
















 Heim
HeimDie LLMs von Deep Cogito übertreffen ähnliche Modelle mit ähnlicher Größe mit IDA
Deep Cogito, ein in San Francisco ansässiges Unternehmen, sorgt in der AI-Community für Aufsehen mit seiner neuesten Veröffentlichung von offenen großen Sprachmodellen (LLMs). Diese Modelle, die in verschiedenen Größen von 3 Milliarden bis 70 Milliarden Parametern reichen, sind nicht nur ein weiterer Satz von AI-Tools; sie sind ein mutiger Schritt hin zu dem, was das Unternehmen „allgemeine Superintelligenz“ nennt. Deep Cogito behauptet, dass jedes ihrer Modelle die führenden offenen Modelle ähnlicher Größe, einschließlich derer von LLAMA, DeepSeek und Qwen, in den meisten Standard-Benchmarks übertrifft. Das ist eine beachtliche Behauptung, aber noch beeindruckender ist, dass ihr 70B-Modell Berichten zufolge das kürzlich veröffentlichte Llama 4 109B Mixture-of-Experts (MoE)-Modell übertrumpft hat.
Iterierte Destillation und Amplifikation (IDA)
Das Herzstück des Durchbruchs von Deep Cogito ist ein neuer Trainingsansatz, den sie Iterierte Destillation und Amplifikation (IDA) nennen. Diese Methode wird als „skalierbare und effiziente Ausrichtungsstrategie für allgemeine Superintelligenz durch iterative Selbstverbesserung“ beschrieben. Sie ist darauf ausgelegt, die Grenzen des traditionellen LLM-Trainings zu überwinden, bei dem die Intelligenz des Modells oft an eine Obergrenze stößt, die durch größere „Überwacher“-Modelle oder menschliche Kuratoren definiert ist.
Der IDA-Prozess dreht sich um zwei wesentliche Schritte, die immer wieder wiederholt werden:
- Amplifikation: Dieser Schritt nutzt mehr Rechenleistung, um dem Modell zu helfen, bessere Lösungen oder Fähigkeiten zu entwickeln, ähnlich wie fortschrittliche Denktechniken.
- Destillation: Hier verinnerlicht das Modell diese verbesserten Fähigkeiten und verfeinert seine Parameter.
Deep Cogito argumentiert, dass dies eine „positive Rückkopplungsschleife“ schafft, die es der Intelligenz des Modells ermöglicht, direkter mit den Rechenressourcen und der Effizienz des IDA-Prozesses selbst zu wachsen, anstatt durch die Intelligenz eines Überwachers begrenzt zu sein.
Das Unternehmen verweist auf historische Erfolge wie AlphaGo und betont, dass „fortschrittliches Denken und iterative Selbstverbesserung“ entscheidend waren. IDA, so behaupten sie, bringt diese Elemente in das LLM-Training. Sie preisen auch die Effizienz von IDA und stellen fest, dass ihr kleines Team es geschafft hat, diese Modelle in nur etwa 75 Tagen zu entwickeln. Im Vergleich zu anderen Methoden wie Reinforcement Learning from Human Feedback (RLHF) oder Standard-Destillation von größeren Modellen soll IDA eine bessere Skalierbarkeit bieten.
Als Beweis hebt Deep Cogito hervor, wie ihr 70B-Modell sowohl Llama 3.3 70B (destilliert aus einem 405B-Modell) als auch Llama 4 Scout 109B (destilliert aus einem 2T-Parameter-Modell) übertrifft.
Fähigkeiten und Leistung der Deep Cogito-Modelle
Die neuen Cogito-Modelle, die auf Llama- und Qwen-Checkpoints aufbauen, sind auf Codierung, Funktionsaufrufe und agentische Anwendungen zugeschnitten. Ein herausragendes Merkmal ist ihre doppelte Funktionalität: „Jedes Modell kann direkt antworten (Standard-LLM) oder vor der Antwort selbst reflektieren (wie Denkmodelle).“ Dies spiegelt Fähigkeiten wider, die in Modellen wie Claude 3.5 zu sehen sind. Deep Cogito erwähnt jedoch, dass sie sich nicht auf sehr lange Denkketten konzentriert haben, sondern schnelle Antworten und die Effizienz der Destillation kürzerer Ketten priorisieren.
Das Unternehmen hat umfassende Benchmark-Ergebnisse geteilt, in denen ihre Cogito-Modelle mit gleich großen, modernen offenen Modellen sowohl im direkten als auch im Denkmodus verglichen werden. Über eine Reihe von Benchmarks wie MMLU, MMLU-Pro, ARC, GSM8K und MATH und über verschiedene Modellgrößen (3B, 8B, 14B, 32B, 70B) zeigen die Cogito-Modelle allgemein signifikante Leistungsverbesserungen. Zum Beispiel erzielt das Cogito 70B-Modell im Standardmodus 91,73 % bei MMLU, eine Verbesserung von +6,40 % gegenüber Llama 3.3 70B, und 91,00 % im Denkmodus, eine Steigerung von +4,40 % gegenüber Deepseek R1 Distill 70B. Livebench-Werte spiegeln diese Gewinne ebenfalls wider.
Hier sind Benchmarks von 14B-Modellen für einen Vergleich mittlerer Größe:
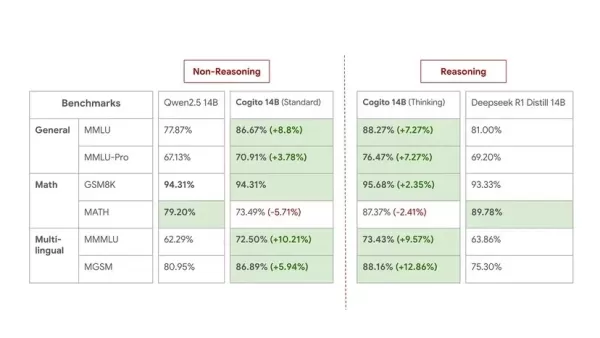
Während Deep Cogito anerkennt, dass Benchmarks nicht die volle praktische Nützlichkeit erfassen, bleiben sie zuversichtlich in die praktische Leistung ihrer Modelle. Diese Veröffentlichung gilt als Vorschau, wobei das Unternehmen angibt, dass sie „noch in den frühen Stadien dieser Skalierungskurve“ stehen. Sie planen, verbesserte Checkpoints für die aktuellen Größen zu veröffentlichen und in den kommenden Wochen und Monaten größere MoE-Modelle (109B, 400B, 671B) einzuführen. Alle zukünftigen Modelle werden ebenfalls Open-Source sein.
Verwandter Artikel
 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon
Empfehlungen zu verwandten Spezialthemen
Geschäft
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon
Empfehlungen zu verwandten Spezialthemen
Geschäft
 Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenabrechnungsprogramme: Quittungen scannen und Geschäftsausgaben automatisch kategorisieren
Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
 10 Tools
10 Tools
 xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
xix.ai
Geschäft
Die besten KI-Tools für die Personalbeschaffung: Lebensläufe prüfen und die Terminplanung für Vorstellungsgespräche automatisieren
Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai
Produktivität
KI-Coaches für persönliches Wohlbefinden und Konzentration: Burnout bewältigen und die geistige Energie steigern
Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai
Chatbot
Die besten KI-basierten Romantik-Chatbots: Bauen Sie langfristige Beziehungen mit beständiger Persönlichkeit auf
Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai
Bildung und Lernen
Die besten AI-Datenwissenschafts-Mentoren: Beherrschen Sie SQL, Pandas und Arbeitsabläufe für maschinelles Lernen.
Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai
Chatbot
Die besten KI-Flirt- und Konversationstrainer: Steigere dein soziales Charisma und dein Selbstvertrauen in Echtzeit
Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

 Kommentare (29)
Kommentare (29)
![FrankMoore]()
看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
![HenryJackson]()
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
![RoyWhite]()
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
![PaulThomas]()
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
![GregoryCarter]()
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
![EricRoberts]()
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
Deep Cogito, ein in San Francisco ansässiges Unternehmen, sorgt in der AI-Community für Aufsehen mit seiner neuesten Veröffentlichung von offenen großen Sprachmodellen (LLMs). Diese Modelle, die in verschiedenen Größen von 3 Milliarden bis 70 Milliarden Parametern reichen, sind nicht nur ein weiterer Satz von AI-Tools; sie sind ein mutiger Schritt hin zu dem, was das Unternehmen „allgemeine Superintelligenz“ nennt. Deep Cogito behauptet, dass jedes ihrer Modelle die führenden offenen Modelle ähnlicher Größe, einschließlich derer von LLAMA, DeepSeek und Qwen, in den meisten Standard-Benchmarks übertrifft. Das ist eine beachtliche Behauptung, aber noch beeindruckender ist, dass ihr 70B-Modell Berichten zufolge das kürzlich veröffentlichte Llama 4 109B Mixture-of-Experts (MoE)-Modell übertrumpft hat.
Iterierte Destillation und Amplifikation (IDA)
Das Herzstück des Durchbruchs von Deep Cogito ist ein neuer Trainingsansatz, den sie Iterierte Destillation und Amplifikation (IDA) nennen. Diese Methode wird als „skalierbare und effiziente Ausrichtungsstrategie für allgemeine Superintelligenz durch iterative Selbstverbesserung“ beschrieben. Sie ist darauf ausgelegt, die Grenzen des traditionellen LLM-Trainings zu überwinden, bei dem die Intelligenz des Modells oft an eine Obergrenze stößt, die durch größere „Überwacher“-Modelle oder menschliche Kuratoren definiert ist.
Der IDA-Prozess dreht sich um zwei wesentliche Schritte, die immer wieder wiederholt werden:
- Amplifikation: Dieser Schritt nutzt mehr Rechenleistung, um dem Modell zu helfen, bessere Lösungen oder Fähigkeiten zu entwickeln, ähnlich wie fortschrittliche Denktechniken.
- Destillation: Hier verinnerlicht das Modell diese verbesserten Fähigkeiten und verfeinert seine Parameter.
Deep Cogito argumentiert, dass dies eine „positive Rückkopplungsschleife“ schafft, die es der Intelligenz des Modells ermöglicht, direkter mit den Rechenressourcen und der Effizienz des IDA-Prozesses selbst zu wachsen, anstatt durch die Intelligenz eines Überwachers begrenzt zu sein.
Das Unternehmen verweist auf historische Erfolge wie AlphaGo und betont, dass „fortschrittliches Denken und iterative Selbstverbesserung“ entscheidend waren. IDA, so behaupten sie, bringt diese Elemente in das LLM-Training. Sie preisen auch die Effizienz von IDA und stellen fest, dass ihr kleines Team es geschafft hat, diese Modelle in nur etwa 75 Tagen zu entwickeln. Im Vergleich zu anderen Methoden wie Reinforcement Learning from Human Feedback (RLHF) oder Standard-Destillation von größeren Modellen soll IDA eine bessere Skalierbarkeit bieten.
Als Beweis hebt Deep Cogito hervor, wie ihr 70B-Modell sowohl Llama 3.3 70B (destilliert aus einem 405B-Modell) als auch Llama 4 Scout 109B (destilliert aus einem 2T-Parameter-Modell) übertrifft.
Fähigkeiten und Leistung der Deep Cogito-Modelle
Die neuen Cogito-Modelle, die auf Llama- und Qwen-Checkpoints aufbauen, sind auf Codierung, Funktionsaufrufe und agentische Anwendungen zugeschnitten. Ein herausragendes Merkmal ist ihre doppelte Funktionalität: „Jedes Modell kann direkt antworten (Standard-LLM) oder vor der Antwort selbst reflektieren (wie Denkmodelle).“ Dies spiegelt Fähigkeiten wider, die in Modellen wie Claude 3.5 zu sehen sind. Deep Cogito erwähnt jedoch, dass sie sich nicht auf sehr lange Denkketten konzentriert haben, sondern schnelle Antworten und die Effizienz der Destillation kürzerer Ketten priorisieren.
Das Unternehmen hat umfassende Benchmark-Ergebnisse geteilt, in denen ihre Cogito-Modelle mit gleich großen, modernen offenen Modellen sowohl im direkten als auch im Denkmodus verglichen werden. Über eine Reihe von Benchmarks wie MMLU, MMLU-Pro, ARC, GSM8K und MATH und über verschiedene Modellgrößen (3B, 8B, 14B, 32B, 70B) zeigen die Cogito-Modelle allgemein signifikante Leistungsverbesserungen. Zum Beispiel erzielt das Cogito 70B-Modell im Standardmodus 91,73 % bei MMLU, eine Verbesserung von +6,40 % gegenüber Llama 3.3 70B, und 91,00 % im Denkmodus, eine Steigerung von +4,40 % gegenüber Deepseek R1 Distill 70B. Livebench-Werte spiegeln diese Gewinne ebenfalls wider.
Hier sind Benchmarks von 14B-Modellen für einen Vergleich mittlerer Größe:
Während Deep Cogito anerkennt, dass Benchmarks nicht die volle praktische Nützlichkeit erfassen, bleiben sie zuversichtlich in die praktische Leistung ihrer Modelle. Diese Veröffentlichung gilt als Vorschau, wobei das Unternehmen angibt, dass sie „noch in den frühen Stadien dieser Skalierungskurve“ stehen. Sie planen, verbesserte Checkpoints für die aktuellen Größen zu veröffentlichen und in den kommenden Wochen und Monaten größere MoE-Modelle (109B, 400B, 671B) einzuführen. Alle zukünftigen Modelle werden ebenfalls Open-Source sein.










 WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
WordPress.com ermöglicht es nun KI-Agenten, Beiträge zu verfassen und zu veröffentlichen – und vieles mehr
WordPress.com, die beliebte Webhosting- und Publishing-Plattform, setzt nun auf KI-Agenten – ein Schritt, der das Erscheinungsbild des Internets grundlegend verändern könnte. Das Unternehmen gab am Fr
Kakao Mobility stellt einen Fahrplan für autonomes Fahren der Stufe 4 im Bereich der physischen KI vor
Kakao Mobility plant, im Rahmen seiner Strategie für physische KI Technologien für autonomes Fahren der Stufe 4 intern zu entwickeln.Auf der Konferenz „World IT Show 2026“ im COEX in Seoul stellte Ki
 Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon
Barry Diller: Das Vertrauen in Sam Altman spielt keine Rolle, da die allgemeine künstliche Intelligenz (AGI) immer näher rückt
Barry Diller, der milliardenschwere Medienmogul, hält OpenAI-CEO Sam Altman nicht für unglaubwürdig, obwohl jüngste Berichte das Gegenteil nahelegen. Bei seiner Rede auf der „Future of Everything“-Kon

Die besten KI-basierten Spesenmanager 2026: Erstklassige Tools zum Scannen von Belegen und zur automatischen Kategorisierung von Unternehmensausgaben. Entdecken Sie leistungsstarke, bahnbrechende Lösungen für müheloses Spesenmanagement, präzise Finanzüberwachung und optimierte Compliance. Unser sorgfältig zusammengestellter, wöchentlich aktualisierter Vergleich zwischen kostenlosen und kostenpflichtigen Optionen hilft Ihnen dabei, die perfekte Lösung zu finden. Nutzen Sie Ihren KI-Vorteil mit den Expertenempfehlungen von XIX.AI.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Tools für die Personalbeschaffung des Jahres 2026. Unsere sorgfältig zusammengestellte Liste umfasst leistungsstarke, bahnbrechende Lösungen für die Sichtung von Lebensläufen und die automatisierte Terminplanung für Vorstellungsgespräche. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Praxistests und wöchentlich aktualisierten Rankings. Finden Sie Ihren perfekten Assistenten für die Personalbeschaffung und optimieren Sie noch heute Ihren Rekrutierungsprozess!
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-basierten Coaches für persönliches Wohlbefinden und Konzentration des Jahres 2026. Unsere sorgfältig zusammengestellte Rangliste umfasst erstklassige, bahnbrechende Tools zur Bewältigung von Burnout und zur Steigerung der mentalen Energie. Vergleichen Sie kostenlose und kostenpflichtige Optionen anhand von Erfahrungsberichten aus der Praxis. Schlagen Sie noch heute den Weg zu höchster Produktivität und Wohlbefinden ein.
10 Tools
xix.ai

Entdecken Sie die besten KI-Romantik-Chatbots des Jahres 2026, mit denen Sie echte, langfristige Beziehungen aufbauen können. Unsere sorgfältig zusammengestellte Liste bietet Ihnen überzeugende, konsistente Persönlichkeiten, Vergleiche zwischen kostenlosen und kostenpflichtigen Angeboten sowie Tests aus der Praxis. Finden Sie Ihren perfekten Begleiter und legen Sie noch heute bei XIX.AI los.
10 Tools
xix.ai

Entdecken Sie die besten AI-Data-Science-Mentoren von 2026, um SQL, Pandas und ML-Arbeitsabläufe zu meistern. Erfahren Sie mehr über unsere hochbewerteten, sorgfältig ausgewählten Angebote bei XIX.AI – für effektive und bahnbrechende Anleitung. Vergleichen Sie kostenlose und bezahlte Optionen mit praktischen Einblicken aus der Praxis. Entfalten Sie Ihr Potenzial in der Data Science noch heute.
10 Tools
xix.ai

Entdecken Sie auf XIX.AI die besten KI-Flirt- und Konversationstrainer des Jahres 2026. Unsere sorgfältig zusammengestellte, erstklassige Auswahl hilft Ihnen dabei, Ihr soziales Charisma und Ihr Selbstvertrauen in Echtzeit zu stärken. Entdecken Sie unverzichtbare, bahnbrechende Tools mit Vergleichen zwischen kostenlosen und kostenpflichtigen Angeboten sowie wöchentlich aktualisierten Rankings. Schaffen Sie sich noch heute einen sozialen Vorsprung.
10 Tools
xix.ai

看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡













