
















 家
家Deep CogitoのLLMSは、IDAを使用して同様のサイズのモデルよりも優れています
ディープ・コジトは、サンフランシスコに拠点を置く企業で、最新のオープン大規模言語モデル(LLMs)のリリースによりAIコミュニティで注目を集めています。これらのモデルは、30億から700億のパラメータに至るさまざまなサイズがあり、単なるAIツールのセットではありません。企業が「一般超知能」と呼ぶものに向けた大胆な一歩です。ディープ・コジトは、彼らの各モデルが、LLAMA、DeepSeek、Qwenなどの同規模の主要なオープンモデルを、ほとんどの標準ベンチマークで上回ると主張しています。これは大胆な主張ですが、さらに印象的なのは、彼らの700億パラメータモデルが、最近リリースされたLlama 4 109B Mixture-of-Experts(MoE)モデルを上回ったと報告されていることです。
反復蒸留と増幅(IDA)
ディープ・コジトの画期的な成果の中心には、彼らが反復蒸留と増幅(IDA)と呼ぶ新しいトレーニングアプローチがあります。この方法は、「反復的自己改善を用いた一般超知能のためのスケーラブルで効率的な整合戦略」と説明されています。従来のLLMトレーニングの限界を打破する設計で、モデルの知能がより大きな「監督者」モデルや人間のキュレーターによって定義された上限に達してしまう問題を克服します。
IDAプロセスは、繰り返し行われる2つの主要なステップを中心に展開します:
- 増幅:このステップでは、より多くの計算能力を使用して、モデルがより優れた解決策や能力を生み出すのを助け、高度な推論技術に似ています。
- 蒸留:ここでは、モデルがこれらの改善された能力を内面化し、パラメータを洗練させます。
ディープ・コジトは、これにより「正のフィードバックループ」が作成され、モデルの知能が監督者の知能に制限されることなく、計算リソースとIDAプロセスの効率によってより直接的に成長すると主張しています。
同社は、AlphaGoのような歴史的な成功例を挙げ、「高度な推論と反復的自己改善」が重要だったと強調しています。IDAは、これらの要素をLLMトレーニングにもたらすと彼らは主張します。また、IDAの効率性も強調し、小規模なチームでありながら、約75日でこれらのモデルを開発できたと述べています。人間のフィードバックからの強化学習(RLHF)や、より大きなモデルからの標準的な蒸留といった他の方法と比較して、IDAはより優れたスケーラビリティを提供するとされています。
証拠として、ディープ・コジトは、彼らの700億モデルが、Llama 3.3 70B(4050億モデルから蒸留)とLlama 4 Scout 109B(2兆パラメータモデルから蒸留)の両方を上回っていることを強調しています。
ディープ・コジトモデルの能力と性能
新しいコジトモデルは、LlamaとQwenのチェックポイントを基に構築されており、コーディング、関数呼び出し、エージェント型アプリケーション向けに調整されています。際立った特徴は、2つの機能性です:「各モデルは直接回答(標準LLM)でき、または回答前に自己反省(推論モデルのように)できます。」これは、Claude 3.5のようなモデルで見られる能力を反映しています。ただし、ディープ・コジトは、非常に長い推論チェーンには焦点を当てておらず、より速い回答と短いチェーンの蒸留の効率を優先していると述べています。
同社は、直接モードと推論モードの両方で、サイズ相当の最先端のオープンモデルに対するコジトモデルの広範なベンチマーク結果を共有しています。MMLU、MMLU-Pro、ARC、GSM8K、MATHなどのさまざまなベンチマークや、異なるモデルサイズ(3B、8B、14B、32B、70B)で、コジトモデルは一般的に大幅な性能向上を示しています。たとえば、コジト700億モデルは、標準モードでMMLUで91.73%を記録し、Llama 3.3 70Bに対して+6.40%の改善、思考モードでは91.00%で、Deepseek R1 Distill 70Bに対して+4.40%の向上を示しています。Livebenchのスコアもこれらの向上を反映しています。
14Bモデルのベンチマークを中規模比較として以下に示します:
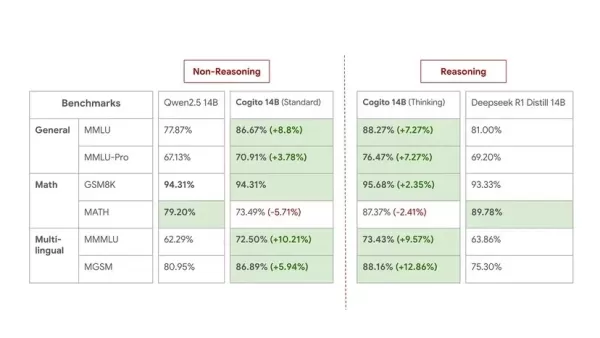
ディープ・コジトは、ベンチマークが実際の有用性を完全に捉えるものではないと認めつつも、モデルの実際の性能に自信を持っています。このリリースはプレビューとされており、同社は「このスケーリングカーブの初期段階にある」と述べています。彼らは現在のサイズの改善されたチェックポイントをリリースし、今後数週間から数か月でより大きなMoEモデル(109B、400B、671B)を導入する予定です。すべての将来のモデルもオープンソースになる予定です。
関連記事
 バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す
真の違い:あることではなく、別のこと
物事は、ある側面だけでなく、別の側面も併せ持っていることがあります。「これは単にこれだけではなく、あれでもある」という表現は、AIが生成した文章においてあまりにも一般的になったため、もはや合成コンテンツの単なるヒントというだけでなく、ほぼ確実な証拠となっています。だからこそ、企業コミュニケーションにおいてこの文構造が急増しているという『バロンズ』のレポートを目にした時、私は単に興味をそそられただけ
関連特集おすすめ
書き込み
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す
真の違い:あることではなく、別のこと
物事は、ある側面だけでなく、別の側面も併せ持っていることがあります。「これは単にこれだけではなく、あれでもある」という表現は、AIが生成した文章においてあまりにも一般的になったため、もはや合成コンテンツの単なるヒントというだけでなく、ほぼ確実な証拠となっています。だからこそ、企業コミュニケーションにおいてこの文構造が急増しているという『バロンズ』のレポートを目にした時、私は単に興味をそそられただけ
関連特集おすすめ
書き込み
 最高のAI仙侠・武侠アシスタント:壮大な修練の物語と武術の演出を執筆
最高のAI仙侠・武侠アシスタント:壮大な修練の物語と武術の演出を執筆
2026年版、壮大な仙侠・武侠物語を創作するための最高のAIアシスタントをご紹介。XIX.AIが厳選したこのリストには、修練の進捗管理や武術の演出を完璧にこなす、高評価で画期的なツールが揃っています。無料版と有料版を実際のテスト結果で比較。あなたの創造力を解き放ち、今すぐ執筆を始めましょう!
 10 ツール
10 ツール
 xix.ai
コード
AIモバイルアプリ開発ツール:プロンプトからクロスプラットフォーム対応のFlutterおよびReact Nativeコードを生成する
xix.ai
コード
AIモバイルアプリ開発ツール:プロンプトからクロスプラットフォーム対応のFlutterおよびReact Nativeコードを生成する
2026年に最も優れたAIモバイルアプリ開発ツールをFlutterおよびReact Native向けにご紹介します。当社が厳選した高評価のツール群は、プロンプトからクロスプラットフォーム対応のコードを自動生成する、画期的なソリューションです。無料版と有料版を実際のテストで比較し、より迅速な開発と高品質なアプリの構築を実現してください。XIX.AIでランキングをご確認ください!
10 ツール
xix.ai
コード
おすすめのAI Chrome拡張機能ジェネレーター:プログラミングの知識がなくてもカスタムブラウザ拡張機能を作成
XIX.AIで、2026年おすすめのAI Chrome拡張機能ジェネレーターを発見しましょう。厳選されたこのリストには、コーディング不要で独自のブラウザ拡張機能を作成できる、高評価の「必見」ツールが揃っています。無料版と有料版の比較や実機テストの結果を確認し、生産性を飛躍的に向上させましょう。最新のランキングをチェックして、あなたにぴったりのツールを今すぐ見つけましょう!
10 ツール
xix.ai
テキスト読み上げ
最高のAI多言語TTS:50以上の言語で本物のネイティブなアクセントの音声を生成する
2026年に最も優れたAI多言語TTSツールを探そう。50以上の言語で本物のネイティブな発音が再現可能だ。当社が厳選したランキングをチェックし、無料版と有料版の比較や実際の使用テスト結果も確認してみてください。XIX.AIで自分に最適な音声ツールを見つけ出し、今日から世界中とのコミュニケーションをスムーズに始めましょう。
10 ツール
xix.ai
ミーティングアシスタント
よりスマートで迅速なコラボレーションを実現する、最高のAI会議自動化ツール
2026年最新の、高評価を得ているAI会議自動化ツールを紹介。よりスマートで迅速なコラボレーションを実現します。厳選されたリストには、議事録、要約、アクションアイテムを自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。チームの生産性を最大限に引き出しましょう。今すぐXIX.AIで厳選されたツールをご覧ください。
10 ツール
xix.ai
プロンプト
Infrastructure-as-Code 向け AI プロンプト:Terraform および Docker の設定を安全にデプロイする
2026年最新の「Infrastructure-as-Code」向け高評価AIプロンプトをご紹介します。XIX.AIが厳選したプロンプトを活用すれば、TerraformやDockerの設定を安全にデプロイし、クラウド環境のセットアップを自動化し、DevOpsの生産性を向上させることができます。実際のテスト結果をもとに、無料版と有料版の比較も可能です。今すぐチェックして、AIの真価を引き出しましょう。
10 ツール
xix.ai

 コメント (29)
0/500
コメント (29)
0/500
![FrankMoore]()
看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
![HenryJackson]()
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
![RoyWhite]()
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
![PaulThomas]()
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
![GregoryCarter]()
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
![EricRoberts]()
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
ディープ・コジトは、サンフランシスコに拠点を置く企業で、最新のオープン大規模言語モデル(LLMs)のリリースによりAIコミュニティで注目を集めています。これらのモデルは、30億から700億のパラメータに至るさまざまなサイズがあり、単なるAIツールのセットではありません。企業が「一般超知能」と呼ぶものに向けた大胆な一歩です。ディープ・コジトは、彼らの各モデルが、LLAMA、DeepSeek、Qwenなどの同規模の主要なオープンモデルを、ほとんどの標準ベンチマークで上回ると主張しています。これは大胆な主張ですが、さらに印象的なのは、彼らの700億パラメータモデルが、最近リリースされたLlama 4 109B Mixture-of-Experts(MoE)モデルを上回ったと報告されていることです。
反復蒸留と増幅(IDA)
ディープ・コジトの画期的な成果の中心には、彼らが反復蒸留と増幅(IDA)と呼ぶ新しいトレーニングアプローチがあります。この方法は、「反復的自己改善を用いた一般超知能のためのスケーラブルで効率的な整合戦略」と説明されています。従来のLLMトレーニングの限界を打破する設計で、モデルの知能がより大きな「監督者」モデルや人間のキュレーターによって定義された上限に達してしまう問題を克服します。
IDAプロセスは、繰り返し行われる2つの主要なステップを中心に展開します:
- 増幅:このステップでは、より多くの計算能力を使用して、モデルがより優れた解決策や能力を生み出すのを助け、高度な推論技術に似ています。
- 蒸留:ここでは、モデルがこれらの改善された能力を内面化し、パラメータを洗練させます。
ディープ・コジトは、これにより「正のフィードバックループ」が作成され、モデルの知能が監督者の知能に制限されることなく、計算リソースとIDAプロセスの効率によってより直接的に成長すると主張しています。
同社は、AlphaGoのような歴史的な成功例を挙げ、「高度な推論と反復的自己改善」が重要だったと強調しています。IDAは、これらの要素をLLMトレーニングにもたらすと彼らは主張します。また、IDAの効率性も強調し、小規模なチームでありながら、約75日でこれらのモデルを開発できたと述べています。人間のフィードバックからの強化学習(RLHF)や、より大きなモデルからの標準的な蒸留といった他の方法と比較して、IDAはより優れたスケーラビリティを提供するとされています。
証拠として、ディープ・コジトは、彼らの700億モデルが、Llama 3.3 70B(4050億モデルから蒸留)とLlama 4 Scout 109B(2兆パラメータモデルから蒸留)の両方を上回っていることを強調しています。
ディープ・コジトモデルの能力と性能
新しいコジトモデルは、LlamaとQwenのチェックポイントを基に構築されており、コーディング、関数呼び出し、エージェント型アプリケーション向けに調整されています。際立った特徴は、2つの機能性です:「各モデルは直接回答(標準LLM)でき、または回答前に自己反省(推論モデルのように)できます。」これは、Claude 3.5のようなモデルで見られる能力を反映しています。ただし、ディープ・コジトは、非常に長い推論チェーンには焦点を当てておらず、より速い回答と短いチェーンの蒸留の効率を優先していると述べています。
同社は、直接モードと推論モードの両方で、サイズ相当の最先端のオープンモデルに対するコジトモデルの広範なベンチマーク結果を共有しています。MMLU、MMLU-Pro、ARC、GSM8K、MATHなどのさまざまなベンチマークや、異なるモデルサイズ(3B、8B、14B、32B、70B)で、コジトモデルは一般的に大幅な性能向上を示しています。たとえば、コジト700億モデルは、標準モードでMMLUで91.73%を記録し、Llama 3.3 70Bに対して+6.40%の改善、思考モードでは91.00%で、Deepseek R1 Distill 70Bに対して+4.40%の向上を示しています。Livebenchのスコアもこれらの向上を反映しています。
14Bモデルのベンチマークを中規模比較として以下に示します:
ディープ・コジトは、ベンチマークが実際の有用性を完全に捉えるものではないと認めつつも、モデルの実際の性能に自信を持っています。このリリースはプレビューとされており、同社は「このスケーリングカーブの初期段階にある」と述べています。彼らは現在のサイズの改善されたチェックポイントをリリースし、今後数週間から数か月でより大きなMoEモデル(109B、400B、671B)を導入する予定です。すべての将来のモデルもオープンソースになる予定です。










 バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
バリー・ディラー:AGIの実現が近づく中、サム・アルトマンへの信頼は重要ではない
億万長者のメディア界の巨頭であるバリー・ディラー氏は、最近の報道でそのように示唆されているにもかかわらず、OpenAIのCEOサム・アルトマン氏が信頼できない人物だとは考えていない。今週開催されたウォール・ストリート・ジャーナル紙主催の「Future of Everything」カンファレンスで講演したディラー氏は、一部の元同僚や取締役から、時折人を利用したり欺いたりする傾向があるとの非難を受けて
 YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す
YouTube、政治家、政府関係者、ジャーナリストを対象にAIによるディープフェイク検出機能を拡大
火曜日、YouTubeは、ディープフェイク検出技術を、特定の政府関係者、政治家候補者、ジャーナリストを対象に拡大すると発表した。このツールはAIによって生成された肖像を識別し、パイロットプログラムの参加者は、YouTubeのポリシーに違反していると判断した無断コンテンツの削除をリクエストできるようになる。この検出システムは、先行するテスト段階を経て、昨年、YouTubeパートナープログラムに参加す
 真の違い:あることではなく、別のこと
物事は、ある側面だけでなく、別の側面も併せ持っていることがあります。「これは単にこれだけではなく、あれでもある」という表現は、AIが生成した文章においてあまりにも一般的になったため、もはや合成コンテンツの単なるヒントというだけでなく、ほぼ確実な証拠となっています。だからこそ、企業コミュニケーションにおいてこの文構造が急増しているという『バロンズ』のレポートを目にした時、私は単に興味をそそられただけ
真の違い:あることではなく、別のこと
物事は、ある側面だけでなく、別の側面も併せ持っていることがあります。「これは単にこれだけではなく、あれでもある」という表現は、AIが生成した文章においてあまりにも一般的になったため、もはや合成コンテンツの単なるヒントというだけでなく、ほぼ確実な証拠となっています。だからこそ、企業コミュニケーションにおいてこの文構造が急増しているという『バロンズ』のレポートを目にした時、私は単に興味をそそられただけ

2026年版、壮大な仙侠・武侠物語を創作するための最高のAIアシスタントをご紹介。XIX.AIが厳選したこのリストには、修練の進捗管理や武術の演出を完璧にこなす、高評価で画期的なツールが揃っています。無料版と有料版を実際のテスト結果で比較。あなたの創造力を解き放ち、今すぐ執筆を始めましょう!
10 ツール
xix.ai

2026年に最も優れたAIモバイルアプリ開発ツールをFlutterおよびReact Native向けにご紹介します。当社が厳選した高評価のツール群は、プロンプトからクロスプラットフォーム対応のコードを自動生成する、画期的なソリューションです。無料版と有料版を実際のテストで比較し、より迅速な開発と高品質なアプリの構築を実現してください。XIX.AIでランキングをご確認ください!
10 ツール
xix.ai

XIX.AIで、2026年おすすめのAI Chrome拡張機能ジェネレーターを発見しましょう。厳選されたこのリストには、コーディング不要で独自のブラウザ拡張機能を作成できる、高評価の「必見」ツールが揃っています。無料版と有料版の比較や実機テストの結果を確認し、生産性を飛躍的に向上させましょう。最新のランキングをチェックして、あなたにぴったりのツールを今すぐ見つけましょう!
10 ツール
xix.ai

2026年に最も優れたAI多言語TTSツールを探そう。50以上の言語で本物のネイティブな発音が再現可能だ。当社が厳選したランキングをチェックし、無料版と有料版の比較や実際の使用テスト結果も確認してみてください。XIX.AIで自分に最適な音声ツールを見つけ出し、今日から世界中とのコミュニケーションをスムーズに始めましょう。
10 ツール
xix.ai

2026年最新の、高評価を得ているAI会議自動化ツールを紹介。よりスマートで迅速なコラボレーションを実現します。厳選されたリストには、議事録、要約、アクションアイテムを自動化する、強力で画期的なソリューションが揃っています。実際のテスト結果や毎週更新されるランキングをもとに、無料版と有料版を比較できます。チームの生産性を最大限に引き出しましょう。今すぐXIX.AIで厳選されたツールをご覧ください。
10 ツール
xix.ai

2026年最新の「Infrastructure-as-Code」向け高評価AIプロンプトをご紹介します。XIX.AIが厳選したプロンプトを活用すれば、TerraformやDockerの設定を安全にデプロイし、クラウド環境のセットアップを自動化し、DevOpsの生産性を向上させることができます。実際のテスト結果をもとに、無料版と有料版の比較も可能です。今すぐチェックして、AIの真価を引き出しましょう。
10 ツール
xix.ai

看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡













