




Deep Cogito的LLMS使用IDA优于类似大小的模型
Deep Cogito,一家总部位于旧金山的公司,以其最新发布的开源大型语言模型(LLMs)在AI社区中掀起了波澜。这些模型拥有从30亿到700亿个参数的多种规模,不仅仅是另一组AI工具;它们是公司所称的“通用超智能”的大胆一步。Deep Cogito声称,其每个模型在大多数标准基准测试中都超越了同等规模的领先开源模型,包括来自LLAMA、DeepSeek和Qwen的模型。这是一个相当大胆的声明,但更令人印象深刻的是,他们的700亿参数模型据报道超过了最近发布的Llama 4 109亿参数混合专家(MoE)模型。
迭代蒸馏与放大(IDA)
Deep Cogito突破的核心是一种他们称之为迭代蒸馏与放大(IDA)的新训练方法。这种方法被描述为“一种通过迭代自我改进实现通用超智能的可扩展且高效的Alignment策略”。它旨在突破传统LLM训练的限制,在传统训练中,模型的智能往往受到更大“监督者”模型或人类策展者的上限限制。
IDA过程围绕两个关键步骤反复进行:
- 放大:这一步骤利用更多的计算能力帮助模型提出更好的解决方案或能力,类似于高级推理技术。
- 蒸馏:在此,模型内化这些改进的能力,优化其参数。
Deep Cogito认为,这创造了一个“正反馈循环”,使模型的智能能够更直接地随计算资源和IDA过程本身的效率而增长,而不是受限于监督者的智能。
公司指出像AlphaGo这样的历史成功案例,强调“高级推理和迭代自我改进”至关重要。他们声称IDA将这些元素引入了LLM训练。他们还强调了IDA的效率,指出他们的小团队仅用大约75天就开发出了这些模型。与其他方法如基于人类反馈的强化学习(RLHF)或从更大模型的标准蒸馏相比,IDA据说提供了更好的可扩展性。
作为证明,Deep Cogito强调他们的700亿参数模型在性能上超过了Llama 3.3 700亿(从4050亿模型蒸馏)和Llama 4 Scout 109亿(从2万亿参数模型蒸馏)。
Deep Cogito模型的能力与性能
新的Cogito模型基于Llama和Qwen检查点,专为编码、函数调用和代理应用量身定制。一个突出特点是它们的双重功能:“每个模型都可以直接回答(标准LLM),或在回答前进行自我反思(类似推理模型)。”这与Claude 3.5等模型的功能相似。然而,Deep Cogito提到他们并未专注于非常长的推理链,优先考虑更快的回答和蒸馏较短链的效率。
公司分享了广泛的基准测试结果,将他们的Cogito模型与同等规模的先进开源模型在直接和推理模式下进行比较。在MMLU、MMLU-Pro、ARC、GSM8K和MATH等一系列基准测试中,以及在不同模型规模(30亿、80亿、140亿、320亿、700亿)中,Cogito模型通常显示出显著的性能提升。例如,Cogito 700亿模型在标准模式下MMLU得分91.73%,比Llama 3.3 700亿提高了+6.40%,在思考模式下得分91.00%,比Deepseek R1 Distill 700亿提高了+4.40%。Livebench得分也反映了这些提升。
以下是140亿模型的基准测试,用于中等规模的比较:
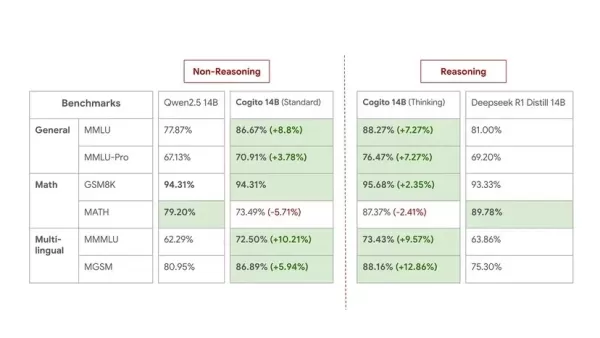
虽然Deep Cogito承认基准测试无法完全反映现实世界的实用性,但他们对其模型的实际性能仍充满信心。此次发布被视为预览,公司表示他们“仍处于这一扩展曲线的早期阶段”。他们计划在未来几周和几个月内发布当前规模的改进检查点,并推出更大的MoE模型(1090亿、4000亿、6710亿)。所有未来模型也将是开源的。
相关文章
 YouTube 将 Veo 3 人工智能视频工具直接整合到短片平台中
今年夏天,YouTube 短片将采用 Veo 3 人工智能视频模式YouTube 首席执行官尼尔-莫汉(Neal Mohan)在戛纳国际电影节主题演讲中透露,该平台最先进的 Veo 3 人工智能视频生成技术将于今年夏天晚些时候在 YouTube Shorts 上首次亮相。此前,艾利森-约翰逊(Allison Johnson)在评论中将 Veo 3 描述为人工智能辅助内容创作的革命。目前,短片创作者
谷歌云为科学研究和发现的突破提供动力
数字革命正在通过前所未有的计算能力改变科学方法。现在,尖端技术增强了理论框架和实验室实验,通过复杂的模拟和大数据分析推动了各学科的突破。通过对基础研究、可扩展云架构和人工智能开发的战略性投资,我们建立了一个加速科学进步的生态系统。我们在制药研究、气候建模和纳米技术等领域做出了突破性创新,并辅之以世界一流的计算基础设施、云原生软件解决方案和新一代生成式人工智能平台。谷歌 DeepMind 的研究实力
