v1.5,基于Doubao 1.5 Pro的努力,采用了共享的RLHF和数据精选技术。
团队旨在改进强化学习,专注于训练效率和不可验证任务的奖励建模。发布BeyondAIME等基准测试将推动推理导向的AI研究的进一步进展。
相关文章
 Google I/O 2026 发布 Gmail 收件箱语音交互功能
谷歌正持续将人工智能融入用户的收件箱。在周二举行的IO 2026开发者大会上,该公司通过对话式人工智能扩展了Gmail的“AI收件箱”功能,让用户能够针对收件箱内容提出问题,而不再仅依赖搜索关键词。据谷歌介绍,这款由Gemini AI驱动的工具名为Gmail Live,可帮助用户快速定位收件箱中被埋没的信息。图片来源:谷歌例如,您可能需要查询即将出发的航班详情、牙医预约时间、爱彼迎(Airbnb)
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
相关专题推荐
商业
Google I/O 2026 发布 Gmail 收件箱语音交互功能
谷歌正持续将人工智能融入用户的收件箱。在周二举行的IO 2026开发者大会上,该公司通过对话式人工智能扩展了Gmail的“AI收件箱”功能,让用户能够针对收件箱内容提出问题,而不再仅依赖搜索关键词。据谷歌介绍,这款由Gemini AI驱动的工具名为Gmail Live,可帮助用户快速定位收件箱中被埋没的信息。图片来源:谷歌例如,您可能需要查询即将出发的航班详情、牙医预约时间、爱彼迎(Airbnb)
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
相关专题推荐
商业
 顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
顶级 AI 定价优化软件:追踪竞争对手并自动调整店铺价格
在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
 10 个工具
10 个工具
 xix.ai
代码
最佳 AI 代码审查工具:自动确保代码符合规范,并重构遗留代码库文件
xix.ai
代码
最佳 AI 代码审查工具:自动确保代码符合规范,并重构遗留代码库文件
在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai
文字转语音
专为阅读障碍设计的顶级AI语音合成应用:助力学生提升学习与阅读效率
探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai
漫画创作
少年漫画顶级AI生成器:打造高能动作场面与特效
在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai
商业
最佳 AI 费用追踪工具:扫描收据并自动分类企业开支
2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai
商业
最佳人工智能招聘工具:筛选简历并自动安排候选人面试
在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

