
















 Hogar
HogarDeep Cogito's LLMS superan modelos de tamaño similar con IDA
Deep Cogito, una empresa con sede en San Francisco, está causando revuelo en la comunidad de IA con su última lanzamiento de modelos de lenguaje grandes abiertos (LLMs). Estos modelos, que varían en tamaño desde 3 mil millones hasta 70 mil millones de parámetros, no son solo otro conjunto de herramientas de IA; son un paso audaz hacia lo que la empresa llama "superinteligencia general". Deep Cogito afirma que cada uno de sus modelos supera a los principales modelos abiertos de tamaños similares, incluyendo los de LLAMA, DeepSeek y Qwen, en la mayoría de los benchmarks estándar. Es una afirmación notable, pero aún más impresionante es que su modelo de 70B ha superado, según se informa, al recientemente lanzado modelo Llama 4 109B Mixture-of-Experts (MoE).
Destilación y Amplificación Iterada (IDA)
En el núcleo del avance de Deep Cogito está un nuevo enfoque de entrenamiento que llaman Destilación y Amplificación Iterada (IDA). Este método se describe como "una estrategia de alineación escalable y eficiente para la superinteligencia general utilizando la mejora iterativa propia". Está diseñado para superar las limitaciones del entrenamiento tradicional de LLMs, donde la inteligencia del modelo a menudo alcanza un límite definido por modelos "supervisores" más grandes o curadores humanos.
El proceso de IDA gira en torno a dos pasos clave que se repiten una y otra vez:
- Amplificación: Este paso utiliza más potencia computacional para ayudar al modelo a generar mejores soluciones o capacidades, similar a las técnicas de razonamiento avanzado.
- Destilación: Aquí, el modelo internaliza estas capacidades mejoradas, refinando sus parámetros.
Deep Cogito argumenta que esto crea un "bucle de retroalimentación positiva", permitiendo que la inteligencia del modelo crezca más directamente con los recursos computacionales y la eficiencia del propio proceso de IDA, en lugar de estar limitada por la inteligencia de un supervisor.
La empresa señala éxitos históricos como AlphaGo, enfatizando que el "Razonamiento Avanzado y la Mejora Iterativa Propia" fueron cruciales. IDA, afirman, incorpora estos elementos al entrenamiento de LLMs. También destacan la eficiencia de IDA, señalando que su equipo, aunque pequeño, logró desarrollar estos modelos en solo unos 75 días. En comparación con otros métodos como el Aprendizaje por Refuerzo desde Retroalimentación Humana (RLHF) o la destilación estándar desde modelos más grandes, se dice que IDA ofrece una mejor escalabilidad.
Como prueba, Deep Cogito destaca cómo su modelo de 70B supera tanto a Llama 3.3 70B (destilado de un modelo de 405B) como a Llama 4 Scout 109B (destilado de un modelo de 2T parámetros).
Capacidades y Rendimiento de los Modelos de Deep Cogito
Los nuevos modelos Cogito, que se basan en checkpoints de Llama y Qwen, están diseñados para codificación, invocación de funciones y aplicaciones agentivas. Una característica destacada es su doble funcionalidad: "Cada modelo puede responder directamente (LLM estándar) o autorreflexionar antes de responder (como modelos de razonamiento)". Esto refleja capacidades vistas en modelos como Claude 3.5. Sin embargo, Deep Cogito menciona que no se han centrado en cadenas de razonamiento muy largas, priorizando respuestas más rápidas y la eficiencia de destilar cadenas más cortas.
La empresa ha compartido resultados de benchmarks extensos, comparando sus modelos Cogito contra modelos abiertos de vanguardia de tamaño equivalente en modos directo y de razonamiento. En una variedad de benchmarks como MMLU, MMLU-Pro, ARC, GSM8K y MATH, y en diferentes tamaños de modelo (3B, 8B, 14B, 32B, 70B), los modelos Cogito generalmente muestran mejoras significativas en el rendimiento. Por ejemplo, el modelo Cogito 70B obtiene un 91.73% en MMLU en modo estándar, una mejora de +6.40% sobre Llama 3.3 70B, y un 91.00% en modo de pensamiento, un aumento de +4.40% sobre Deepseek R1 Distill 70B. Los puntajes de Livebench también reflejan estas mejoras.
Aquí están los benchmarks de los modelos de 14B para una comparación de tamaño medio:
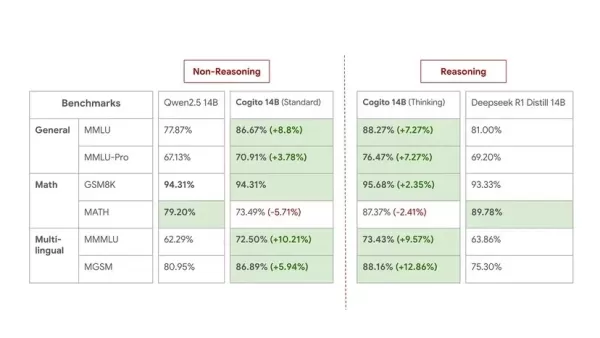
Aunque Deep Cogito reconoce que los benchmarks no capturan completamente la utilidad en el mundo real, confían en el rendimiento práctico de sus modelos. Este lanzamiento se considera una vista previa, con la empresa afirmando que están "todavía en las primeras etapas de esta curva de escalado". Planean lanzar checkpoints mejorados para los tamaños actuales e introducir modelos MoE más grandes (109B, 400B, 671B) en las próximas semanas y meses. Todos los modelos futuros también serán de código abierto.
Artículo relacionado
 Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge
La verdadera diferencia: no es una cosa, sino otra
A veces, las cosas no son solo una cosa, sino también otra. La frase «No es solo esto, es aquello» se ha vuelto tan habitual en los textos generados por IA que ya no es solo un indicio de contenido si
Recomendaciones de temas especiales relacionados
escribiendo
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge
La verdadera diferencia: no es una cosa, sino otra
A veces, las cosas no son solo una cosa, sino también otra. La frase «No es solo esto, es aquello» se ha vuelto tan habitual en los textos generados por IA que ya no es solo un indicio de contenido si
Recomendaciones de temas especiales relacionados
escribiendo
 Los mejores asistentes de IA para Xianxia y Wuxia: escribe progresiones épicas de cultivo y coreografías de artes marciales
Los mejores asistentes de IA para Xianxia y Wuxia: escribe progresiones épicas de cultivo y coreografías de artes marciales
Descubre los mejores asistentes de IA de 2026 para crear épicas historias de xianxia y wuxia. La lista seleccionada por XIX.AI incluye herramientas de primera categoría y revolucionarias para dominar la progresión en el camino del cultivo y la coreografía de las artes marciales. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales. ¡Libera tu potencial creativo y empieza a escribir hoy mismo!
 10 herramientas
10 herramientas
 xix.ai
código
Herramientas de codificación para aplicaciones móviles AI: Genera código multiplataforma en Flutter y React Native a partir de instrucciones proporcionadas.
xix.ai
código
Herramientas de codificación para aplicaciones móviles AI: Genera código multiplataforma en Flutter y React Native a partir de instrucciones proporcionadas.
Descubra los mejores herramientas de codificación para aplicaciones móviles basadas en IA en 2026, compatibles con Flutter y React Native. Nuestra lista, seleccionada cuidadosamente y evaluada por expertos, incluye soluciones poderosas que permiten generar código multiplataforma a partir de instrucciones sencillas. Compare opciones gratuitas y pagadas mediante pruebas reales. Acelere su desarrollo y cree aplicaciones de mejor calidad. Consulte las clasificaciones en XIX.AI ahora mismo.
10 herramientas
xix.ai
código
Las mejores extensiones de Chrome para generar contenido con IA: crea complementos personalizados para el navegador sin necesidad de saber programar
Descubre las mejores extensiones de Chrome para generar IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría que no te puedes perder y que te permiten crear complementos personalizados para el navegador sin necesidad de programar. Compara las opciones gratuitas con las de pago, consulta pruebas reales y potencia tu productividad. ¡Explora las últimas clasificaciones y encuentra hoy mismo la herramienta perfecta para ti!
10 herramientas
xix.ai
Texto a voz
Mejor sistema de voz sintética multilingüe por IA: genera habla auténtica con acento nativo en más de 50 idiomas
Descubra los mejores herramientas de TTS multilingües basadas en IA de 2026 que ofrecen pronunciaciones auténticas con acento nativo en más de 50 idiomas. Explore nuestras clasificaciones seleccionadas y evaluadas, con comparaciones entre opciones gratuitas y pagas, así como pruebas reales en el mundo real. Encuentre la herramienta de voz perfecta para usted en XIX.AI y desbloquee las posibilidades de la comunicación global hoy mismo.
10 herramientas
xix.ai
Asistente de reuniones
Los mejores herramientas de automatización de reuniones con IA para una colaboración más inteligente y rápida
Descubra las herramientas de automatización de reuniones con IA más recientes y mejor evaluadas en 2026 para una colaboración más inteligente y rápida. Nuestra lista seleccionada incluye soluciones poderosas que revolucionarán la forma en que se toman notas, se realizan resúmenes y se planifican acciones. Compare las opciones gratuitas con las pagadas a través de pruebas reales y clasificaciones actualizadas semanalmente. Desbloquee el máximo rendimiento de su equipo. Explore las mejores opciones ahora mismo en XIX.AI.
10 herramientas
xix.ai
Inmediato
Plantillas de IA para «infraestructura como código»: implementa configuraciones de Terraform y Docker de forma segura
Descubre las mejores plantillas de IA de 2026 para «Infraestructura como código». La selección de XIX.AI te ayuda a implementar de forma segura configuraciones de Terraform y Docker, automatizar configuraciones en la nube y potenciar la productividad de DevOps. Compara las opciones gratuitas con las de pago mediante pruebas reales. Explora ahora y saca el máximo partido a tu ventaja en IA.
10 herramientas
xix.ai

 comentario (29)
0/500
comentario (29)
0/500
![FrankMoore]()
看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
![HenryJackson]()
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
![RoyWhite]()
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
![PaulThomas]()
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
![GregoryCarter]()
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
![EricRoberts]()
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
Deep Cogito, una empresa con sede en San Francisco, está causando revuelo en la comunidad de IA con su última lanzamiento de modelos de lenguaje grandes abiertos (LLMs). Estos modelos, que varían en tamaño desde 3 mil millones hasta 70 mil millones de parámetros, no son solo otro conjunto de herramientas de IA; son un paso audaz hacia lo que la empresa llama "superinteligencia general". Deep Cogito afirma que cada uno de sus modelos supera a los principales modelos abiertos de tamaños similares, incluyendo los de LLAMA, DeepSeek y Qwen, en la mayoría de los benchmarks estándar. Es una afirmación notable, pero aún más impresionante es que su modelo de 70B ha superado, según se informa, al recientemente lanzado modelo Llama 4 109B Mixture-of-Experts (MoE).
Destilación y Amplificación Iterada (IDA)
En el núcleo del avance de Deep Cogito está un nuevo enfoque de entrenamiento que llaman Destilación y Amplificación Iterada (IDA). Este método se describe como "una estrategia de alineación escalable y eficiente para la superinteligencia general utilizando la mejora iterativa propia". Está diseñado para superar las limitaciones del entrenamiento tradicional de LLMs, donde la inteligencia del modelo a menudo alcanza un límite definido por modelos "supervisores" más grandes o curadores humanos.
El proceso de IDA gira en torno a dos pasos clave que se repiten una y otra vez:
- Amplificación: Este paso utiliza más potencia computacional para ayudar al modelo a generar mejores soluciones o capacidades, similar a las técnicas de razonamiento avanzado.
- Destilación: Aquí, el modelo internaliza estas capacidades mejoradas, refinando sus parámetros.
Deep Cogito argumenta que esto crea un "bucle de retroalimentación positiva", permitiendo que la inteligencia del modelo crezca más directamente con los recursos computacionales y la eficiencia del propio proceso de IDA, en lugar de estar limitada por la inteligencia de un supervisor.
La empresa señala éxitos históricos como AlphaGo, enfatizando que el "Razonamiento Avanzado y la Mejora Iterativa Propia" fueron cruciales. IDA, afirman, incorpora estos elementos al entrenamiento de LLMs. También destacan la eficiencia de IDA, señalando que su equipo, aunque pequeño, logró desarrollar estos modelos en solo unos 75 días. En comparación con otros métodos como el Aprendizaje por Refuerzo desde Retroalimentación Humana (RLHF) o la destilación estándar desde modelos más grandes, se dice que IDA ofrece una mejor escalabilidad.
Como prueba, Deep Cogito destaca cómo su modelo de 70B supera tanto a Llama 3.3 70B (destilado de un modelo de 405B) como a Llama 4 Scout 109B (destilado de un modelo de 2T parámetros).
Capacidades y Rendimiento de los Modelos de Deep Cogito
Los nuevos modelos Cogito, que se basan en checkpoints de Llama y Qwen, están diseñados para codificación, invocación de funciones y aplicaciones agentivas. Una característica destacada es su doble funcionalidad: "Cada modelo puede responder directamente (LLM estándar) o autorreflexionar antes de responder (como modelos de razonamiento)". Esto refleja capacidades vistas en modelos como Claude 3.5. Sin embargo, Deep Cogito menciona que no se han centrado en cadenas de razonamiento muy largas, priorizando respuestas más rápidas y la eficiencia de destilar cadenas más cortas.
La empresa ha compartido resultados de benchmarks extensos, comparando sus modelos Cogito contra modelos abiertos de vanguardia de tamaño equivalente en modos directo y de razonamiento. En una variedad de benchmarks como MMLU, MMLU-Pro, ARC, GSM8K y MATH, y en diferentes tamaños de modelo (3B, 8B, 14B, 32B, 70B), los modelos Cogito generalmente muestran mejoras significativas en el rendimiento. Por ejemplo, el modelo Cogito 70B obtiene un 91.73% en MMLU en modo estándar, una mejora de +6.40% sobre Llama 3.3 70B, y un 91.00% en modo de pensamiento, un aumento de +4.40% sobre Deepseek R1 Distill 70B. Los puntajes de Livebench también reflejan estas mejoras.
Aquí están los benchmarks de los modelos de 14B para una comparación de tamaño medio:
Aunque Deep Cogito reconoce que los benchmarks no capturan completamente la utilidad en el mundo real, confían en el rendimiento práctico de sus modelos. Este lanzamiento se considera una vista previa, con la empresa afirmando que están "todavía en las primeras etapas de esta curva de escalado". Planean lanzar checkpoints mejorados para los tamaños actuales e introducir modelos MoE más grandes (109B, 400B, 671B) en las próximas semanas y meses. Todos los modelos futuros también serán de código abierto.










 Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
Barry Diller: La confianza en Sam Altman es irrelevante a medida que se acerca la IA general
Barry Diller, el multimillonario magnate de los medios de comunicación, no cree que Sam Altman, director ejecutivo de OpenAI, sea poco digno de confianza, a pesar de los recientes informes que sugiere
 YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge
YouTube amplía la detección de deepfakes mediante IA a políticos, funcionarios públicos y periodistas
El martes, YouTube anunció que va a ampliar su tecnología de detección de deepfakes a un grupo selecto de funcionarios públicos, candidatos políticos y periodistas. La herramienta identifica las imáge
 La verdadera diferencia: no es una cosa, sino otra
A veces, las cosas no son solo una cosa, sino también otra. La frase «No es solo esto, es aquello» se ha vuelto tan habitual en los textos generados por IA que ya no es solo un indicio de contenido si
La verdadera diferencia: no es una cosa, sino otra
A veces, las cosas no son solo una cosa, sino también otra. La frase «No es solo esto, es aquello» se ha vuelto tan habitual en los textos generados por IA que ya no es solo un indicio de contenido si

Descubre los mejores asistentes de IA de 2026 para crear épicas historias de xianxia y wuxia. La lista seleccionada por XIX.AI incluye herramientas de primera categoría y revolucionarias para dominar la progresión en el camino del cultivo y la coreografía de las artes marciales. Compara las opciones gratuitas con las de pago mediante pruebas en condiciones reales. ¡Libera tu potencial creativo y empieza a escribir hoy mismo!
10 herramientas
xix.ai

Descubra los mejores herramientas de codificación para aplicaciones móviles basadas en IA en 2026, compatibles con Flutter y React Native. Nuestra lista, seleccionada cuidadosamente y evaluada por expertos, incluye soluciones poderosas que permiten generar código multiplataforma a partir de instrucciones sencillas. Compare opciones gratuitas y pagadas mediante pruebas reales. Acelere su desarrollo y cree aplicaciones de mejor calidad. Consulte las clasificaciones en XIX.AI ahora mismo.
10 herramientas
xix.ai

Descubre las mejores extensiones de Chrome para generar IA de 2026 en XIX.AI. Nuestra lista seleccionada incluye herramientas de primera categoría que no te puedes perder y que te permiten crear complementos personalizados para el navegador sin necesidad de programar. Compara las opciones gratuitas con las de pago, consulta pruebas reales y potencia tu productividad. ¡Explora las últimas clasificaciones y encuentra hoy mismo la herramienta perfecta para ti!
10 herramientas
xix.ai

Descubra los mejores herramientas de TTS multilingües basadas en IA de 2026 que ofrecen pronunciaciones auténticas con acento nativo en más de 50 idiomas. Explore nuestras clasificaciones seleccionadas y evaluadas, con comparaciones entre opciones gratuitas y pagas, así como pruebas reales en el mundo real. Encuentre la herramienta de voz perfecta para usted en XIX.AI y desbloquee las posibilidades de la comunicación global hoy mismo.
10 herramientas
xix.ai

Descubra las herramientas de automatización de reuniones con IA más recientes y mejor evaluadas en 2026 para una colaboración más inteligente y rápida. Nuestra lista seleccionada incluye soluciones poderosas que revolucionarán la forma en que se toman notas, se realizan resúmenes y se planifican acciones. Compare las opciones gratuitas con las pagadas a través de pruebas reales y clasificaciones actualizadas semanalmente. Desbloquee el máximo rendimiento de su equipo. Explore las mejores opciones ahora mismo en XIX.AI.
10 herramientas
xix.ai

Descubre las mejores plantillas de IA de 2026 para «Infraestructura como código». La selección de XIX.AI te ayuda a implementar de forma segura configuraciones de Terraform y Docker, automatizar configuraciones en la nube y potenciar la productividad de DevOps. Compara las opciones gratuitas con las de pago mediante pruebas reales. Explora ahora y saca el máximo partido a tu ventaja en IA.
10 herramientas
xix.ai

看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡













