
















 家
家Microsoft Study Reveals AI Models' Limitations in Software Debugging
OpenAI、Anthropic、その他の主要AIラボのAIモデルは、コーディングタスクにますます活用されています。GoogleのCEOであるSundar Pichaiは10月に、AIが同社の新しいコードの25%を生成していると述べ、MetaのCEOであるMark Zuckerbergは、ソーシャルメディア大手内でAIコーディングツールを広く導入することを目指しています。
しかし、最高性能のモデルでさえ、経験豊富な開発者が容易に処理できるソフトウェアのバグ修正に苦戦しています。
MicrosoftのR&D部門が実施した最近のMicrosoft Researchの研究では、AnthropicのClaude 3.7 SonnetやOpenAIのo3-miniなどのモデルが、SWE-bench Liteソフトウェア開発ベンチマークの多くの問題を解決するのに苦労していることが示されています。この結果は、OpenAIなどの企業からの大胆な主張にもかかわらず、AIはコーディングなどの分野でまだ人間の専門知識に及ばないことを強調しています。
研究者は、Pythonデバッガを含むデバッグツールを備えた「シングルプロンプトベースのエージェント」の基盤として9つのモデルをテストしました。このエージェントは、SWE-bench Liteから選ばれた300のソフトウェアデバッグ課題に取り組む任務を負いました。
結果は、高度なモデルを使用しても、エージェントがタスクの半分以上を成功裏に解決することはほとんどありませんでした。Claude 3.7 Sonnetが48.4%の成功率でトップに立ち、OpenAIのo1が30.2%、o3-miniが22.1%でした。
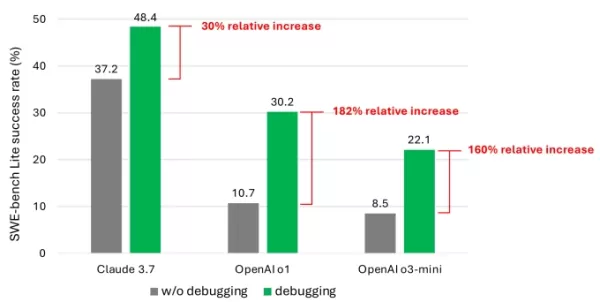
デバッグツールによるモデルのパフォーマンス向上を示す研究のチャート。画像提供:Microsoft この平凡な結果の原因は何でしょうか?一部のモデルは、利用可能なデバッグツールを効果的に使用したり、特定の問題に適したツールを特定したりするのに苦労しました。研究者によると、主な問題は、特に「連続的な意思決定プロセス」を捉えたデータ、例えば人間のデバッグトレースのような十分なトレーニングデータの不足でした。
「これらのモデルをトレーニングまたは微調整することで、デバッグ能力を向上させることができると信じています」と研究者は書いています。「しかし、これには、エージェントがデバッガと対話して情報を収集し、修正を提案する前に軌跡データを取得するような特殊なデータが必要です。」
TechCrunch Sessions: AIに参加
OpenAI、Anthropic、Cohereのスピーカーが参加する当社の主要なAI業界イベントで席を確保してください。期間限定で、チケットは専門家の講演、ワークショップ、ネットワーキングの機会が1日中楽しめるわずか292ドルです。
TechCrunch Sessions: AIで展示
TC Sessions: AIであなたの作品を1,200人以上の意思決定者に紹介するスポットを予約してください。展示の機会は5月9日まで、またはテーブルがすべて予約されるまで利用可能です。
この結果は驚くべきことではありません。多くの研究が、AIが生成したコードは、プログラミングロジックの理解の弱さからセキュリティの欠陥やエラーを引き起こすことが多いことを示しています。最近のテストでは、よく知られたAIコーディングツールであるDevinが、20のプログラミングタスクのうち3つしか完了できませんでした。
Microsoftの研究は、AIモデルが直面するこの継続的な課題について最も詳細な調査の1つを提供しています。AIを活用したコーディングツールへの投資家の関心を抑えることはないかもしれませんが、開発者やそのリーダーに、コーディングタスクにAIに大きく依存することを再考させる可能性があります。
注目すべきは、複数のテックリーダーが、AIがコーディングの仕事をなくすという考えに反論していることです。Microsoftの共同創業者Bill Gates、ReplitのCEOであるAmjad Masad、OktaのCEOであるTodd McKinnon、IBMのCEOであるArvind Krishnaは、プログラミングという職業が存続すると確信を表明しています。
関連記事
 カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す
関連特集おすすめ
チャットボット
カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す
関連特集おすすめ
チャットボット
 高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
高評価のAI恋愛チャットボット:一貫した個性で長期的な関係を築く
2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
 10 ツール
10 ツール
 xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
xix.ai
教育と学習
最高のAIデータサイエンスメンター:SQL、Pandas、および機械学習ワークフローをマスターしましょう
2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai
チャットボット
最高のAIを使ったナンパ&会話トレーニング:社交的な魅力と自信をリアルタイムで高める
XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai
コード
自動化ユニットテストに最適なAIツール:ワンクリックでJest、PyTest、JUnitのテストケースを生成する
2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai
データ分析
最高のAIデータ可視化ツール:生データからインタラクティブなBIダッシュボードを自動生成
XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai
ソーシャルメディア
ソーシャルメディア向けAIブランディングキット:すべてのチャネルで一貫したブランドビジュアルを維持
2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

 コメント (6)
0/500
コメント (6)
0/500
![ThomasScott]()
微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
![HenryWalker]()
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
![BrianRoberts]()
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
![KevinDavis]()
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
![PeterThomas]()
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
![JuanWhite]()
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.
OpenAI、Anthropic、その他の主要AIラボのAIモデルは、コーディングタスクにますます活用されています。GoogleのCEOであるSundar Pichaiは10月に、AIが同社の新しいコードの25%を生成していると述べ、MetaのCEOであるMark Zuckerbergは、ソーシャルメディア大手内でAIコーディングツールを広く導入することを目指しています。
しかし、最高性能のモデルでさえ、経験豊富な開発者が容易に処理できるソフトウェアのバグ修正に苦戦しています。
MicrosoftのR&D部門が実施した最近のMicrosoft Researchの研究では、AnthropicのClaude 3.7 SonnetやOpenAIのo3-miniなどのモデルが、SWE-bench Liteソフトウェア開発ベンチマークの多くの問題を解決するのに苦労していることが示されています。この結果は、OpenAIなどの企業からの大胆な主張にもかかわらず、AIはコーディングなどの分野でまだ人間の専門知識に及ばないことを強調しています。
研究者は、Pythonデバッガを含むデバッグツールを備えた「シングルプロンプトベースのエージェント」の基盤として9つのモデルをテストしました。このエージェントは、SWE-bench Liteから選ばれた300のソフトウェアデバッグ課題に取り組む任務を負いました。
結果は、高度なモデルを使用しても、エージェントがタスクの半分以上を成功裏に解決することはほとんどありませんでした。Claude 3.7 Sonnetが48.4%の成功率でトップに立ち、OpenAIのo1が30.2%、o3-miniが22.1%でした。
この平凡な結果の原因は何でしょうか?一部のモデルは、利用可能なデバッグツールを効果的に使用したり、特定の問題に適したツールを特定したりするのに苦労しました。研究者によると、主な問題は、特に「連続的な意思決定プロセス」を捉えたデータ、例えば人間のデバッグトレースのような十分なトレーニングデータの不足でした。
「これらのモデルをトレーニングまたは微調整することで、デバッグ能力を向上させることができると信じています」と研究者は書いています。「しかし、これには、エージェントがデバッガと対話して情報を収集し、修正を提案する前に軌跡データを取得するような特殊なデータが必要です。」
TechCrunch Sessions: AIに参加
OpenAI、Anthropic、Cohereのスピーカーが参加する当社の主要なAI業界イベントで席を確保してください。期間限定で、チケットは専門家の講演、ワークショップ、ネットワーキングの機会が1日中楽しめるわずか292ドルです。
TechCrunch Sessions: AIで展示
TC Sessions: AIであなたの作品を1,200人以上の意思決定者に紹介するスポットを予約してください。展示の機会は5月9日まで、またはテーブルがすべて予約されるまで利用可能です。
この結果は驚くべきことではありません。多くの研究が、AIが生成したコードは、プログラミングロジックの理解の弱さからセキュリティの欠陥やエラーを引き起こすことが多いことを示しています。最近のテストでは、よく知られたAIコーディングツールであるDevinが、20のプログラミングタスクのうち3つしか完了できませんでした。
Microsoftの研究は、AIモデルが直面するこの継続的な課題について最も詳細な調査の1つを提供しています。AIを活用したコーディングツールへの投資家の関心を抑えることはないかもしれませんが、開発者やそのリーダーに、コーディングタスクにAIに大きく依存することを再考させる可能性があります。
注目すべきは、複数のテックリーダーが、AIがコーディングの仕事をなくすという考えに反論していることです。Microsoftの共同創業者Bill Gates、ReplitのCEOであるAmjad Masad、OktaのCEOであるTodd McKinnon、IBMのCEOであるArvind Krishnaは、プログラミングという職業が存続すると確信を表明しています。









 カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
カカオ・モビリティ、物理AIに向けたレベル4自動運転のロードマップを提示
カカオ・モビリティは、フィジカルAI戦略の一環として、レベル4の自動運転技術を自社開発する計画だ。ソウルCOEXで開催された「2026ワールドITショー」のカンファレンスにおいて、カカオモビリティのフィジカルAI部門長兼副社長であるキム・ジンギュ氏がロードマップを発表した。同氏の講演は、フィジカルAI時代におけるモビリティプラットフォームを軸とした自動運転サービスに焦点を当てたものだった。聯合
 バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
 YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す
YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す

2026年版、本物の長期的なつながりを築くための、高評価のAI恋愛チャットボットをご紹介します。厳選されたリストには、魅力的で一貫性のあるキャラクター、無料版と有料版の比較、そして実地テストの結果が掲載されています。あなたにぴったりのパートナーを見つけて、今すぐXIX.AIで関係を築き始めましょう。
10 ツール
xix.ai

2026年に最も優れたAIデータサイエンスのメンターを探して、SQL、Pandas、およびMLワークフローをマスターしましょう。XIX.AIで評価の高い厳選されたメンターたちの指導を受けて、力強く、革新的なアドバイスを得てください。無料オプションと有料オプションを実世界の視点から比較しましょう。今日すぐにデータサイエンスのスキルを向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIを使った口説き術・会話トレーニングツールを発見しましょう。厳選された高評価のツールが、リアルタイムで社交的な魅力と自信を築くお手伝いをします。無料版と有料版の比較や毎週更新されるランキングを参考に、ぜひ試すべき画期的なツールを探してみてください。今すぐ、あなたの社交力を引き出しましょう。
10 ツール
xix.ai

2026年に登場した、自動化ユニットテスト用の最高評価を受けたAIツールを発見してください。当社が厳選したこれらのツールは、Jest、PyTest、JUnitのテストケースを瞬時に生成するための強力で革新的なソリューションです。XIX.AIでは、無料オプションと有料オプションを実際のテストデータと共に比較し、毎週更新されるランキングもご覧いただけます。今すぐAIの力を活用して、開発生産性を向上させましょう。
10 ツール
xix.ai

XIX.AIで、2026年最高のAIデータ可視化ツールをご覧ください。厳選された高評価のツール群を活用すれば、生データから強力でインタラクティブなBIダッシュボードを瞬時に自動生成できます。実環境でのテスト結果や毎週更新されるランキングをもとに、無料版と有料版の比較も可能です。今すぐデータの可能性を引き出しましょう。
10 ツール
xix.ai

2026年版、ソーシャルメディア向けAIブランディングキットベストセレクションをご紹介。XIX.AIが厳選したこのリストには、あらゆるチャネルでブランドビジュアルの統一感を完璧に保つ、高評価で画期的なツールが揃っています。実際のテスト結果をもとに、無料版と有料版を比較しましょう。今すぐ、ブランドのビジュアル面での優位性を手に入れましょう。
10 ツール
xix.ai

微软这个研究结果太真实了😂 前几天用Copilot改bug,它居然把正确代码改得更错了…看来AI写代码还是得人工把关,至少现阶段别太依赖它们debug。
It's wild that AI is pumping out 25% of Google's code, but this Microsoft study shows it's not perfect at debugging. Kinda makes you wonder if we're trusting these models a bit too much too soon. 😅 Anyone else worried about buggy AI code sneaking into big projects?
It's wild that AI is cranking out 25% of Google's code, but the debugging struggles are real. Makes me wonder if we're leaning too hard on AI without fixing its blind spots first. 🧑💻
It's wild that AI is pumping out 25% of Google's code, but the debugging limitations in this study make me wonder if we're leaning too hard on these models without enough human oversight. 🤔
Interesting read! AI generating 25% of Google's code is wild, but I'm not surprised it struggles with debugging. Machines can churn out code fast, but catching tricky bugs? That’s still a human’s game. 🧑💻
AI coding sounds cool, but if it can't debug properly, what's the point? 🤔 Feels like we're hyping up half-baked tools while devs still clean up the mess.