 评论 (1)
0/500
评论 (1)
0/500
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
高级推理AI的竞赛始于2024年9月OpenAI的o1模型,随着2025年1月DeepSeek的R1发布而加速。
主要AI开发者现正竞相打造更快、更具成本效益的推理AI模型,通过链式思考过程提供精确、深思熟虑的回答,确保回答前的准确性。
字节跳动,TikTok的母公司,推出了Seed-Thinking-v1.5,这是一个在技术论文中概述的新大型语言模型(LLM),旨在提升STEM和通用领域的推理能力。
该模型尚未发布,其许可模式——无论是专有、开源还是混合——仍未披露。然而,该论文提供了值得在发布前探索的关键见解。
利用专家混合(MoE)框架
继Meta的Llama 4和Mistral的Mixtral之后,Seed-Thinking-v1.5采用了专家混合(MoE)架构。
这种方法通过整合多个专注于不同领域的专业模型来提升效率。
Seed-Thinking-v1.5一次仅使用其2000亿参数中的200亿,优化了性能。
字节跳动在GitHub上发布的论文强调了该模型专注于结构化推理和深思熟虑的回答生成。
它超越了DeepSeek R1,并在第三方基准测试中与Google的Gemini 2.5 Pro和OpenAI的o3-mini-high匹敌,甚至在ARC-AGI基准测试中表现出色,该基准是衡量向通用人工智能进展的关键指标,超越了OpenAI标准下人类在经济价值任务中的表现。
作为紧凑而强大的替代大型模型,Seed-Thinking-v1.5通过创新的强化学习、精选训练数据和先进的AI基础设施实现了强劲的基准测试结果。
基准测试表现与核心优势
Seed-Thinking-v1.5在困难任务中表现出色,在AIME 2024上得分86.7%,在Codeforces上pass@8得分55.0%,在GPQA科学基准测试中得分77.3%,在推理指标上接近或超越OpenAI的o3-mini-high和Google的Gemini 2.5 Pro等模型。
在非推理任务中,它比DeepSeek R1高出8.0%的人类偏好胜率,展示了逻辑和数学之外的多样性。
为应对基准测试饱和,字节跳动创建了BeyondAIME,一个更难的数学基准测试,以抵制记忆并更好地评估模型性能。这与Codeforces数据集一起,将公开发布以助力未来研究。
训练数据策略
数据质量在开发Seed-Thinking-v1.5中至关重要。用于监督微调的40万个样本经过精心挑选:30万个可验证的STEM、逻辑和编码任务,以及10万个不可验证的任务,如创意写作。
用于强化学习的数据分为:
- 可验证问题:从精英竞赛中精心挑选的10万个STEM问题和逻辑谜题,由专家验证。
- 不可验证任务:用于开放式提示的人类偏好数据集,通过成对奖励模型评估。
超过80%的STEM数据专注于高级数学,逻辑任务如数独和24点谜题按模型进展进行扩展。
强化学习创新
Seed-Thinking-v1.5使用定制的actor-critic(VAPO)和策略梯度(DAPO)框架来稳定强化学习,解决长链式思考场景中的问题。
两个奖励模型增强了强化学习监督:
- Seed-Verifier:基于规则的LLM,确保生成答案与参考答案的数学等价性。
- Seed-Thinking-Verifier:基于推理的评判模型,保持一致性评估,抵御奖励操控。
这一双重系统支持简单和复杂任务的精确评估。
可扩展的基础设施设计
字节跳动的HybridFlow框架,由Ray集群提供支持,支持高效的大规模训练,通过协同定位训练和推理以最小化GPU空闲时间。
流式推出系统(SRS)将模型演化与运行时分离,通过异步管理部分生成,将迭代速度提高至三倍。
其他技术包括:
- 混合精度(FP8)以提高内存效率
- 专家并行和内核自动调优以优化MoE
- ByteCheckpoint用于稳健的检查点
- AutoTuner用于优化的并行和内存设置
以人为本的评估与实际应用
在创意写作、人文学科和一般对话的人类测试中,Seed-Thinking-v1.5超越了DeepSeek R1,证明了其现实世界的相关性。
团队指出,在可验证任务上的训练增强了对创意领域的泛化能力,这是由严格的数学工作流程驱动的。
对技术团队和企业的意义
对于管理LLM生命周期的技术领导者,Seed-Thinking-v1.5提供了一个将高级推理整合到企业AI系统中的模型。
其模块化训练,结合可验证数据集和多阶段强化学习,适合需要精确控制的LLM开发团队。
Seed-Verifier和Seed-Thinking-Verifier增强了可信的奖励建模,对于面向客户或受监管的环境至关重要。
对于时间紧迫的团队,VAPO和动态采样减少了迭代周期,简化了特定任务的微调。
混合基础设施,包括SRS和FP8优化,提升了训练吞吐量和硬件效率,适用于云和本地系统。
模型的自适应奖励反馈解决了管理多样化数据管道的挑战,确保跨领域的一致性。
对于数据工程师,严格的数据过滤和专家验证的重点强调了高质量数据集在提升模型性能中的价值。
未来展望
由吴永辉领导、林海滨公开代表的字节跳动Seed LLM系统团队开发的Seed-Thinking-v1.5,基于Doubao 1.5 Pro的努力,采用了共享的RLHF和数据精选技术。
团队旨在改进强化学习,专注于训练效率和不可验证任务的奖励建模。发布BeyondAIME等基准测试将推动推理导向的AI研究的进一步进展。










 Google I/O 2026 发布 Gmail 收件箱语音交互功能
谷歌正持续将人工智能融入用户的收件箱。在周二举行的IO 2026开发者大会上,该公司通过对话式人工智能扩展了Gmail的“AI收件箱”功能,让用户能够针对收件箱内容提出问题,而不再仅依赖搜索关键词。据谷歌介绍,这款由Gemini AI驱动的工具名为Gmail Live,可帮助用户快速定位收件箱中被埋没的信息。图片来源:谷歌例如,您可能需要查询即将出发的航班详情、牙医预约时间、爱彼迎(Airbnb)
Google I/O 2026 发布 Gmail 收件箱语音交互功能
谷歌正持续将人工智能融入用户的收件箱。在周二举行的IO 2026开发者大会上,该公司通过对话式人工智能扩展了Gmail的“AI收件箱”功能,让用户能够针对收件箱内容提出问题,而不再仅依赖搜索关键词。据谷歌介绍,这款由Gemini AI驱动的工具名为Gmail Live,可帮助用户快速定位收件箱中被埋没的信息。图片来源:谷歌例如,您可能需要查询即将出发的航班详情、牙医预约时间、爱彼迎(Airbnb)
 萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
萨提亚·纳德拉准备利用与OpenAI的新合作关系
周三,一位华尔街分析师直接询问了微软首席执行官萨蒂亚·纳德拉,修订后的OpenAI合作关系将如何影响公司的财务状况。 纳德拉将这一新协议描述为对各方都有利的结果。“我们对与OpenAI的合作感到满意。我始终非常重视任何合作关系,并确保它能够实现双赢。只有这样,双方才能保持良好的合作伙伴关系。” 他强调,微软仍然可以使用OpenAI的知识产权,包括其模型和智能体产品,但不再需要为此向OpenAI支付费用。 谈到在2032年之前可以免费使用OpenAI最先进的人工智能技术,纳德拉表示:“
 OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的
OpenAI勾勒出以公共财富基金、机器人税和每周四天工作制为核心的人工智能经济蓝图
正当各国政府竭力应对超级智能机器带来的经济影响之际,OpenAI发布了一套政策建议,概述了在“智能时代”财富与工作将如何重塑。这些构想将传统左倾机制——例如公共财富基金和扩大的社会安全网——与根本上属于资本主义、由市场驱动的经济框架相结合。OpenAI的提案本质上是一份愿望清单,这份公开声明旨在帮助民选官员、投资者和公众理解这家市值8520亿美元的公司如何看待人工智能在重塑劳动力和经济过程中带来的

在 XIX.AI 上探索 2026 年最佳 AI 定价优化软件。我们精心挑选的清单汇集了备受好评、具有颠覆性意义的工具,这些工具不仅能追踪竞争对手,还能自动调整您的店铺价格,从而实现利润最大化。通过实际测试对比免费与付费选项。立即掌握您的定价优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最佳 AI 代码审查工具。我们的精选列表汇集了备受好评、具有颠覆性的工具,可自动确保代码规范并重构遗留代码库文件。通过实际测试和每周更新的排行榜,对比免费与付费选项。立即开启您的 AI 优势。
10 个工具
xix.ai

探索2026年最新精选的高评分AI语音合成(TTS)应用,专为阅读障碍者提供支持。我们的专家评级对比了免费与付费工具,重点介绍了能够提升阅读效率和学习效果的强大功能。探索这些必试的、具有革命性意义的解决方案,释放学生的潜能。立即访问XIX.AI,开启您的探索之旅。
10 个工具
xix.ai

在 XIX.AI 探索 2026 年最优秀的少年漫画 AI 生成工具。我们精心筛选的这份高评分清单汇集了强大的工具,助您创作充满张力的动作场面和动态能量特效。通过实际测试对比免费与付费选项。释放您的创作潜能,立即开始创作史诗级漫画吧!
15 个工具
xix.ai

2026年最新最佳AI报销管理工具:广受好评的解决方案,可自动扫描收据并分类企业支出。探索这些功能强大、颠覆传统的解决方案,助您轻松管理报销、精准追踪财务并简化合规流程。我们精心整理并每周更新的免费与付费选项对比指南,助您找到最适合的工具。通过XIX.AI的专家精选,释放您的AI优势。
10 个工具
xix.ai

在 XIX.AI 上探索 2026 年最新、评价最高的人工智能招聘工具。我们精心筛选的清单汇集了功能强大、颠覆传统的解决方案,可帮助您筛选简历并自动安排候选人面试。通过实际测试和每周更新的排名,对比免费与付费选项。立即找到最适合您的招聘助手,优化您的招聘流程!
10 个工具
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













