
















 Home
HomeByteDance Unveils Seed-Thinking-v1.5 AI Model to Boost Reasoning Capabilities
The race for advanced reasoning AI began with OpenAI’s o1 model in September 2024, gaining momentum with DeepSeek’s R1 launch in January 2025.
Major AI developers are now competing to create faster, more cost-effective reasoning AI models that deliver precise, well-thought-out responses through chain-of-thought processes, ensuring accuracy before answering.
ByteDance, the parent company of TikTok, has entered the fray with Seed-Thinking-v1.5, a new large language model (LLM) outlined in a technical paper, aimed at enhancing reasoning in STEM and general domains.
The model is not yet available, and its licensing—whether proprietary, open-source, or hybrid—remains undisclosed. The paper, however, offers key insights worth exploring ahead of its release.
Leveraging the Mixture-of-Experts (MoE) Framework
Following Meta’s Llama 4 and Mistral’s Mixtral, Seed-Thinking-v1.5 adopts the Mixture-of-Experts (MoE) architecture.
This approach enhances efficiency by integrating multiple specialized models into one, each focusing on distinct domains.
Seed-Thinking-v1.5 uses just 20 billion of its 200 billion parameters at a time, optimizing performance.
ByteDance’s GitHub-published paper highlights the model’s focus on structured reasoning and deliberate response generation.
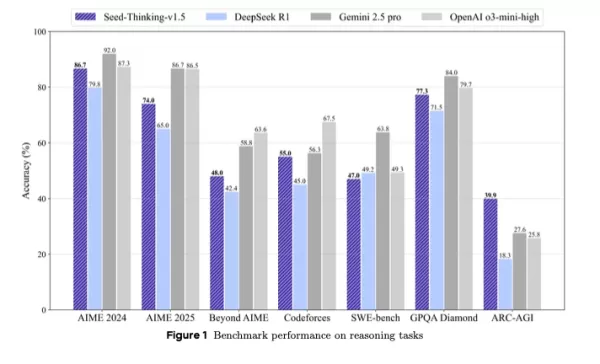
It surpasses DeepSeek R1 and rivals Google’s Gemini 2.5 Pro and OpenAI’s o3-mini-high in third-party benchmarks, even outperforming them on the ARC-AGI benchmark, a key measure of progress toward artificial general intelligence, exceeding human performance in economically valuable tasks, per OpenAI’s standards.
Positioned as a compact yet powerful alternative to larger models, Seed-Thinking-v1.5 delivers strong benchmark results through innovative reinforcement learning, curated training data, and advanced AI infrastructure.
Benchmark Performance and Core Strengths
Seed-Thinking-v1.5 excels in tough tasks, scoring 86.7% on AIME 2024, 55.0% pass@8 on Codeforces, and 77.3% on the GPQA science benchmark, closely matching or exceeding models like OpenAI’s o3-mini-high and Google’s Gemini 2.5 Pro in reasoning metrics.
In non-reasoning tasks, it achieved an 8.0% higher human preference win rate over DeepSeek R1, showing versatility beyond logic and math.
To counter benchmark saturation, ByteDance created BeyondAIME, a tougher math benchmark to resist memorization and better evaluate model performance. This, along with the Codeforces set, will be publicly released to aid future research.
Training Data Approach
Data quality was pivotal in developing Seed-Thinking-v1.5. For supervised fine-tuning, 400,000 samples were curated: 300,000 verifiable STEM, logic, and coding tasks, and 100,000 non-verifiable tasks like creative writing.
For reinforcement learning, data was divided into:
- Verifiable problems: 100,000 carefully selected STEM questions and logic puzzles from elite competitions, validated by experts.
- Non-verifiable tasks: Human-preference datasets for open-ended prompts, assessed via pairwise reward models.
Over 80% of STEM data focused on advanced mathematics, with logic tasks like Sudoku and 24-point puzzles scaled to match model progress.
Reinforcement Learning Innovations
Seed-Thinking-v1.5 uses custom actor-critic (VAPO) and policy-gradient (DAPO) frameworks to stabilize reinforcement learning, addressing issues in long chain-of-thought scenarios.
Two reward models enhance RL supervision:
- Seed-Verifier: A rule-based LLM ensuring mathematical equivalence between generated and reference answers.
- Seed-Thinking-Verifier: A reasoning-based judge for consistent evaluation, resistant to reward manipulation.
This dual system supports precise assessment across simple and complex tasks.
Scalable Infrastructure Design
ByteDance’s HybridFlow framework, powered by Ray clusters, supports efficient large-scale training with co-located training and inference to minimize GPU idle time.
The Streaming Rollout System (SRS) separates model evolution from runtime, speeding up iterations by up to three times through asynchronous management of partial generations.
Additional techniques include:
- Mixed precision (FP8) for memory efficiency
- Expert parallelism and kernel auto-tuning for MoE optimization
- ByteCheckpoint for robust checkpointing
- AutoTuner for optimized parallelism and memory settings
Human-Centric Evaluation and Applications
Human testing across creative writing, humanities, and general conversation showed Seed-Thinking-v1.5 outperforming DeepSeek R1, proving its real-world relevance.
The team notes that training on verifiable tasks enhanced generalization to creative domains, driven by rigorous mathematical workflows.
Implications for Technical Teams and Enterprises
For technical leaders overseeing LLM lifecycles, Seed-Thinking-v1.5 offers a model for integrating advanced reasoning into enterprise AI systems.
Its modular training, with verifiable datasets and multi-phase reinforcement learning, suits teams scaling LLM development with precise control.
Seed-Verifier and Seed-Thinking-Verifier enhance trustworthy reward modeling, vital for customer-facing or regulated settings.
For teams with tight schedules, VAPO and dynamic sampling reduce iteration cycles, streamlining task-specific fine-tuning.
The hybrid infrastructure, including SRS and FP8 optimization, boosts training throughput and hardware efficiency, ideal for cloud and on-premises systems.
The model’s adaptive reward feedback addresses challenges in managing diverse data pipelines, ensuring consistency across domains.
For data engineers, the focus on rigorous data filtering and expert verification underscores the value of high-quality datasets in boosting model performance.
Looking Ahead
Developed by ByteDance’s Seed LLM Systems team, led by Yonghui Wu and represented publicly by Haibin Lin, Seed-Thinking-v1.5 builds on efforts like Doubao 1.5 Pro, using shared RLHF and data curation techniques.
The team aims to refine reinforcement learning, focusing on training efficiency and reward modeling for non-verifiable tasks. Releasing benchmarks like BeyondAIME will drive further progress in reasoning-focused AI research.
Related article
 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton
Related Special Topic Recommendations
Comic Creation
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton
Related Special Topic Recommendations
Comic Creation
 Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Top AI Generators for Shonen Manga: Create High-Octane Action Sequences & Energy Effects
Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
 15 tools
15 tools
 xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
xix.ai
Business
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

 Comments (1)
0/500
Comments (1)
0/500
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
The race for advanced reasoning AI began with OpenAI’s o1 model in September 2024, gaining momentum with DeepSeek’s R1 launch in January 2025.
Major AI developers are now competing to create faster, more cost-effective reasoning AI models that deliver precise, well-thought-out responses through chain-of-thought processes, ensuring accuracy before answering.
ByteDance, the parent company of TikTok, has entered the fray with Seed-Thinking-v1.5, a new large language model (LLM) outlined in a technical paper, aimed at enhancing reasoning in STEM and general domains.
The model is not yet available, and its licensing—whether proprietary, open-source, or hybrid—remains undisclosed. The paper, however, offers key insights worth exploring ahead of its release.
Leveraging the Mixture-of-Experts (MoE) Framework
Following Meta’s Llama 4 and Mistral’s Mixtral, Seed-Thinking-v1.5 adopts the Mixture-of-Experts (MoE) architecture.
This approach enhances efficiency by integrating multiple specialized models into one, each focusing on distinct domains.
Seed-Thinking-v1.5 uses just 20 billion of its 200 billion parameters at a time, optimizing performance.
ByteDance’s GitHub-published paper highlights the model’s focus on structured reasoning and deliberate response generation.
It surpasses DeepSeek R1 and rivals Google’s Gemini 2.5 Pro and OpenAI’s o3-mini-high in third-party benchmarks, even outperforming them on the ARC-AGI benchmark, a key measure of progress toward artificial general intelligence, exceeding human performance in economically valuable tasks, per OpenAI’s standards.
Positioned as a compact yet powerful alternative to larger models, Seed-Thinking-v1.5 delivers strong benchmark results through innovative reinforcement learning, curated training data, and advanced AI infrastructure.
Benchmark Performance and Core Strengths
Seed-Thinking-v1.5 excels in tough tasks, scoring 86.7% on AIME 2024, 55.0% pass@8 on Codeforces, and 77.3% on the GPQA science benchmark, closely matching or exceeding models like OpenAI’s o3-mini-high and Google’s Gemini 2.5 Pro in reasoning metrics.
In non-reasoning tasks, it achieved an 8.0% higher human preference win rate over DeepSeek R1, showing versatility beyond logic and math.
To counter benchmark saturation, ByteDance created BeyondAIME, a tougher math benchmark to resist memorization and better evaluate model performance. This, along with the Codeforces set, will be publicly released to aid future research.
Training Data Approach
Data quality was pivotal in developing Seed-Thinking-v1.5. For supervised fine-tuning, 400,000 samples were curated: 300,000 verifiable STEM, logic, and coding tasks, and 100,000 non-verifiable tasks like creative writing.
For reinforcement learning, data was divided into:
- Verifiable problems: 100,000 carefully selected STEM questions and logic puzzles from elite competitions, validated by experts.
- Non-verifiable tasks: Human-preference datasets for open-ended prompts, assessed via pairwise reward models.
Over 80% of STEM data focused on advanced mathematics, with logic tasks like Sudoku and 24-point puzzles scaled to match model progress.
Reinforcement Learning Innovations
Seed-Thinking-v1.5 uses custom actor-critic (VAPO) and policy-gradient (DAPO) frameworks to stabilize reinforcement learning, addressing issues in long chain-of-thought scenarios.
Two reward models enhance RL supervision:
- Seed-Verifier: A rule-based LLM ensuring mathematical equivalence between generated and reference answers.
- Seed-Thinking-Verifier: A reasoning-based judge for consistent evaluation, resistant to reward manipulation.
This dual system supports precise assessment across simple and complex tasks.
Scalable Infrastructure Design
ByteDance’s HybridFlow framework, powered by Ray clusters, supports efficient large-scale training with co-located training and inference to minimize GPU idle time.
The Streaming Rollout System (SRS) separates model evolution from runtime, speeding up iterations by up to three times through asynchronous management of partial generations.
Additional techniques include:
- Mixed precision (FP8) for memory efficiency
- Expert parallelism and kernel auto-tuning for MoE optimization
- ByteCheckpoint for robust checkpointing
- AutoTuner for optimized parallelism and memory settings
Human-Centric Evaluation and Applications
Human testing across creative writing, humanities, and general conversation showed Seed-Thinking-v1.5 outperforming DeepSeek R1, proving its real-world relevance.
The team notes that training on verifiable tasks enhanced generalization to creative domains, driven by rigorous mathematical workflows.
Implications for Technical Teams and Enterprises
For technical leaders overseeing LLM lifecycles, Seed-Thinking-v1.5 offers a model for integrating advanced reasoning into enterprise AI systems.
Its modular training, with verifiable datasets and multi-phase reinforcement learning, suits teams scaling LLM development with precise control.
Seed-Verifier and Seed-Thinking-Verifier enhance trustworthy reward modeling, vital for customer-facing or regulated settings.
For teams with tight schedules, VAPO and dynamic sampling reduce iteration cycles, streamlining task-specific fine-tuning.
The hybrid infrastructure, including SRS and FP8 optimization, boosts training throughput and hardware efficiency, ideal for cloud and on-premises systems.
The model’s adaptive reward feedback addresses challenges in managing diverse data pipelines, ensuring consistency across domains.
For data engineers, the focus on rigorous data filtering and expert verification underscores the value of high-quality datasets in boosting model performance.
Looking Ahead
Developed by ByteDance’s Seed LLM Systems team, led by Yonghui Wu and represented publicly by Haibin Lin, Seed-Thinking-v1.5 builds on efforts like Doubao 1.5 Pro, using shared RLHF and data curation techniques.
The team aims to refine reinforcement learning, focusing on training efficiency and reward modeling for non-verifiable tasks. Releasing benchmarks like BeyondAIME will drive further progress in reasoning-focused AI research.










 Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
Satya Nadella ready to exploit new OpenAI deal
On Wednesday, a Wall Street analyst asked Microsoft CEO Satya Nadella directly how the revised OpenAI partnership would affect the company’s financials.Nadella described the new agreement as a win for everyone. “We feel good about our partnership wit
 OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
OpenAI outlines AI economy with public wealth funds, robot taxes, and four-day week
As governments struggle to manage the economic impact of superintelligent machines, OpenAI has released a set of policy proposals outlining how wealth and work could be reshaped in an "intelligence age." The ideas blend traditional left-leaning mecha
 Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton
Meta signs deal for millions of Amazon AI CPUs
Amazon has secured a significant partnership with Meta, once again relying on its own custom-designed chips. Meta has agreed to deploy millions of AWS Graviton chips to meet its expanding AI demands, Amazon confirmed on Friday.Note that AWS Graviton

Discover the 2026 best AI generators for Shonen manga at XIX.AI. Our top-rated, curated list features powerful tools for creating high-octane action sequences and dynamic energy effects. Compare free vs paid options with real-world tests. Unlock your creative potential and start crafting epic manga today!
15 tools
xix.ai

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













