
















 Lar
LarO LLMS da Deep Cogito superou os modelos de tamanho semelhante usando IDA
Deep Cogito, uma empresa com sede em São Francisco, está causando impacto na comunidade de IA com seu mais recente lançamento de modelos de linguagem de grande escala (LLMs) abertos. Esses modelos, que variam em tamanhos de 3 bilhões a 70 bilhões de parâmetros, não são apenas mais um conjunto de ferramentas de IA; são um passo ousado em direção ao que a empresa chama de "superinteligência geral". A Deep Cogito afirma que cada um de seus modelos supera os principais modelos abertos de tamanhos semelhantes, incluindo aqueles da LLAMA, DeepSeek e Qwen, na maioria dos benchmarks padrão. É uma afirmação impressionante, mas o que é ainda mais impressionante é que seu modelo de 70B teria superado o recentemente lançado modelo Llama 4 109B Mixture-of-Experts (MoE).
Destilação e Amplificação Iteradas (IDA)
No cerne do avanço da Deep Cogito está uma nova abordagem de treinamento que eles chamam de Destilação e Amplificação Iteradas (IDA). Esse método é descrito como "uma estratégia de alinhamento escalável e eficiente para superinteligência geral usando autoaperfeiçoamento iterativo". Ele é projetado para superar as limitações do treinamento tradicional de LLMs, onde a inteligência do modelo frequentemente atinge um teto definido por modelos "supervisores" maiores ou curadores humanos.
O processo IDA gira em torno de dois passos principais que são repetidos continuamente:
- Amplificação: Esta etapa utiliza mais poder computacional para ajudar o modelo a encontrar melhores soluções ou capacidades, semelhante a técnicas de raciocínio avançado.
- Destilação: Aqui, o modelo internaliza essas capacidades aprimoradas, refinando seus parâmetros.
A Deep Cogito argumenta que isso cria um "ciclo de retroalimentação positiva", permitindo que a inteligência do modelo cresça mais diretamente com os recursos computacionais e a eficiência do próprio processo IDA, em vez de ser limitada pela inteligência de um supervisor.
A empresa aponta para sucessos históricos como o AlphaGo, enfatizando que "Raciocínio Avançado e Autoaperfeiçoamento Iterativo" foram cruciais. O IDA, eles afirmam, traz esses elementos para o treinamento de LLMs. Eles também destacam a eficiência do IDA, observando que sua equipe, embora pequena, conseguiu desenvolver esses modelos em cerca de 75 dias. Quando comparado a outros métodos como Aprendizado por Reforço a partir de Feedback Humano (RLHF) ou destilação padrão de modelos maiores, o IDA é dito oferecer melhor escalabilidade.
Como prova, a Deep Cogito destaca como seu modelo de 70B supera tanto o Llama 3.3 70B (destilado de um modelo de 405B) quanto o Llama 4 Scout 109B (destilado de um modelo de 2T de parâmetros).
Capacidades e Desempenho dos Modelos Deep Cogito
Os novos modelos Cogito, que se baseiam em checkpoints do Llama e Qwen, são adaptados para codificação, chamada de funções e aplicações agentivas. Um recurso destacado é sua funcionalidade dupla: "Cada modelo pode responder diretamente (LLM padrão) ou autorrefletir antes de responder (como modelos de raciocínio)." Isso reflete capacidades vistas em modelos como Claude 3.5. No entanto, a Deep Cogito menciona que não focou em cadeias de raciocínio muito longas, priorizando respostas mais rápidas e a eficiência de destilar cadeias mais curtas.
A empresa compartilhou resultados extensivos de benchmarks, comparando seus modelos Cogito contra modelos abertos de última geração de tamanhos equivalentes, tanto em modos direto quanto de raciocínio. Em uma variedade de benchmarks como MMLU, MMLU-Pro, ARC, GSM8K e MATH, e em diferentes tamanhos de modelo (3B, 8B, 14B, 32B, 70B), os modelos Cogito geralmente mostram melhorias significativas de desempenho. Por exemplo, o modelo Cogito 70B pontua 91,73% no MMLU em modo padrão, uma melhoria de +6,40% sobre o Llama 3.3 70B, e 91,00% no modo de pensamento, um aumento de +4,40% sobre o Deepseek R1 Distill 70B. As pontuações do Livebench também refletem esses ganhos.
Aqui estão os benchmarks dos modelos de 14B para uma comparação de tamanho médio:
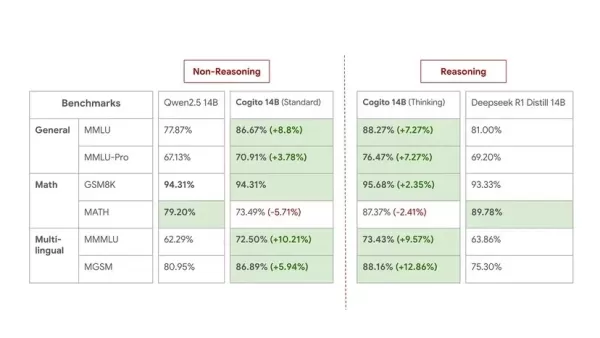
Embora a Deep Cogito reconheça que os benchmarks não capturam totalmente a utilidade no mundo real, eles permanecem confiantes no desempenho prático de seus modelos. Este lançamento é considerado uma prévia, com a empresa afirmando que está "ainda nos estágios iniciais dessa curva de escalonamento". Eles planejam lançar checkpoints aprimorados para os tamanhos atuais e introduzir modelos MoE maiores (109B, 400B, 671B) nas próximas semanas e meses. Todos os modelos futuros também serão de código aberto.
Artigo relacionado
 Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden
A verdadeira diferença: não é uma coisa, mas outra
Às vezes, as coisas não são apenas uma coisa, mas também outra. A frase “Não é só isso — é aquilo” tornou-se tão comum em textos gerados por IA que agora serve como mais do que uma indicação de conteú
Recomendações de tópicos especiais relacionados
escrita
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden
A verdadeira diferença: não é uma coisa, mas outra
Às vezes, as coisas não são apenas uma coisa, mas também outra. A frase “Não é só isso — é aquilo” tornou-se tão comum em textos gerados por IA que agora serve como mais do que uma indicação de conteú
Recomendações de tópicos especiais relacionados
escrita
 Os melhores assistentes de IA para Xianxia e Wuxia: crie histórias épicas de evolução no caminho do cultivo e coreografias de artes marciais
Os melhores assistentes de IA para Xianxia e Wuxia: crie histórias épicas de evolução no caminho do cultivo e coreografias de artes marciais
Descubra os melhores assistentes de IA de 2026 para criar histórias épicas de xianxia e wuxia. A lista selecionada pela XIX.AI apresenta ferramentas de primeira linha e revolucionárias para dominar a progressão no caminho do cultivo e a coreografia de artes marciais. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a escrever hoje mesmo!
 10 ferramentas
10 ferramentas
 xix.ai
código
Ferramentas de Codificação para Aplicativos Móveis com IA: Gere código multiplataforma Flutter e React Native a partir de prompts.
xix.ai
código
Ferramentas de Codificação para Aplicativos Móveis com IA: Gere código multiplataforma Flutter e React Native a partir de prompts.
Descubra os melhores ferramentas de programação para aplicativos móveis com IA em 2026 para Flutter e React Native. Nossa lista selecionada e altamente avaliada apresenta soluções poderosas que revolucionam o processo de desenvolvimento, gerando código multiplataforma a partir de instruções simples. Compare opções gratuitas e pagas com testes reais. Acelere seu desenvolvimento e crie aplicativos melhores. Explore as classificações no XIX.AI agora mesmo!
10 ferramentas
xix.ai
código
Os melhores geradores de extensões do Chrome com IA: crie complementos personalizados para o navegador sem precisar saber programar
Descubra as melhores extensões do Chrome com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta as ferramentas mais bem avaliadas e imperdíveis, que permitem criar complementos personalizados para o navegador sem precisar programar. Compare as opções gratuitas com as pagas, confira testes práticos e aumente sua produtividade. Explore os rankings mais recentes e encontre a ferramenta perfeita para você hoje mesmo!
10 ferramentas
xix.ai
Conversão de texto para fala
Melhor Tecnologia de Voz Artificial Multilíngue: Geração de Falas Autênticas com Sotaque Nativo em Mais de 50 Línguas
Descubra os melhores ferramentas de TTS multilíngues de IA de 2026 para obter falas com sotaques nativos autênticos em mais de 50 idiomas. Conheça nossas classificações selecionadas, com comparações entre versões gratuitas e pagas, além de testes reais. Encontre a ferramenta de voz perfeita para você no XIX.AI e desfrute da comunicação global já hoje.
10 ferramentas
xix.ai
Assistente de Reunião
Os melhores ferramentas de automação de reuniões com inteligência artificial para uma colaboração mais inteligente e rápida
Descubra as mais recentes e bem avaliadas ferramentas de automação de reuniões por IA de 2026 para uma colaboração mais inteligente e rápida. Nossa lista selecionada apresenta soluções poderosas que podem transformar a forma como você organiza notas, resumos e tarefas. Compare opções gratuitas e pagas com testes reais e rankings atualizados semanalmente. Aumente a produtividade da sua equipe. Explore as melhores escolhas agora em XIX.AI.
10 ferramentas
xix.ai
Incitar
Sugestões de IA para Infraestrutura como Código: Implemente configurações do Terraform e do Docker com segurança
Descubra os prompts de IA mais bem avaliados de 2026 para Infraestrutura como Código. A seleção cuidadosamente escolhida pela XIX.AI ajuda você a implantar com segurança configurações do Terraform e do Docker, automatizar configurações na nuvem e aumentar a produtividade do DevOps. Compare as opções gratuitas com as pagas por meio de testes práticos. Explore agora e descubra o seu diferencial em IA.
10 ferramentas
xix.ai

 Comentários (29)
Comentários (29)
![FrankMoore]()
看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
![HenryJackson]()
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
![RoyWhite]()
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
![PaulThomas]()
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
![GregoryCarter]()
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
![EricRoberts]()
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡
Deep Cogito, uma empresa com sede em São Francisco, está causando impacto na comunidade de IA com seu mais recente lançamento de modelos de linguagem de grande escala (LLMs) abertos. Esses modelos, que variam em tamanhos de 3 bilhões a 70 bilhões de parâmetros, não são apenas mais um conjunto de ferramentas de IA; são um passo ousado em direção ao que a empresa chama de "superinteligência geral". A Deep Cogito afirma que cada um de seus modelos supera os principais modelos abertos de tamanhos semelhantes, incluindo aqueles da LLAMA, DeepSeek e Qwen, na maioria dos benchmarks padrão. É uma afirmação impressionante, mas o que é ainda mais impressionante é que seu modelo de 70B teria superado o recentemente lançado modelo Llama 4 109B Mixture-of-Experts (MoE).
Destilação e Amplificação Iteradas (IDA)
No cerne do avanço da Deep Cogito está uma nova abordagem de treinamento que eles chamam de Destilação e Amplificação Iteradas (IDA). Esse método é descrito como "uma estratégia de alinhamento escalável e eficiente para superinteligência geral usando autoaperfeiçoamento iterativo". Ele é projetado para superar as limitações do treinamento tradicional de LLMs, onde a inteligência do modelo frequentemente atinge um teto definido por modelos "supervisores" maiores ou curadores humanos.
O processo IDA gira em torno de dois passos principais que são repetidos continuamente:
- Amplificação: Esta etapa utiliza mais poder computacional para ajudar o modelo a encontrar melhores soluções ou capacidades, semelhante a técnicas de raciocínio avançado.
- Destilação: Aqui, o modelo internaliza essas capacidades aprimoradas, refinando seus parâmetros.
A Deep Cogito argumenta que isso cria um "ciclo de retroalimentação positiva", permitindo que a inteligência do modelo cresça mais diretamente com os recursos computacionais e a eficiência do próprio processo IDA, em vez de ser limitada pela inteligência de um supervisor.
A empresa aponta para sucessos históricos como o AlphaGo, enfatizando que "Raciocínio Avançado e Autoaperfeiçoamento Iterativo" foram cruciais. O IDA, eles afirmam, traz esses elementos para o treinamento de LLMs. Eles também destacam a eficiência do IDA, observando que sua equipe, embora pequena, conseguiu desenvolver esses modelos em cerca de 75 dias. Quando comparado a outros métodos como Aprendizado por Reforço a partir de Feedback Humano (RLHF) ou destilação padrão de modelos maiores, o IDA é dito oferecer melhor escalabilidade.
Como prova, a Deep Cogito destaca como seu modelo de 70B supera tanto o Llama 3.3 70B (destilado de um modelo de 405B) quanto o Llama 4 Scout 109B (destilado de um modelo de 2T de parâmetros).
Capacidades e Desempenho dos Modelos Deep Cogito
Os novos modelos Cogito, que se baseiam em checkpoints do Llama e Qwen, são adaptados para codificação, chamada de funções e aplicações agentivas. Um recurso destacado é sua funcionalidade dupla: "Cada modelo pode responder diretamente (LLM padrão) ou autorrefletir antes de responder (como modelos de raciocínio)." Isso reflete capacidades vistas em modelos como Claude 3.5. No entanto, a Deep Cogito menciona que não focou em cadeias de raciocínio muito longas, priorizando respostas mais rápidas e a eficiência de destilar cadeias mais curtas.
A empresa compartilhou resultados extensivos de benchmarks, comparando seus modelos Cogito contra modelos abertos de última geração de tamanhos equivalentes, tanto em modos direto quanto de raciocínio. Em uma variedade de benchmarks como MMLU, MMLU-Pro, ARC, GSM8K e MATH, e em diferentes tamanhos de modelo (3B, 8B, 14B, 32B, 70B), os modelos Cogito geralmente mostram melhorias significativas de desempenho. Por exemplo, o modelo Cogito 70B pontua 91,73% no MMLU em modo padrão, uma melhoria de +6,40% sobre o Llama 3.3 70B, e 91,00% no modo de pensamento, um aumento de +4,40% sobre o Deepseek R1 Distill 70B. As pontuações do Livebench também refletem esses ganhos.
Aqui estão os benchmarks dos modelos de 14B para uma comparação de tamanho médio:
Embora a Deep Cogito reconheça que os benchmarks não capturam totalmente a utilidade no mundo real, eles permanecem confiantes no desempenho prático de seus modelos. Este lançamento é considerado uma prévia, com a empresa afirmando que está "ainda nos estágios iniciais dessa curva de escalonamento". Eles planejam lançar checkpoints aprimorados para os tamanhos atuais e introduzir modelos MoE maiores (109B, 400B, 671B) nas próximas semanas e meses. Todos os modelos futuros também serão de código aberto.










 Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
Barry Diller: A confiança em Sam Altman é irrelevante à medida que a IA geral se aproxima
Barry Diller, o bilionário magnata da mídia, não acredita que Sam Altman, CEO da OpenAI, seja indigno de confiança, apesar de relatos recentes sugerirem o contrário. Em discurso na conferência “Future
 O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden
O YouTube amplia a detecção de deepfakes por IA para políticos, autoridades governamentais e jornalistas
Na terça-feira, o YouTube anunciou que está expandindo sua tecnologia de detecção de deepfakes para um grupo seleto de autoridades governamentais, candidatos políticos e jornalistas. A ferramenta iden
 A verdadeira diferença: não é uma coisa, mas outra
Às vezes, as coisas não são apenas uma coisa, mas também outra. A frase “Não é só isso — é aquilo” tornou-se tão comum em textos gerados por IA que agora serve como mais do que uma indicação de conteú
A verdadeira diferença: não é uma coisa, mas outra
Às vezes, as coisas não são apenas uma coisa, mas também outra. A frase “Não é só isso — é aquilo” tornou-se tão comum em textos gerados por IA que agora serve como mais do que uma indicação de conteú

Descubra os melhores assistentes de IA de 2026 para criar histórias épicas de xianxia e wuxia. A lista selecionada pela XIX.AI apresenta ferramentas de primeira linha e revolucionárias para dominar a progressão no caminho do cultivo e a coreografia de artes marciais. Compare opções gratuitas e pagas com testes práticos. Liberte seu potencial criativo e comece a escrever hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores ferramentas de programação para aplicativos móveis com IA em 2026 para Flutter e React Native. Nossa lista selecionada e altamente avaliada apresenta soluções poderosas que revolucionam o processo de desenvolvimento, gerando código multiplataforma a partir de instruções simples. Compare opções gratuitas e pagas com testes reais. Acelere seu desenvolvimento e crie aplicativos melhores. Explore as classificações no XIX.AI agora mesmo!
10 ferramentas
xix.ai

Descubra as melhores extensões do Chrome com IA de 2026 no XIX.AI. Nossa lista selecionada apresenta as ferramentas mais bem avaliadas e imperdíveis, que permitem criar complementos personalizados para o navegador sem precisar programar. Compare as opções gratuitas com as pagas, confira testes práticos e aumente sua produtividade. Explore os rankings mais recentes e encontre a ferramenta perfeita para você hoje mesmo!
10 ferramentas
xix.ai

Descubra os melhores ferramentas de TTS multilíngues de IA de 2026 para obter falas com sotaques nativos autênticos em mais de 50 idiomas. Conheça nossas classificações selecionadas, com comparações entre versões gratuitas e pagas, além de testes reais. Encontre a ferramenta de voz perfeita para você no XIX.AI e desfrute da comunicação global já hoje.
10 ferramentas
xix.ai

Descubra as mais recentes e bem avaliadas ferramentas de automação de reuniões por IA de 2026 para uma colaboração mais inteligente e rápida. Nossa lista selecionada apresenta soluções poderosas que podem transformar a forma como você organiza notas, resumos e tarefas. Compare opções gratuitas e pagas com testes reais e rankings atualizados semanalmente. Aumente a produtividade da sua equipe. Explore as melhores escolhas agora em XIX.AI.
10 ferramentas
xix.ai

Descubra os prompts de IA mais bem avaliados de 2026 para Infraestrutura como Código. A seleção cuidadosamente escolhida pela XIX.AI ajuda você a implantar com segurança configurações do Terraform e do Docker, automatizar configurações na nuvem e aumentar a produtividade do DevOps. Compare as opções gratuitas com as pagas por meio de testes práticos. Explore agora e descubra o seu diferencial em IA.
10 ferramentas
xix.ai

看起来这家叫做Deep Cogito的新公司有点门道。IDA架构?之前没听说过这个技术,好奇跟MoE比怎么样。要是能出个小点的模型让大家体验一下就好了,毕竟现在动辄几十B参数量,普通开发者根本玩不起。希望别只是实验室数据漂亮,实际应用打折扣。
このモデルの性能、ほかの同サイズのモデルより優れてるの?IDAの手法が効いてるのかな。個人的には倫理的な側面も気になるけど、オープンソースなのはすごく良いと思う👍 実際に使ってみたい!
Deep Cogito's LLMs sound like a game-changer! Outperforming models of similar size with IDA is no small feat. Curious to see how these stack up in real-world tasks. 🚀
Super cool to see Deep Cogito pushing the boundaries with their LLMs! 😎 Those parameter sizes are wild—wonder how they stack up in real-world tasks?
LLM от Deep Cogito впечатляют, но приложение могло бы иметь лучший UI. Навигация по разным размерам моделей немного неуклюжая. Тем не менее, производительность на высшем уровне, особенно с технологией IDA. Обязательно стоит посмотреть, если вы интересуетесь ИИ и хотите увидеть, что возможно с большими языковыми моделями! 🤖💡
ディープコギトのLLMは印象的ですが、アプリのUIがもう少し改善されると良いですね。モデルサイズをナビゲートするのが少しぎこちないです。それでも、パフォーマンスは最高で、特にIDAテクノロジーとの組み合わせが素晴らしいです。AIに興味があるなら、大規模言語モデルの可能性を見る価値がありますよ!🤖💡













