
















 Heim
HeimByteDance enthüllt Seed-Thinking-v1.5 KI-Modell zur Verbesserung der Denkfähigkeiten
Das Rennen um fortschrittliche denkende KI begann mit OpenAIs o1-Modell im September 2024 und gewann mit dem Start von DeepSeeks R1 im Januar 2025 an Dynamik.
Wichtige KI-Entwickler konkurrieren nun darum, schnellere, kostengünstigere denkende KI-Modelle zu entwickeln, die präzise, gut durchdachte Antworten durch verkettete Denkprozesse liefern und Genauigkeit vor der Antwort sicherstellen.
ByteDance, die Muttergesellschaft von TikTok, hat mit Seed-Thinking-v1.5, einem neuen großen Sprachmodell (LLM), das in einem technischen Bericht beschrieben wird, das Ziel, die Denkfähigkeit in STEM- und allgemeinen Bereichen zu verbessern.
Das Modell ist noch nicht verfügbar, und seine Lizenzierung – ob proprietär, Open-Source oder hybrid – bleibt unklar. Der Bericht bietet jedoch wichtige Einblicke, die vor der Veröffentlichung erkundet werden sollten.
Nutzung des Mixture-of-Experts (MoE) Frameworks
Nach Metas Llama 4 und Mistrals Mixtral verwendet Seed-Thinking-v1.5 die Mixture-of-Experts (MoE)-Architektur.
Dieser Ansatz steigert die Effizienz durch die Integration mehrerer spezialisierter Modelle in einem, die jeweils auf unterschiedliche Domänen fokussiert sind.
Seed-Thinking-v1.5 nutzt nur 20 Milliarden seiner 200 Milliarden Parameter gleichzeitig, um die Leistung zu optimieren.
Der auf GitHub veröffentlichte Bericht von ByteDance hebt den Fokus des Modells auf strukturiertes Denken und bewusste Antwortgenerierung hervor.
Es übertrifft DeepSeek R1 und konkurriert mit Googles Gemini 2.5 Pro und OpenAIs o3-mini-high in Benchmarks von Drittanbietern und übertrifft sie sogar im ARC-AGI-Benchmark, einem wichtigen Maß für Fortschritte hin zu künstlicher allgemeiner Intelligenz, die menschliche Leistungen in wirtschaftlich wertvollen Aufgaben übertrifft, gemäß den Standards von OpenAI.
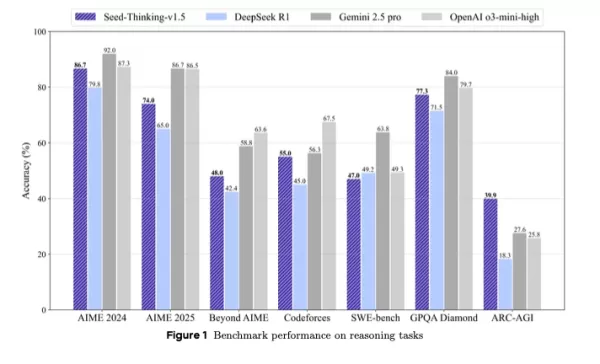
Als kompakte, aber leistungsstarke Alternative zu größeren Modellen positioniert, liefert Seed-Thinking-v1.5 starke Benchmark-Ergebnisse durch innovatives Verstärkendes Lernen, kuratierte Trainingsdaten und fortschrittliche KI-Infrastruktur.
Benchmark-Leistung und Kernstärken
Seed-Thinking-v1.5 glänzt bei schwierigen Aufgaben mit 86,7 % beim AIME 2024, 55,0 % pass@8 bei Codeforces und 77,3 % beim GPQA-Wissenschafts-Benchmark und liegt damit nahe an oder übertrifft Modelle wie OpenAIs o3-mini-high und Googles Gemini 2.5 Pro in Denkfähigkeitsmetriken.
Bei nicht-denkenden Aufgaben erreichte es eine um 8,0 % höhere Präferenzrate bei Menschen gegenüber DeepSeek R1, was Vielseitigkeit jenseits von Logik und Mathematik zeigt.
Um der Benchmarksättigung entgegenzuwirken, entwickelte ByteDance BeyondAIME, einen schwierigeren Mathematik-Benchmark, um Auswendiglernen zu verhindern und die Modellleistung besser zu bewerten. Dieser sowie der Codeforces-Satz werden öffentlich freigegeben, um zukünftige Forschung zu unterstützen.
Ansatz für Trainingsdaten
Die Datenqualität war entscheidend bei der Entwicklung von Seed-Thinking-v1.5. Für das überwachte Feintuning wurden 400.000 Proben kuratiert: 300.000 überprüfbare STEM-, Logik- und Programmieraufgaben sowie 100.000 nicht überprüfbare Aufgaben wie kreatives Schreiben.
Für Verstärkendes Lernen wurden die Daten unterteilt in:
- Überprüfbare Probleme: 100.000 sorgfältig ausgewählte STEM-Fragen und Logikrätsel aus Elitewettbewerben, validiert von Experten.
- Nicht überprüfbare Aufgaben: Datensätze mit menschlichen Präferenzen für offene Aufforderungen, bewertet über paarweise Belohnungsmodelle.
Über 80 % der STEM-Daten konzentrierten sich auf fortgeschrittene Mathematik, mit Logikaufgaben wie Sudoku und 24-Punkte-Rätseln, die an den Modellfortschritt angepasst wurden.
Innovationen im Verstärkenden Lernen
Seed-Thinking-v1.5 verwendet angepasste Actor-Critic (VAPO)- und Policy-Gradient (DAPO)-Frameworks, um Verstärkendes Lernen zu stabilisieren und Probleme in langen verketteten Denk-Szenarien zu lösen.
Zwei Belohnungsmodelle verbessern die RL-Überwachung:
- Seed-Verifier: Ein regelbasiertes LLM, das mathematische Äquivalenz zwischen generierten und Referenzantworten sicherstellt.
- Seed-Thinking-Verifier: Ein denkbasierter Richter für konsistente Bewertung, resistent gegen Belohnungsmanipulation.
Dieses duale System unterstützt präzise Bewertungen bei einfachen und komplexen Aufgaben.
Skalierbares Infrastrukturdesign
ByteDances HybridFlow-Framework, unterstützt von Ray-Clustern, ermöglicht effizientes Training großer Modelle mit kollokiertem Training und Inferenz, um GPU-Leerlaufzeiten zu minimieren.
Das Streaming Rollout System (SRS) trennt die Modellevolution vom Laufzeitbetrieb und beschleunigt Iterationen bis zu dreimal durch asynchrones Management von Teilgenerierungen.
Zusätzliche Techniken umfassen:
- Gemischte Präzision (FP8) für Speichereffizienz
- Experten-Parallelismus und Kernel-Auto-Tuning für MoE-Optimierung
- ByteCheckpoint für robustes Checkpointing
- AutoTuner für optimierte Parallelismus- und Speichereinstellungen
Menschzentrierte Bewertung und Anwendungen
Menschliche Tests in kreativem Schreiben, Geisteswissenschaften und allgemeinen Gesprächen zeigten, dass Seed-Thinking-v1.5 DeepSeek R1 übertrifft und seine Relevanz in der realen Welt beweist.
Das Team stellt fest, dass das Training mit überprüfbaren Aufgaben die Verallgemeinerung auf kreative Domänen verbesserte, angetrieben durch rigorose mathematische Arbeitsabläufe.
Bedeutung für technische Teams und Unternehmen
Für technische Leiter, die LLM-Lebenszyklen überwachen, bietet Seed-Thinking-v1.5 ein Modell zur Integration fortschrittlicher Denkfähigkeiten in Unternehmens-KI-Systeme.
Sein modulares Training mit überprüfbaren Datensätzen und mehrphasigem Verstärkendem Lernen eignet sich für Teams, die LLM-Entwicklung mit präziser Kontrolle skalieren.
Seed-Verifier und Seed-Thinking-Verifier verbessern vertrauenswürdige Belohnungsmodellierung, entscheidend für kundenorientierte oder regulierte Umgebungen.
Für Teams mit engen Zeitplänen reduzieren VAPO und dynamisches Sampling Iterationszyklen und optimieren aufgabenspezifisches Feintuning.
Die hybride Infrastruktur, einschließlich SRS und FP8-Optimierung, steigert den Trainingsdurchsatz und die Hardwareeffizienz, ideal für Cloud- und lokale Systeme.
Das adaptive Belohnungsfeedback des Modells löst Herausforderungen bei der Verwaltung vielfältiger Datenpipelines und gewährleistet Konsistenz über Domänen hinweg.
Für Dateningenieure unterstreicht der Fokus auf rigoroses Datenfiltern und Expertenverifikation den Wert hochwertiger Datensätze zur Steigerung der Modellleistung.
Ausblick
Entwickelt vom Seed LLM Systems-Team von ByteDance unter der Leitung von Yonghui Wu und öffentlich vertreten durch Haibin Lin, baut Seed-Thinking-v1.5 auf Bemühungen wie Doubao 1.5 Pro auf, unter Verwendung gemeinsamer RLHF- und Datencuration-Techniken.
Das Team zielt darauf ab, Verstärkendes Lernen zu verfeinern, mit Fokus auf Trainingseffizienz und Belohnungsmodellierung für nicht überprüfbare Aufgaben. Die Veröffentlichung von Benchmarks wie BeyondAIME wird weitere Fortschritte in der denkfokussierten KI-Forschung vorantreiben.
Verwandter Artikel
 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz
Empfehlungen zu verwandten Spezialthemen
Text-zu-Sprache
 Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Die besten KI-Sprachausgabe-Apps für Legasthenie: Unterstützung für das Lernen und effizienteres Lesen bei Schülern
Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
 10 Tools
10 Tools
 xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
xix.ai
Comic-Erstellung
Die besten KI-Generatoren für Shonen-Manga: Erstelle actiongeladene Sequenzen und dynamische Effekte
Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai
Geschäft
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

 Kommentare (1)
Kommentare (1)
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
Das Rennen um fortschrittliche denkende KI begann mit OpenAIs o1-Modell im September 2024 und gewann mit dem Start von DeepSeeks R1 im Januar 2025 an Dynamik.
Wichtige KI-Entwickler konkurrieren nun darum, schnellere, kostengünstigere denkende KI-Modelle zu entwickeln, die präzise, gut durchdachte Antworten durch verkettete Denkprozesse liefern und Genauigkeit vor der Antwort sicherstellen.
ByteDance, die Muttergesellschaft von TikTok, hat mit Seed-Thinking-v1.5, einem neuen großen Sprachmodell (LLM), das in einem technischen Bericht beschrieben wird, das Ziel, die Denkfähigkeit in STEM- und allgemeinen Bereichen zu verbessern.
Das Modell ist noch nicht verfügbar, und seine Lizenzierung – ob proprietär, Open-Source oder hybrid – bleibt unklar. Der Bericht bietet jedoch wichtige Einblicke, die vor der Veröffentlichung erkundet werden sollten.
Nutzung des Mixture-of-Experts (MoE) Frameworks
Nach Metas Llama 4 und Mistrals Mixtral verwendet Seed-Thinking-v1.5 die Mixture-of-Experts (MoE)-Architektur.
Dieser Ansatz steigert die Effizienz durch die Integration mehrerer spezialisierter Modelle in einem, die jeweils auf unterschiedliche Domänen fokussiert sind.
Seed-Thinking-v1.5 nutzt nur 20 Milliarden seiner 200 Milliarden Parameter gleichzeitig, um die Leistung zu optimieren.
Der auf GitHub veröffentlichte Bericht von ByteDance hebt den Fokus des Modells auf strukturiertes Denken und bewusste Antwortgenerierung hervor.
Es übertrifft DeepSeek R1 und konkurriert mit Googles Gemini 2.5 Pro und OpenAIs o3-mini-high in Benchmarks von Drittanbietern und übertrifft sie sogar im ARC-AGI-Benchmark, einem wichtigen Maß für Fortschritte hin zu künstlicher allgemeiner Intelligenz, die menschliche Leistungen in wirtschaftlich wertvollen Aufgaben übertrifft, gemäß den Standards von OpenAI.
Als kompakte, aber leistungsstarke Alternative zu größeren Modellen positioniert, liefert Seed-Thinking-v1.5 starke Benchmark-Ergebnisse durch innovatives Verstärkendes Lernen, kuratierte Trainingsdaten und fortschrittliche KI-Infrastruktur.
Benchmark-Leistung und Kernstärken
Seed-Thinking-v1.5 glänzt bei schwierigen Aufgaben mit 86,7 % beim AIME 2024, 55,0 % pass@8 bei Codeforces und 77,3 % beim GPQA-Wissenschafts-Benchmark und liegt damit nahe an oder übertrifft Modelle wie OpenAIs o3-mini-high und Googles Gemini 2.5 Pro in Denkfähigkeitsmetriken.
Bei nicht-denkenden Aufgaben erreichte es eine um 8,0 % höhere Präferenzrate bei Menschen gegenüber DeepSeek R1, was Vielseitigkeit jenseits von Logik und Mathematik zeigt.
Um der Benchmarksättigung entgegenzuwirken, entwickelte ByteDance BeyondAIME, einen schwierigeren Mathematik-Benchmark, um Auswendiglernen zu verhindern und die Modellleistung besser zu bewerten. Dieser sowie der Codeforces-Satz werden öffentlich freigegeben, um zukünftige Forschung zu unterstützen.
Ansatz für Trainingsdaten
Die Datenqualität war entscheidend bei der Entwicklung von Seed-Thinking-v1.5. Für das überwachte Feintuning wurden 400.000 Proben kuratiert: 300.000 überprüfbare STEM-, Logik- und Programmieraufgaben sowie 100.000 nicht überprüfbare Aufgaben wie kreatives Schreiben.
Für Verstärkendes Lernen wurden die Daten unterteilt in:
- Überprüfbare Probleme: 100.000 sorgfältig ausgewählte STEM-Fragen und Logikrätsel aus Elitewettbewerben, validiert von Experten.
- Nicht überprüfbare Aufgaben: Datensätze mit menschlichen Präferenzen für offene Aufforderungen, bewertet über paarweise Belohnungsmodelle.
Über 80 % der STEM-Daten konzentrierten sich auf fortgeschrittene Mathematik, mit Logikaufgaben wie Sudoku und 24-Punkte-Rätseln, die an den Modellfortschritt angepasst wurden.
Innovationen im Verstärkenden Lernen
Seed-Thinking-v1.5 verwendet angepasste Actor-Critic (VAPO)- und Policy-Gradient (DAPO)-Frameworks, um Verstärkendes Lernen zu stabilisieren und Probleme in langen verketteten Denk-Szenarien zu lösen.
Zwei Belohnungsmodelle verbessern die RL-Überwachung:
- Seed-Verifier: Ein regelbasiertes LLM, das mathematische Äquivalenz zwischen generierten und Referenzantworten sicherstellt.
- Seed-Thinking-Verifier: Ein denkbasierter Richter für konsistente Bewertung, resistent gegen Belohnungsmanipulation.
Dieses duale System unterstützt präzise Bewertungen bei einfachen und komplexen Aufgaben.
Skalierbares Infrastrukturdesign
ByteDances HybridFlow-Framework, unterstützt von Ray-Clustern, ermöglicht effizientes Training großer Modelle mit kollokiertem Training und Inferenz, um GPU-Leerlaufzeiten zu minimieren.
Das Streaming Rollout System (SRS) trennt die Modellevolution vom Laufzeitbetrieb und beschleunigt Iterationen bis zu dreimal durch asynchrones Management von Teilgenerierungen.
Zusätzliche Techniken umfassen:
- Gemischte Präzision (FP8) für Speichereffizienz
- Experten-Parallelismus und Kernel-Auto-Tuning für MoE-Optimierung
- ByteCheckpoint für robustes Checkpointing
- AutoTuner für optimierte Parallelismus- und Speichereinstellungen
Menschzentrierte Bewertung und Anwendungen
Menschliche Tests in kreativem Schreiben, Geisteswissenschaften und allgemeinen Gesprächen zeigten, dass Seed-Thinking-v1.5 DeepSeek R1 übertrifft und seine Relevanz in der realen Welt beweist.
Das Team stellt fest, dass das Training mit überprüfbaren Aufgaben die Verallgemeinerung auf kreative Domänen verbesserte, angetrieben durch rigorose mathematische Arbeitsabläufe.
Bedeutung für technische Teams und Unternehmen
Für technische Leiter, die LLM-Lebenszyklen überwachen, bietet Seed-Thinking-v1.5 ein Modell zur Integration fortschrittlicher Denkfähigkeiten in Unternehmens-KI-Systeme.
Sein modulares Training mit überprüfbaren Datensätzen und mehrphasigem Verstärkendem Lernen eignet sich für Teams, die LLM-Entwicklung mit präziser Kontrolle skalieren.
Seed-Verifier und Seed-Thinking-Verifier verbessern vertrauenswürdige Belohnungsmodellierung, entscheidend für kundenorientierte oder regulierte Umgebungen.
Für Teams mit engen Zeitplänen reduzieren VAPO und dynamisches Sampling Iterationszyklen und optimieren aufgabenspezifisches Feintuning.
Die hybride Infrastruktur, einschließlich SRS und FP8-Optimierung, steigert den Trainingsdurchsatz und die Hardwareeffizienz, ideal für Cloud- und lokale Systeme.
Das adaptive Belohnungsfeedback des Modells löst Herausforderungen bei der Verwaltung vielfältiger Datenpipelines und gewährleistet Konsistenz über Domänen hinweg.
Für Dateningenieure unterstreicht der Fokus auf rigoroses Datenfiltern und Expertenverifikation den Wert hochwertiger Datensätze zur Steigerung der Modellleistung.
Ausblick
Entwickelt vom Seed LLM Systems-Team von ByteDance unter der Leitung von Yonghui Wu und öffentlich vertreten durch Haibin Lin, baut Seed-Thinking-v1.5 auf Bemühungen wie Doubao 1.5 Pro auf, unter Verwendung gemeinsamer RLHF- und Datencuration-Techniken.
Das Team zielt darauf ab, Verstärkendes Lernen zu verfeinern, mit Fokus auf Trainingseffizienz und Belohnungsmodellierung für nicht überprüfbare Aufgaben. Die Veröffentlichung von Benchmarks wie BeyondAIME wird weitere Fortschritte in der denkfokussierten KI-Forschung vorantreiben.










 Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
Satya Nadella bereit, die neuen Vorteile der Vereinbarung mit OpenAI zu nutzen
Am Mittwoch fragte ein Analyst von Wall Street den Microsoft-CEO Satya Nadella direkt, wie die überarbeitete Partnerschaft mit OpenAI die finanziellen Ergebnisse des Unternehmens beeinflussen würde.Nadella bezeichnete die neue Vereinbarung als einen
 OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
OpenAI skizziert eine KI-Wirtschaft mit öffentlichen Vermögensfonds, Robotersteuern und einer Vier-Tage-Woche
Während Regierungen darum ringen, die wirtschaftlichen Auswirkungen superintelligenter Maschinen zu bewältigen, hat OpenAI eine Reihe von politischen Vorschlägen veröffentlicht, in denen dargelegt wir
 Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz
Meta unterzeichnet Vertrag über Millionen von Amazon-KI-CPUs
Amazon hat eine bedeutende Partnerschaft mit Meta geschlossen und setzt dabei erneut auf seine eigenen, speziell entwickelten Chips. Meta hat sich bereit erklärt, Millionen von AWS-Graviton-Chips einz

Entdecken Sie die besten KI-TTS-Apps des Jahres 2026, die speziell zur Unterstützung bei Legasthenie ausgewählt wurden. In unseren Experten-Rankings vergleichen wir kostenlose und kostenpflichtige Tools und stellen leistungsstarke Funktionen für mehr Leseeffizienz und besseren Lernerfolg vor. Entdecken Sie bahnbrechende Lösungen, die Sie unbedingt ausprobieren sollten, um das Potenzial Ihrer Schüler voll auszuschöpfen. Beginnen Sie Ihre Reise bei XIX.AI.
10 Tools
xix.ai

Entdecken Sie bei XIX.AI die besten KI-Generatoren für Shonen-Manga des Jahres 2026. Unsere sorgfältig zusammengestellte Liste der Top-Anbieter umfasst leistungsstarke Tools zur Erstellung actiongeladener Sequenzen und dynamischer Energieeffekte. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests. Entfalten Sie Ihr kreatives Potenzial und beginnen Sie noch heute mit der Gestaltung epischer Manga!
15 Tools
xix.ai

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













