
















 집
집Deep Cogito의 LLMS는 IDA를 사용하여 유사한 크기의 모델보다 우수합니다
샌프란시스코에 본사를 둔 Deep Cogito는 최신 오픈 대규모 언어 모델(LLMs) 출시로 AI 커뮤니티에서 큰 반향을 일으키고 있습니다. 30억에서 700억 매개변수에 이르는 다양한 크기의 이 모델들은 단순한 AI 도구가 아니라, 회사가 "일반 초지능"이라고 부르는 대담한 발걸음입니다. Deep Cogito는 각 모델이 LLAMA, DeepSeek, Qwen의 유사한 크기의 선도적인 오픈 모델들을 대부분의 표준 벤치마크에서 능가한다고 주장합니다. 이는 상당한 주장인데, 더 인상적인 것은 그들의 70B 모델이 최근 출시된 Llama 4 109B Mixture-of-Experts (MoE) 모델을 능가했다는 보고입니다.
반복 증류 및 증폭 (IDA)
Deep Cogito의 획기적인 발전의 핵심에는 그들이 반복 증류 및 증폭(IDA)이라고 부르는 새로운 훈련 접근 방식이 있습니다. 이 방법은 "반복적 자기 개선을 통해 일반 초지능을 위한 확장 가능하고 효율적인 정렬 전략"으로 설명됩니다. 이는 전통적인 LLM 훈련의 한계를 넘어, 모델의 지능이 종종 더 큰 "감독자" 모델이나 인간 큐레이터에 의해 정의된 한계에 부딪히는 문제를 해결하도록 설계되었습니다.
IDA 프로세스는 반복적으로 수행되는 두 가지 주요 단계를 중심으로 이루어집니다:
- 증폭: 이 단계에서는 더 많은 컴퓨팅 파워를 사용하여 모델이 더 나은 솔루션이나 능력을 도출하도록 돕습니다. 이는 고급 추론 기술과 유사합니다.
- 증류: 여기서 모델은 이러한 향상된 능력을 내재화하여 매개변수를 정제합니다.
Deep Cogito는 이것이 "긍정적인 피드백 루프"를 만들어, 모델의 지능이 감독자의 지능에 의해 제한되지 않고 컴퓨팅 자원과 IDA 프로세스 자체의 효율성에 따라 더 직접적으로 성장할 수 있다고 주장합니다.
회사는 AlphaGo의 역사적 성공을 예로 들며, "고급 추론과 반복적 자기 개선"이 중요했다고 강조합니다. IDA는 이러한 요소를 LLM 훈련에 도입한다고 주장합니다. 또한 IDA의 효율성을 강조하며, 소규모 팀이 약 75일 만에 이 모델들을 개발했다고 밝혔습니다. 인간 피드백을 통한 강화 학습(RLHF)이나 더 큰 모델로부터의 표준 증류와 같은 다른 방법과 비교했을 때, IDA는 더 나은 확장성을 제공한다고 합니다.
증거로, Deep Cogito는 그들의 70B 모델이 Llama 3.3 70B(405B 모델에서 증류)와 Llama 4 Scout 109B(2T 매개변수 모델에서 증류)를 모두 능가한다고 강조합니다.
Deep Cogito 모델의 능력과 성능
Llama와 Qwen 체크포인트를 기반으로 구축된 새로운 Cogito 모델은 코딩, 함수 호출, 에이전트 애플리케이션에 맞춰져 있습니다. 두드러진 특징은 이중 기능성입니다: "각 모델은 직접 응답(표준 LLM)하거나 응답 전에 자기 성찰(추론 모델과 유사)할 수 있습니다." 이는 Claude 3.5와 같은 모델에서 볼 수 있는 능력을 반영합니다. 그러나 Deep Cogito는 매우 긴 추론 체인에 초점을 맞추지 않고, 더 빠른 응답과 더 짧은 체인의 증류 효율성을 우선시했다고 언급했습니다.
회사는 Cogito 모델을 직접 및 추론 모드에서 크기가 비슷한 최첨단 오픈 모델들과 비교한 광범위한 벤치마크 결과를 공유했습니다. MMLU, MMLU-Pro, ARC, GSM8K, MATH와 같은 다양한 벤치마크와 3B, 8B, 14B, 32B, 70B의 다양한 모델 크기에서 Cogito 모델은 일반적으로 상당한 성능 향상을 보여줍니다. 예를 들어, Cogito 70B 모델은 표준 모드에서 MMLU에서 91.73%를 기록하며 Llama 3.3 70B보다 +6.40% 향상되었고, 사고 모드에서는 91.00%로 Deepseek R1 Distill 70B보다 +4.40% 향상되었습니다. Livebench 점수도 이러한 성과를 반영합니다.
14B 모델의 벤치마크는 중간 크기 비교를 위해 다음과 같습니다:
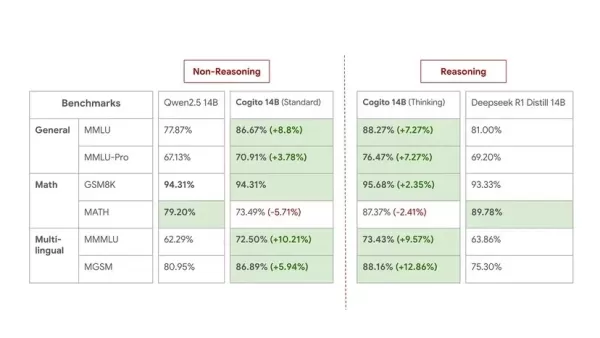
Deep Cogito는 벤치마크가 실세계 유용성을 완전히 포착하지 않는다고 인정하면서도, 모델의 실제 성능에 자신감을 나타냅니다. 이번 출시는 미리보기 단계로 간주되며, 회사는 "이 스케일링 곡선의 초기 단계에 있다"고 밝혔습니다. 그들은 현재 크기에 대한 개선된 체크포인트를 출시하고, 앞으로 몇 주와 몇 달 안에 더 큰 MoE 모델(109B, 400B, 671B)을 소개할 계획입니다. 모든 미래 모델도 오픈소스로 제공될 것입니다.
관련 기사
 카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
관련 특별 주제 추천
사업
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
관련 특별 주제 추천
사업
 최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
최고의 AI 채용 도구: 이력서 심사 및 후보자 면접 일정 자동화
XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
 10 도구
10 도구
 xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
xix.ai
생산력
AI 개인 웰니스 및 집중력 코치: 번아웃 관리 및 정신적 에너지 수준 향상
XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai
챗봇
최고 평점을 받은 AI 로맨틱 챗봇: 일관된 성격으로 장기적인 관계를 구축하세요
진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai
교육 및 학습
최고의 AI 데이터 과학 멘토들: SQL, Pandas 및 머신 러닝 워크플로우 마스터하기
2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai
챗봇
최고의 AI 유혹 및 대화 트레이너: 실시간으로 사회적 매력과 자신감을 높여보세요
XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai
암호
자동화된 단위 테스트를 위한 최고의 AI 도구들: 한 번의 클릭으로 Jest, PyTest, JUnit 테스트 케이스를 생성하세요.
2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai

 의견 (29)
0/500
의견 (29)
0/500
![FrankMoore]()
看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
![HenryJackson]()
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
![RoyWhite]()
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
![PaulThomas]()
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
![GregoryCarter]()
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
![EricRoberts]()
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
샌프란시스코에 본사를 둔 Deep Cogito는 최신 오픈 대규모 언어 모델(LLMs) 출시로 AI 커뮤니티에서 큰 반향을 일으키고 있습니다. 30억에서 700억 매개변수에 이르는 다양한 크기의 이 모델들은 단순한 AI 도구가 아니라, 회사가 "일반 초지능"이라고 부르는 대담한 발걸음입니다. Deep Cogito는 각 모델이 LLAMA, DeepSeek, Qwen의 유사한 크기의 선도적인 오픈 모델들을 대부분의 표준 벤치마크에서 능가한다고 주장합니다. 이는 상당한 주장인데, 더 인상적인 것은 그들의 70B 모델이 최근 출시된 Llama 4 109B Mixture-of-Experts (MoE) 모델을 능가했다는 보고입니다.
반복 증류 및 증폭 (IDA)
Deep Cogito의 획기적인 발전의 핵심에는 그들이 반복 증류 및 증폭(IDA)이라고 부르는 새로운 훈련 접근 방식이 있습니다. 이 방법은 "반복적 자기 개선을 통해 일반 초지능을 위한 확장 가능하고 효율적인 정렬 전략"으로 설명됩니다. 이는 전통적인 LLM 훈련의 한계를 넘어, 모델의 지능이 종종 더 큰 "감독자" 모델이나 인간 큐레이터에 의해 정의된 한계에 부딪히는 문제를 해결하도록 설계되었습니다.
IDA 프로세스는 반복적으로 수행되는 두 가지 주요 단계를 중심으로 이루어집니다:
- 증폭: 이 단계에서는 더 많은 컴퓨팅 파워를 사용하여 모델이 더 나은 솔루션이나 능력을 도출하도록 돕습니다. 이는 고급 추론 기술과 유사합니다.
- 증류: 여기서 모델은 이러한 향상된 능력을 내재화하여 매개변수를 정제합니다.
Deep Cogito는 이것이 "긍정적인 피드백 루프"를 만들어, 모델의 지능이 감독자의 지능에 의해 제한되지 않고 컴퓨팅 자원과 IDA 프로세스 자체의 효율성에 따라 더 직접적으로 성장할 수 있다고 주장합니다.
회사는 AlphaGo의 역사적 성공을 예로 들며, "고급 추론과 반복적 자기 개선"이 중요했다고 강조합니다. IDA는 이러한 요소를 LLM 훈련에 도입한다고 주장합니다. 또한 IDA의 효율성을 강조하며, 소규모 팀이 약 75일 만에 이 모델들을 개발했다고 밝혔습니다. 인간 피드백을 통한 강화 학습(RLHF)이나 더 큰 모델로부터의 표준 증류와 같은 다른 방법과 비교했을 때, IDA는 더 나은 확장성을 제공한다고 합니다.
증거로, Deep Cogito는 그들의 70B 모델이 Llama 3.3 70B(405B 모델에서 증류)와 Llama 4 Scout 109B(2T 매개변수 모델에서 증류)를 모두 능가한다고 강조합니다.
Deep Cogito 모델의 능력과 성능
Llama와 Qwen 체크포인트를 기반으로 구축된 새로운 Cogito 모델은 코딩, 함수 호출, 에이전트 애플리케이션에 맞춰져 있습니다. 두드러진 특징은 이중 기능성입니다: "각 모델은 직접 응답(표준 LLM)하거나 응답 전에 자기 성찰(추론 모델과 유사)할 수 있습니다." 이는 Claude 3.5와 같은 모델에서 볼 수 있는 능력을 반영합니다. 그러나 Deep Cogito는 매우 긴 추론 체인에 초점을 맞추지 않고, 더 빠른 응답과 더 짧은 체인의 증류 효율성을 우선시했다고 언급했습니다.
회사는 Cogito 모델을 직접 및 추론 모드에서 크기가 비슷한 최첨단 오픈 모델들과 비교한 광범위한 벤치마크 결과를 공유했습니다. MMLU, MMLU-Pro, ARC, GSM8K, MATH와 같은 다양한 벤치마크와 3B, 8B, 14B, 32B, 70B의 다양한 모델 크기에서 Cogito 모델은 일반적으로 상당한 성능 향상을 보여줍니다. 예를 들어, Cogito 70B 모델은 표준 모드에서 MMLU에서 91.73%를 기록하며 Llama 3.3 70B보다 +6.40% 향상되었고, 사고 모드에서는 91.00%로 Deepseek R1 Distill 70B보다 +4.40% 향상되었습니다. Livebench 점수도 이러한 성과를 반영합니다.
14B 모델의 벤치마크는 중간 크기 비교를 위해 다음과 같습니다:
Deep Cogito는 벤치마크가 실세계 유용성을 완전히 포착하지 않는다고 인정하면서도, 모델의 실제 성능에 자신감을 나타냅니다. 이번 출시는 미리보기 단계로 간주되며, 회사는 "이 스케일링 곡선의 초기 단계에 있다"고 밝혔습니다. 그들은 현재 크기에 대한 개선된 체크포인트를 출시하고, 앞으로 몇 주와 몇 달 안에 더 큰 MoE 모델(109B, 400B, 671B)을 소개할 계획입니다. 모든 미래 모델도 오픈소스로 제공될 것입니다.









 카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
카카오 모빌리티, 물리적 AI를 위한 레벨 4 자율주행 로드맵 제시
카카오모빌리티는 물리적 AI 전략의 일환으로 레벨 4 자율주행 기술을 자체 개발할 계획이다.서울 코엑스에서 열린 '2026 월드 IT 쇼' 컨퍼런스에서 카카오모빌리티의 김진규 부사장 겸 피지컬 AI 사업본부장은 로드맵을 발표했다. 그의 발표는 피지컬 AI 시대의 모빌리티 플랫폼을 기반으로 한 자율주행 서비스에 중점을 두었다.연합뉴스에 따르면, '아이디어
 배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
배리 딜러: AGI 시대가 다가옴에 따라 샘 알트먼에 대한 신뢰는 무의미하다
억만장자 미디어 거물 배리 딜러는 최근 보도에서 달리 제기된 주장에도 불구하고, 오픈AI의 샘 알트만 CEO가 신뢰할 수 없는 인물이라고 생각하지 않는다고 밝혔다. 이번 주 월스트리트저널(WSJ)이 주최한 ‘Future of Everything’ 컨퍼런스에서 연설한 딜러는, 일부 전직 동료들과 이사회 구성원들로부터 때때로 교묘하게 조종하거나 기만적이라는 비
 유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의
유튜브, 정치인·공직자·언론인을 대상으로 AI 딥페이크 탐지 기능 확대
화요일, 유튜브는 딥페이크 탐지 기술을 일부 정부 관계자, 정치 후보자 및 언론인 대상으로 확대한다고 발표했다. 이 도구는 AI로 생성된 유사 영상을 식별하며, 시범 운영 참여자들은 유튜브 정책을 위반한다고 판단되는 무단 콘텐츠의 삭제를 요청할 수 있다.이 탐지 시스템은 초기 테스트 단계를 거친 후, 작년 유튜브 파트너 프로그램에 가입된 약 400만 명의