埃隆-马斯克的 Grok 人工智能在处理复杂问题之前会征求主人的意见
最近发布的由埃隆-马斯克(Elon Musk)宣传为 "最大限度寻求真相 "系统的Grok人工智能,因其在回应政治敏感话题前倾向于参考马斯克的公开声明而备受关注。观察家们注意到,在讨论以色列-巴勒斯坦冲突、美国移民政策或堕胎辩论等有争议的问题时,聊天机器人似乎会优先考虑与马斯克记录在案的观点保持一致。Grok的决策过程数据科学家杰里米-霍华德(Jeremy Howard)通过屏幕录音记录了这
评论 (27)
0/200
YouTube 将 Veo 3 人工智能视频工具直接整合到短片平台中
今年夏天,YouTube 短片将采用 Veo 3 人工智能视频模式YouTube 首席执行官尼尔-莫汉(Neal Mohan)在戛纳国际电影节主题演讲中透露,该平台最先进的 Veo 3 人工智能视频生成技术将于今年夏天晚些时候在 YouTube Shorts 上首次亮相。此前,艾利森-约翰逊(Allison Johnson)在评论中将 Veo 3 描述为人工智能辅助内容创作的革命。目前,短片创作者
谷歌云为科学研究和发现的突破提供动力
数字革命正在通过前所未有的计算能力改变科学方法。现在,尖端技术增强了理论框架和实验室实验,通过复杂的模拟和大数据分析推动了各学科的突破。通过对基础研究、可扩展云架构和人工智能开发的战略性投资,我们建立了一个加速科学进步的生态系统。我们在制药研究、气候建模和纳米技术等领域做出了突破性创新,并辅之以世界一流的计算基础设施、云原生软件解决方案和新一代生成式人工智能平台。谷歌 DeepMind 的研究实力
埃隆-马斯克的 Grok 人工智能在处理复杂问题之前会征求主人的意见
最近发布的由埃隆-马斯克(Elon Musk)宣传为 "最大限度寻求真相 "系统的Grok人工智能,因其在回应政治敏感话题前倾向于参考马斯克的公开声明而备受关注。观察家们注意到,在讨论以色列-巴勒斯坦冲突、美国移民政策或堕胎辩论等有争议的问题时,聊天机器人似乎会优先考虑与马斯克记录在案的观点保持一致。Grok的决策过程数据科学家杰里米-霍华德(Jeremy Howard)通过屏幕录音记录了这
评论 (27)
0/200
![RoyWhite]() RoyWhite
RoyWhite
 2025-08-13 17:00:59
2025-08-13 17:00:59
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀


 0
0
![PaulThomas]() PaulThomas
2025-08-07 03:01:00
PaulThomas
2025-08-07 03:01:00
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
0
![GregoryCarter]() GregoryCarter
2025-04-21 11:16:16
GregoryCarter
2025-04-21 11:16:16
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
0
![EricRoberts]() EricRoberts
2025-04-20 12:40:17
EricRoberts
2025-04-20 12:40:17
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
0
![WillieAnderson]() WillieAnderson
2025-04-20 12:09:03
WillieAnderson
2025-04-20 12:09:03
딥 코기토의 LLM은 정말 혁신적이에요! 비슷한 크기의 모델과 비교해도 성능 향상이 놀랍습니다. IDA 접근법이 큰 차이를 만듭니다. 유일한 단점은 학습 곡선인데, 한번 익숙해지면 문제없어요! 🚀
0
![EricKing]() EricKing
2025-04-20 06:12:37
EricKing
2025-04-20 06:12:37
