
















 Hogar
Hogar
ByteDance Presenta el Modelo de IA Seed-Thinking-v1.5 para Mejorar las Capacidades de Razonamiento
La carrera por una IA avanzada en razonamiento comenzó con el modelo o1 de OpenAI en septiembre de 2024, ganando impulso con el lanzamiento de R1 de DeepSeek en enero de 2025.
Los principales desarrolladores de IA están ahora compitiendo por crear modelos de IA de razonamiento más rápidos y rentables que ofrezcan respuestas precisas y bien pensadas a través de procesos de cadena de pensamiento, garantizando precisión antes de responder.
ByteDance, la empresa matriz de TikTok, ha entrado en la competencia con Seed-Thinking-v1.5, un nuevo modelo de lenguaje grande (LLM) descrito en un documento técnico, destinado a mejorar el razonamiento en STEM y dominios generales.
El modelo aún no está disponible, y su licencia—ya sea propietario, de código abierto o híbrido—permanece sin revelarse. Sin embargo, el documento ofrece perspectivas clave que vale la pena explorar antes de su lanzamiento.
Aprovechando el Marco de Mezcla de Expertos (MoE)
Siguiendo a Llama 4 de Meta y Mixtral de Mistral, Seed-Thinking-v1.5 adopta la arquitectura de Mezcla de Expertos (MoE).
Este enfoque mejora la eficiencia al integrar múltiples modelos especializados en uno solo, cada uno centrado en dominios distintos.
Seed-Thinking-v1.5 utiliza solo 20 mil millones de sus 200 mil millones de parámetros a la vez, optimizando el rendimiento.
El documento publicado por ByteDance en GitHub destaca el enfoque del modelo en el razonamiento estructurado y la generación de respuestas deliberadas.
Supera a DeepSeek R1 y compite con Gemini 2.5 Pro de Google y o3-mini-high de OpenAI en evaluaciones de terceros, incluso superándolos en el punto de referencia ARC-AGI, una medida clave del progreso hacia la inteligencia artificial general, superando el rendimiento humano en tareas económicamente valiosas, según los estándares de OpenAI.
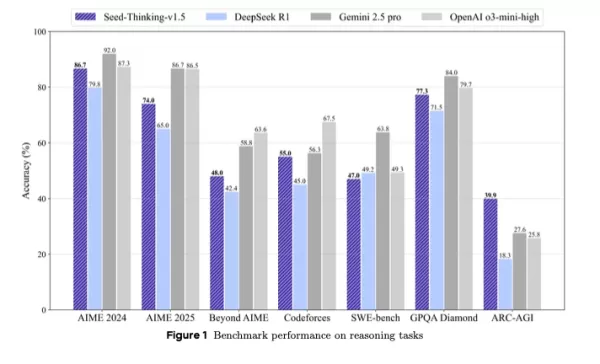
Posicionado como una alternativa compacta pero poderosa a modelos más grandes, Seed-Thinking-v1.5 ofrece resultados sólidos en puntos de referencia mediante aprendizaje por refuerzo innovador, datos de entrenamiento curados e infraestructura avanzada de IA.
Rendimiento en Puntos de Referencia y Fortalezas Principales
Seed-Thinking-v1.5 destaca en tareas difíciles, obteniendo un 86.7% en AIME 2024, un 55.0% de aprobación@8 en Codeforces y un 77.3% en el punto de referencia científico GPQA, igualando o superando a modelos como o3-mini-high de OpenAI y Gemini 2.5 Pro de Google en métricas de razonamiento.
En tareas no relacionadas con el razonamiento, logró una tasa de preferencia humana un 8.0% más alta que DeepSeek R1, mostrando versatilidad más allá de la lógica y las matemáticas.
Para contrarrestar la saturación de puntos de referencia, ByteDance creó BeyondAIME, un punto de referencia matemático más difícil para resistir la memorización y evaluar mejor el rendimiento del modelo. Este, junto con el conjunto de Codeforces, será publicado para ayudar en futuras investigaciones.
Enfoque en Datos de Entrenamiento
La calidad de los datos fue crucial en el desarrollo de Seed-Thinking-v1.5. Para el ajuste fino supervisado, se curaron 400,000 muestras: 300,000 tareas verificables de STEM, lógica y codificación, y 100,000 tareas no verificables como escritura creativa.
Para el aprendizaje por refuerzo, los datos se dividieron en:
- Problemas verificables: 100,000 preguntas de STEM y rompecabezas lógicos seleccionados cuidadosamente de competiciones de élite, validados por expertos.
- Tareas no verificables: Conjuntos de datos de preferencia humana para prompts abiertos, evaluados mediante modelos de recompensa por pares.
Más del 80% de los datos de STEM se centraron en matemáticas avanzadas, con tareas lógicas como Sudoku y rompecabezas de 24 puntos escalados para coincidir con el progreso del modelo.
Innovaciones en Aprendizaje por Refuerzo
Seed-Thinking-v1.5 utiliza marcos personalizados de actor-crítico (VAPO) y gradiente de política (DAPO) para estabilizar el aprendizaje por refuerzo, abordando problemas en escenarios largos de cadena de pensamiento.
Dos modelos de recompensa mejoran la supervisión de RL:
- Seed-Verifier: Un LLM basado en reglas que asegura la equivalencia matemática entre las respuestas generadas y las de referencia.
- Seed-Thinking-Verifier: Un juez basado en razonamiento para una evaluación consistente, resistente a la manipulación de recompensas.
