
















 首頁
首頁字節跳動推出Seed-Thinking-v1.5 AI模型以提升推理能力
先進推理AI的競賽始於2024年9月OpenAI的o1模型,隨著2025年1月DeepSeek的R1推出而加速。
主要AI開發商現正競相打造更快、更具成本效益的推理AI模型,通過思維鏈過程提供精確、深思熟慮的回應,確保回答前的準確性。
字節跳動,TikTok的母公司,推出Seed-Thinking-v1.5,一款在技術論文中概述的新大型語言模型(LLM),旨在增強STEM及一般領域的推理能力。
該模型尚未公開,且其授權方式—無論是專有、開源或混合—仍未透露。然而,該論文提供了值得在發布前探索的關鍵見解。
利用專家混合(MoE)框架
繼Meta的Llama 4和Mistral的Mixtral之後,Seed-Thinking-v1.5採用了專家混合(MoE)架構。
這種方法通過將多個專精模型整合為一體來提升效率,每個模型專注於不同領域。
Seed-Thinking-v1.5僅使用其2000億參數中的200億,優化性能。
字節跳動在GitHub發布的論文強調該模型專注於結構化推理和審慎回應生成。
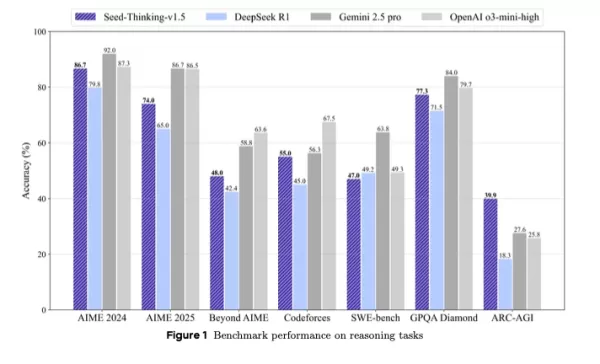
它超越DeepSeek R1,並在第三方基準測試中與Google的Gemini 2.5 Pro和OpenAI的o3-mini-high競爭,甚至在ARC-AGI基準測試中表現優於它們,該基準是衡量人工通用智能進展的關鍵指標,根據OpenAI的標準,超越了人類在經濟上有價值的任務中的表現。
作為比大型模型更緊湊但強大的替代方案,Seed-Thinking-v1.5通過創新的強化學習、精選訓練數據和先進的AI基礎設施,提供了出色的基準測試結果。
基準測試表現與核心優勢
Seed-Thinking-v1.5在艱難任務中表現出色,在AIME 2024獲得86.7%的分數,在Codeforces上獲得55.0%的pass@8,在GPQA科學基準測試中獲得77.3%,與OpenAI的o3-mini-high和Google的Gemini 2.5 Pro在推理指標上接近或超越。
在非推理任務中,它的人類偏好勝率比DeepSeek R1高出8.0%,顯示出超越邏輯和數學的靈活性。
為應對基準測試飽和問題,字節跳動創建了BeyondAIME,一個更嚴格的數學基準測試,以抵制記憶並更好地評估模型表現。該基準與Codeforces集合將公開發布,以促進未來研究。
訓練數據策略
數據質量在開發Seed-Thinking-v1.5中至關重要。為進行監督微調,精選了40萬個樣本:30萬個可驗證的STEM、邏輯和編碼任務,以及10萬個不可驗證的任務,如創意寫作。
對於強化學習,數據分為:
- 可驗證問題:從頂尖比賽中精心挑選的10萬個STEM問題和邏輯謎題,由專家驗證。
- 不可驗證任務:針對開放式提示的人類偏好數據集,通過成對獎勵模型評估。
超過80%的STEM數據專注於高級數學,邏輯任務如數獨和24點謎題根據模型進展進行縮放。
強化學習創新
Seed-Thinking-v1.5使用自定義的actor-critic(VAPO)和策略梯度(DAPO)框架來穩定強化學習,解決長思維鏈場景中的問題。
兩個獎勵模型增強了強化學習監督:
- Seed-Verifier:基於規則的LLM,確保生成答案與參考答案的數學等價性。
- Seed-Thinking-Verifier:基於推理的評估器,確保一致性評估,抵禦獎勵操縱。
此雙重系統支持簡單和複雜任務的精確評估。
可擴展基礎設施設計
字節跳動的HybridFlow框架,由Ray集群提供支持,支持高效的大規模訓練,通過訓練與推理共置減少GPU閒置時間。
流式推出系統(SRS)將模型進化與運行時分離,通過異步管理部分生成,將迭代速度提升至三倍。
其他技術包括:
- 混合精度(FP8)以提升記憶體效率
- 專家並行和內核自動調整以優化MoE
- ByteCheckpoint以實現穩健的檢查點
- AutoTuner以優化並行和記憶體設置
以人為本的評估與應用
在創意寫作、人文學科和一般對話中的人類測試顯示,Seed-Thinking-v1.5超越DeepSeek R1,證明其現實世界的相關性。
團隊指出,在可驗證任務上的訓練增強了對創意領域的泛化能力,這得益於嚴格的數學工作流程。
對技術團隊和企業的影響
對於監督LLM生命週期的技術領導者,Seed-Thinking-v1.5提供了一個將高級推理整合到企業AI系統中的模型。
其模組化訓練,包含可驗證數據集和多階段強化學習,適合需要精確控制的LLM開發團隊。
Seed-Verifier和Seed-Thinking-Verifier增強了可信的獎勵建模,這對面向客戶或受監管的環境至關重要。
對於時間緊迫的團隊,VAPO和動態採樣縮短了迭代週期,簡化了特定任務的微調。
混合基礎設施,包括SRS和FP8優化,提升了訓練吞吐量和硬體效率,適合雲端和本地系統。
該模型的自適應獎勵反饋解決了管理多樣化數據管道的挑戰,確保跨領域的一致性。
對於數據工程師,嚴格的數據過濾和專家驗證的重視凸顯了高質量數據集在提升模型性能方面的價值。
未來展望
由字節跳動的Seed LLM Systems團隊開發,由吳永輝領導並由林海濱公開代表,Seed-Thinking-v1.5在Doubao 1.5 Pro的基礎上,採用共享的RLHF和數據精選技術。
團隊旨在精進強化學習,專注於訓練效率和不可驗證任務的獎勵建模。發布BeyondAIME等基準將推動專注於推理的AI研究的進一步進展。
相關文章
 Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
相關專題推薦
動畫創作
Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
相關專題推薦
動畫創作
 專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
專為東華設計的AI動漫生成器:可用於建立網路小說角色及漫畫頭像
探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
 10 個工具
10 個工具
 xix.ai
漫畫創作
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
xix.ai
漫畫創作
漫畫頂尖 AI 自動上色工具:零一致性錯誤地套用平面色彩
立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai
寫作
頂尖 AI 角色設定生成工具:創造一致的角色動機與致命弱點
探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai
商業
頂尖 AI 定價優化軟體:追蹤競爭對手並自動調整商店價格
立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai
代碼
最佳 AI 程式碼審查工具:自動化確保程式碼整潔度,並重構舊版儲存庫檔案
立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai
文字轉語音
專為閱讀障礙設計的頂尖 AI 語音合成應用程式:協助學生提升學習與閱讀效率
探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

 評論 (1)
0/500
評論 (1)
0/500
![ChristopherDavis]()
Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.
先進推理AI的競賽始於2024年9月OpenAI的o1模型,隨著2025年1月DeepSeek的R1推出而加速。
主要AI開發商現正競相打造更快、更具成本效益的推理AI模型,通過思維鏈過程提供精確、深思熟慮的回應,確保回答前的準確性。
字節跳動,TikTok的母公司,推出Seed-Thinking-v1.5,一款在技術論文中概述的新大型語言模型(LLM),旨在增強STEM及一般領域的推理能力。
該模型尚未公開,且其授權方式—無論是專有、開源或混合—仍未透露。然而,該論文提供了值得在發布前探索的關鍵見解。
利用專家混合(MoE)框架
繼Meta的Llama 4和Mistral的Mixtral之後,Seed-Thinking-v1.5採用了專家混合(MoE)架構。
這種方法通過將多個專精模型整合為一體來提升效率,每個模型專注於不同領域。
Seed-Thinking-v1.5僅使用其2000億參數中的200億,優化性能。
字節跳動在GitHub發布的論文強調該模型專注於結構化推理和審慎回應生成。
它超越DeepSeek R1,並在第三方基準測試中與Google的Gemini 2.5 Pro和OpenAI的o3-mini-high競爭,甚至在ARC-AGI基準測試中表現優於它們,該基準是衡量人工通用智能進展的關鍵指標,根據OpenAI的標準,超越了人類在經濟上有價值的任務中的表現。
作為比大型模型更緊湊但強大的替代方案,Seed-Thinking-v1.5通過創新的強化學習、精選訓練數據和先進的AI基礎設施,提供了出色的基準測試結果。
基準測試表現與核心優勢
Seed-Thinking-v1.5在艱難任務中表現出色,在AIME 2024獲得86.7%的分數,在Codeforces上獲得55.0%的pass@8,在GPQA科學基準測試中獲得77.3%,與OpenAI的o3-mini-high和Google的Gemini 2.5 Pro在推理指標上接近或超越。
在非推理任務中,它的人類偏好勝率比DeepSeek R1高出8.0%,顯示出超越邏輯和數學的靈活性。
為應對基準測試飽和問題,字節跳動創建了BeyondAIME,一個更嚴格的數學基準測試,以抵制記憶並更好地評估模型表現。該基準與Codeforces集合將公開發布,以促進未來研究。
訓練數據策略
數據質量在開發Seed-Thinking-v1.5中至關重要。為進行監督微調,精選了40萬個樣本:30萬個可驗證的STEM、邏輯和編碼任務,以及10萬個不可驗證的任務,如創意寫作。
對於強化學習,數據分為:
- 可驗證問題:從頂尖比賽中精心挑選的10萬個STEM問題和邏輯謎題,由專家驗證。
- 不可驗證任務:針對開放式提示的人類偏好數據集,通過成對獎勵模型評估。
超過80%的STEM數據專注於高級數學,邏輯任務如數獨和24點謎題根據模型進展進行縮放。
強化學習創新
Seed-Thinking-v1.5使用自定義的actor-critic(VAPO)和策略梯度(DAPO)框架來穩定強化學習,解決長思維鏈場景中的問題。
兩個獎勵模型增強了強化學習監督:
- Seed-Verifier:基於規則的LLM,確保生成答案與參考答案的數學等價性。
- Seed-Thinking-Verifier:基於推理的評估器,確保一致性評估,抵禦獎勵操縱。
此雙重系統支持簡單和複雜任務的精確評估。
可擴展基礎設施設計
字節跳動的HybridFlow框架,由Ray集群提供支持,支持高效的大規模訓練,通過訓練與推理共置減少GPU閒置時間。
流式推出系統(SRS)將模型進化與運行時分離,通過異步管理部分生成,將迭代速度提升至三倍。
其他技術包括:
- 混合精度(FP8)以提升記憶體效率
- 專家並行和內核自動調整以優化MoE
- ByteCheckpoint以實現穩健的檢查點
- AutoTuner以優化並行和記憶體設置
以人為本的評估與應用
在創意寫作、人文學科和一般對話中的人類測試顯示,Seed-Thinking-v1.5超越DeepSeek R1,證明其現實世界的相關性。
團隊指出,在可驗證任務上的訓練增強了對創意領域的泛化能力,這得益於嚴格的數學工作流程。
對技術團隊和企業的影響
對於監督LLM生命週期的技術領導者,Seed-Thinking-v1.5提供了一個將高級推理整合到企業AI系統中的模型。
其模組化訓練,包含可驗證數據集和多階段強化學習,適合需要精確控制的LLM開發團隊。
Seed-Verifier和Seed-Thinking-Verifier增強了可信的獎勵建模,這對面向客戶或受監管的環境至關重要。
對於時間緊迫的團隊,VAPO和動態採樣縮短了迭代週期,簡化了特定任務的微調。
混合基礎設施,包括SRS和FP8優化,提升了訓練吞吐量和硬體效率,適合雲端和本地系統。
該模型的自適應獎勵反饋解決了管理多樣化數據管道的挑戰,確保跨領域的一致性。
對於數據工程師,嚴格的數據過濾和專家驗證的重視凸顯了高質量數據集在提升模型性能方面的價值。
未來展望
由字節跳動的Seed LLM Systems團隊開發,由吳永輝領導並由林海濱公開代表,Seed-Thinking-v1.5在Doubao 1.5 Pro的基礎上,採用共享的RLHF和數據精選技術。
團隊旨在精進強化學習,專注於訓練效率和不可驗證任務的獎勵建模。發布BeyondAIME等基準將推動專注於推理的AI研究的進一步進展。










 Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
Google I/O 2026 發表了與 Gmail 收件匣的語音互動功能
Google 持續將人工智慧整合至您的收件匣中。在週二舉行的 IO 2026 開發者大會上,該公司透過對話式人工智慧擴充了 Gmail 的「AI 收件匣」功能,讓使用者能針對收件匣內容提出問題,而非僅依賴搜尋關鍵字。據 Google 表示,這項由 Gemini AI 驅動的工具名為「Gmail Live」,能協助使用者快速找出埋藏在收件匣中的資訊。圖片來源:Google舉例來說,您可能需要查詢即將
 薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
薩提亞·納德拉準備利用與OpenAI的新合作關係
週三,一位華爾街分析師直接詢問了微軟執行長薩蒂亞·納德拉,修訂後的OpenAI合作關係將如何影響公司的財務狀況。 納德拉將這一新協議描述為對各方都有利的結果。“我們對與OpenAI的合作感到滿意。我始終非常重視任何合作關係,並確保它能夠實現雙贏。只有這樣,雙方才能保持良好的合作伙伴關係。” 他強調,微軟仍然可以使用OpenAI的智慧財產權,包括其模型和智慧體產品,但不再需要為此向OpenAI支付費用。 談到在2032年之前可以免費使用OpenAI最先進的人工智慧技術,納德拉表示:“
 OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程
OpenAI 勾勒出以公共財富基金、機器人稅及每週四天工作制為核心的人工智慧經濟藍圖
當各國政府正竭力應對超智能機器帶來的經濟衝擊之際,OpenAI 發布了一系列政策提案,闡述在「智能時代」中財富與工作可能如何重塑。這些構想將傳統的左翼機制——例如公共財富基金與擴大的社會安全網——與根本上資本主義、市場導向的經濟框架相融合。OpenAI 的提案本質上是一份願望清單,這份公開聲明有助於民選官員、投資者及公眾理解這家市值 8,520 億美元的公司,如何看待人工智慧在重塑勞動與經濟的過程

探索2026年最適合製作中文動畫的人工智慧工具。我們精心挑選的頂級列表中包含了各種強大的工具,能夠幫助你建立出令人驚歎的網路小說角色和漫畫頭像。透過實際測試來對比免費選項和付費選項,找到最適合你的創作工具,今天就在XIX.AI上將你的故事變為現實吧。
10 個工具
xix.ai

立即前往 XIX.AI,探索 2026 年最優秀的漫畫 AI 自動上色工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的解決方案,這些工具能以零一致性錯誤的方式套用平面色彩,大幅提升您的工作效率。透過免費與付費版本的比較、實際測試結果,以及每週更新的排行榜,找到最適合您的工具。立即解鎖您的 AI 優勢。
10 個工具
xix.ai

探索 2026 年最優秀的 AI 角色設定生成工具,打造立體鮮明的角色。XIX.AI 精心整理的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具能生成一貫的動機與致命缺陷。透過實際測試,比較免費與付費選項的差異。立即釋放您的說故事潛能。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 定價優化軟體。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,這些工具不僅能追蹤競爭對手,還能自動調整您的商店價格,以實現利潤最大化。透過實際測試,比較免費與付費方案的差異。立即掌握您的定價優勢。
10 個工具
xix.ai

立即在 XIX.AI 探索 2026 年最佳 AI 程式碼審查工具。我們精心挑選的清單收錄了備受好評、能徹底改變遊戲規則的工具,可自動確保程式碼符合規範,並重構舊版儲存庫檔案。透過實際測試與每週更新的排行榜,比較免費與付費選項。立即掌握您的 AI 競爭優勢。
10 個工具
xix.ai

探索 2026 年最新精選、專為閱讀障礙者設計的頂級 AI 語音合成(TTS)應用程式。我們的專家評比將免費與付費工具進行對照,重點介紹能提升閱讀效率與學習成效的強大功能。發掘這些必試且能帶來革命性改變的解決方案,釋放學生的潛能。立即前往 XIX.AI 展開您的探索之旅。
10 個工具
xix.ai

Cette accélération dans la course au raisonnement avancé me donne un peu le vertige 😅. D'un côté c'est fascinant de voir comment les modèles deviennent de plus en plus 'intelligents', mais d'un autre... on est certains que tout ce développement est sous contrôle ? Pas sûr que les entreprises pensent beaucoup aux implications éthiques quand elles sont lancées dans cette bataille commerciale ultra-compétitive.