XIX.AI에서 2026년 최신 최고 평점을 받은 AI 채용 도구를 확인해 보세요. 저희가 엄선한 이 목록에는 이력서 심사 및 후보자 면접 일정 자동화를 위한 강력하고 혁신적인 솔루션이 포함되어 있습니다. 실제 테스트 결과와 매주 업데이트되는 순위를 바탕으로 무료 및 유료 옵션을 비교해 보세요. 지금 바로 귀사에 딱 맞는 채용 도우미를 찾아 채용 프로세스를 효율화하세요!
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 기반 개인 웰니스 및 집중력 코치들을 만나보세요. 저희가 엄선한 순위 목록에는 번아웃을 관리하고 정신적 에너지를 높여주는 최고 평점을 받은 혁신적인 도구들이 소개되어 있습니다. 실제 사용 후기를 바탕으로 무료 버전과 유료 버전을 비교해 보세요. 지금 바로 최고의 생산성과 웰빙을 향한 길을 열어보세요.
10 도구
xix.ai

진정성 있는 장기적인 관계를 형성할 수 있는 2026년 최신 최고 평점 AI 로맨틱 챗봇을 만나보세요. 저희가 엄선한 이 목록에는 강력하고 일관된 캐릭터, 무료 및 유료 버전 비교, 실제 사용 후기가 담겨 있습니다. XIX.AI에서 나에게 딱 맞는 파트너를 찾아 오늘 바로 관계를 시작해 보세요.
10 도구
xix.ai

2026년 최고의 AI 데이터 과학 멘토들을 만나 SQL, Pandas 및 머신러닝 워크플로우를 마스터하세요. XIX.AI에서 선별한 최고의 멘토들을 통해 강력하고 혁신적인 지도를 받아보세요. 무료 옵션과 유료 옵션을 실제 사례를 바탕으로 비교해 보세요. 오늘 바로 데이터 과학의 전문성을 확보하세요.
10 도구
xix.ai

XIX.AI에서 2026년 최고의 AI 플러팅 및 대화 트레이너를 만나보세요. 엄선된 최고 평점의 제품들을 통해 실시간으로 사회적 매력과 자신감을 키울 수 있습니다. 무료와 유료 버전을 비교하고 매주 업데이트되는 순위를 확인하며, 꼭 사용해봐야 할 획기적인 도구들을 탐색해 보세요. 지금 바로 여러분의 사회적 경쟁력을 한 단계 높여보세요.
10 도구
xix.ai

2026년에 출시된 최신이자 가장 높은 평가를 받는 AI 도구들을 만나보세요. 저희가 엄선한 이 도구들은 Jest, PyTest, JUnit 테스트 케이스를 즉시 생성할 수 있게 해주는 강력하고 혁신적인 솔루션들을 제공합니다. XIX.AI에서 무료 옵션과 유료 옵션을 실제 테스트 결과와 함께 비교해보시고, 매주 업데이트되는 순위를 확인해보세요. 지금 바로 AI의 장점을 활용하여 개발 생산성을 높이세요.
10 도구
xix.ai

看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡













