
















 家
家バイトダンスがSeed-Thinking-v1.5 AIモデルを公開し、推論能力を向上
高度な推論AIの競争は、2024年9月にOpenAIのo1モデルで始まり、2025年1月のDeepSeekのR1ローンチで勢いを増しました。
主要なAI開発企業は現在、より高速でコスト効率の高い推論AIモデルを開発するために競争しており、チェーン・オブ・ソートプロセスを通じて正確でよく考え抜かれた応答を提供し、回答前に正確性を確保しています。
TikTokの親会社であるバイトダンスは、技術論文で概要が示された新しい大規模言語モデル(LLM)であるSeed-Thinking-v1.5を発表し、STEMおよび一般的な領域での推論を強化することを目指しています。
このモデルはまだ利用可能ではなく、ライセンスが独自仕様、オープンソース、またはハイブリッドのいずれであるかは未公開です。ただし、論文にはリリース前に探る価値のある重要な洞察が含まれています。
Mixture-of-Experts(MoE)フレームワークの活用
MetaのLlama 4やMistralのMixtralに続き、Seed-Thinking-v1.5はMixture-of-Experts(MoE)アーキテクチャを採用しています。
このアプローチは、複数の専門モデルを1つに統合し、それぞれが異なる領域に焦点を当てることで効率を高めます。
Seed-Thinking-v1.5は、2000億のパラメータのうち200億のみを一度に使用し、パフォーマンスを最適化しています。
バイトダンスのGitHubで公開された論文は、モデルの構造化された推論と意図的な応答生成への焦点を強調しています。
これはDeepSeek R1を超え、GoogleのGemini 2.5 ProやOpenAIのo3-mini-highと第三者ベンチマークで競合し、ARC-AGIベンチマークではそれらを上回り、OpenAIの基準に従って経済的に価値のあるタスクで人間のパフォーマンスを超える、人工知能の進歩の重要な指標です。
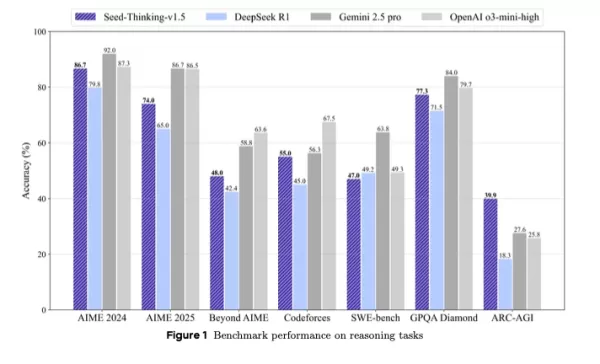
コンパクトでありながら強力な代替として位置付けられたSeed-Thinking-v1.5は、革新的な強化学習、厳選されたトレーニングデータ、先進的なAIインフラストラクチャを通じて優れたベンチマーク結果を提供します。
ベンチマーク性能とコアの強み
Seed-Thinking-v1.5は困難なタスクで優れており、AIME 2024で86.7%、Codeforcesでpass@8で55.0%、GPQA科学ベンチマークで77.3%を記録し、OpenAIのo3-mini-highやGoogleのGemini 2.5 Proと推論指標でほぼ同等またはそれらを上回っています。
非推論タスクでは、DeepSeek R1に対して8.0%高い人間の好み勝率を達成し、論理や数学を超えた汎用性を示しています。
ベンチマークの飽和に対抗するため、バイトダンスは記憶に頼らないより厳しい数学ベンチマークであるBeyondAIMEを作成し、モデル性能をより良く評価します。このベンチマークは、Codeforcesセットと共に、将来の研究を支援するために公開されます。
トレーニングデータのアプローチ
Seed-Thinking-v1.5の開発ではデータ品質が重要でした。教師あり微調整のために、40万のサンプルが厳選されました:30万の検証可能なSTEM、論理、コーディングタスクと、10万のクリエイティブライティングのような検証不可能なタスクです。
強化学習のために、データは以下に分けられました:
- 検証可能な問題:エリート競技から慎重に選ばれた10万のSTEM質問と論理パズル、専門家によって検証されました。
- 検証不可能なタスク:オープンエンドのプロンプトに対する人間の好みデータセット、ペアワイズ報酬モデルで評価されました。
STEMデータの80%以上は高度な数学に焦点を当て、Sudokuや24ポイントパズルなどの論理タスクはモデル進捗に合わせてスケールされました。
強化学習の革新
Seed-Thinking-v1.5は、カスタムのアクター-クリティック(VAPO)およびポリシー勾配(DAPO)フレームワークを使用して、長いチェーン・オブ・ソートシナリオでの問題に対処し、強化学習を安定化します。
2つの報酬モデルがRL監督を強化します:
- Seed-Verifier:生成された回答と参照回答の数学的同等性を保証するルールベースのLLM。
- Seed-Thinking-Verifier:報酬操作に耐性のある一貫した評価のための推論ベースのジャッジ。
このデュアルシステムは、単純および複雑なタスクでの正確な評価をサポートします。
スケーラブルなインフラストラクチャ設計
バイトダンスのHybridFlowフレームワークは、Rayクラスタによって支えられ、GPUのアイドル時間を最小化する共同配置されたトレーニングと推論で効率的な大規模トレーニングをサポートします。
ストリーミングロールアウトシステム(SRS)は、モデル進化とランタイムを分離し、部分生成の非同期管理により反復を最大3倍高速化します。
追加の技術には以下が含まれます:
- メモリ効率のための混合精度(FP8)
- MoE最適化のためのエキスパート並列処理とカーネル自動チューニング
- 堅牢なチェックポインティングのためのByteCheckpoint
- 最適化された並列処理とメモリ設定のためのAutoTuner
人間中心の評価と応用
クリエイティブライティング、人文科学、一般会話での人間のテストでは、Seed-Thinking-v1.5がDeepSeek R1を上回り、現実世界での関連性を証明しました。
チームは、検証可能なタスクでのトレーニングが、厳格な数学的ワークフローに駆動されて、クリエイティブな領域への一般化を強化したと述べています。
技術チームと企業への影響
LLMライフサイクルを監督する技術リーダーにとって、Seed-Thinking-v1.5は高度な推論を企業AIシステムに統合するモデルを提供します。
検証可能なデータセットと多段階の強化学習によるモジュラートレーニングは、LLM開発を正確に制御しながらスケールするチームに適しています。
Seed-VerifierとSeed-Thinking-Verifierは、顧客向けまたは規制された環境で重要な信頼性の高い報酬モデリングを強化します。
タイトなスケジュールのチームにとって、VAPOと動的サンプリングは反復サイクルを短縮し、タスク固有の微調整を効率化します。
ハイブリッドインフラストラクチャ(SRSやFP8最適化を含む)は、トレーニングスループットとハードウェア効率を高め、クラウドおよびオンプレミスシステムに最適です。
モデルの適応型報酬フィードバックは、多様なデータパイプラインの管理における課題に対処し、ドメイン間で一貫性を確保します。
データエンジニアにとって、厳格なデータフィルタリングと専門家検証への焦点は、モデル性能向上における高品質データセットの価値を強調します。
今後の展望
バイトダンスのSeed LLM Systemsチームによって開発され、Yonghui Wuが率い、Haibin Linが公開代表を務めるSeed-Thinking-v1.5は、Doubao 1.5 Proなどの取り組みを基盤とし、共有されたRLHFとデータキュレーション技術を使用しています。
チームは、トレーニング効率と検証不可能なタスクの報酬モデリングに焦点を当て、強化学習を改良することを目指しています。BeyondAIMEのようなベンチマークの公開は、推論に焦点を当てたAI研究のさらなる進展を促進します。
関連記事
 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
関連特集おすすめ
コード
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
関連特集おすすめ
コード
 最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
最高のAIコードレビューツール:クリーンコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリング
XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
 10 ツール
10 ツール
 xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
xix.ai
テキスト読み上げ
ディスレクシアに最適なAI音声合成アプリ:生徒の学習と読解力の向上をサポート
ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai
漫画制作
少年漫画向けトップAIジェネレーター:迫力満点のアクションシーンやエネルギーエフェクトを作成
XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai
仕事
おすすめのAI経費管理ツール:レシートをスキャンして、業務経費を自動分類
2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai
仕事
おすすめのAI採用ツール:履歴書の選考と候補者の面接スケジュール管理を自動化
XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai
生産性
AIパーソナルウェルネス&集中力コーチ:バーンアウトの予防とメンタルエネルギーの向上
XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

 コメント (1)
0/500
コメント (1)
0/500
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
高度な推論AIの競争は、2024年9月にOpenAIのo1モデルで始まり、2025年1月のDeepSeekのR1ローンチで勢いを増しました。
主要なAI開発企業は現在、より高速でコスト効率の高い推論AIモデルを開発するために競争しており、チェーン・オブ・ソートプロセスを通じて正確でよく考え抜かれた応答を提供し、回答前に正確性を確保しています。
TikTokの親会社であるバイトダンスは、技術論文で概要が示された新しい大規模言語モデル(LLM)であるSeed-Thinking-v1.5を発表し、STEMおよび一般的な領域での推論を強化することを目指しています。
このモデルはまだ利用可能ではなく、ライセンスが独自仕様、オープンソース、またはハイブリッドのいずれであるかは未公開です。ただし、論文にはリリース前に探る価値のある重要な洞察が含まれています。
Mixture-of-Experts(MoE)フレームワークの活用
MetaのLlama 4やMistralのMixtralに続き、Seed-Thinking-v1.5はMixture-of-Experts(MoE)アーキテクチャを採用しています。
このアプローチは、複数の専門モデルを1つに統合し、それぞれが異なる領域に焦点を当てることで効率を高めます。
Seed-Thinking-v1.5は、2000億のパラメータのうち200億のみを一度に使用し、パフォーマンスを最適化しています。
バイトダンスのGitHubで公開された論文は、モデルの構造化された推論と意図的な応答生成への焦点を強調しています。
これはDeepSeek R1を超え、GoogleのGemini 2.5 ProやOpenAIのo3-mini-highと第三者ベンチマークで競合し、ARC-AGIベンチマークではそれらを上回り、OpenAIの基準に従って経済的に価値のあるタスクで人間のパフォーマンスを超える、人工知能の進歩の重要な指標です。
コンパクトでありながら強力な代替として位置付けられたSeed-Thinking-v1.5は、革新的な強化学習、厳選されたトレーニングデータ、先進的なAIインフラストラクチャを通じて優れたベンチマーク結果を提供します。
ベンチマーク性能とコアの強み
Seed-Thinking-v1.5は困難なタスクで優れており、AIME 2024で86.7%、Codeforcesでpass@8で55.0%、GPQA科学ベンチマークで77.3%を記録し、OpenAIのo3-mini-highやGoogleのGemini 2.5 Proと推論指標でほぼ同等またはそれらを上回っています。
非推論タスクでは、DeepSeek R1に対して8.0%高い人間の好み勝率を達成し、論理や数学を超えた汎用性を示しています。
ベンチマークの飽和に対抗するため、バイトダンスは記憶に頼らないより厳しい数学ベンチマークであるBeyondAIMEを作成し、モデル性能をより良く評価します。このベンチマークは、Codeforcesセットと共に、将来の研究を支援するために公開されます。
トレーニングデータのアプローチ
Seed-Thinking-v1.5の開発ではデータ品質が重要でした。教師あり微調整のために、40万のサンプルが厳選されました:30万の検証可能なSTEM、論理、コーディングタスクと、10万のクリエイティブライティングのような検証不可能なタスクです。
強化学習のために、データは以下に分けられました:
- 検証可能な問題:エリート競技から慎重に選ばれた10万のSTEM質問と論理パズル、専門家によって検証されました。
- 検証不可能なタスク:オープンエンドのプロンプトに対する人間の好みデータセット、ペアワイズ報酬モデルで評価されました。
STEMデータの80%以上は高度な数学に焦点を当て、Sudokuや24ポイントパズルなどの論理タスクはモデル進捗に合わせてスケールされました。
強化学習の革新
Seed-Thinking-v1.5は、カスタムのアクター-クリティック(VAPO)およびポリシー勾配(DAPO)フレームワークを使用して、長いチェーン・オブ・ソートシナリオでの問題に対処し、強化学習を安定化します。
2つの報酬モデルがRL監督を強化します:
- Seed-Verifier:生成された回答と参照回答の数学的同等性を保証するルールベースのLLM。
- Seed-Thinking-Verifier:報酬操作に耐性のある一貫した評価のための推論ベースのジャッジ。
このデュアルシステムは、単純および複雑なタスクでの正確な評価をサポートします。
スケーラブルなインフラストラクチャ設計
バイトダンスのHybridFlowフレームワークは、Rayクラスタによって支えられ、GPUのアイドル時間を最小化する共同配置されたトレーニングと推論で効率的な大規模トレーニングをサポートします。
ストリーミングロールアウトシステム(SRS)は、モデル進化とランタイムを分離し、部分生成の非同期管理により反復を最大3倍高速化します。
追加の技術には以下が含まれます:
- メモリ効率のための混合精度(FP8)
- MoE最適化のためのエキスパート並列処理とカーネル自動チューニング
- 堅牢なチェックポインティングのためのByteCheckpoint
- 最適化された並列処理とメモリ設定のためのAutoTuner
人間中心の評価と応用
クリエイティブライティング、人文科学、一般会話での人間のテストでは、Seed-Thinking-v1.5がDeepSeek R1を上回り、現実世界での関連性を証明しました。
チームは、検証可能なタスクでのトレーニングが、厳格な数学的ワークフローに駆動されて、クリエイティブな領域への一般化を強化したと述べています。
技術チームと企業への影響
LLMライフサイクルを監督する技術リーダーにとって、Seed-Thinking-v1.5は高度な推論を企業AIシステムに統合するモデルを提供します。
検証可能なデータセットと多段階の強化学習によるモジュラートレーニングは、LLM開発を正確に制御しながらスケールするチームに適しています。
Seed-VerifierとSeed-Thinking-Verifierは、顧客向けまたは規制された環境で重要な信頼性の高い報酬モデリングを強化します。
タイトなスケジュールのチームにとって、VAPOと動的サンプリングは反復サイクルを短縮し、タスク固有の微調整を効率化します。
ハイブリッドインフラストラクチャ(SRSやFP8最適化を含む)は、トレーニングスループットとハードウェア効率を高め、クラウドおよびオンプレミスシステムに最適です。
モデルの適応型報酬フィードバックは、多様なデータパイプラインの管理における課題に対処し、ドメイン間で一貫性を確保します。
データエンジニアにとって、厳格なデータフィルタリングと専門家検証への焦点は、モデル性能向上における高品質データセットの価値を強調します。
今後の展望
バイトダンスのSeed LLM Systemsチームによって開発され、Yonghui Wuが率い、Haibin Linが公開代表を務めるSeed-Thinking-v1.5は、Doubao 1.5 Proなどの取り組みを基盤とし、共有されたRLHFとデータキュレーション技術を使用しています。
チームは、トレーニング効率と検証不可能なタスクの報酬モデリングに焦点を当て、強化学習を改良することを目指しています。BeyondAIMEのようなベンチマークの公開は、推論に焦点を当てたAI研究のさらなる進展を促進します。










 サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
サティヤ・ナデラ、新たなOpenAIとの契約を活用する準備ができている
水曜日に、ウォール・ストリートのアナリストがマイクロソフトのCEOであるサティヤ・ナデラ氏に直接尋ねました。改正されたOpenAIとの提携関係が同社の財務状況にどのような影響を与えるのかと。ナデラ氏はこの新しい協定を「皆にとっての勝利」と表現しました。「OpenAIとの提携については満足しています。私は常にどんな提携でもウィンウィンの関係を築くことに重点を置いています。そうすることで、長期的に良いパートナーシップを維持できるからです。」彼は、マイクロソフトが依然としてOpenAIの知的財産、
 OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
OpenAIは、公的基金、ロボット税、週4日勤務制を柱とするAI経済の構想を提示した
各国政府が超知能機械による経済的影響への対応に苦慮する中、OpenAIは「知能の時代」において富と労働がどのように再構築されるべきかを概説した一連の政策提言を発表した。その構想は、公的資産基金や社会安全網の拡充といった伝統的な左派的な仕組みと、根本的に資本主義的で市場主導型の経済枠組みとを融合させたものである。OpenAIの提案は本質的に「要望リスト」に相当し、人工知能が労働と経済を変革する中で、
 Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン
Meta、AmazonのAI用CPUを数百万台分調達する契約を締結
アマゾンは、再び自社開発のカスタムチップを活用し、Metaとの重要な提携関係を確立した。アマゾンは金曜日、Metaが拡大するAI需要に対応するため、数百万個のAWS Gravitonチップを導入することに合意したと発表した。なお、AWSグラビトンはGPU(グラフィックス処理ユニット)ではなく、ARMベースのCPU(汎用計算用に設計された中央処理装置)である点に留意が必要だ。大規模モデルのトレーニン