Deep Cogito's LLMs are impressive, but the app could use a better UI. It's a bit clunky to navigate through the different model sizes. Still, the performance is top-notch, especially with the IDA tech. Definitely worth a look if you're into AI and want to see what's possible with large language models! 🤖💡
0
Deep Cogito,一家总部位于旧金山的公司,以其最新发布的开源大型语言模型(LLMs)在AI社区中掀起了波澜。这些模型拥有从30亿到700亿个参数的多种规模,不仅仅是另一组AI工具;它们是公司所称的“通用超智能”的大胆一步。Deep Cogito声称,其每个模型在大多数标准基准测试中都超越了同等规模的领先开源模型,包括来自LLAMA、DeepSeek和Qwen的模型。这是一个相当大胆的声明,但更令人印象深刻的是,他们的700亿参数模型据报道超过了最近发布的Llama 4 109亿参数混合专家(MoE)模型。
迭代蒸馏与放大(IDA)
Deep Cogito突破的核心是一种他们称之为迭代蒸馏与放大(IDA)的新训练方法。这种方法被描述为“一种通过迭代自我改进实现通用超智能的可扩展且高效的Alignment策略”。它旨在突破传统LLM训练的限制,在传统训练中,模型的智能往往受到更大“监督者”模型或人类策展者的上限限制。
IDA过程围绕两个关键步骤反复进行:
- 放大:这一步骤利用更多的计算能力帮助模型提出更好的解决方案或能力,类似于高级推理技术。
- 蒸馏:在此,模型内化这些改进的能力,优化其参数。
Deep Cogito认为,这创造了一个“正反馈循环”,使模型的智能能够更直接地随计算资源和IDA过程本身的效率而增长,而不是受限于监督者的智能。
公司指出像AlphaGo这样的历史成功案例,强调“高级推理和迭代自我改进”至关重要。他们声称IDA将这些元素引入了LLM训练。他们还强调了IDA的效率,指出他们的小团队仅用大约75天就开发出了这些模型。与其他方法如基于人类反馈的强化学习(RLHF)或从更大模型的标准蒸馏相比,IDA据说提供了更好的可扩展性。
作为证明,Deep Cogito强调他们的700亿参数模型在性能上超过了Llama 3.3 700亿(从4050亿模型蒸馏)和Llama 4 Scout 109亿(从2万亿参数模型蒸馏)。
Deep Cogito模型的能力与性能
新的Cogito模型基于Llama和Qwen检查点,专为编码、函数调用和代理应用量身定制。一个突出特点是它们的双重功能:“每个模型都可以直接回答(标准LLM),或在回答前进行自我反思(类似推理模型)。”这与Claude 3.5等模型的功能相似。然而,Deep Cogito提到他们并未专注于非常长的推理链,优先考虑更快的回答和蒸馏较短链的效率。
公司分享了广泛的基准测试结果,将他们的Cogito模型与同等规模的先进开源模型在直接和推理模式下进行比较。在MMLU、MMLU-Pro、ARC、GSM8K和MATH等一系列基准测试中,以及在不同模型规模(30亿、80亿、140亿、320亿、700亿)中,Cogito模型通常显示出显著的性能提升。例如,Cogito 700亿模型在标准模式下MMLU得分91.73%,比Llama 3.3 700亿提高了+6.40%,在思考模式下得分91.00%,比Deepseek R1 Distill 700亿提高了+4.40%。Livebench得分也反映了这些提升。
以下是140亿模型的基准测试,用于中等规模的比较:
虽然Deep Cogito承认基准测试无法完全反映现实世界的实用性,但他们对其模型的实际性能仍充满信心。此次发布被视为预览,公司表示他们“仍处于这一扩展曲线的早期阶段”。他们计划在未来几周和几个月内发布当前规模的改进检查点,并推出更大的MoE模型(1090亿、4000亿、6710亿)。所有未来模型也将是开源的。










 YouTube 将 Veo 3 人工智能视频工具直接整合到短片平台中
今年夏天,YouTube 短片将采用 Veo 3 人工智能视频模式YouTube 首席执行官尼尔-莫汉(Neal Mohan)在戛纳国际电影节主题演讲中透露,该平台最先进的 Veo 3 人工智能视频生成技术将于今年夏天晚些时候在 YouTube Shorts 上首次亮相。此前,艾利森-约翰逊(Allison Johnson)在评论中将 Veo 3 描述为人工智能辅助内容创作的革命。目前,短片创作者
YouTube 将 Veo 3 人工智能视频工具直接整合到短片平台中
今年夏天,YouTube 短片将采用 Veo 3 人工智能视频模式YouTube 首席执行官尼尔-莫汉(Neal Mohan)在戛纳国际电影节主题演讲中透露,该平台最先进的 Veo 3 人工智能视频生成技术将于今年夏天晚些时候在 YouTube Shorts 上首次亮相。此前,艾利森-约翰逊(Allison Johnson)在评论中将 Veo 3 描述为人工智能辅助内容创作的革命。目前,短片创作者
 谷歌云为科学研究和发现的突破提供动力
数字革命正在通过前所未有的计算能力改变科学方法。现在,尖端技术增强了理论框架和实验室实验,通过复杂的模拟和大数据分析推动了各学科的突破。通过对基础研究、可扩展云架构和人工智能开发的战略性投资,我们建立了一个加速科学进步的生态系统。我们在制药研究、气候建模和纳米技术等领域做出了突破性创新,并辅之以世界一流的计算基础设施、云原生软件解决方案和新一代生成式人工智能平台。谷歌 DeepMind 的研究实力
谷歌云为科学研究和发现的突破提供动力
数字革命正在通过前所未有的计算能力改变科学方法。现在,尖端技术增强了理论框架和实验室实验,通过复杂的模拟和大数据分析推动了各学科的突破。通过对基础研究、可扩展云架构和人工智能开发的战略性投资,我们建立了一个加速科学进步的生态系统。我们在制药研究、气候建模和纳米技术等领域做出了突破性创新,并辅之以世界一流的计算基础设施、云原生软件解决方案和新一代生成式人工智能平台。谷歌 DeepMind 的研究实力
 埃隆-马斯克的 Grok 人工智能在处理复杂问题之前会征求主人的意见
最近发布的由埃隆-马斯克(Elon Musk)宣传为 "最大限度寻求真相 "系统的Grok人工智能,因其在回应政治敏感话题前倾向于参考马斯克的公开声明而备受关注。观察家们注意到,在讨论以色列-巴勒斯坦冲突、美国移民政策或堕胎辩论等有争议的问题时,聊天机器人似乎会优先考虑与马斯克记录在案的观点保持一致。Grok的决策过程数据科学家杰里米-霍华德(Jeremy Howard)通过屏幕录音记录了这
2025-08-13 17:00:59
埃隆-马斯克的 Grok 人工智能在处理复杂问题之前会征求主人的意见
最近发布的由埃隆-马斯克(Elon Musk)宣传为 "最大限度寻求真相 "系统的Grok人工智能,因其在回应政治敏感话题前倾向于参考马斯克的公开声明而备受关注。观察家们注意到,在讨论以色列-巴勒斯坦冲突、美国移民政策或堕胎辩论等有争议的问题时,聊天机器人似乎会优先考虑与马斯克记录在案的观点保持一致。Grok的决策过程数据科学家杰里米-霍华德(Jeremy Howard)通过屏幕录音记录了这
2025-08-13 17:00:59
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
0
2025-08-07 03:01:00
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
0
2025-04-21 11:16:16
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
0
2025-04-20 12:40:17
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
0
2025-04-20 12:09:03
딥 코기토의 LLM은 정말 혁신적이에요! 비슷한 크기의 모델과 비교해도 성능 향상이 놀랍습니다. IDA 접근법이 큰 차이를 만듭니다. 유일한 단점은 학습 곡선인데, 한번 익숙해지면 문제없어요! 🚀
0
2025-04-20 06:12:37
Deep Cogito's LLMs are impressive, but the app could use a better UI. It's a bit clunky to navigate through the different model sizes. Still, the performance is top-notch, especially with the IDA tech. Definitely worth a look if you're into AI and want to see what's possible with large language models! 🤖💡
0