Este sistema dual apoya una evaluación precisa en tareas simples y complejas.
Diseño de Infraestructura Escalable
El marco HybridFlow de ByteDance, impulsado por clústeres Ray, soporta un entrenamiento eficiente a gran escala con entrenamiento e inferencia co-ubicados para minimizar el tiempo de inactividad de la GPU.
El Sistema de Despliegue en Streaming (SRS) separa la evolución del modelo del tiempo de ejecución, acelerando las iteraciones hasta tres veces mediante la gestión asíncrona de generaciones parciales.
Técnicas adicionales incluyen:
- Precisión mixta (FP8) para eficiencia de memoria
- Paralelismo de expertos y autoajuste de kernel para optimización de MoE
- ByteCheckpoint para puntos de control robustos
- AutoTuner para configuraciones optimizadas de paralelismo y memoria
Evaluación Centrada en Humanos y Aplicaciones
Las pruebas humanas en escritura creativa, humanidades y conversación general mostraron que Seed-Thinking-v1.5 supera a DeepSeek R1, demostrando su relevancia en el mundo real.
El equipo señala que el entrenamiento en tareas verificables mejoró la generalización a dominios creativos, impulsado por flujos de trabajo matemáticos rigurosos.
Implicaciones para Equipos Técnicos y Empresas
Para líderes técnicos que supervisan los ciclos de vida de LLM, Seed-Thinking-v1.5 ofrece un modelo para integrar razonamiento avanzado en sistemas de IA empresariales.
Su entrenamiento modular, con conjuntos de datos verificables y aprendizaje por refuerzo multifase, es adecuado para equipos que escalan el desarrollo de LLM con control preciso.
Seed-Verifier y Seed-Thinking-Verifier mejoran el modelado de recompensas confiable, vital para entornos orientados al cliente o regulados.
Para equipos con plazos ajustados, VAPO y el muestreo dinámico reducen los ciclos de iteración, simplificando el ajuste fino específico de tareas.
La infraestructura híbrida, incluyendo SRS y optimización FP8, aumenta el rendimiento del entrenamiento y la eficiencia del hardware, ideal para sistemas en la nube y locales.
El feedback de recompensa adaptativo del modelo aborda los desafíos en la gestión de tuberías de datos diversas, asegurando consistencia entre dominios.
Para ingenieros de datos, el enfoque en filtrado riguroso de datos y verificación de expertos subraya el valor de los conjuntos de datos de alta calidad para mejorar el rendimiento del modelo.
Perspectivas Futuras
Desarrollado por el equipo de Seed LLM Systems de ByteDance, liderado por Yonghui Wu y representado públicamente por Haibin Lin, Seed-Thinking-v1.5 se basa en esfuerzos como Doubao 1.5 Pro, utilizando técnicas compartidas de RLHF y curación de datos.
El equipo busca refinar el aprendizaje por refuerzo, enfocándose en la eficiencia del entrenamiento y el modelado de recompensas para tareas no verificables. La publicación de puntos de referencia como BeyondAIME impulsará un mayor progreso en la investigación de IA centrada en el razonamiento.
Artículo relacionado
 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien
Recomendaciones de temas especiales relacionados
Texto a voz
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien
Recomendaciones de temas especiales relacionados
Texto a voz
 Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Las mejores aplicaciones de síntesis de voz con IA para la dislexia: apoyo al aprendizaje y mejora de la eficiencia en la lectura de los estudiantes
Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
 10 herramientas
10 herramientas
 xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
xix.ai
Creación de cómics
Los mejores generadores de IA para manga shonen: crea secuencias de acción trepidantes y efectos de energía
Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai
Negocio
Los mejores gestores de gastos con IA: escanea recibos y clasifica automáticamente los gastos de la empresa
Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai
Negocio
Las mejores herramientas de selección de personal basadas en IA: filtrar currículos y automatizar la programación de entrevistas con los candidatos
Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai
Productividad
Entrenadores personales de bienestar y concentración basados en IA: controla el agotamiento y aumenta tus niveles de energía mental
Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai
chatbot
Los mejores chatbots románticos con IA: crea relaciones duraderas con personalidades coherentes
Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

 comentario (1)
0/500
comentario (1)
0/500
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
La carrera por una IA avanzada en razonamiento comenzó con el modelo o1 de OpenAI en septiembre de 2024, ganando impulso con el lanzamiento de R1 de DeepSeek en enero de 2025.
Los principales desarrolladores de IA están ahora compitiendo por crear modelos de IA de razonamiento más rápidos y rentables que ofrezcan respuestas precisas y bien pensadas a través de procesos de cadena de pensamiento, garantizando precisión antes de responder.
ByteDance, la empresa matriz de TikTok, ha entrado en la competencia con Seed-Thinking-v1.5, un nuevo modelo de lenguaje grande (LLM) descrito en un documento técnico, destinado a mejorar el razonamiento en STEM y dominios generales.
El modelo aún no está disponible, y su licencia—ya sea propietario, de código abierto o híbrido—permanece sin revelarse. Sin embargo, el documento ofrece perspectivas clave que vale la pena explorar antes de su lanzamiento.
Aprovechando el Marco de Mezcla de Expertos (MoE)
Siguiendo a Llama 4 de Meta y Mixtral de Mistral, Seed-Thinking-v1.5 adopta la arquitectura de Mezcla de Expertos (MoE).
Este enfoque mejora la eficiencia al integrar múltiples modelos especializados en uno solo, cada uno centrado en dominios distintos.
Seed-Thinking-v1.5 utiliza solo 20 mil millones de sus 200 mil millones de parámetros a la vez, optimizando el rendimiento.
El documento publicado por ByteDance en GitHub destaca el enfoque del modelo en el razonamiento estructurado y la generación de respuestas deliberadas.
Supera a DeepSeek R1 y compite con Gemini 2.5 Pro de Google y o3-mini-high de OpenAI en evaluaciones de terceros, incluso superándolos en el punto de referencia ARC-AGI, una medida clave del progreso hacia la inteligencia artificial general, superando el rendimiento humano en tareas económicamente valiosas, según los estándares de OpenAI.
Posicionado como una alternativa compacta pero poderosa a modelos más grandes, Seed-Thinking-v1.5 ofrece resultados sólidos en puntos de referencia mediante aprendizaje por refuerzo innovador, datos de entrenamiento curados e infraestructura avanzada de IA.
Rendimiento en Puntos de Referencia y Fortalezas Principales
Seed-Thinking-v1.5 destaca en tareas difíciles, obteniendo un 86.7% en AIME 2024, un 55.0% de aprobación@8 en Codeforces y un 77.3% en el punto de referencia científico GPQA, igualando o superando a modelos como o3-mini-high de OpenAI y Gemini 2.5 Pro de Google en métricas de razonamiento.
En tareas no relacionadas con el razonamiento, logró una tasa de preferencia humana un 8.0% más alta que DeepSeek R1, mostrando versatilidad más allá de la lógica y las matemáticas.
Para contrarrestar la saturación de puntos de referencia, ByteDance creó BeyondAIME, un punto de referencia matemático más difícil para resistir la memorización y evaluar mejor el rendimiento del modelo. Este, junto con el conjunto de Codeforces, será publicado para ayudar en futuras investigaciones.
Enfoque en Datos de Entrenamiento
La calidad de los datos fue crucial en el desarrollo de Seed-Thinking-v1.5. Para el ajuste fino supervisado, se curaron 400,000 muestras: 300,000 tareas verificables de STEM, lógica y codificación, y 100,000 tareas no verificables como escritura creativa.
Para el aprendizaje por refuerzo, los datos se dividieron en:
- Problemas verificables: 100,000 preguntas de STEM y rompecabezas lógicos seleccionados cuidadosamente de competiciones de élite, validados por expertos.
- Tareas no verificables: Conjuntos de datos de preferencia humana para prompts abiertos, evaluados mediante modelos de recompensa por pares.
Más del 80% de los datos de STEM se centraron en matemáticas avanzadas, con tareas lógicas como Sudoku y rompecabezas de 24 puntos escalados para coincidir con el progreso del modelo.
Innovaciones en Aprendizaje por Refuerzo
Seed-Thinking-v1.5 utiliza marcos personalizados de actor-crítico (VAPO) y gradiente de política (DAPO) para estabilizar el aprendizaje por refuerzo, abordando problemas en escenarios largos de cadena de pensamiento.
Dos modelos de recompensa mejoran la supervisión de RL:
- Seed-Verifier: Un LLM basado en reglas que asegura la equivalencia matemática entre las respuestas generadas y las de referencia.
- Seed-Thinking-Verifier: Un juez basado en razonamiento para una evaluación consistente, resistente a la manipulación de recompensas.
Este sistema dual apoya una evaluación precisa en tareas simples y complejas.
Diseño de Infraestructura Escalable
El marco HybridFlow de ByteDance, impulsado por clústeres Ray, soporta un entrenamiento eficiente a gran escala con entrenamiento e inferencia co-ubicados para minimizar el tiempo de inactividad de la GPU.
El Sistema de Despliegue en Streaming (SRS) separa la evolución del modelo del tiempo de ejecución, acelerando las iteraciones hasta tres veces mediante la gestión asíncrona de generaciones parciales.
Técnicas adicionales incluyen:
- Precisión mixta (FP8) para eficiencia de memoria
- Paralelismo de expertos y autoajuste de kernel para optimización de MoE
- ByteCheckpoint para puntos de control robustos
- AutoTuner para configuraciones optimizadas de paralelismo y memoria
Evaluación Centrada en Humanos y Aplicaciones
Las pruebas humanas en escritura creativa, humanidades y conversación general mostraron que Seed-Thinking-v1.5 supera a DeepSeek R1, demostrando su relevancia en el mundo real.
El equipo señala que el entrenamiento en tareas verificables mejoró la generalización a dominios creativos, impulsado por flujos de trabajo matemáticos rigurosos.
Implicaciones para Equipos Técnicos y Empresas
Para líderes técnicos que supervisan los ciclos de vida de LLM, Seed-Thinking-v1.5 ofrece un modelo para integrar razonamiento avanzado en sistemas de IA empresariales.
Su entrenamiento modular, con conjuntos de datos verificables y aprendizaje por refuerzo multifase, es adecuado para equipos que escalan el desarrollo de LLM con control preciso.
Seed-Verifier y Seed-Thinking-Verifier mejoran el modelado de recompensas confiable, vital para entornos orientados al cliente o regulados.
Para equipos con plazos ajustados, VAPO y el muestreo dinámico reducen los ciclos de iteración, simplificando el ajuste fino específico de tareas.
La infraestructura híbrida, incluyendo SRS y optimización FP8, aumenta el rendimiento del entrenamiento y la eficiencia del hardware, ideal para sistemas en la nube y locales.
El feedback de recompensa adaptativo del modelo aborda los desafíos en la gestión de tuberías de datos diversas, asegurando consistencia entre dominios.
Para ingenieros de datos, el enfoque en filtrado riguroso de datos y verificación de expertos subraya el valor de los conjuntos de datos de alta calidad para mejorar el rendimiento del modelo.
Perspectivas Futuras
Desarrollado por el equipo de Seed LLM Systems de ByteDance, liderado por Yonghui Wu y representado públicamente por Haibin Lin, Seed-Thinking-v1.5 se basa en esfuerzos como Doubao 1.5 Pro, utilizando técnicas compartidas de RLHF y curación de datos.
El equipo busca refinar el aprendizaje por refuerzo, enfocándose en la eficiencia del entrenamiento y el modelado de recompensas para tareas no verificables. La publicación de puntos de referencia como BeyondAIME impulsará un mayor progreso en la investigación de IA centrada en el razonamiento.










 Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
Satya Nadella está listo para aprovechar el nuevo acuerdo con OpenAI
El miércoles, un analista de Wall Street preguntó directamente al CEO de Microsoft, Satya Nadella, cómo la revisada asociación con OpenAI afectaría las finanzas de la empresa.Nadella describió el nuevo acuerdo como una victoria para todos. “Estamos
 OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
OpenAI esboza la economía de la IA con fondos de riqueza pública, impuestos sobre los robots y la semana laboral de cuatro días
Mientras los gobiernos se esfuerzan por gestionar el impacto económico de las máquinas superinteligentes, OpenAI ha publicado una serie de propuestas políticas en las que se esboza cómo podrían reconf
 Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien
Meta firma un acuerdo para adquirir millones de CPU de IA de Amazon
Amazon ha cerrado una importante alianza con Meta, apostando una vez más por sus propios chips de diseño propio. Meta ha acordado implementar millones de chips AWS Graviton para satisfacer sus crecien

Descubre las mejores aplicaciones de TTS con IA de 2026, seleccionadas específicamente para ayudar a las personas con dislexia. Nuestra clasificación, elaborada por expertos, compara herramientas gratuitas y de pago, y destaca sus potentes funciones para mejorar la eficiencia en la lectura y el aprendizaje. Explora soluciones innovadoras e imprescindibles para liberar el potencial de los estudiantes. Empieza tu viaje en XIX.AI.
10 herramientas
xix.ai

Descubre los mejores generadores de IA para manga shonen de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada y con las mejores valoraciones, incluye potentes herramientas para crear secuencias de acción trepidantes y efectos energéticos dinámicos. Compara las opciones gratuitas con las de pago mediante pruebas reales. ¡Libera tu potencial creativo y empieza a crear manga épico hoy mismo!
15 herramientas
xix.ai

Los mejores gestores de gastos con IA de 2026: las herramientas mejor valoradas para escanear recibos y clasificar automáticamente los gastos de la empresa. Descubre soluciones potentes y revolucionarias para una gestión de gastos sin esfuerzo, un seguimiento financiero preciso y un cumplimiento normativo optimizado. Nuestra comparativa, seleccionada y actualizada semanalmente, entre opciones gratuitas y de pago te ayuda a encontrar la que mejor se adapta a tus necesidades. Aprovecha al máximo las ventajas de la IA con las recomendaciones de los expertos de XIX.AI.
10 herramientas
xix.ai

Descubre las mejores herramientas de selección de personal basadas en IA de 2026 en XIX.AI. Nuestra lista, cuidadosamente seleccionada, incluye soluciones potentes y revolucionarias para la selección de currículos y la automatización de la programación de entrevistas con los candidatos. Compara las opciones gratuitas con las de pago gracias a pruebas reales y a clasificaciones que se actualizan semanalmente. ¡Encuentra tu asistente de selección de personal ideal y optimiza tu proceso de selección hoy mismo!
10 herramientas
xix.ai

Descubre los mejores entrenadores personales de bienestar y concentración basados en IA de 2026 en XIX.AI. Nuestras clasificaciones, cuidadosamente seleccionadas, incluyen herramientas revolucionarias y de primera categoría para gestionar el agotamiento y potenciar la energía mental. Compara las opciones gratuitas con las de pago gracias a información basada en casos reales. Descubre hoy mismo el camino hacia la máxima productividad y el bienestar.
10 herramientas
xix.ai

Descubre los mejores chatbots románticos con IA de 2026 para establecer relaciones auténticas y duraderas. Nuestra lista seleccionada incluye personalidades sólidas y coherentes, comparativas entre versiones gratuitas y de pago, y pruebas en situaciones reales. Encuentra a tu compañero ideal y empieza a construir tu relación hoy mismo en XIX.AI.
10 herramientas
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