XIX.AIで、2026年最高のAIコードレビューツールを発見しましょう。厳選されたこのリストには、クリーンなコードの遵守を自動化し、レガシーリポジトリのファイルをリファクタリングするための、高評価で画期的なツールが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版を比較してください。今すぐAIの力を活用しましょう。
10 ツール
xix.ai

ディスレクシア支援のために厳選された、2026年最新の最高評価AI TTSアプリをご紹介します。専門家によるランキングでは、無料ツールと有料ツールを比較し、読解効率と学習効果を高める強力な機能を詳しく解説しています。生徒の可能性を引き出す、ぜひ試すべき画期的なソリューションをご覧ください。XIX.AIでその第一歩を踏み出しましょう。
10 ツール
xix.ai

XIX.AIで、2026年のおすすめ少年漫画向けAIジェネレーターをご紹介します。厳選されたトップクラスのリストには、迫力満点のアクションシーンや躍動感あふれるエフェクトを作成できる強力なツールが揃っています。実際のテスト結果をもとに、無料版と有料版の比較も可能です。あなたの創造力を解き放ち、今日から壮大な漫画の制作を始めましょう!
15 ツール
xix.ai

2026年最新・最高のAI経費管理ツール:レシートをスキャンし、法人経費を自動分類する高評価ツールをご紹介。手間いらずの経費管理、正確な財務追跡、コンプライアンス対応の効率化を実現する、画期的なソリューションをご覧ください。無料版と有料版の比較表は厳選され、毎週更新されるため、最適なツール選びにお役立ていただけます。XIX.AIの専門家が厳選したツールで、AIの力を最大限に活用しましょう。
10 ツール
xix.ai

XIX.AIで、2026年最新の評価の高いAI採用ツールをチェックしましょう。厳選されたリストには、履歴書のスクリーニングや候補者の面接スケジュール管理を自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングを参考に、無料版と有料版の比較が可能です。最適な採用アシスタントを見つけて、今すぐ採用業務を効率化しましょう!
10 ツール
xix.ai

XIX.AIで、2026年最高のAIパーソナルウェルネス&集中力向上ツールをご紹介。厳選されたランキングでは、バーンアウトの解消やメンタルエネルギーの向上に役立つ、高評価で画期的なツールを取り上げています。実際のユーザーの声をもとに、無料版と有料版の比較も可能です。今すぐ、最高の生産性とウェルビーイングへの道を開きましょう。
10 ツール
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













