
















 Home
HomeDeep Cogito's LLMs Outperform Similar-Sized Models Using IDA
Deep Cogito, a San Francisco-based company, is making waves in the AI community with its latest release of open large language models (LLMs). These models, which come in various sizes ranging from 3 billion to 70 billion parameters, are not just another set of AI tools; they're a bold step towards what the company calls "general superintelligence." Deep Cogito claims that each of their models outperforms the leading open models of similar sizes, including those from LLAMA, DeepSeek, and Qwen, across most standard benchmarks. It's quite a claim, but what's even more impressive is that their 70B model has reportedly outshone the recently released Llama 4 109B Mixture-of-Experts (MoE) model.
Iterated Distillation and Amplification (IDA)
At the heart of Deep Cogito's breakthrough is a new training approach they call Iterated Distillation and Amplification (IDA). This method is described as "a scalable and efficient alignment strategy for general superintelligence using iterative self-improvement." It's designed to push past the limitations of traditional LLM training, where the model's intelligence often hits a ceiling defined by larger "overseer" models or human curators.
The IDA process revolves around two key steps that are repeated over and over:
- Amplification: This step uses more computational power to help the model come up with better solutions or capabilities, much like advanced reasoning techniques.
- Distillation: Here, the model internalizes these improved capabilities, refining its parameters.
Deep Cogito argues that this creates a "positive feedback loop," allowing the model's intelligence to grow more directly with the computational resources and the efficiency of the IDA process itself, rather than being limited by an overseer's intelligence.
The company points to historical successes like AlphaGo, emphasizing that "Advanced Reasoning and Iterative Self-Improvement" were crucial. IDA, they claim, brings these elements into LLM training. They also tout the efficiency of IDA, noting that their team, though small, managed to develop these models in just about 75 days. When compared to other methods like Reinforcement Learning from Human Feedback (RLHF) or standard distillation from larger models, IDA is said to offer better scalability.
As proof, Deep Cogito highlights how their 70B model outperforms both Llama 3.3 70B (distilled from a 405B model) and Llama 4 Scout 109B (distilled from a 2T parameter model).
Capabilities and Performance of Deep Cogito Models
The new Cogito models, which build upon Llama and Qwen checkpoints, are tailored for coding, function calling, and agentic applications. A standout feature is their dual functionality: "Each model can answer directly (standard LLM), or self-reflect before answering (like reasoning models)." This mirrors capabilities seen in models like Claude 3.5. However, Deep Cogito mentions they haven't focused on very long reasoning chains, prioritizing faster answers and the efficiency of distilling shorter chains.
The company has shared extensive benchmark results, comparing their Cogito models against size-equivalent state-of-the-art open models in both direct and reasoning modes. Across a range of benchmarks like MMLU, MMLU-Pro, ARC, GSM8K, and MATH, and across different model sizes (3B, 8B, 14B, 32B, 70B), the Cogito models generally show significant performance improvements. For example, the Cogito 70B model scores 91.73% on MMLU in standard mode, a +6.40% improvement over Llama 3.3 70B, and 91.00% in thinking mode, a +4.40% boost over Deepseek R1 Distill 70B. Livebench scores also reflect these gains.
Here are benchmarks of 14B models for a medium-sized comparison:
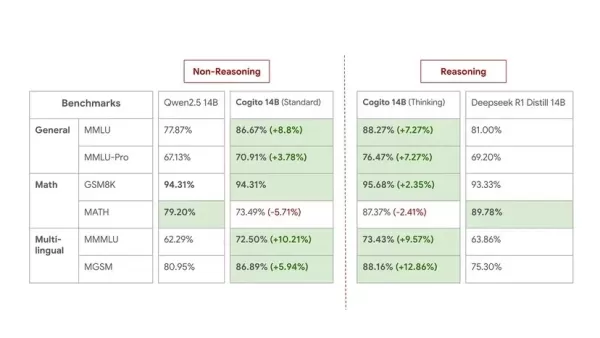
While Deep Cogito acknowledges that benchmarks don't fully capture real-world utility, they remain confident in the practical performance of their models. This release is considered a preview, with the company stating they are "still in the early stages of this scaling curve." They plan to release improved checkpoints for the current sizes and introduce larger MoE models (109B, 400B, 671B) in the coming weeks and months. All future models will also be open-source.
Related article
 WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman
Related Special Topic Recommendations
Business
WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman
Related Special Topic Recommendations
Business
 Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
Best AI Expense Trackers: Scan Receipts & Categorize Corporate Spend Automatically
2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
 10 tools
10 tools
 xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
xix.ai
Business
Best AI Recruiting Tools: Screen Resumes & Automate Candidate Interview Scheduling
Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai
Productivity
AI Personal Wellness & Focus Coaches: Manage Burnout & Boost Mental Energy Levels
Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai
chatbot
Top-Rated AI Romantic Chatbots: Build Long-Term Relationships with Consistent Personalities
Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai
Education and Learning
Best AI Data Science Mentors: Master SQL, Pandas & Machine Learning Workflows
Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai
chatbot
Best AI Flirting & Conversation Trainers: Improve Social Charisma and Confidence in Real-Time
Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

 Comments (29)
0/500
Comments (29)
0/500
![FrankMoore]()
看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
![HenryJackson]()
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
![RoyWhite]()
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
![PaulThomas]()
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
![GregoryCarter]()
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
![EricRoberts]()
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
Deep Cogito, a San Francisco-based company, is making waves in the AI community with its latest release of open large language models (LLMs). These models, which come in various sizes ranging from 3 billion to 70 billion parameters, are not just another set of AI tools; they're a bold step towards what the company calls "general superintelligence." Deep Cogito claims that each of their models outperforms the leading open models of similar sizes, including those from LLAMA, DeepSeek, and Qwen, across most standard benchmarks. It's quite a claim, but what's even more impressive is that their 70B model has reportedly outshone the recently released Llama 4 109B Mixture-of-Experts (MoE) model.
Iterated Distillation and Amplification (IDA)
At the heart of Deep Cogito's breakthrough is a new training approach they call Iterated Distillation and Amplification (IDA). This method is described as "a scalable and efficient alignment strategy for general superintelligence using iterative self-improvement." It's designed to push past the limitations of traditional LLM training, where the model's intelligence often hits a ceiling defined by larger "overseer" models or human curators.
The IDA process revolves around two key steps that are repeated over and over:
- Amplification: This step uses more computational power to help the model come up with better solutions or capabilities, much like advanced reasoning techniques.
- Distillation: Here, the model internalizes these improved capabilities, refining its parameters.
Deep Cogito argues that this creates a "positive feedback loop," allowing the model's intelligence to grow more directly with the computational resources and the efficiency of the IDA process itself, rather than being limited by an overseer's intelligence.
The company points to historical successes like AlphaGo, emphasizing that "Advanced Reasoning and Iterative Self-Improvement" were crucial. IDA, they claim, brings these elements into LLM training. They also tout the efficiency of IDA, noting that their team, though small, managed to develop these models in just about 75 days. When compared to other methods like Reinforcement Learning from Human Feedback (RLHF) or standard distillation from larger models, IDA is said to offer better scalability.
As proof, Deep Cogito highlights how their 70B model outperforms both Llama 3.3 70B (distilled from a 405B model) and Llama 4 Scout 109B (distilled from a 2T parameter model).
Capabilities and Performance of Deep Cogito Models
The new Cogito models, which build upon Llama and Qwen checkpoints, are tailored for coding, function calling, and agentic applications. A standout feature is their dual functionality: "Each model can answer directly (standard LLM), or self-reflect before answering (like reasoning models)." This mirrors capabilities seen in models like Claude 3.5. However, Deep Cogito mentions they haven't focused on very long reasoning chains, prioritizing faster answers and the efficiency of distilling shorter chains.
The company has shared extensive benchmark results, comparing their Cogito models against size-equivalent state-of-the-art open models in both direct and reasoning modes. Across a range of benchmarks like MMLU, MMLU-Pro, ARC, GSM8K, and MATH, and across different model sizes (3B, 8B, 14B, 32B, 70B), the Cogito models generally show significant performance improvements. For example, the Cogito 70B model scores 91.73% on MMLU in standard mode, a +6.40% improvement over Llama 3.3 70B, and 91.00% in thinking mode, a +4.40% boost over Deepseek R1 Distill 70B. Livebench scores also reflect these gains.
Here are benchmarks of 14B models for a medium-sized comparison:
While Deep Cogito acknowledges that benchmarks don't fully capture real-world utility, they remain confident in the practical performance of their models. This release is considered a preview, with the company stating they are "still in the early stages of this scaling curve." They plan to release improved checkpoints for the current sizes and introduce larger MoE models (109B, 400B, 671B) in the coming weeks and months. All future models will also be open-source.










 WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
WordPress.com now allows AI agents to write and publish posts, plus more
WordPress.com, the popular web hosting and publishing platform, is now embracing AI agents—a move that could reshape the look and feel of the web. The company announced Friday that it will allow AI agents to draft, edit, and publish content on custom
Kakao Mobility outlines Level 4 autonomous driving roadmap for physical AI
Kakao Mobility is planning to develop Level 4 autonomous driving technologies internally as part of its physical AI strategy.
At the 2026 World IT Show conference in Seoul's COEX, Kim Jin-kyu — vice president and head of Kakao Mobility's Physical AI
 Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman
Barry Diller: Trust in Sam Altman irrelevant as AGI nears
Barry Diller, the billionaire media titan, does not believe OpenAI CEO Sam Altman is untrustworthy, despite recent reports suggesting otherwise. Speaking at the Wall Street Journal's "Future of Everything" conference this week, Diller defended Altman

2026 Latest Best AI Expense Trackers: Top-rated tools to scan receipts & categorize corporate spend automatically. Discover powerful, game-changing solutions for effortless expense management, accurate financial tracking, and streamlined compliance. Our curated, weekly-updated comparison of free vs paid options helps you find the perfect fit. Unlock your AI edge with XIX.AI's expert picks.
10 tools
xix.ai

Discover the 2026 latest top-rated AI recruiting tools on XIX.AI. Our curated list features powerful, game-changing solutions for screening resumes and automating candidate interview scheduling. Compare free vs paid options with real-world tests and weekly updated rankings. Find your perfect hiring assistant and streamline your recruitment today!
10 tools
xix.ai

Discover the 2026 best AI personal wellness and focus coaches on XIX.AI. Our curated rankings feature top-rated, game-changing tools to manage burnout and boost mental energy. Compare free vs paid options with real-world insights. Unlock your path to peak productivity and well-being today.
10 tools
xix.ai

Discover the 2026 latest top-rated AI romantic chatbots for building genuine, long-term connections. Our curated list features powerful, consistent personalities, free vs paid comparisons, and real-world tests. Find your perfect companion and start building today at XIX.AI.
10 tools
xix.ai

Discover the 2026 best AI data science mentors to master SQL, Pandas & ML workflows. Explore our top-rated, curated selection at XIX.AI for powerful, game-changing guidance. Compare free vs paid options with real-world insights. Unlock your data science mastery today.
10 tools
xix.ai

Discover the 2026 best AI flirting and conversation trainers on XIX.AI. Our curated, top-rated selection helps you build social charisma and confidence in real-time. Explore must-try, game-changing tools with free vs paid comparisons and weekly updated rankings. Unlock your social edge today.
10 tools
xix.ai

看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡













