




Deep Cogito的LLMS使用IDA優於類似大小的模型
Deep Cogito,一家總部位於舊金山的企業,正在人工智慧社群中掀起波瀾,其最新發布的開放大型語言模型(LLMs)備受矚目。這些模型參數規模從30億到700億不等,不僅僅是另一組AI工具;它們是該公司所稱的「通用超級智能」的重要一步。Deep Cogito聲稱,其每個模型在大多數標準基準測試中均超越同等規模的領先開放模型,包括來自LLAMA、DeepSeek和Qwen的模型。這是一個相當大的主張,但更令人印象深刻的是,他們的700億參數模型據報在性能上超越了最近發布的Llama 4 109B混合專家(MoE)模型。
迭代蒸餾與放大(IDA)
Deep Cogito的突破核心在於一種他們稱為迭代蒸餾與放大(IDA)的新訓練方法。該方法被描述為「一種可擴展且高效的通用超級智能對齊策略,通過迭代自我改進實現」。它旨在突破傳統LLM訓練的限制,在傳統方法中,模型的智能通常受到較大的「監督者」模型或人類策展者的上限限制。
IDA過程圍繞兩個反覆進行的關鍵步驟:
- 放大:此步驟利用更多計算能力幫助模型提出更好的解決方案或能力,類似於高級推理技術。
- 蒸餾:在此,模型內化這些改進的能力,優化其參數。
Deep Cogito認為,這創造了一個「正向反饋循環」,使模型的智能能夠隨著計算資源和IDA過程本身的效率更直接地增長,而不受監督者智能的限制。
該公司指出像AlphaGo這樣的歷史成功案例,強調「高級推理和迭代自我改進」至關重要。他們聲稱,IDA將這些元素引入LLM訓練。他們還強調IDA的效率,指出他們的小型團隊僅用大約75天就開發出這些模型。與其他方法如基於人類反饋的強化學習(RLHF)或從較大模型的標準蒸餾相比,IDA據稱提供更好的可擴展性。
作為證明,Deep Cogito強調其700億參數模型在性能上超越了Llama 3.3 70B(從405B模型蒸餾)和Llama 4 Scout 109B(從2T參數模型蒸餾)。
Deep Cogito模型的能力與性能
新的Cogito模型以Llama和Qwen檢查點為基礎,專為編碼、函數調用和代理應用量身定制。一個突出特點是它們的雙重功能:「每個模型都可以直接回答(標準LLM),或在回答前進行自我反思(類似推理模型)」。這與Claude 3.5等模型的功能相似。然而,Deep Cogito提到他們尚未專注於非常長的推理鏈,優先考慮更快的回答和蒸餾較短鏈的效率。
該公司分享了廣泛的基準測試結果,將其Cogito模型與同等規模的最新開放模型在直接和推理模式下進行比較。在MMLU、MMLU-Pro、ARC、GSM8K和MATH等一系列基準測試中,以及不同模型規模(3B、8B、14B、32B、70B)中,Cogito模型通常顯示出顯著的性能提升。例如,Cogito 70B模型在標準模式下的MMLU得分為91.73%,比Llama 3.3 70B提高+6.40%,在思考模式下得分為91.00%,比Deepseek R1 Distill 70B提高+4.40%。Livebench得分也反映了這些進展。
以下是14B模型的基準測試,用於中等規模比較:
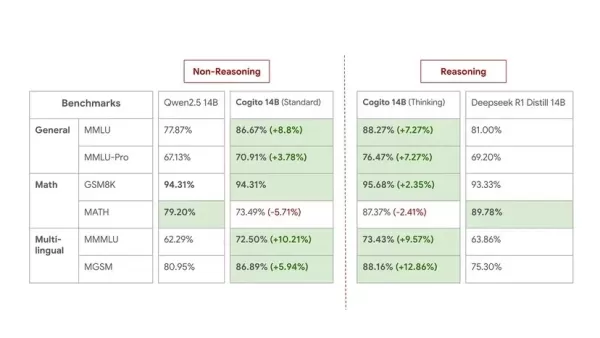
雖然Deep Cogito承認基準測試無法完全反映現實世界的實用性,但他們對模型的實際性能仍充滿信心。此次發布被視為預覽,公司表示他們「仍處於這一擴展曲線的早期階段」。他們計劃在未來幾週和幾個月內發布當前規模的改進檢查點,並引入更大的MoE模型(109B、400B、671B)。所有未來模型也將是開源的。
相關文章
 川普將人工智慧的成長優先於管制,爭取超越中國
川普政府於週三公佈了具有里程碑意義的「人工智慧行動計畫」,標誌著與拜登政府迴避風險的人工智慧政策的決裂。這份雄心勃勃的藍圖將積極發展基礎設施、全面放寬監管、加強國家安全措施以及與中國在人工智能領域的戰略競爭放在首位。政策的轉變可能會對經濟和社會產生廣泛的影響,特別是在能源使用和環境法規方面。政府建議擴大資料中心建設,包括在聯邦土地上,同時可能放寬能源需求高峰期的環境保護,這些決定可能會影響產業和消
YouTube 將 Veo 3 AI 視訊工具直接整合至短片平台
YouTube Shorts 今年夏天將採用 Veo 3 AI 視訊模型YouTube 執行長 Neal Mohan 在坎城獅子獎主題演講中透露,該平台最尖端的 Veo 3 AI 影片生成技術將於今年夏天稍後在 YouTube Shorts 上亮相。在此之前,Allison Johnson 曾發表評論,將 Veo 3 描述為 AI 輔助內容創作的革命。目前,Shorts 製作人員透過 Dream
Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
評論 (27)
0/200
川普將人工智慧的成長優先於管制,爭取超越中國
川普政府於週三公佈了具有里程碑意義的「人工智慧行動計畫」,標誌著與拜登政府迴避風險的人工智慧政策的決裂。這份雄心勃勃的藍圖將積極發展基礎設施、全面放寬監管、加強國家安全措施以及與中國在人工智能領域的戰略競爭放在首位。政策的轉變可能會對經濟和社會產生廣泛的影響,特別是在能源使用和環境法規方面。政府建議擴大資料中心建設,包括在聯邦土地上,同時可能放寬能源需求高峰期的環境保護,這些決定可能會影響產業和消
YouTube 將 Veo 3 AI 視訊工具直接整合至短片平台
YouTube Shorts 今年夏天將採用 Veo 3 AI 視訊模型YouTube 執行長 Neal Mohan 在坎城獅子獎主題演講中透露,該平台最尖端的 Veo 3 AI 影片生成技術將於今年夏天稍後在 YouTube Shorts 上亮相。在此之前,Allison Johnson 曾發表評論,將 Veo 3 描述為 AI 輔助內容創作的革命。目前,Shorts 製作人員透過 Dream
Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
評論 (27)
0/200
![RoyWhite]() RoyWhite
RoyWhite
 2025-08-13 17:00:59
2025-08-13 17:00:59
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀


 0
0
![PaulThomas]() PaulThomas
2025-08-07 03:01:00
PaulThomas
2025-08-07 03:01:00
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
0
![GregoryCarter]() GregoryCarter
2025-04-21 11:16:16
GregoryCarter
2025-04-21 11:16:16
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
0
![EricRoberts]() EricRoberts
2025-04-20 12:40:17
EricRoberts
2025-04-20 12:40:17
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
0
![WillieAnderson]() WillieAnderson
2025-04-20 12:09:03
WillieAnderson
2025-04-20 12:09:03
딥 코기토의 LLM은 정말 혁신적이에요! 비슷한 크기의 모델과 비교해도 성능 향상이 놀랍습니다. IDA 접근법이 큰 차이를 만듭니다. 유일한 단점은 학습 곡선인데, 한번 익숙해지면 문제없어요! 🚀
0
![EricKing]() EricKing
2025-04-20 06:12:37
EricKing
2025-04-20 06:12:37
Deep Cogito's LLMs are impressive, but the app could use a better UI. It's a bit clunky to navigate through the different model sizes. Still, the performance is top-notch, especially with the IDA tech. Definitely worth a look if you're into AI and want to see what's possible with large language models! 🤖💡
0
Deep Cogito,一家總部位於舊金山的企業,正在人工智慧社群中掀起波瀾,其最新發布的開放大型語言模型(LLMs)備受矚目。這些模型參數規模從30億到700億不等,不僅僅是另一組AI工具;它們是該公司所稱的「通用超級智能」的重要一步。Deep Cogito聲稱,其每個模型在大多數標準基準測試中均超越同等規模的領先開放模型,包括來自LLAMA、DeepSeek和Qwen的模型。這是一個相當大的主張,但更令人印象深刻的是,他們的700億參數模型據報在性能上超越了最近發布的Llama 4 109B混合專家(MoE)模型。
迭代蒸餾與放大(IDA)
Deep Cogito的突破核心在於一種他們稱為迭代蒸餾與放大(IDA)的新訓練方法。該方法被描述為「一種可擴展且高效的通用超級智能對齊策略,通過迭代自我改進實現」。它旨在突破傳統LLM訓練的限制,在傳統方法中,模型的智能通常受到較大的「監督者」模型或人類策展者的上限限制。
IDA過程圍繞兩個反覆進行的關鍵步驟:
- 放大:此步驟利用更多計算能力幫助模型提出更好的解決方案或能力,類似於高級推理技術。
- 蒸餾:在此,模型內化這些改進的能力,優化其參數。
Deep Cogito認為,這創造了一個「正向反饋循環」,使模型的智能能夠隨著計算資源和IDA過程本身的效率更直接地增長,而不受監督者智能的限制。
該公司指出像AlphaGo這樣的歷史成功案例,強調「高級推理和迭代自我改進」至關重要。他們聲稱,IDA將這些元素引入LLM訓練。他們還強調IDA的效率,指出他們的小型團隊僅用大約75天就開發出這些模型。與其他方法如基於人類反饋的強化學習(RLHF)或從較大模型的標準蒸餾相比,IDA據稱提供更好的可擴展性。
作為證明,Deep Cogito強調其700億參數模型在性能上超越了Llama 3.3 70B(從405B模型蒸餾)和Llama 4 Scout 109B(從2T參數模型蒸餾)。
Deep Cogito模型的能力與性能
新的Cogito模型以Llama和Qwen檢查點為基礎,專為編碼、函數調用和代理應用量身定制。一個突出特點是它們的雙重功能:「每個模型都可以直接回答(標準LLM),或在回答前進行自我反思(類似推理模型)」。這與Claude 3.5等模型的功能相似。然而,Deep Cogito提到他們尚未專注於非常長的推理鏈,優先考慮更快的回答和蒸餾較短鏈的效率。
該公司分享了廣泛的基準測試結果,將其Cogito模型與同等規模的最新開放模型在直接和推理模式下進行比較。在MMLU、MMLU-Pro、ARC、GSM8K和MATH等一系列基準測試中,以及不同模型規模(3B、8B、14B、32B、70B)中,Cogito模型通常顯示出顯著的性能提升。例如,Cogito 70B模型在標準模式下的MMLU得分為91.73%,比Llama 3.3 70B提高+6.40%,在思考模式下得分為91.00%,比Deepseek R1 Distill 70B提高+4.40%。Livebench得分也反映了這些進展。
以下是14B模型的基準測試,用於中等規模比較:
雖然Deep Cogito承認基準測試無法完全反映現實世界的實用性,但他們對模型的實際性能仍充滿信心。此次發布被視為預覽,公司表示他們「仍處於這一擴展曲線的早期階段」。他們計劃在未來幾週和幾個月內發布當前規模的改進檢查點,並引入更大的MoE模型(109B、400B、671B)。所有未來模型也將是開源的。










 川普將人工智慧的成長優先於管制,爭取超越中國
川普政府於週三公佈了具有里程碑意義的「人工智慧行動計畫」,標誌著與拜登政府迴避風險的人工智慧政策的決裂。這份雄心勃勃的藍圖將積極發展基礎設施、全面放寬監管、加強國家安全措施以及與中國在人工智能領域的戰略競爭放在首位。政策的轉變可能會對經濟和社會產生廣泛的影響,特別是在能源使用和環境法規方面。政府建議擴大資料中心建設,包括在聯邦土地上,同時可能放寬能源需求高峰期的環境保護,這些決定可能會影響產業和消
川普將人工智慧的成長優先於管制,爭取超越中國
川普政府於週三公佈了具有里程碑意義的「人工智慧行動計畫」,標誌著與拜登政府迴避風險的人工智慧政策的決裂。這份雄心勃勃的藍圖將積極發展基礎設施、全面放寬監管、加強國家安全措施以及與中國在人工智能領域的戰略競爭放在首位。政策的轉變可能會對經濟和社會產生廣泛的影響,特別是在能源使用和環境法規方面。政府建議擴大資料中心建設,包括在聯邦土地上,同時可能放寬能源需求高峰期的環境保護,這些決定可能會影響產業和消
 YouTube 將 Veo 3 AI 視訊工具直接整合至短片平台
YouTube Shorts 今年夏天將採用 Veo 3 AI 視訊模型YouTube 執行長 Neal Mohan 在坎城獅子獎主題演講中透露,該平台最尖端的 Veo 3 AI 影片生成技術將於今年夏天稍後在 YouTube Shorts 上亮相。在此之前,Allison Johnson 曾發表評論,將 Veo 3 描述為 AI 輔助內容創作的革命。目前,Shorts 製作人員透過 Dream
YouTube 將 Veo 3 AI 視訊工具直接整合至短片平台
YouTube Shorts 今年夏天將採用 Veo 3 AI 視訊模型YouTube 執行長 Neal Mohan 在坎城獅子獎主題演講中透露,該平台最尖端的 Veo 3 AI 影片生成技術將於今年夏天稍後在 YouTube Shorts 上亮相。在此之前,Allison Johnson 曾發表評論,將 Veo 3 描述為 AI 輔助內容創作的革命。目前,Shorts 製作人員透過 Dream
 Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
2025-08-13 17:00:59
Google Cloud 為科學研究與發現的突破提供動力
數位革命正透過前所未有的計算能力改變科學方法。尖端技術現在可增強理論框架和實驗室實驗,透過精密模擬和大數據分析,推動各學科的突破。透過策略性地投資於基礎研究、可擴充的雲端架構和人工智慧開發,我們建立了一個加速科學進步的生態系統。我們的貢獻橫跨醫藥研究、氣候建模和奈米技術等領域的突破性創新,並輔以世界級的運算基礎架構、雲端原生軟體解決方案和新一代的生成式人工智慧平台。Google DeepMind
2025-08-13 17:00:59
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
0
2025-08-07 03:01:00
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
0
2025-04-21 11:16:16
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
0
2025-04-20 12:40:17
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
0
2025-04-20 12:09:03
딥 코기토의 LLM은 정말 혁신적이에요! 비슷한 크기의 모델과 비교해도 성능 향상이 놀랍습니다. IDA 접근법이 큰 차이를 만듭니다. 유일한 단점은 학습 곡선인데, 한번 익숙해지면 문제없어요! 🚀
0
2025-04-20 06:12:37
Deep Cogito's LLMs are impressive, but the app could use a better UI. It's a bit clunky to navigate through the different model sizes. Still, the performance is top-notch, especially with the IDA tech. Definitely worth a look if you're into AI and want to see what's possible with large language models! 🤖💡
0













